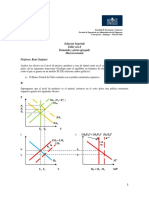
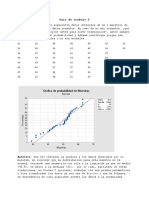
También podría gustarte
- Certamen 1 Contabilidad IIDocumento3 páginasCertamen 1 Contabilidad IILau Errazuriz0% (1)
- Estadistica NestorDocumento7 páginasEstadistica Nestorleidy100% (1)
- Tig DisminucionDocumento11 páginasTig DisminucionBenjamin VergaraAún no hay calificaciones
- TIG DERECHO Y EMPRESA FinalDocumento20 páginasTIG DERECHO Y EMPRESA FinalBenjamín GagoAún no hay calificaciones
- Lab 3Documento2 páginasLab 3Mauricio Abel Ruiz LeónAún no hay calificaciones
- EST400 08 Probabilidad CondicionalDocumento3 páginasEST400 08 Probabilidad CondicionalBernardita Faundez Parra0% (2)
- Iicg2102 - s11 - Marmentini - Felipe - Solemne 2Documento7 páginasIicg2102 - s11 - Marmentini - Felipe - Solemne 2MarmensorcoAún no hay calificaciones
- Tarea 3 Christian SandovalDocumento8 páginasTarea 3 Christian SandovalChristian Andrés Sandoval0% (1)
- Actividad Practica 2 - Ariel MontecinosDocumento8 páginasActividad Practica 2 - Ariel MontecinosAriel Montecinos BAún no hay calificaciones
- Pauta 20101icn320-C1 PDFDocumento6 páginasPauta 20101icn320-C1 PDFNico SagredoAún no hay calificaciones
- Prueba 2 CASO Industria Salmonera en Chile PREGUNTAS A GONZALO ROJAS GARRIDODocumento4 páginasPrueba 2 CASO Industria Salmonera en Chile PREGUNTAS A GONZALO ROJAS GARRIDOVicente Ignacio Correa JulietAún no hay calificaciones
- ICAD601 TIG Caso1econometriaDocumento3 páginasICAD601 TIG Caso1econometriaAlejandra Jarpa0% (1)
- Probabilidad y Estadistica Unidad 1Documento11 páginasProbabilidad y Estadistica Unidad 1Víctor Hernández DozalAún no hay calificaciones
- Prueba de Hipótesis Sobre La VarianzaDocumento6 páginasPrueba de Hipótesis Sobre La Varianzavalo490Aún no hay calificaciones
- Guia de Ejercicios Inter ConfDocumento6 páginasGuia de Ejercicios Inter ConfDAYSI NAULA100% (2)
- Malla Icv Usm 2021Documento1 páginaMalla Icv Usm 2021rebeca marchant moralesAún no hay calificaciones
- Foro 3Documento7 páginasForo 3Cesar Alfonso Rosales AmayaAún no hay calificaciones
- Pauta - Certamen 1Documento5 páginasPauta - Certamen 1SoledadAún no hay calificaciones
- Programa de Finanzas2 UsmDocumento4 páginasPrograma de Finanzas2 UsmDiego Sanchez Naglieri100% (1)
- Análisis Econométrico Con Perspectiva de Género Del Sistema de Pensiones ChilenoDocumento12 páginasAnálisis Econométrico Con Perspectiva de Género Del Sistema de Pensiones ChilenoNicole Rojas Hernández100% (1)
- Icad503 Tig Grupo 1 HoradeltéDocumento34 páginasIcad503 Tig Grupo 1 HoradeltéAlvaro ParedesAún no hay calificaciones
- La Caida Del BANGO RIGGSDocumento22 páginasLa Caida Del BANGO RIGGSMARCHENA OLIVOS MELANNY ANTONELLAAún no hay calificaciones
- Ayudantia 2 MAT-033 2021-1Documento2 páginasAyudantia 2 MAT-033 2021-1SoledadAún no hay calificaciones
- Ejercicios Resueltos de Ingenieria Economica USMDocumento11 páginasEjercicios Resueltos de Ingenieria Economica USMvencrovenAún no hay calificaciones
- 2021 05 FMMA210 T3 PautaDocumento7 páginas2021 05 FMMA210 T3 PautaValeriaAún no hay calificaciones
- Pauta ControlDocumento2 páginasPauta ControlVicente Prohens KoteskyAún no hay calificaciones
- Certamen I Soledad Cofré Usm Mayo Vitacura p101Documento12 páginasCertamen I Soledad Cofré Usm Mayo Vitacura p101SoledadAún no hay calificaciones
- Mi Proyecto EmpresarialDocumento13 páginasMi Proyecto EmpresarialSusana López HernándezAún no hay calificaciones
- Resumen Operación de Negocios para Solemne 1Documento15 páginasResumen Operación de Negocios para Solemne 1Seba Camus SotoAún no hay calificaciones
- Solemne 1 Final IC 2021Documento4 páginasSolemne 1 Final IC 2021EXO2506Aún no hay calificaciones
- Estrategias CCUDocumento2 páginasEstrategias CCUScarlett Meza HernándezAún no hay calificaciones
- ICAD502 U3 S7 Apte - ISLMBPtcFlexibleDocumento8 páginasICAD502 U3 S7 Apte - ISLMBPtcFlexibleElizabeth San Martin SotoAún no hay calificaciones
- TIG Econometria V - 3Documento18 páginasTIG Econometria V - 3Josefina Valenzuela GrauschopfAún no hay calificaciones
- Facultad de Economía Y Negocios Escuela de Ingeniería en Administración de Empresas Ingeniería en Administración de Empresas Mención FinanzasDocumento15 páginasFacultad de Economía Y Negocios Escuela de Ingeniería en Administración de Empresas Ingeniería en Administración de Empresas Mención FinanzasvicnetAún no hay calificaciones
- Tópicos de Matemática Aplicada.Documento2 páginasTópicos de Matemática Aplicada.Hugo Hugo CarvajalAún no hay calificaciones
- LoginDocumento108 páginasLoginJorge ChandiaAún no hay calificaciones
- Caso MolettoDocumento5 páginasCaso MolettoDenia Mariela Mungia LopezAún no hay calificaciones
- Final SQM !!!!Documento17 páginasFinal SQM !!!!Kariitho Estefania Ruggieri Donoso100% (1)
- Cambios de Sujeto Pasivo en El ImpuestoDocumento7 páginasCambios de Sujeto Pasivo en El ImpuestoAracelli BarrigaAún no hay calificaciones
- Guia Bonos AdvanceDocumento15 páginasGuia Bonos AdvanceSatseva2011100% (2)
- Uso Covarianza y Sus PropiedadesDocumento73 páginasUso Covarianza y Sus PropiedadesVicente Prohens KoteskyAún no hay calificaciones
- Resumen Modelo CAPMDocumento11 páginasResumen Modelo CAPMAlicia GonzalezAún no hay calificaciones
- Solución S Taller 6 Formativo Macroeconomía Advance UNABDocumento4 páginasSolución S Taller 6 Formativo Macroeconomía Advance UNABandreaAún no hay calificaciones
- Trabajo EtadisticaDocumento30 páginasTrabajo EtadisticaMatias Ignacio AcuñaAún no hay calificaciones
- 1 Prueba Solemne PautaDocumento6 páginas1 Prueba Solemne PautaEduardx Sepúlveda CorreaAún no hay calificaciones
- EconometriaDocumento7 páginasEconometriaANDRESAún no hay calificaciones
- Trabajo EconometriaDocumento16 páginasTrabajo EconometriaMaldonado91Aún no hay calificaciones
- Pauta Certamenes 2 (2014s1 - 2009s1)Documento69 páginasPauta Certamenes 2 (2014s1 - 2009s1)Daniel Antonio Jelvez CifuentesAún no hay calificaciones
- Resumen Solemne Derecho y EmpresaDocumento7 páginasResumen Solemne Derecho y EmpresaJorge Diez SalinasAún no hay calificaciones
- Finanzas UsmDocumento47 páginasFinanzas UsmmarceloramirezqAún no hay calificaciones
- Boletin Estadistico PDFDocumento38 páginasBoletin Estadistico PDFSONIA MARGARITA MOLINA DE MEDINAAún no hay calificaciones
- TLC Entre Chile y China Un Análisis Económico Legal Del Tratado y Sus AnexosDocumento276 páginasTLC Entre Chile y China Un Análisis Económico Legal Del Tratado y Sus AnexosKassandra MacarenaAún no hay calificaciones
- Reforma TributariaDocumento11 páginasReforma TributariaPAULA YULIETH RUIZ ROAAún no hay calificaciones
- Examen Final de EconomíaDocumento5 páginasExamen Final de EconomíaYampier MartinezAún no hay calificaciones
- Control 3 microII Advance Unab PDFDocumento1 páginaControl 3 microII Advance Unab PDFFrancisco CaresAún no hay calificaciones
- Ejercicios de Oferta y DemandaDocumento5 páginasEjercicios de Oferta y Demandaalejandro argumedoAún no hay calificaciones
- PREGUNTAS CONTROL 1 MacroeconomíaDocumento20 páginasPREGUNTAS CONTROL 1 MacroeconomíalitreAún no hay calificaciones
- Aux8 3Documento6 páginasAux8 3Jean Francisco GonzálezAún no hay calificaciones
- Gestion Empresarial DogmatismoDocumento7 páginasGestion Empresarial DogmatismoMariela MakyAún no hay calificaciones
- Emprendimiento 1 BasicoDocumento4 páginasEmprendimiento 1 BasicoCarlos Eriberto Xicay MiculaxAún no hay calificaciones
- TIG Negociación Internacional 2.0Documento41 páginasTIG Negociación Internacional 2.0Matias Soffia RosselotAún no hay calificaciones
- Proyecto de EmprendimientoDocumento15 páginasProyecto de EmprendimientojavdelapenaAún no hay calificaciones
- Tipos de MuestreoDocumento71 páginasTipos de MuestreoArroyo Martínez José GabrielAún no hay calificaciones
- 2-Tipos de MuestreoDocumento38 páginas2-Tipos de Muestreogloriagallardo856Aún no hay calificaciones
- Econom Iate Mas 12345Documento13 páginasEconom Iate Mas 12345Cristian Rodrigo Candia QuisbertAún no hay calificaciones
- Monografía Teorema Central Del LímiteDocumento11 páginasMonografía Teorema Central Del LímitegggarciaAún no hay calificaciones
- Tema 7 - Recolección y Análisis de Datos Cuantitativos - Parte 1-1575429149Documento5 páginasTema 7 - Recolección y Análisis de Datos Cuantitativos - Parte 1-1575429149Sami SaiAún no hay calificaciones
- Estadistica AplicadaDocumento119 páginasEstadistica Aplicadachilo/isidro100% (1)
- RP Mat3 k12 Ficha 12Documento10 páginasRP Mat3 k12 Ficha 12Rosa Maria Arrese RojasAún no hay calificaciones
- Ejercicios Medidas de Variabilidad y Medidas de FormaDocumento3 páginasEjercicios Medidas de Variabilidad y Medidas de FormaJhossy Torres RomeroAún no hay calificaciones
- Syllabus Matematicas NM Sas Ib 2015-2016Documento10 páginasSyllabus Matematicas NM Sas Ib 2015-2016miky3177Aún no hay calificaciones
- Ejercicios Resueltos de Estadistica InderencialDocumento16 páginasEjercicios Resueltos de Estadistica InderencialAlejandro BernalAún no hay calificaciones
- S2 - Contenido - Estgt1102Documento15 páginasS2 - Contenido - Estgt1102Claudio GómezAún no hay calificaciones
- Formulas S3 para MiDocumento3 páginasFormulas S3 para MiClara MejiaAún no hay calificaciones
- Diseño de ExperimentosDocumento17 páginasDiseño de Experimentosgeovana torreroAún no hay calificaciones
- Tarea CTADocumento2 páginasTarea CTAjuly1692hotmail.comAún no hay calificaciones
- Estadistica 30Documento4 páginasEstadistica 30Hidalgo RosadoAún no hay calificaciones
- Cuestionario de EvaluacionDocumento13 páginasCuestionario de EvaluacionFidel LantiguaAún no hay calificaciones
- Curso Geoestadistica PDFDocumento41 páginasCurso Geoestadistica PDFraquel vilchezAún no hay calificaciones
- Tabla - de - Especificaciones Matematicas Bachillerato 2020 2021Documento20 páginasTabla - de - Especificaciones Matematicas Bachillerato 2020 2021Ricardo MendezAún no hay calificaciones
- Unidad 1 - Introducción A La Estadística y Análisis de DatosDocumento62 páginasUnidad 1 - Introducción A La Estadística y Análisis de DatosCeleste CasillaAún no hay calificaciones
- Guía de Trabajo 2Documento5 páginasGuía de Trabajo 2Xavier OjedaAún no hay calificaciones
- Apuntes de Estadistica Social Cap 2 Analisis - FactorialDocumento22 páginasApuntes de Estadistica Social Cap 2 Analisis - FactorialDaniel MoyaAún no hay calificaciones
- Análisis Probabilístico de Fallas Superficiales en Taludes PDFDocumento13 páginasAnálisis Probabilístico de Fallas Superficiales en Taludes PDFvictor gomezAún no hay calificaciones
- Medias y Desviacion Cepre Uni 2021-2Documento68 páginasMedias y Desviacion Cepre Uni 2021-2FRANAún no hay calificaciones
- Clase 5 Estadistica Aplicada UcvDocumento19 páginasClase 5 Estadistica Aplicada UcvLizeth ChavezAún no hay calificaciones
- Yasna - Reygadas - Tarea S8 - Formulación y Evaluación de ProyectosDocumento11 páginasYasna - Reygadas - Tarea S8 - Formulación y Evaluación de ProyectosyasnaAún no hay calificaciones
- Análisis de Regresión y CorrelaciónDocumento12 páginasAnálisis de Regresión y CorrelaciónRomina MoralesAún no hay calificaciones
- Geometria y Estadistica de 6°Documento29 páginasGeometria y Estadistica de 6°Yerman CordobaAún no hay calificaciones
- Trabajo Del Curso Primera EntregaDocumento11 páginasTrabajo Del Curso Primera EntregaLavalle Merino CristhianAún no hay calificaciones