También podría gustarte
- Procesamient o de Lenguaje Natural con Python: COMPUTADORASDe EverandProcesamient o de Lenguaje Natural con Python: COMPUTADORASAún no hay calificaciones
- Memoria e inteligencia. Guías para los laboratoriosDe EverandMemoria e inteligencia. Guías para los laboratoriosCalificación: 5 de 5 estrellas5/5 (1)
- Guía de Clase 4 - Iramuteq - 2020Documento5 páginasGuía de Clase 4 - Iramuteq - 2020Bside FitnessAún no hay calificaciones
- Análisis cualitativo de entrevistas con ATLAS.tiDocumento20 páginasAnálisis cualitativo de entrevistas con ATLAS.tiLore GarciaAún no hay calificaciones
- Análisis Documental Bibliográfico Con MAXQDA 2020Documento53 páginasAnálisis Documental Bibliográfico Con MAXQDA 2020Ali MartinezAún no hay calificaciones
- Foro 1 - Análisis de Datos de La Investigación SocialDocumento2 páginasForo 1 - Análisis de Datos de La Investigación SocialLorena MartínezAún no hay calificaciones
- Funciones 1111Documento3 páginasFunciones 1111Brayan Gonzáles RequejoAún no hay calificaciones
- Manual Estudiante U1 TallerdeAnalitica2Documento44 páginasManual Estudiante U1 TallerdeAnalitica2Christian Farnast ContardoAún no hay calificaciones
- HerTecInvApl LS7Documento15 páginasHerTecInvApl LS7YHON CORTESAún no hay calificaciones
- Spss InformeDocumento9 páginasSpss InformeGabriel QuirozAún no hay calificaciones
- Apuntes Tesis IDocumento2 páginasApuntes Tesis ILuisAún no hay calificaciones
- Los CAQDASDocumento6 páginasLos CAQDASHernan HerreraAún no hay calificaciones
- Elementos Basicos de SPSS. Poy y Rodr+¡guezDocumento14 páginasElementos Basicos de SPSS. Poy y Rodr+¡guezMiguel AngelAún no hay calificaciones
- Cuadernillo 2 InteractivoDocumento20 páginasCuadernillo 2 InteractivoJuanAún no hay calificaciones
- Tertulia N1 Normas APADocumento7 páginasTertulia N1 Normas APAtimoteo1986_46043411Aún no hay calificaciones
- Lenguajes y Autómatas 2: Análisis SemánticoDocumento16 páginasLenguajes y Autómatas 2: Análisis Semánticoflick360Aún no hay calificaciones
- Guia de Trabajo Del Silabo de Presupuesto Publico.Documento7 páginasGuia de Trabajo Del Silabo de Presupuesto Publico.Manuel Eduardo Alvarez AlvaradoAún no hay calificaciones
- Semana 1 - Programacion Avanzada IIDocumento5 páginasSemana 1 - Programacion Avanzada IIFelipe Jara AguilarAún no hay calificaciones
- ANÁLISIS DATOS BASE SPSSDocumento4 páginasANÁLISIS DATOS BASE SPSScinthya lopez89% (9)
- Infomes Guía PDFDocumento299 páginasInfomes Guía PDFEstefaníaAún no hay calificaciones
- Clasificacion de Los Textos Usando WikipediaDocumento14 páginasClasificacion de Los Textos Usando WikipediaAngel LRAún no hay calificaciones
- ¿Cómo Se Llevan A Cabo Los Análisis Estadísticos?Documento20 páginas¿Cómo Se Llevan A Cabo Los Análisis Estadísticos?Vazquez JorgeAún no hay calificaciones
- Taller Sobre Conocimiento Inherente en Los Modelos de LenguajeDocumento9 páginasTaller Sobre Conocimiento Inherente en Los Modelos de LenguajeJulian DiazAún no hay calificaciones
- TareasDocumento3 páginasTareasAdriana Diaz HernandezAún no hay calificaciones
- Diseñando Matrices y Redes para El Despliegue de Los DatosDocumento12 páginasDiseñando Matrices y Redes para El Despliegue de Los DatosmartinguelmanAún no hay calificaciones
- Protestas sociales generan cambiosDocumento7 páginasProtestas sociales generan cambiosJenni CastilloAún no hay calificaciones
- Guía para La Integración de EvidenciasDocumento8 páginasGuía para La Integración de EvidenciasMARIA DEL SOCORRO MENDOZAAún no hay calificaciones
- Componentes BDDocumento3 páginasComponentes BDaventura4689Aún no hay calificaciones
- Guia para Elaborar Análisis de ContenidoDocumento7 páginasGuia para Elaborar Análisis de ContenidoJesus R. Romero ManzanillaAún no hay calificaciones
- 311 - Base de Datos PDFDocumento108 páginas311 - Base de Datos PDFzurelysAún no hay calificaciones
- Tema 7Documento13 páginasTema 7ndelpozoAún no hay calificaciones
- Manual de Estadistica en ExcelDocumento41 páginasManual de Estadistica en ExcelMary TLAún no hay calificaciones
- Guia de Ejercicios SBD2Documento28 páginasGuia de Ejercicios SBD2julio cesar goza diasAún no hay calificaciones
- APA ProfundizaciónDocumento7 páginasAPA ProfundizaciónCesar PinillaAún no hay calificaciones
- Tarea 7 Andres ArcosDocumento9 páginasTarea 7 Andres Arcosromeo00024Aún no hay calificaciones
- Mod Nivel II Lic Gestión de La Tecnología (Completo) PDFDocumento44 páginasMod Nivel II Lic Gestión de La Tecnología (Completo) PDFMatias OjedaAún no hay calificaciones
- Compendio Unidad 4 PDFDocumento35 páginasCompendio Unidad 4 PDFKaroline DlAún no hay calificaciones
- Guía rápida de ATLAS.tiDocumento23 páginasGuía rápida de ATLAS.tinaval1879Aún no hay calificaciones
- Gestión información UDGDocumento11 páginasGestión información UDGlloviznaaAún no hay calificaciones
- Foro 9 Grupo 5 .Documento7 páginasForo 9 Grupo 5 .EBER RAUL VILCA ROMEROAún no hay calificaciones
- Actividad Integradora_1_ Instructivo_Conociendo el e-learningDocumento4 páginasActividad Integradora_1_ Instructivo_Conociendo el e-learningana.guzmanAún no hay calificaciones
- Análisis de textos con IRAMUTEQDocumento49 páginasAnálisis de textos con IRAMUTEQTomas FontainesAún no hay calificaciones
- Clase 6 Herramientas de Big Data para La Gestión ComercialDocumento15 páginasClase 6 Herramientas de Big Data para La Gestión Comercialjoaquin ignacio murúa herreraAún no hay calificaciones
- U4 - Actividad SumativaDocumento7 páginasU4 - Actividad Sumativadanielyael romanAún no hay calificaciones
- Taller 1 Base de DatosDocumento3 páginasTaller 1 Base de Datosmariua motta50% (10)
- Proyecto de BD G5Documento9 páginasProyecto de BD G5Norbert Dvj Hop0% (1)
- Documento de Apoyo Al Trabajo Parte 1Documento2 páginasDocumento de Apoyo Al Trabajo Parte 1RICARDO ADRIÁN TRUJILLO TORRESAún no hay calificaciones
- Consideraciones Del Trabajo Aplicativo PDFDocumento2 páginasConsideraciones Del Trabajo Aplicativo PDFFABRICIO EMANUEL GONZALES VILCA0% (1)
- Planeación de Español y Su Metodología de La EnseñanzaDocumento22 páginasPlaneación de Español y Su Metodología de La EnseñanzaEnrimart NadxAún no hay calificaciones
- Evidencia 5 Mapa Conceptual Choosing The Right Software PDFDocumento1 páginaEvidencia 5 Mapa Conceptual Choosing The Right Software PDFJohana LealAún no hay calificaciones
- Investigacion Documental Tecnicas Y Procedimientos by Montero Maritza Y Hochman ElenaDocumento128 páginasInvestigacion Documental Tecnicas Y Procedimientos by Montero Maritza Y Hochman ElenaDavid alvarado100% (1)
- Manual SPSS - Victoria CamacaroDocumento9 páginasManual SPSS - Victoria CamacaroVictoria V. Camacaro Y.Aún no hay calificaciones
- MODULO 3 Guia TPDocumento45 páginasMODULO 3 Guia TPOsvaldo PistánAún no hay calificaciones
- 2da WebconferenciaDocumento25 páginas2da WebconferenciaMateo Estrada EcheverriAún no hay calificaciones
- Consigna para El InformeDocumento3 páginasConsigna para El InformeRayluz ValdezAún no hay calificaciones
- Fassio, A. Pascual, L. y Suarez, F. EXTRACTO. Introducción a la Metodología de la Investigación aplicada al Saber AdministrativoDocumento19 páginasFassio, A. Pascual, L. y Suarez, F. EXTRACTO. Introducción a la Metodología de la Investigación aplicada al Saber AdministrativoFranco PoggioAún no hay calificaciones
- Tratamiento Cuantitativo de La InformacionDocumento14 páginasTratamiento Cuantitativo de La InformacionCamila Del BalzoAún no hay calificaciones
- Normas para la presentación de informes finales de investigación y artículos científicosDe EverandNormas para la presentación de informes finales de investigación y artículos científicosAún no hay calificaciones
- Resolviendo el Problema de Escribir en la Universidad: Construcción de Textos Académicos en Educación SuperiorDe EverandResolviendo el Problema de Escribir en la Universidad: Construcción de Textos Académicos en Educación SuperiorCalificación: 5 de 5 estrellas5/5 (2)
- Aprende a programar en Python: de cero al infinitoDe EverandAprende a programar en Python: de cero al infinitoAún no hay calificaciones
- Practica 5Documento5 páginasPractica 5Bside Fitness100% (1)
- Guía de Clase 1 - IramuteqDocumento5 páginasGuía de Clase 1 - IramuteqBside FitnessAún no hay calificaciones
- Discriminación laboral: enfoques sobre igualdad de oportunidadesDocumento9 páginasDiscriminación laboral: enfoques sobre igualdad de oportunidadesBside FitnessAún no hay calificaciones
- Caracteristicas Generales Del Sistema de Educacion Superior Universitario Argentino 2Documento9 páginasCaracteristicas Generales Del Sistema de Educacion Superior Universitario Argentino 2Bside FitnessAún no hay calificaciones
- 2022-Saavedra Alan MiedoDocumento62 páginas2022-Saavedra Alan MiedoBside FitnessAún no hay calificaciones
- Explicacion Unidad 1Documento2 páginasExplicacion Unidad 1Bside FitnessAún no hay calificaciones
- Clase 10-08 ClinicasDocumento1 páginaClase 10-08 ClinicasBside FitnessAún no hay calificaciones
- Clase 09-06 DeontologiaDocumento1 páginaClase 09-06 DeontologiaBside FitnessAún no hay calificaciones
- Clase 08-06-Elementos para Una Clínica Del SujetoDocumento3 páginasClase 08-06-Elementos para Una Clínica Del SujetoBside FitnessAún no hay calificaciones
- Talleres de orientación al empleo para jóvenesDocumento4 páginasTalleres de orientación al empleo para jóvenesBside FitnessAún no hay calificaciones
- Clinicas Clase 01-06Documento3 páginasClinicas Clase 01-06Bside FitnessAún no hay calificaciones
- Clinicas Clase 11-04Documento2 páginasClinicas Clase 11-04Bside FitnessAún no hay calificaciones
- Psicología laboralDocumento3 páginasPsicología laboralBside FitnessAún no hay calificaciones
- Entrevista psicoanalítica: características y teoríasDocumento8 páginasEntrevista psicoanalítica: características y teoríasPau Ortega0% (1)
- Clase 1 - PPS LABORALDocumento2 páginasClase 1 - PPS LABORALBside FitnessAún no hay calificaciones
- Clase 3 - PPS LABORALDocumento6 páginasClase 3 - PPS LABORALBside FitnessAún no hay calificaciones
- Clase 2Documento2 páginasClase 2Bside FitnessAún no hay calificaciones
- Apunts Sistemica AngelsDocumento13 páginasApunts Sistemica AngelsGem GemmaAún no hay calificaciones
- Quién Es El Paciente en ET (Elsa Coriat) PDFDocumento10 páginasQuién Es El Paciente en ET (Elsa Coriat) PDFColipan MarciaAún no hay calificaciones
- Psicoanálisis de Las Configuraciones Vinculares Puget-Berenstein (Resumen) PDFDocumento9 páginasPsicoanálisis de Las Configuraciones Vinculares Puget-Berenstein (Resumen) PDFJerry HdzAún no hay calificaciones
- Introducción A JMFDocumento10 páginasIntroducción A JMFGabriel Farfan MolinaAún no hay calificaciones
- 1.3 EnsayoDocumento3 páginas1.3 EnsayoDavid CybridAún no hay calificaciones
- Teoria de Solucion de Conflicto de Las CalificacionesDocumento2 páginasTeoria de Solucion de Conflicto de Las CalificacionesYonathan FuentesAún no hay calificaciones
- Argumentacion OralDocumento9 páginasArgumentacion OralArath JerezAún no hay calificaciones
- Colestasis Intrahepatica Del EmbarazoDocumento5 páginasColestasis Intrahepatica Del EmbarazoPercy Bellido SotilloAún no hay calificaciones
- Gestión Calidad COPEMIDocumento24 páginasGestión Calidad COPEMISistemas - Dionicio MelendezAún no hay calificaciones
- Las Sociedades OralesDocumento1 páginaLas Sociedades OralesAguirre AlarcónAún no hay calificaciones
- Ciencia Sociedad y Tecnología Joel ReginoDocumento9 páginasCiencia Sociedad y Tecnología Joel ReginoJoelrefe ReginoAún no hay calificaciones
- Costos en hoteles y restaurantesDocumento5 páginasCostos en hoteles y restaurantesGonzAguirre0% (1)
- Información completa sobre BilaxtenDocumento7 páginasInformación completa sobre BilaxtenMariano SuarezAún no hay calificaciones
- Vida Universitaria 188 UANLDocumento40 páginasVida Universitaria 188 UANLadanrocaAún no hay calificaciones
- 1.1 Configuración Básica de RedesDocumento12 páginas1.1 Configuración Básica de RedesKatia Rubit Benitez CastroAún no hay calificaciones
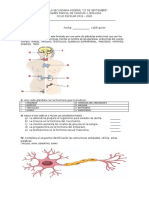
- EL SISTEMA ENDOCRINO Esta Formado Por Una Serie de Glándulas EndocrinasDocumento2 páginasEL SISTEMA ENDOCRINO Esta Formado Por Una Serie de Glándulas EndocrinasFlorencia Mendoza100% (1)
- Acondicionamiento de SeñalesDocumento8 páginasAcondicionamiento de SeñalesMarco Vinicio Chuma AlvarezAún no hay calificaciones
- Resumen Penal P. GeneralDocumento40 páginasResumen Penal P. GeneralJessicaAún no hay calificaciones
- Pressbook El Hoyo PDFDocumento19 páginasPressbook El Hoyo PDFRodrigo Alvarez EspejelAún no hay calificaciones
- UDI 3 LC 6º and - 15Documento37 páginasUDI 3 LC 6º and - 15SergioAún no hay calificaciones
- Análisis Cinemático de Una Transmisión Automática Allison 1000Documento9 páginasAnálisis Cinemático de Una Transmisión Automática Allison 1000Ricardo Fierro100% (1)
- Ámbitos de La BioéticaDocumento5 páginasÁmbitos de La BioéticaAlexis Vera Del ValleAún no hay calificaciones
- Herramienta 11. Minutas Factor de Actividad Física LeveDocumento13 páginasHerramienta 11. Minutas Factor de Actividad Física LeveLilianaMarcelaLeónPabónAún no hay calificaciones
- Plan de trabajo COVID-19 Mayo Religión Evangélica 1oDocumento2 páginasPlan de trabajo COVID-19 Mayo Religión Evangélica 1oElish AbbaAún no hay calificaciones
- Trabajo de Campo de Embriologia Dr. MarianelaDocumento11 páginasTrabajo de Campo de Embriologia Dr. Marianelakivapaos0206Aún no hay calificaciones
- BROCHURE - Ug-Contabilidad-Y-FinanzasDocumento13 páginasBROCHURE - Ug-Contabilidad-Y-FinanzasSantiago D. PerezAún no hay calificaciones
- Manual Del Justiciable Materia CivilDocumento127 páginasManual Del Justiciable Materia CivilIrving Vargas100% (2)
- Administración de Riesgos Financieros: Modelos y MediciónDocumento142 páginasAdministración de Riesgos Financieros: Modelos y MediciónandreaAún no hay calificaciones
- PRS Avance Admi N 2Documento16 páginasPRS Avance Admi N 2Francis NoriegaAún no hay calificaciones
- MA262 - Libro Digital - Derivada de Funciones TrigonométricasDocumento9 páginasMA262 - Libro Digital - Derivada de Funciones TrigonométricasFred Jheffersson100% (1)
- Balance Apertura Mario Medina 02-01-2020Documento18 páginasBalance Apertura Mario Medina 02-01-2020Wilber jhoy Vallejos100% (1)
- Ficha #36 Leemos Textos ExpresivosDocumento3 páginasFicha #36 Leemos Textos ExpresivosRobert Enrique Salas BailonAún no hay calificaciones