
También podría gustarte
- Programa de Finanzas2 UsmDocumento4 páginasPrograma de Finanzas2 UsmDiego Sanchez Naglieri100% (1)
- Malla Icv Usm 2021Documento1 páginaMalla Icv Usm 2021rebeca marchant moralesAún no hay calificaciones
- Análisis Econométrico Con Perspectiva de Género Del Sistema de Pensiones ChilenoDocumento12 páginasAnálisis Econométrico Con Perspectiva de Género Del Sistema de Pensiones ChilenoNicole Rojas Hernández100% (1)
- Muestreo Econometria 2 2020Documento21 páginasMuestreo Econometria 2 2020clementeAún no hay calificaciones
- Ejercicios Resueltos de Ingenieria Economica USMDocumento11 páginasEjercicios Resueltos de Ingenieria Economica USMvencrovenAún no hay calificaciones
- Finanzas UsmDocumento47 páginasFinanzas UsmmarceloramirezqAún no hay calificaciones
- Solemne 2 Viña Del Mar Vespertino 2017 Pauta PDFDocumento5 páginasSolemne 2 Viña Del Mar Vespertino 2017 Pauta PDFAndres Astete ÁlvarezAún no hay calificaciones
- Taller 3 EconometriaDocumento8 páginasTaller 3 EconometriaMelissa EstradaAún no hay calificaciones
- Uso Covarianza y Sus PropiedadesDocumento73 páginasUso Covarianza y Sus PropiedadesVicente Prohens KoteskyAún no hay calificaciones
- Taller No. 1 Inferencial 2018Documento5 páginasTaller No. 1 Inferencial 2018crismolgarAún no hay calificaciones
- Trabajo Final Econometria UdecDocumento12 páginasTrabajo Final Econometria UdecMackarena Fierro ArratiaAún no hay calificaciones
- ICAD502 U3 S7 Apte - ISLMBPtcFlexibleDocumento8 páginasICAD502 U3 S7 Apte - ISLMBPtcFlexibleElizabeth San Martin SotoAún no hay calificaciones
- Tarea 3 Christian SandovalDocumento8 páginasTarea 3 Christian SandovalChristian Andrés Sandoval0% (1)
- Laboratorio 1Documento9 páginasLaboratorio 1Roger GomezAún no hay calificaciones
- Practica #1Documento5 páginasPractica #1Diego Alejandro Urbina GuisbertAún no hay calificaciones
- Trabajo EconometriaDocumento16 páginasTrabajo EconometriaMaldonado91Aún no hay calificaciones
- Guia de Estudio 2 - Resuelta - FMS 176 - 2016 - 20 PDFDocumento6 páginasGuia de Estudio 2 - Resuelta - FMS 176 - 2016 - 20 PDFMatias Ignacio Zarate PiñeiroAún no hay calificaciones
- Tig Microeconomía Avanzada Angel CortaDocumento13 páginasTig Microeconomía Avanzada Angel CortaAngel CortaAún no hay calificaciones
- EconometriaDocumento7 páginasEconometriaANDRESAún no hay calificaciones
- Taller Preparación Parcial 2 - 2021-1Documento6 páginasTaller Preparación Parcial 2 - 2021-1Jose Miguel Garcia EscobarAún no hay calificaciones
- Snacks de Grillos, MercaDocumento7 páginasSnacks de Grillos, MercaMax RamirezAún no hay calificaciones
- TP 2 - 80.00% - Produccion 2Documento6 páginasTP 2 - 80.00% - Produccion 2Agustin DonatoAún no hay calificaciones
- Practica EconometriaDocumento24 páginasPractica Econometriajorge100% (1)
- Icad503 Tig Grupo 1 HoradeltéDocumento34 páginasIcad503 Tig Grupo 1 HoradeltéAlvaro ParedesAún no hay calificaciones
- Pruebas Pasadas Econometria II PDFDocumento127 páginasPruebas Pasadas Econometria II PDFJonathan BidwellAún no hay calificaciones
- Ejercicios Regresion MúltipleDocumento9 páginasEjercicios Regresion MúltipleAlina RivasAún no hay calificaciones
- Valoración de Derivados 1 2010Documento19 páginasValoración de Derivados 1 2010Jaime Andres Laverde ZuletaAún no hay calificaciones
- Estrategias CCUDocumento2 páginasEstrategias CCUScarlett Meza HernándezAún no hay calificaciones
- 2021 05 FMMA210 T3 PautaDocumento7 páginas2021 05 FMMA210 T3 PautaValeriaAún no hay calificaciones
- Examen Parcial - Semana 4 - Inv - Primer Bloque-Econometria - (Grupo b01)Documento13 páginasExamen Parcial - Semana 4 - Inv - Primer Bloque-Econometria - (Grupo b01)alejandragonzalezAún no hay calificaciones
- Tig Econometria LanDocumento24 páginasTig Econometria LanKarla Estefanía Godoy FuentesAún no hay calificaciones
- Iicg2102 - s11 - Marmentini - Felipe - Solemne 2Documento7 páginasIicg2102 - s11 - Marmentini - Felipe - Solemne 2MarmensorcoAún no hay calificaciones
- Solemne 1 Final IC 2021Documento4 páginasSolemne 1 Final IC 2021EXO2506Aún no hay calificaciones
- Cadenas de MarkovDocumento7 páginasCadenas de MarkovDaniela Mollo RivasAún no hay calificaciones
- Ar 19050Documento7 páginasAr 19050gabriela mendezAún no hay calificaciones
- Final SQM !!!!Documento17 páginasFinal SQM !!!!Kariitho Estefania Ruggieri Donoso100% (1)
- Clases UNAB 1de2Documento85 páginasClases UNAB 1de2ELe MaGoAún no hay calificaciones
- Prueba 2 CASO Industria Salmonera en Chile PREGUNTAS A GONZALO ROJAS GARRIDODocumento4 páginasPrueba 2 CASO Industria Salmonera en Chile PREGUNTAS A GONZALO ROJAS GARRIDOVicente Ignacio Correa JulietAún no hay calificaciones
- Taller MacroDocumento5 páginasTaller MacroDairon DuqueAún no hay calificaciones
- EstadisticaDocumento72 páginasEstadisticadalerigaAún no hay calificaciones
- TIG Econometria V - 3Documento18 páginasTIG Econometria V - 3Josefina Valenzuela GrauschopfAún no hay calificaciones
- Solución S Taller 6 Formativo Macroeconomía Advance UNABDocumento4 páginasSolución S Taller 6 Formativo Macroeconomía Advance UNABandreaAún no hay calificaciones
- Resumen Operación de Negocios para Solemne 1Documento15 páginasResumen Operación de Negocios para Solemne 1Seba Camus SotoAún no hay calificaciones
- Tiempo de ReaccionDocumento10 páginasTiempo de ReaccionWilson BenavidesAún no hay calificaciones
- Aerolíneas de Bajo Costo vs. Aerolíneas Convencionales - ArtículoDocumento18 páginasAerolíneas de Bajo Costo vs. Aerolíneas Convencionales - ArtículoCharlyn Almeciga Gonzalez100% (1)
- Facultad de Economía Y Negocios Escuela de Ingeniería en Administración de Empresas Ingeniería en Administración de Empresas Mención FinanzasDocumento15 páginasFacultad de Economía Y Negocios Escuela de Ingeniería en Administración de Empresas Ingeniería en Administración de Empresas Mención FinanzasvicnetAún no hay calificaciones
- Encuesta Del MinimarketDocumento12 páginasEncuesta Del MinimarketLeandro Perez AguirreAún no hay calificaciones
- Trabajo EconometriaDocumento30 páginasTrabajo EconometriaCAMILA RAMIREZ MUÑOZAún no hay calificaciones
- Econometria 2Documento21 páginasEconometria 2loreta fernandezAún no hay calificaciones
- Guia Control 2 PDFDocumento17 páginasGuia Control 2 PDFAndrés Neira SalazarAún no hay calificaciones
- 2018 11 22 FCD Examen - PautaDocumento8 páginas2018 11 22 FCD Examen - PautaJesus Marcelo Jara Hormazabal100% (1)
- Ejercicio de Pareto y IshikawaDocumento13 páginasEjercicio de Pareto y IshikawaVR DanAún no hay calificaciones
- USS EcMt S1 20T3Documento2 páginasUSS EcMt S1 20T3Victor HernándezAún no hay calificaciones
- Jardin Infantil Mi Primera RimaDocumento42 páginasJardin Infantil Mi Primera RimaMarlenyAún no hay calificaciones
- Plan Agregado de Producción Mediante El Uso de Un Algoritmo de Programación Lineal: Un Caso de Estudio para La Pequeña IndustriaDocumento7 páginasPlan Agregado de Producción Mediante El Uso de Un Algoritmo de Programación Lineal: Un Caso de Estudio para La Pequeña IndustriamarielagasteluAún no hay calificaciones
- Guia Investigacion de MercadoDocumento16 páginasGuia Investigacion de MercadoJaviera UrrutiaAún no hay calificaciones
- HeterocedasticidadDocumento28 páginasHeterocedasticidadVictoria MassonAún no hay calificaciones
- Foro 3Documento7 páginasForo 3Cesar Alfonso Rosales Amaya0% (1)
- Econometría Práctica 1Documento13 páginasEconometría Práctica 1Like New50% (2)
- Solución Taller 2 EconometríaDocumento8 páginasSolución Taller 2 EconometríaCarlos humberto Alvarez borda100% (1)
- Tarea 1Documento5 páginasTarea 1Cesar Alfonso Rosales AmayaAún no hay calificaciones
- Foro 4Documento8 páginasForo 4Cesar Alfonso Rosales AmayaAún no hay calificaciones
- Foro 3Documento7 páginasForo 3Cesar Alfonso Rosales Amaya0% (1)
- Tarea 3Documento3 páginasTarea 3Cesar Alfonso Rosales AmayaAún no hay calificaciones
- Tarea ExtraDocumento8 páginasTarea ExtraCesar Alfonso Rosales AmayaAún no hay calificaciones
- Contaminación AcústicaDocumento13 páginasContaminación AcústicaCesar Alfonso Rosales AmayaAún no hay calificaciones
- Contaminacion AmbientalDocumento20 páginasContaminacion AmbientalCesar Alfonso Rosales AmayaAún no hay calificaciones
- Foro 6 Primera SecuenciaDocumento3 páginasForo 6 Primera SecuenciaCesar Alfonso Rosales AmayaAún no hay calificaciones
- Foro 2 Primera y Segunda ParteDocumento7 páginasForo 2 Primera y Segunda ParteCesar Alfonso Rosales AmayaAún no hay calificaciones
- Minimos Cuadrados Ordinarios IIDocumento32 páginasMinimos Cuadrados Ordinarios IICesar Alfonso Rosales Amaya100% (1)
- MicroecnomiaDocumento9 páginasMicroecnomiaCesar Alfonso Rosales AmayaAún no hay calificaciones
- Foro 1 Primera SecuenciaDocumento5 páginasForo 1 Primera SecuenciaCesar Alfonso Rosales Amaya100% (1)
- Ensayo Sobre El BitcoinDocumento4 páginasEnsayo Sobre El BitcoinCesar Alfonso Rosales AmayaAún no hay calificaciones
- Foro 7 Primera SecuenciaDocumento2 páginasForo 7 Primera SecuenciaCesar Alfonso Rosales AmayaAún no hay calificaciones
- Presupuesto General de HondurasDocumento4 páginasPresupuesto General de HondurasCesar Alfonso Rosales AmayaAún no hay calificaciones
- Apuntes de La Clase - Liquidación 2018 y 2019Documento10 páginasApuntes de La Clase - Liquidación 2018 y 2019Cesar Alfonso Rosales AmayaAún no hay calificaciones
- Tarea - Investigacion de PaisDocumento11 páginasTarea - Investigacion de PaisCesar Alfonso Rosales AmayaAún no hay calificaciones
- Análisis Del Crecimiento Económico de Honduras en Los Últimos Cuatro AñosDocumento1 páginaAnálisis Del Crecimiento Económico de Honduras en Los Últimos Cuatro AñosCesar Alfonso Rosales AmayaAún no hay calificaciones
- Cuestionario de Elementos TeóricosDocumento2 páginasCuestionario de Elementos TeóricosCesar Alfonso Rosales AmayaAún no hay calificaciones
- Ejercicio 3 Pib CatrachilandiaDocumento12 páginasEjercicio 3 Pib CatrachilandiaCesar Alfonso Rosales AmayaAún no hay calificaciones
- Preguntas Actividad 1Documento3 páginasPreguntas Actividad 1Cesar Alfonso Rosales AmayaAún no hay calificaciones
- Programa de Probabilidad y Estadistica 2024Documento5 páginasPrograma de Probabilidad y Estadistica 2024Carlos Isaí Amaya FloresAún no hay calificaciones
- Currículo Del Título de FP Básica de Cocina y RestauraciónDocumento30 páginasCurrículo Del Título de FP Básica de Cocina y RestauraciónFETE-UGT ExtremaduraAún no hay calificaciones
- A171Z215 EstadisticaInferencialDocumento6 páginasA171Z215 EstadisticaInferencialOsman Albino Mejia HidalgoAún no hay calificaciones
- La Correlación Bivariada y Cómo AnalizarlaDocumento4 páginasLa Correlación Bivariada y Cómo AnalizarlaGenaro Cabrera SantillanAún no hay calificaciones
- Investigacion de Mercados Espoch Tomo 3Documento108 páginasInvestigacion de Mercados Espoch Tomo 3Paul ReveloVelozAún no hay calificaciones
- Prueba de Hipotesis para La Razon de Varianza (Fisher)Documento7 páginasPrueba de Hipotesis para La Razon de Varianza (Fisher)Araceli AbarcaAún no hay calificaciones
- Tesis FinalDocumento57 páginasTesis FinalEmma rios pradaAún no hay calificaciones
- Proyecto de Investigación - 22Documento37 páginasProyecto de Investigación - 22Iris QuintanaAún no hay calificaciones
- Consolidación ETDocumento5 páginasConsolidación ETGema Vera rubioAún no hay calificaciones
- T2. Razonamiento Cuantitativo - 07 - 05 - 2020 PDFDocumento43 páginasT2. Razonamiento Cuantitativo - 07 - 05 - 2020 PDFLorena OrjuelaAún no hay calificaciones
- Diseño ExperimentalDocumento6 páginasDiseño Experimentalarley herranAún no hay calificaciones
- Practica Dirigida Unidad 3 - Inferencias Acerca de Dos MuestrasDocumento7 páginasPractica Dirigida Unidad 3 - Inferencias Acerca de Dos MuestrasAngel Inconfundible Povis Ore100% (1)
- Precision y Exactitud InformeDocumento5 páginasPrecision y Exactitud InformeAlex OwenAún no hay calificaciones
- Solución Taller N°1 - Estadisticas y ProbabilidadesDocumento19 páginasSolución Taller N°1 - Estadisticas y Probabilidadessebastian albañil100% (1)
- Resolucion para Recursos HumanosDocumento21 páginasResolucion para Recursos HumanosStrange DanyAún no hay calificaciones
- Trabajo Individual Econometria 3.1Documento22 páginasTrabajo Individual Econometria 3.1Wilson CordovaAún no hay calificaciones
- Unidad Cero y Evaluación Diagnostica - Primaria - 5to y 6to - V CicloDocumento12 páginasUnidad Cero y Evaluación Diagnostica - Primaria - 5to y 6to - V CicloKarla MostaceroAún no hay calificaciones
- Medidas de Tendencia CentralDocumento16 páginasMedidas de Tendencia CentralestreAún no hay calificaciones
- Metodos y Tecnicas Cuantitativas II - Pablo TapiaDocumento4 páginasMetodos y Tecnicas Cuantitativas II - Pablo TapiaGladys ArochaAún no hay calificaciones
- ESTADÍSTICADocumento2 páginasESTADÍSTICAcharsAún no hay calificaciones
- Atlas TiDocumento46 páginasAtlas TiPatricio MonroyAún no hay calificaciones
- Estadística I - Presentaciones PDFDocumento301 páginasEstadística I - Presentaciones PDFAna AyessaAún no hay calificaciones
- Guía Didáctica de Taller Estimación Puntual y Estimación Por IntervalosDocumento7 páginasGuía Didáctica de Taller Estimación Puntual y Estimación Por IntervalosLuis RoseroAún no hay calificaciones
- Cocepto de EstadisticaDocumento18 páginasCocepto de EstadisticaSandra milena Hernandez hernandezAún no hay calificaciones
- Ejercicios de Proyecciones de VentasDocumento13 páginasEjercicios de Proyecciones de Ventasmauricio100% (2)
- Estadísitca UdesDocumento3 páginasEstadísitca UdesChemy Ay Caramba AcevedoAún no hay calificaciones
- Practica 1Documento5 páginasPractica 1LA Javier CeAún no hay calificaciones
- Nccu-202 TrabajofinalDocumento3 páginasNccu-202 TrabajofinalHausterTakuAún no hay calificaciones
- 0 Que Es El DOEDocumento9 páginas0 Que Es El DOEXtremebot RepdomAún no hay calificaciones
- Estadistica Inferencial Clase 2Documento55 páginasEstadistica Inferencial Clase 2Nestor Camilo DoriaAún no hay calificaciones
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Fundamentos de matemática: Introducción al nivel universitarioDe EverandFundamentos de matemática: Introducción al nivel universitarioCalificación: 3 de 5 estrellas3/5 (9)
- Control de calidad. Un enfoque integral y estadísticoDe EverandControl de calidad. Un enfoque integral y estadísticoCalificación: 5 de 5 estrellas5/5 (8)
- Introducción a las ecuaciones de la física matemáticaDe EverandIntroducción a las ecuaciones de la física matemáticaCalificación: 5 de 5 estrellas5/5 (4)
- Estadística Descriptiva y ProbabilidadDe EverandEstadística Descriptiva y ProbabilidadCalificación: 5 de 5 estrellas5/5 (2)
- La Biblia de las Matemáticas RápidasDe EverandLa Biblia de las Matemáticas RápidasCalificación: 4.5 de 5 estrellas4.5/5 (19)
- Elementos de estadística en riesgo financieroDe EverandElementos de estadística en riesgo financieroAún no hay calificaciones
- Mi proyecto escolar Matemáticas Lúdicas: Adaptaciones curriculares para preescolar, primaria y secundariaDe EverandMi proyecto escolar Matemáticas Lúdicas: Adaptaciones curriculares para preescolar, primaria y secundariaCalificación: 5 de 5 estrellas5/5 (5)
- Mentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraDe EverandMentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraCalificación: 4.5 de 5 estrellas4.5/5 (5)
- Métodos cuantitativos 4a Ed. Herramientas para la investigación en saludDe EverandMétodos cuantitativos 4a Ed. Herramientas para la investigación en saludCalificación: 4 de 5 estrellas4/5 (1)
- Introducción a la estadística con aplicaciones en Ciencias SocialesDe EverandIntroducción a la estadística con aplicaciones en Ciencias SocialesCalificación: 3.5 de 5 estrellas3.5/5 (2)
- Iniciación al estudio didáctico del Álgebra: Orígenes y perspectivasDe EverandIniciación al estudio didáctico del Álgebra: Orígenes y perspectivasAún no hay calificaciones
- La Teoría de Conjuntos y los Fundamentos de las MatemáticasDe EverandLa Teoría de Conjuntos y los Fundamentos de las MatemáticasCalificación: 5 de 5 estrellas5/5 (1)
- Psicoterapia psicoanalítica: Investigación, evaluación y práctica clínicaDe EverandPsicoterapia psicoanalítica: Investigación, evaluación y práctica clínicaAún no hay calificaciones
- Introducción a la estadística matemáticaDe EverandIntroducción a la estadística matemáticaCalificación: 5 de 5 estrellas5/5 (2)
- Didáctica de la matemática en la escuela primariaDe EverandDidáctica de la matemática en la escuela primariaCalificación: 2.5 de 5 estrellas2.5/5 (3)
- Introducción a la Estadística BayesianaDe EverandIntroducción a la Estadística BayesianaCalificación: 5 de 5 estrellas5/5 (2)
- Enseñar Matemática hoy: Miradas, sentidos y desafíosDe EverandEnseñar Matemática hoy: Miradas, sentidos y desafíosCalificación: 5 de 5 estrellas5/5 (1)
- Estadística básica: Introducción a la estadística con RDe EverandEstadística básica: Introducción a la estadística con RCalificación: 5 de 5 estrellas5/5 (8)









































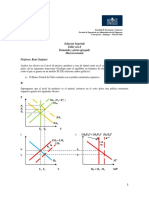




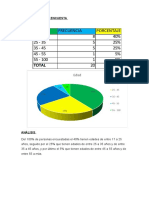





































































![Diseño de Experimentos [Métodos y Aplicaciones]](https://imgv2-1-f.scribdassets.com/img/word_document/436271314/149x198/596c96deb2/1654336147?v=1)





















