También podría gustarte
- Graficos EstadisticosDocumento18 páginasGraficos EstadisticoslauraAún no hay calificaciones
- Modulo 2 de Excel - GraficosDocumento19 páginasModulo 2 de Excel - Graficosa b r i l vmAún no hay calificaciones
- Elementos de estadística para ingeniería: Un curso básicoDe EverandElementos de estadística para ingeniería: Un curso básicoAún no hay calificaciones
- Tabla de Datos y Graficos EstadisticosDocumento10 páginasTabla de Datos y Graficos Estadisticoscesar casani huamanAún no hay calificaciones
- Representaciones GraficasDocumento13 páginasRepresentaciones GraficasSantiago Matias Linares PostigoAún no hay calificaciones
- Diferentes Formas de Visualizar Los DatosDocumento3 páginasDiferentes Formas de Visualizar Los Datosandres tovarAún no hay calificaciones
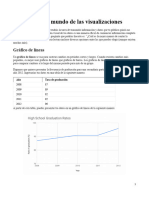
- El Maravilloso Mundo de Las VisualizacionesDocumento6 páginasEl Maravilloso Mundo de Las VisualizacionesNicolás Juri MalakAún no hay calificaciones
- 5 Los Más Utilizadoss-Gráficos de Barra y LíneasDocumento12 páginas5 Los Más Utilizadoss-Gráficos de Barra y LíneasEdgar CárdenasAún no hay calificaciones
- Cuaderno Del EstudianteDocumento23 páginasCuaderno Del EstudianteADITEC HOGARAún no hay calificaciones
- Qué Es La BioestadísticaDocumento14 páginasQué Es La BioestadísticaBrahian CastañoAún no hay calificaciones
- PalaciovicentecontenidosDocumento9 páginasPalaciovicentecontenidosAndrea PalacioAún no hay calificaciones
- Foro 1 Que Es La EstadisticaDocumento5 páginasForo 1 Que Es La EstadisticaPAOLAAún no hay calificaciones
- Tarea 2 de Estadistica IDocumento12 páginasTarea 2 de Estadistica IOdalis HernandezAún no hay calificaciones
- GRAFICOS 2020 IcestDocumento8 páginasGRAFICOS 2020 IcestPatric PatricAún no hay calificaciones
- Gráfico EstadísticoDocumento11 páginasGráfico EstadísticoJuan Jose Portocarrero IzquierdoAún no hay calificaciones
- Gráficos EstadísticosDocumento14 páginasGráficos EstadísticosJuan Jose Portocarrero IzquierdoAún no hay calificaciones
- GraficasDocumento6 páginasGraficasitzelitagomezc.2006Aún no hay calificaciones
- Tarea No.1Documento9 páginasTarea No.1Andrea BarillasAún no hay calificaciones
- EstadisticaDocumento15 páginasEstadisticaJosué FunesAún no hay calificaciones
- HistogramaDocumento6 páginasHistogramaFernando MichuaAún no hay calificaciones
- Estadistica GeneralDocumento7 páginasEstadistica Generalsusana maria hernandez urdanetaAún no hay calificaciones
- Graficas 22-3Documento22 páginasGraficas 22-3William Josue MartinezAún no hay calificaciones
- Tablas de Frecuencias para Datos Agrupados y EjemplosDocumento8 páginasTablas de Frecuencias para Datos Agrupados y EjemplosDIEGO ZARAZAAún no hay calificaciones
- CLASE. Análisis Exploratorio de Datos, Uso de Gráficos.Documento12 páginasCLASE. Análisis Exploratorio de Datos, Uso de Gráficos.perezdyana610Aún no hay calificaciones
- Foro Tematico Del Curso Calidad TotalDocumento10 páginasForo Tematico Del Curso Calidad TotalCesar SMAún no hay calificaciones
- SAS-Tecnicas de Visualización de DatosDocumento26 páginasSAS-Tecnicas de Visualización de DatosMauro Pinilla Soto100% (1)
- Tarea 1 EstadisticaDocumento12 páginasTarea 1 EstadisticaJennifer CastilloAún no hay calificaciones
- Preguntas de Investigación y Tipos de GráficasDocumento49 páginasPreguntas de Investigación y Tipos de Gráficasunai.casadoAún no hay calificaciones
- Qué Es Un Gráfico EstadísticoDocumento12 páginasQué Es Un Gráfico EstadísticoLUIS ALFREDO APAZA POMAAún no hay calificaciones
- Graficos EstadisticosDocumento17 páginasGraficos EstadisticosBertaAún no hay calificaciones
- Comportamiento de Dos Variables.Documento15 páginasComportamiento de Dos Variables.Jose Garcia100% (2)
- Investigación Las Gráficas Como Herramientas de Análisis Económico M. Vega 8-985-3Documento9 páginasInvestigación Las Gráficas Como Herramientas de Análisis Económico M. Vega 8-985-3JoseAún no hay calificaciones
- 02 Descriptive-Statistics - EsDocumento2 páginas02 Descriptive-Statistics - Essankhasubhra mandalAún no hay calificaciones
- Grafico Manual de Datos EstadísticosDocumento16 páginasGrafico Manual de Datos EstadísticosjhonatanAún no hay calificaciones
- ESTADISTICADocumento6 páginasESTADISTICAPIXELART SJAún no hay calificaciones
- Tarea GraficosDocumento5 páginasTarea GraficosMDLR YTAún no hay calificaciones
- Tablas y Graficos Dimanicos.1docxDocumento8 páginasTablas y Graficos Dimanicos.1docxmorales28.paolaAún no hay calificaciones
- Graficacion PDFDocumento7 páginasGraficacion PDFDanny ILAún no hay calificaciones
- Modulo 3Documento31 páginasModulo 3Pablo CanestaAún no hay calificaciones
- Modulo 1 Ciencia de DatosDocumento11 páginasModulo 1 Ciencia de Datosstevenespinoza902Aún no hay calificaciones
- Tarea 3 Control y CalidadDocumento10 páginasTarea 3 Control y CalidadYelitza Santana100% (1)
- Estadística para NegociosDocumento12 páginasEstadística para NegociosLeonardo LinaresAún no hay calificaciones
- Guion de Clases de Graficas para Sexto GradoDocumento2 páginasGuion de Clases de Graficas para Sexto GradoWilliams Efrain HernandezAún no hay calificaciones
- Los Gráficos en GeografíaDocumento3 páginasLos Gráficos en GeografíaDocum clasAún no hay calificaciones
- Tipos de Graficas EstadisticasDocumento2 páginasTipos de Graficas EstadisticasJESSIAún no hay calificaciones
- Clase 3 Las Graficas Como Herramientas de Análisis EconomicoDocumento10 páginasClase 3 Las Graficas Como Herramientas de Análisis EconomicoJehanAún no hay calificaciones
- Aplicaciones de Las Graficas en Las Ramas D Ela Ingenieria.Documento17 páginasAplicaciones de Las Graficas en Las Ramas D Ela Ingenieria.Erick NavarreteAún no hay calificaciones
- Videotest 2Documento2 páginasVideotest 2juan diego chirito salvatierraAún no hay calificaciones
- Actividad 5 Gráficos EstadísticosDocumento39 páginasActividad 5 Gráficos EstadísticosEmilio Vázquez PonceAún no hay calificaciones
- GRAFICASDocumento12 páginasGRAFICASCINTHYA CAROLYN PEREZ PECHAún no hay calificaciones
- Cápsula 2crear Un Gráfico de Principio A FinDocumento15 páginasCápsula 2crear Un Gráfico de Principio A FinAlison Nieto HernandezAún no hay calificaciones
- Recurso 1 - Qué Tipo de Gráfico Utilizar para Presentar DatosDocumento7 páginasRecurso 1 - Qué Tipo de Gráfico Utilizar para Presentar DatosGerson GodoyAún no hay calificaciones
- MAECDocumento8 páginasMAECSantiago BasabesAún no hay calificaciones
- Estadistica DescriptivaDocumento14 páginasEstadistica DescriptivaAaron Quiroa ReyesAún no hay calificaciones
- POBLACIÓNDocumento6 páginasPOBLACIÓNEdgar Antonio Berduo GomezAún no hay calificaciones
- GraficasDocumento7 páginasGraficasyulianagarciayg8637164Aún no hay calificaciones
- Qué Son Los Diagramas de BarrasDocumento7 páginasQué Son Los Diagramas de BarrasLadys Sierva DE JehovaAún no hay calificaciones
- HISTOGRAMADocumento9 páginasHISTOGRAMAMario CasasolaAún no hay calificaciones
- Graficos VisualesDocumento9 páginasGraficos VisualesKiaraAún no hay calificaciones
- Esta Di SticaDocumento13 páginasEsta Di SticaDaniela HerreraAún no hay calificaciones
- Mecanica de Fractura Lineal - Elastica - 1Documento12 páginasMecanica de Fractura Lineal - Elastica - 1Leonardo MartinettoAún no hay calificaciones
- Mina CondestableDocumento35 páginasMina CondestableJAVIER ZETA PAZAún no hay calificaciones
- Informe Final de Practicas UacDocumento44 páginasInforme Final de Practicas UacJOSE RODRIGO GUILLEN VARGASAún no hay calificaciones
- Pobreza FinalDocumento26 páginasPobreza FinalVanesaAún no hay calificaciones
- Practica 4 Lab - Fisica4Documento8 páginasPractica 4 Lab - Fisica4Erick RodriguezAún no hay calificaciones
- Taller de Refuerzo de Español Grado 3°Documento2 páginasTaller de Refuerzo de Español Grado 3°Gerson Salgado100% (1)
- Pdu Version Abreviada Periodico OficialDocumento24 páginasPdu Version Abreviada Periodico OficialChelis FernándezAún no hay calificaciones
- Caso Relaciones PublicasDocumento3 páginasCaso Relaciones PublicasDaniel Morán YepesAún no hay calificaciones
- Q Ecologico 2020Documento70 páginasQ Ecologico 2020Carlos GarciaAún no hay calificaciones
- Endosimbiosis SeriadaDocumento2 páginasEndosimbiosis SeriadaSergio Adrian Lazo HernanadezAún no hay calificaciones
- Exposición de Siderurgia 2022Documento16 páginasExposición de Siderurgia 2022Meday BaltodanoAún no hay calificaciones
- 1auditoria Realizapa Por Orlando Gallego BedoyaDocumento6 páginas1auditoria Realizapa Por Orlando Gallego Bedoyalacobus galicino100% (1)
- Inicial Niños de 5 Años ProgramaDocumento18 páginasInicial Niños de 5 Años ProgramaEmperor GgAún no hay calificaciones
- Mecanica Icfes PDFDocumento5 páginasMecanica Icfes PDFLelio Antonio Alzate MoraAún no hay calificaciones
- Esquema Desarrollo Evolutivo NiñosDocumento4 páginasEsquema Desarrollo Evolutivo NiñosLety GonzálezAún no hay calificaciones
- Hearing and Testing Pediatric Brochure SpanishDocumento3 páginasHearing and Testing Pediatric Brochure Spanishdianita.garpil27Aún no hay calificaciones
- Cinematica InversaDocumento3 páginasCinematica InversaJose Ignacio Lopez AlmanzaAún no hay calificaciones
- Modulo 1 (Preparar Soluciones)Documento19 páginasModulo 1 (Preparar Soluciones)Olivares Pérez José SamuelAún no hay calificaciones
- La Ceramica en El Arte Griego - Historia Del Arte en ResumenDocumento5 páginasLa Ceramica en El Arte Griego - Historia Del Arte en ResumenXimena GattoAún no hay calificaciones
- Informe de EclimetroDocumento10 páginasInforme de EclimetroDennith Gersonn Caruajulca BernalAún no hay calificaciones
- Implementación de Un Sitema de Gestiíon Ambiental para La Empresa Constructora Ahec SRL Basado en La Norma Iso 14001Documento7 páginasImplementación de Un Sitema de Gestiíon Ambiental para La Empresa Constructora Ahec SRL Basado en La Norma Iso 14001MaryAún no hay calificaciones
- Retroalimentación Del AprendizajeDocumento8 páginasRetroalimentación Del AprendizajeGeorges El Grande100% (3)
- VIOLA-GE y G PDocumento57 páginasVIOLA-GE y G PSamuel BastidasAún no hay calificaciones
- 1975 WorkDocumento2 páginas1975 WorkSEBASTIÁN MÉNDEZ BADILLOAún no hay calificaciones
- Alegato de Apertura de La DefensaDocumento2 páginasAlegato de Apertura de La DefensaIvaan AndradeAún no hay calificaciones
- Ejercicios de Autocovarianza y Modelo MA Series de TiempoDocumento5 páginasEjercicios de Autocovarianza y Modelo MA Series de TiempoGENIX LONARDI CANTA ALVISAún no hay calificaciones
- Alvaro Figueroa COntrol3Documento9 páginasAlvaro Figueroa COntrol3Alvaro Figueroa100% (2)
- Práctica 2 - Análisis Cuantitativo y Cualitativo Del MovimientoDocumento6 páginasPráctica 2 - Análisis Cuantitativo y Cualitativo Del MovimientoAnna ReAún no hay calificaciones
- Latex Tablas Apuntes10Documento12 páginasLatex Tablas Apuntes10Jose VIadimirAún no hay calificaciones
- Caracterizacion y Propiedades de Los GruposDocumento4 páginasCaracterizacion y Propiedades de Los Grupossara sotoAún no hay calificaciones