También podría gustarte
- Charles SpurgeonDocumento42 páginasCharles SpurgeonMario Casanoves100% (1)
- Grupo 5 MBA 160B - Competir Mediante El AnálisisDocumento2 páginasGrupo 5 MBA 160B - Competir Mediante El AnálisisJensen Roy Quispe Suárez100% (1)
- Evaluacion Proyectos 2018Documento26 páginasEvaluacion Proyectos 2018Jhon FigueroaAún no hay calificaciones
- Ppt-Introducción de Machine Learning Con PythonDocumento21 páginasPpt-Introducción de Machine Learning Con PythonAron Ruben Flores Zarzosa100% (1)
- Herramientas Cualitativas y Cuantitativas de Análisis de ProcesosDocumento61 páginasHerramientas Cualitativas y Cuantitativas de Análisis de ProcesosManuel Madera AguilarAún no hay calificaciones
- Aprendizaje supervisado y regresión lineal en MLDocumento27 páginasAprendizaje supervisado y regresión lineal en MLcarlosjulioph100% (1)
- Check List Alza-HombreDocumento3 páginasCheck List Alza-HombreCarlos Sepulveda100% (1)
- M15 U3 A1 ConcepcionVictorioDocumento3 páginasM15 U3 A1 ConcepcionVictorioAnthony TwissAún no hay calificaciones
- Investigación de MercadosDocumento497 páginasInvestigación de Mercadosrberrospi_2100% (2)
- 6° Sesion Division de Numeros NaturalesDocumento34 páginas6° Sesion Division de Numeros NaturalesFlor María Martínez Flores100% (1)
- PRUEBA de HISTORIA Unidad Vivir en SociedadDocumento8 páginasPRUEBA de HISTORIA Unidad Vivir en SociedadRosa Cheuqueman VargasAún no hay calificaciones
- Escalonamiento MultidimensionalDocumento1 páginaEscalonamiento MultidimensionalKevin VillcaAún no hay calificaciones
- Sesiones 05 de SetiembreDocumento11 páginasSesiones 05 de SetiembreVeronica Del Rocio Changanaqui BarzolaAún no hay calificaciones
- M1 - Proceso de Aprendizaje - 300821Documento23 páginasM1 - Proceso de Aprendizaje - 300821Alex Romero MendozaAún no hay calificaciones
- Mapa Mental Mineria de DatosDocumento1 páginaMapa Mental Mineria de DatosCurtis AdriánAún no hay calificaciones
- Entendimiento del negocio: Definición de la variable objetivo (TargetDocumento41 páginasEntendimiento del negocio: Definición de la variable objetivo (TargetLuis Villegas AjahuanaAún no hay calificaciones
- Sesion01 - MachineLearningInmersionPythonDocumento49 páginasSesion01 - MachineLearningInmersionPythonAngie Evangelista MautinoAún no hay calificaciones
- Tabla Comparativa - Tipos de ModelosDocumento4 páginasTabla Comparativa - Tipos de ModelosDiego Armando Espinosa LastraAún no hay calificaciones
- MicroESTADISTICA 2018FT GPA 003diseñomicrocurricular - Vjunio2020Documento6 páginasMicroESTADISTICA 2018FT GPA 003diseñomicrocurricular - Vjunio2020JeisonMuneraAún no hay calificaciones
- A1_JFBRDocumento3 páginasA1_JFBRJuan Franciso Borrayo RodriguezAún no hay calificaciones
- MapaDocumento3 páginasMapaCarla JacoboAún no hay calificaciones
- 6° Sesion Division de Numeros NaturalesDocumento32 páginas6° Sesion Division de Numeros NaturalesYuvissa Zavaleta LozanoAún no hay calificaciones
- 05 Intriago - C - U3Documento3 páginas05 Intriago - C - U3Karina MaldonadoAún no hay calificaciones
- 3 Plan de DestrezasDocumento18 páginas3 Plan de DestrezasArturo RosalesAún no hay calificaciones
- Módulo de Aprendizaje 2Documento6 páginasMódulo de Aprendizaje 2Oswaldo BenitesAún no hay calificaciones
- 25.syllabus 2021 Álgebra Lineal OkDocumento9 páginas25.syllabus 2021 Álgebra Lineal OkGuillermo Alexander Rojas LunaAún no hay calificaciones
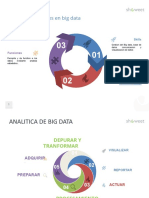
- Datas Science INfoDocumento1 páginaDatas Science INfoLiz GmarAún no hay calificaciones
- Alvaradohectoralejandrobonilla - 15849 - 2732133 - Presentacion Machine Learning Grupo #6 - SubirDocumento8 páginasAlvaradohectoralejandrobonilla - 15849 - 2732133 - Presentacion Machine Learning Grupo #6 - SubirMike WuAún no hay calificaciones
- Mapa Mental Proceso de CompraDocumento1 páginaMapa Mental Proceso de Compranadia baxinAún no hay calificaciones
- Malla Mat. 4° 2023Documento4 páginasMalla Mat. 4° 2023lina zuluagaAún no hay calificaciones
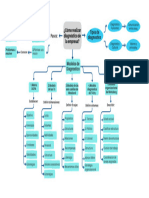
- Mapa mental - Diagnostico de la empresaDocumento1 páginaMapa mental - Diagnostico de la empresakerenAún no hay calificaciones
- Grafica Modelo Canvas para Modelo de Negocio Ilustrado NudeDocumento1 páginaGrafica Modelo Canvas para Modelo de Negocio Ilustrado NudeLuis Alberto Sanchez FigueroaAún no hay calificaciones
- Ova 2Documento5 páginasOva 2Nelson Mauricio ReyesAún no hay calificaciones
- Matematicas - 2 Parcial - 1 Quimestre - SeptimosDocumento9 páginasMatematicas - 2 Parcial - 1 Quimestre - SeptimosAlexx AntonAún no hay calificaciones
- Representación gráfica de datos estadísticosDocumento3 páginasRepresentación gráfica de datos estadísticosRosa BaezAún no hay calificaciones
- Secuencia Didáctica SéptimoDocumento2 páginasSecuencia Didáctica SéptimodantoniolAún no hay calificaciones
- Conceptos básicos de estadística descriptivaDocumento12 páginasConceptos básicos de estadística descriptivaPaula AndreaAún no hay calificaciones
- Microcurriculo Estadística Basica EBX04Documento10 páginasMicrocurriculo Estadística Basica EBX04Andrus0827Aún no hay calificaciones
- REJILLA DE EVALUACIÓN ESTUDIANTES Y PADRES DE FAMILIA 2°Documento1 páginaREJILLA DE EVALUACIÓN ESTUDIANTES Y PADRES DE FAMILIA 2°Manuel Alejandro Mayorga BetancourtAún no hay calificaciones
- Tareas Metodos Algoritmos DatascienceDocumento4 páginasTareas Metodos Algoritmos DatascienceAlberto Valdes ChavezAún no hay calificaciones
- Estructura Grado PrimeroDocumento6 páginasEstructura Grado PrimeroOrjuela Pena Carlos AndresAún no hay calificaciones
- r-2 (5)Documento31 páginasr-2 (5)YERALD IGNACIO ARAYA CANALESAún no hay calificaciones
- Anexo 2.1. Plan Unidad de Trabajo-PUTDocumento10 páginasAnexo 2.1. Plan Unidad de Trabajo-PUTBachilleratoAún no hay calificaciones
- Silabo Curso FMMP210 BETADocumento4 páginasSilabo Curso FMMP210 BETAJavi FernandaAún no hay calificaciones
- Actividad 1 EconometriaDocumento6 páginasActividad 1 EconometriaAlejandro VargasAún no hay calificaciones
- Planificación microcurricular de unidad didácticaDocumento3 páginasPlanificación microcurricular de unidad didácticacarolinaAún no hay calificaciones
- Matemáticas 3Documento4 páginasMatemáticas 3Juan Manuel Beleño NietoAún no hay calificaciones
- Mapa Mental (Ingeniería de Requisitos) 1Documento3 páginasMapa Mental (Ingeniería de Requisitos) 1Jezuz SalamancaAún no hay calificaciones
- Aprendizaje SupervisadoDocumento11 páginasAprendizaje SupervisadoClaudia MosqueraAún no hay calificaciones
- A2 AdalDocumento3 páginasA2 Adalalex daniel acosta lunaAún no hay calificaciones
- Sesion Martes 2Documento9 páginasSesion Martes 2Mari Díaz VásquezAún no hay calificaciones
- Pud 4 TerceroDocumento5 páginasPud 4 TerceroStalin FernandezAún no hay calificaciones
- HC ASUC01274 Estadística Aplicada para La Gestión 2022Documento15 páginasHC ASUC01274 Estadística Aplicada para La Gestión 2022SEBASTIAN ROLAND CHAMORRO ARROYOAún no hay calificaciones
- 3.1 Planificación de La Demanda y PronósticoDocumento19 páginas3.1 Planificación de La Demanda y Pronósticojuan moyaAún no hay calificaciones
- 00 PresentaciónDocumento12 páginas00 PresentaciónJohn J. ParedesAún no hay calificaciones
- S.1.22.23 Planeacion Aing Ra 1.2Documento18 páginasS.1.22.23 Planeacion Aing Ra 1.2Mauricio Almazán TorresAún no hay calificaciones
- Sistemas de Informacion PDFDocumento8 páginasSistemas de Informacion PDFjulio0% (1)
- Silabus Estadística 2022 RevisadoDocumento92 páginasSilabus Estadística 2022 RevisadoCORPROVISEG S.R.L.Aún no hay calificaciones
- Ruta de Actividades de Ept de La 2da Unidad de AprendizajeDocumento4 páginasRuta de Actividades de Ept de La 2da Unidad de AprendizajeSofia ChucoAún no hay calificaciones
- Matematica 7mo PLAN SEMANAL DE CLASE 2023 (Semana 5)Documento2 páginasMatematica 7mo PLAN SEMANAL DE CLASE 2023 (Semana 5)Gregorio CoelloAún no hay calificaciones
- Mapa conceptual del área de operacionesDocumento1 páginaMapa conceptual del área de operacionesMaguie Lizama BarreraAún no hay calificaciones
- Tabla Comparativa - Tipos de ModelosDocumento4 páginasTabla Comparativa - Tipos de ModelosDiego Armando Espinosa LastraAún no hay calificaciones
- Piar Maria Valentina Ovalle Martinez Segundo Grado Primer Periodo 2023Documento5 páginasPiar Maria Valentina Ovalle Martinez Segundo Grado Primer Periodo 2023Claudia Esperanza Lopez PinzonAún no hay calificaciones
- Estructura de codigosDocumento7 páginasEstructura de codigosalexander recaldeAún no hay calificaciones
- Clase 2 - Business IntelligenceDocumento30 páginasClase 2 - Business IntelligenceValdés LorenaAún no hay calificaciones
- RDocumento2 páginasRJhon FigueroaAún no hay calificaciones
- Intro to Data Engineering Course Completed by JH ON VIDAL F IGUEROA C ESPEDESDocumento1 páginaIntro to Data Engineering Course Completed by JH ON VIDAL F IGUEROA C ESPEDESJhon FigueroaAún no hay calificaciones
- ChungaSilvio Tesis Maestria 2020Documento75 páginasChungaSilvio Tesis Maestria 2020Jhon FigueroaAún no hay calificaciones
- Manual - Pago ElectrónicoDocumento4 páginasManual - Pago ElectrónicoJhon FigueroaAún no hay calificaciones
- File 3Documento1 páginaFile 3Jhon FigueroaAún no hay calificaciones
- Macro ResearchDocumento2 páginasMacro ResearchJhon FigueroaAún no hay calificaciones
- Seguro médico integral para perrosDocumento144 páginasSeguro médico integral para perrosJhon FigueroaAún no hay calificaciones
- Detalle de viaje en autobús con todos los detalles del boletoDocumento1 páginaDetalle de viaje en autobús con todos los detalles del boletoJhon FigueroaAún no hay calificaciones
- Java ScriptDocumento2 páginasJava ScriptJhon FigueroaAún no hay calificaciones
- SQLDocumento12 páginasSQLJhon FigueroaAún no hay calificaciones
- Report 1Documento7 páginasReport 1Jhon FigueroaAún no hay calificaciones
- Report 1Documento7 páginasReport 1Jhon FigueroaAún no hay calificaciones
- Programa de Especializacion en POWER BI - Social Data ConsultingDocumento14 páginasPrograma de Especializacion en POWER BI - Social Data ConsultingJhon FigueroaAún no hay calificaciones
- Modelos Ciclos Económicos RealesDocumento4 páginasModelos Ciclos Económicos RealesJhon FigueroaAún no hay calificaciones
- Macro Dinamica RBC Syllabus PDFDocumento4 páginasMacro Dinamica RBC Syllabus PDFJhon FigueroaAún no hay calificaciones
- Modelamiento Financiero con Crystal Ball - Portafolio de 3 accionesDocumento1 páginaModelamiento Financiero con Crystal Ball - Portafolio de 3 accionesJhon FigueroaAún no hay calificaciones
- PtpiedraDocumento19 páginasPtpiedraJhon FigueroaAún no hay calificaciones
- Gestión de La Calidad Del Proyecto PDFDocumento68 páginasGestión de La Calidad Del Proyecto PDFJhon FigueroaAún no hay calificaciones
- Ficha de Resumen CurricularDocumento2 páginasFicha de Resumen CurricularJhon FigueroaAún no hay calificaciones
- Derivados Financieros PDFDocumento51 páginasDerivados Financieros PDFJhon FigueroaAún no hay calificaciones
- Bases Concurso de Practicas N°003 - 2019 - Planeamiento 2daDocumento8 páginasBases Concurso de Practicas N°003 - 2019 - Planeamiento 2daJhon FigueroaAún no hay calificaciones
- HHJDocumento3 páginasHHJJhon FigueroaAún no hay calificaciones
- CarsDocumento2 páginasCarsLady Diane EstoniloAún no hay calificaciones
- Impactos de La Crisis Financiera en LatinoamericaDocumento38 páginasImpactos de La Crisis Financiera en LatinoamericaLuis Alejandro FernandezAún no hay calificaciones
- Taller 3 Guia Diagnostico Tesis de SotoDocumento19 páginasTaller 3 Guia Diagnostico Tesis de SotoJhon FigueroaAún no hay calificaciones
- Analisis de La Macro-Region NorteDocumento2 páginasAnalisis de La Macro-Region NorteJhon FigueroaAún no hay calificaciones
- Ficha de InscripcionDocumento1 páginaFicha de InscripcionJhon FigueroaAún no hay calificaciones
- El Llamamiento de GedeónDocumento2 páginasEl Llamamiento de GedeónJemina Emilia Roca SalazarAún no hay calificaciones
- Resumen Informe Téc. Todo El AñoDocumento49 páginasResumen Informe Téc. Todo El AñoAndrea Johana Mahecha AcostaAún no hay calificaciones
- Temario Del Curso de UltrasonidoDocumento2 páginasTemario Del Curso de UltrasonidoJesus R. AguileraAún no hay calificaciones
- Bases Del Proceso de Seleccion de Tecnicos - As de Sistemas Referencia JN 052023 123962Documento11 páginasBases Del Proceso de Seleccion de Tecnicos - As de Sistemas Referencia JN 052023 123962Javi MillanAún no hay calificaciones
- Calculo Taller LimDocumento6 páginasCalculo Taller LimMaidyyulieth sanchez cuellarAún no hay calificaciones
- Foro #3Documento4 páginasForo #3MARTINNA ALDANA CHAVARROAún no hay calificaciones
- Integrantes: Camila Romero Bastian Saavedra Claudia Valdebenito Gabriel Villarroel Rodrigo VinesDocumento3 páginasIntegrantes: Camila Romero Bastian Saavedra Claudia Valdebenito Gabriel Villarroel Rodrigo Vinesnicole pobleteAún no hay calificaciones
- Perez Gollan, Nastri PolitisDocumento4 páginasPerez Gollan, Nastri PolitissilviaAún no hay calificaciones
- Capitulo I ZUMDocumento28 páginasCapitulo I ZUMMatamoros De La Cruz JorgeAún no hay calificaciones
- 0123 9392 Inf 24 03 s1 186 PDFDocumento123 páginas0123 9392 Inf 24 03 s1 186 PDFJuliethAún no hay calificaciones
- Catalogo - Sellos Quimicos MODELODocumento2 páginasCatalogo - Sellos Quimicos MODELOJors SanzAún no hay calificaciones
- 810 2550 00A - EspDocumento319 páginas810 2550 00A - EspJohn Edwin Arboleda CaicedoAún no hay calificaciones
- ACTADocumento8 páginasACTADANIELA MABEL CHOQUECONDO ASPILCUETAAún no hay calificaciones
- PKS08 - Ficha TecnicaDocumento8 páginasPKS08 - Ficha TecnicaAna CondeAún no hay calificaciones
- Interes CompuestoDocumento10 páginasInteres CompuestoALEX RONALDO BUENO CABOSAún no hay calificaciones
- Juan Dorado Romero REP157Documento30 páginasJuan Dorado Romero REP157Juan DoradoAún no hay calificaciones
- PLC1101 202 Actividad 2Documento38 páginasPLC1101 202 Actividad 2valentina urrutiaAún no hay calificaciones
- Batalla de YrendagüéDocumento13 páginasBatalla de Yrendagüéjuancarlosmp54Aún no hay calificaciones
- Trabajo 3 - Sandra DíazDocumento30 páginasTrabajo 3 - Sandra DíazJulieth DíazAún no hay calificaciones
- Follari 2Documento10 páginasFollari 2Andres CastillejosAún no hay calificaciones
- HBF - Incmnsz - Dolor Ago 2019 FinalDocumento45 páginasHBF - Incmnsz - Dolor Ago 2019 Finaljem bistreAún no hay calificaciones
- Examen de Psicologia Del Deporte Tu Esposa No BorrarDocumento4 páginasExamen de Psicologia Del Deporte Tu Esposa No BorrarLuis Fernando Tipan VergaraAún no hay calificaciones
- Entre Dos Pandemias Influenza y El Covid-19Documento23 páginasEntre Dos Pandemias Influenza y El Covid-19Miguel G.nAún no hay calificaciones
- Oscar MartínezDocumento2 páginasOscar MartínezoscarormeAún no hay calificaciones
- Hoja de Vida Del BrigadistaDocumento3 páginasHoja de Vida Del BrigadistaMANUELAún no hay calificaciones
- O y S FlujogramaDocumento5 páginasO y S FlujogramaDaniela Isabel Solano VargasAún no hay calificaciones