También podría gustarte
- 210215005836-01 Introduccion Al Procesamiento Subsimbolico v3Documento44 páginas210215005836-01 Introduccion Al Procesamiento Subsimbolico v3Christopher OOAún no hay calificaciones
- ICARO - Deep Learning Con KerasDocumento9 páginasICARO - Deep Learning Con KerasMartin IglesiasAún no hay calificaciones
- Contenido TemáticoDocumento32 páginasContenido Temáticoeduardo_benitez_18Aún no hay calificaciones
- E Big Data IaDocumento5 páginasE Big Data IaWalter CambaAún no hay calificaciones
- 0.parcelacion Microprocesadores (Remota)Documento6 páginas0.parcelacion Microprocesadores (Remota)Daniel PerezAún no hay calificaciones
- reconocimientofacialDeeplearningDocumento10 páginasreconocimientofacialDeeplearninggsamp707Aún no hay calificaciones
- PA - 0425404T - Fundamentos de Logica DigitalDocumento9 páginasPA - 0425404T - Fundamentos de Logica DigitalEdgar VasquezAún no hay calificaciones
- Guía Didáctica. Unidad 1Documento24 páginasGuía Didáctica. Unidad 1Pepin MacarenoAún no hay calificaciones
- Dinta Uc 07062023Documento9 páginasDinta Uc 07062023FotogonAún no hay calificaciones
- Deep LearningDocumento4 páginasDeep LearningCARLOS YAÑEZAún no hay calificaciones
- PythonDL Parte2Documento144 páginasPythonDL Parte2MariaOtiliaCañonAún no hay calificaciones
- VVDocumento24 páginasVVFernando Solana ClementeAún no hay calificaciones
- Intro DL: Aprendizaje ProfundoDocumento8 páginasIntro DL: Aprendizaje ProfundoGABRIEL EDUARDO DEL CARPIO VILLAFUERTEAún no hay calificaciones
- TEB-2102 Inteligencia Artificial IIDocumento10 páginasTEB-2102 Inteligencia Artificial IIJose Luis Perez ResendizAún no hay calificaciones
- Carreras TI CibertecDocumento5 páginasCarreras TI CibertecAfritt TerronesAún no hay calificaciones
- Diploma Inteligencia Artificial PUCDocumento8 páginasDiploma Inteligencia Artificial PUCPatricioAún no hay calificaciones
- Documento Inteligencia ArtificialDocumento19 páginasDocumento Inteligencia ArtificialKarencita LicoAún no hay calificaciones
- ProgramaciónDocumento20 páginasProgramaciónJonathan AndradeAún no hay calificaciones
- Navegación visual robot Deep LearningDocumento133 páginasNavegación visual robot Deep LearningPandyllaAún no hay calificaciones
- Algebra Lineal-Trabajo Colaborativo - p1Documento4 páginasAlgebra Lineal-Trabajo Colaborativo - p1Daniel Fontal fontaldanielAún no hay calificaciones
- Temario DL FISDocumento2 páginasTemario DL FISplotus4Aún no hay calificaciones
- Derecho Comercial Profesor Rafael GómezDocumento116 páginasDerecho Comercial Profesor Rafael GómezIngrid Bravo LlamatantaAún no hay calificaciones
- Dis 988918 Proyecto de Realidad Virtual InmersivaDocumento7 páginasDis 988918 Proyecto de Realidad Virtual InmersivaZamoOritaRamirezOmarciitoAún no hay calificaciones
- BLOQUE 2 - Deep LearnigDocumento26 páginasBLOQUE 2 - Deep LearnigRaul JasoAún no hay calificaciones
- PythonDL Parte1Documento94 páginasPythonDL Parte1MariaOtiliaCañonAún no hay calificaciones
- Silabo de Tecnología de Multimedia, y Realidad VirtualDocumento3 páginasSilabo de Tecnología de Multimedia, y Realidad VirtualChristian Renato Espinoza GallangosAún no hay calificaciones
- Aprende Inteligencia Artificial con Jetson NanoDocumento4 páginasAprende Inteligencia Artificial con Jetson NanoCarlos Mamani HuisaAún no hay calificaciones
- Inteligencia ArtificialDocumento6 páginasInteligencia ArtificialnicolasAún no hay calificaciones
- FundamentosdeProgramacionConPython Semana 1Documento83 páginasFundamentosdeProgramacionConPython Semana 1pedroAún no hay calificaciones
- Topología de redesDocumento3 páginasTopología de redesAxel XG100% (1)
- Inteligencia Artificial - Procesos 2Documento11 páginasInteligencia Artificial - Procesos 2Jhon Alexander Zagaceta DazaAún no hay calificaciones
- Plan de La Clase Semana 2Documento3 páginasPlan de La Clase Semana 2claudia castellaniAún no hay calificaciones
- Silabo Prog 232 Industrial UNPDocumento8 páginasSilabo Prog 232 Industrial UNPwilmersilvapaico97Aún no hay calificaciones
- TEMA 1 - Introducción A Las Redes NeuronalesDocumento9 páginasTEMA 1 - Introducción A Las Redes NeuronalesJuan SánchezAún no hay calificaciones
- Algoritmia y Estructura de DatosDocumento128 páginasAlgoritmia y Estructura de DatosJeymis P. De la Cruz Palacios0% (1)
- I. Datos InformativosDocumento8 páginasI. Datos InformativosJamer Moisés Delgado PérezAún no hay calificaciones
- Sílabo IoT 2023-2Documento8 páginasSílabo IoT 2023-2Erick PeñafielAún no hay calificaciones
- PLAN DE CLASE - Micro DOCENCIADocumento2 páginasPLAN DE CLASE - Micro DOCENCIAZoila Beatriz Sumalé BuezoAún no hay calificaciones
- DIS141400 InfodiseñoDocumento7 páginasDIS141400 InfodiseñoGladiz LoyolaAún no hay calificaciones
- Formato General Silabo-Sunedu ArquitecturaDocumento5 páginasFormato General Silabo-Sunedu ArquitecturaJuan Perez ArizavalAún no hay calificaciones
- Inteligencia ArtificialDocumento36 páginasInteligencia ArtificialÁmbar Talia GuzmánAún no hay calificaciones
- Silabo de MicroprocesadoresDocumento7 páginasSilabo de MicroprocesadoresI.e. Agropecuario Naranjillo NaranjilloAún no hay calificaciones
- Clase 5 - Redes NeuronalesDocumento22 páginasClase 5 - Redes NeuronalesmagonzalezAún no hay calificaciones
- Clase 01 SistInt Clase 01Documento29 páginasClase 01 SistInt Clase 01Marx GalvezAún no hay calificaciones
- Deep LearningDocumento5 páginasDeep LearningFELIPE CALDERON VACCAAún no hay calificaciones
- Syllabus Procesamiento Digital de SeñalesDocumento6 páginasSyllabus Procesamiento Digital de SeñalesSteven RoseroAún no hay calificaciones
- Programador Junior en Machine LearningDocumento3 páginasProgramador Junior en Machine LearningodcardozoAún no hay calificaciones
- Arquitectura de Computadoras PDFDocumento11 páginasArquitectura de Computadoras PDFLuis Fernando Ruiz AvilaAún no hay calificaciones
- Portafolio de EvidenciasDocumento54 páginasPortafolio de Evidenciasenelsam am0% (1)
- Sesion I de Computación 5to GradoDocumento1 páginaSesion I de Computación 5to GradoJaime ChafloqueAún no hay calificaciones
- E Big Data IaDocumento3 páginasE Big Data IaValeria Flores GuanínAún no hay calificaciones
- Sistemas de Inspeccion Inteligente IsmacDocumento181 páginasSistemas de Inspeccion Inteligente IsmacJefferson PichuchoAún no hay calificaciones
- Conceptos de Arquitectura de ComputadorasDocumento5 páginasConceptos de Arquitectura de ComputadorasPedro Antonio MendozaAún no hay calificaciones
- Trabajo ....Documento36 páginasTrabajo ....Ambar GuzmanAún no hay calificaciones
- Tututorial VRML97 2ºDocumento35 páginasTututorial VRML97 2ºDennison Romero SerranoAún no hay calificaciones
- TIC - II Segundo SemestreDocumento8 páginasTIC - II Segundo SemestreAbrahn Hdez MilAún no hay calificaciones
- OK - Syllabus Elementos de Computacion II 2006Documento40 páginasOK - Syllabus Elementos de Computacion II 2006David E. Mendoza GutierrezAún no hay calificaciones
- Programación I Syllabus UDABOLDocumento42 páginasProgramación I Syllabus UDABOLSusana DiazAún no hay calificaciones
- Manual 2022 04 Maqueteria Virtual y Render (SP4471)Documento99 páginasManual 2022 04 Maqueteria Virtual y Render (SP4471)JOSEET AARON ORLANDO ROJAS ORTIZAún no hay calificaciones
- Deep Learning: Teoría y aplicacionesDe EverandDeep Learning: Teoría y aplicacionesCalificación: 5 de 5 estrellas5/5 (1)
- Interfaces Camaras Digitales PDFDocumento28 páginasInterfaces Camaras Digitales PDFVJN1109Aún no hay calificaciones
- Planificación de Trayectorias para El Control Autónomo de Un Cuadricóptero Utilizando Técnicas de Visión Artificial y Aprendizaje ProfundoDocumento134 páginasPlanificación de Trayectorias para El Control Autónomo de Un Cuadricóptero Utilizando Técnicas de Visión Artificial y Aprendizaje ProfundoScarllet Osuna TostadoAún no hay calificaciones
- Lsgonzález TFG Ic 2021Documento79 páginasLsgonzález TFG Ic 2021Scarllet Osuna TostadoAún no hay calificaciones
- Diseño Mecatrónico: Evaluación de mapa conceptual y tablaDocumento1 páginaDiseño Mecatrónico: Evaluación de mapa conceptual y tablaScarllet Osuna TostadoAún no hay calificaciones
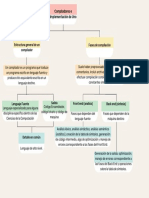
- Mapa Conceptual Sobre Compiladores e Implementación de UnoDocumento1 páginaMapa Conceptual Sobre Compiladores e Implementación de UnoScarllet Osuna TostadoAún no hay calificaciones
- Apa 7Documento48 páginasApa 7Adriana Carolina Rodriguez HerreraAún no hay calificaciones
- Control DigitalDocumento17 páginasControl DigitalScarllet Osuna TostadoAún no hay calificaciones
- Tarea 2Documento1 páginaTarea 2Scarllet Osuna TostadoAún no hay calificaciones
- T1 - Edo Actual MecatrónicaDocumento11 páginasT1 - Edo Actual MecatrónicaScarllet Osuna TostadoAún no hay calificaciones
- Mapa Conceptual Sobre Desarrollo de SistemasDocumento3 páginasMapa Conceptual Sobre Desarrollo de SistemasScarllet Osuna TostadoAún no hay calificaciones
- Dis Mec U1Documento22 páginasDis Mec U1Scarllet Osuna TostadoAún no hay calificaciones
- Morfologia de Los RobotDocumento27 páginasMorfologia de Los RobotAlejandro C. GamundiAún no hay calificaciones
- Home Carpeta PDF MANUAL APA ULACIT Actualizado 2012Documento11 páginasHome Carpeta PDF MANUAL APA ULACIT Actualizado 2012Edgar GonzalezAún no hay calificaciones
- T1 U1 EdoActualDocumento1 páginaT1 U1 EdoActualScarllet Osuna TostadoAún no hay calificaciones
- T2 U1 Descrip Sist MecDocumento1 páginaT2 U1 Descrip Sist MecScarllet Osuna TostadoAún no hay calificaciones
- Normas ASTM en EspañolDocumento161 páginasNormas ASTM en Españolbryan JavierAún no hay calificaciones
- Manufactura de Materiales CompuestosDocumento30 páginasManufactura de Materiales Compuestoseduardos9500Aún no hay calificaciones
- Propiedades FísicasDocumento11 páginasPropiedades FísicasScarllet Osuna TostadoAún no hay calificaciones
- Dureza Tension ImpactoDocumento27 páginasDureza Tension ImpactoErick ArimAún no hay calificaciones
- Dialnet OptimizacionDePropiedadesMecanicasYTermicasDeUnAgl 3198662 PDFDocumento16 páginasDialnet OptimizacionDePropiedadesMecanicasYTermicasDeUnAgl 3198662 PDFAnyiAún no hay calificaciones
- Tarea3 U1 DesgloseComponentesDocumento1 páginaTarea3 U1 DesgloseComponentesScarllet Osuna TostadoAún no hay calificaciones
- Transmision Del MovimientoDocumento12 páginasTransmision Del MovimientoIvette RamírezAún no hay calificaciones
- Propiedades MecánicasDocumento16 páginasPropiedades MecánicasScarllet Osuna TostadoAún no hay calificaciones
- Propiedades Físicas y MecanicasDocumento58 páginasPropiedades Físicas y MecanicasJorge Moya RzAún no hay calificaciones
- Sensor EsDocumento26 páginasSensor EsScarllet Osuna TostadoAún no hay calificaciones
- T3 - Desglose de ComponentesDocumento7 páginasT3 - Desglose de ComponentesScarllet Osuna TostadoAún no hay calificaciones
- T2 - Lista de CotejoDocumento1 páginaT2 - Lista de CotejoScarllet Osuna TostadoAún no hay calificaciones
- t1 - Actualización de RobotsDocumento6 páginast1 - Actualización de RobotsScarllet Osuna TostadoAún no hay calificaciones
- Unidad 1Documento24 páginasUnidad 1Scarllet Osuna TostadoAún no hay calificaciones
- Paper de Redes NeuronalesDocumento9 páginasPaper de Redes NeuronalesErnesto VarelaAún no hay calificaciones
- Examen FinalDocumento3 páginasExamen FinalVictor Junco RenteraAún no hay calificaciones
- Redes Neuronales ArtificialesDocumento57 páginasRedes Neuronales ArtificialesJuanAún no hay calificaciones
- Como La IA Influye en La Ingeniería ElectrónicaDocumento2 páginasComo La IA Influye en La Ingeniería ElectrónicaRocio Carolina BernalAún no hay calificaciones
- Mapas Autoorganizados de KohonenDocumento9 páginasMapas Autoorganizados de KohonenRichard PolonioAún no hay calificaciones
- Resumen Redes NeuronalesDocumento25 páginasResumen Redes NeuronalesJOSE SALOMON CHAMBI GUTIERREZ50% (2)
- Proyecto TesisDocumento8 páginasProyecto TesisLulu LuluAún no hay calificaciones
- Desarrrollo de Una Base de Análisis de Datos. BioinformáticaDocumento51 páginasDesarrrollo de Una Base de Análisis de Datos. BioinformáticaLuis Alberto Marín AguilarAún no hay calificaciones
- IA Introducción a la inteligencia artificialDocumento47 páginasIA Introducción a la inteligencia artificialErika Vazquez100% (1)
- Inteligencia Artificial y Machine LearningDocumento9 páginasInteligencia Artificial y Machine LearningLuis Land AngelulandAún no hay calificaciones
- Unidad 3 - AdalineDocumento19 páginasUnidad 3 - AdalineMarlon Alexis Plúas GuamánAún no hay calificaciones
- Folleto Dua Cenarec 2019 PDFDocumento18 páginasFolleto Dua Cenarec 2019 PDFLeonardo Pinet Acosta100% (2)
- Ejemploaterrizado WEKADocumento18 páginasEjemploaterrizado WEKARosita DiazAún no hay calificaciones
- Investigación: Redes Neuronales ArtificialesDocumento8 páginasInvestigación: Redes Neuronales ArtificialesMateo ChuquimarcaAún no hay calificaciones
- Documento Inteligencia ArtificialDocumento19 páginasDocumento Inteligencia ArtificialKarencita LicoAún no hay calificaciones
- UTP-SRN-SL1 Funciones de Rna PDFDocumento15 páginasUTP-SRN-SL1 Funciones de Rna PDFcarlosandresdavidbueAún no hay calificaciones
- Introduccion A Los DCSDocumento43 páginasIntroduccion A Los DCSalgrone666Aún no hay calificaciones
- Avances en Ciencias e Ingeniería Diciembre 2014Documento183 páginasAvances en Ciencias e Ingeniería Diciembre 2014jaimepaezvAún no hay calificaciones
- Modelos de Relación CultivoDocumento3 páginasModelos de Relación CultivoGabriel Villagran PereaAún no hay calificaciones
- Informe Adeline Perceptron MulticapaDocumento13 páginasInforme Adeline Perceptron MulticapaJhoselyn Jara EspinozaAún no hay calificaciones
- Unidad III. Redes NeuronalesDocumento7 páginasUnidad III. Redes NeuronalesAgustinaDiazAún no hay calificaciones
- Diseño de un pequeño robot humanoide y control mediante redes neuronales en CPLDDocumento111 páginasDiseño de un pequeño robot humanoide y control mediante redes neuronales en CPLDJosé Alfredo Macario Castillo MendozaAún no hay calificaciones
- Representaciones MentalesDocumento53 páginasRepresentaciones Mentalesandresjensen26Aún no hay calificaciones
- Simulación Por Eventos Discretos PDFDocumento15 páginasSimulación Por Eventos Discretos PDFJoeAdamsArrietaAún no hay calificaciones
- Métodos Minería DatosDocumento5 páginasMétodos Minería DatosHector RojasAún no hay calificaciones
- Ensayo Sobre Casos Prácticos en La Neumática e HidráulicaDocumento56 páginasEnsayo Sobre Casos Prácticos en La Neumática e HidráulicaJuanje TL100% (1)
- Analisis de Algotirmos para La Prediccion de Hepatitits en WekaDocumento5 páginasAnalisis de Algotirmos para La Prediccion de Hepatitits en WekaErika AncoAún no hay calificaciones
- 07MIAR DeepLearning Texto Secuencias1Documento34 páginas07MIAR DeepLearning Texto Secuencias1Cooperacion ValleAún no hay calificaciones
- Sistema de pronóstico de ventas Pymes usando RNsDocumento156 páginasSistema de pronóstico de ventas Pymes usando RNsAndrés HAún no hay calificaciones
- TFMSantiago Sanchez Migallon Redes Neuronales Profundas 2020Documento69 páginasTFMSantiago Sanchez Migallon Redes Neuronales Profundas 2020yulieth galvisAún no hay calificaciones