También podría gustarte
- Educación en bioética y alimentos genéticamente modificadosDe EverandEducación en bioética y alimentos genéticamente modificadosAún no hay calificaciones
- Ingenieria GeneticaDocumento24 páginasIngenieria Geneticaicrg0% (1)
- Manual de prácticas de laboratorio en microbiología veterinariaDe EverandManual de prácticas de laboratorio en microbiología veterinariaAún no hay calificaciones
- BIOinformaticaDocumento26 páginasBIOinformaticaAlba V. DemesaAún no hay calificaciones
- Citogenética aplicada a la medicinaDe EverandCitogenética aplicada a la medicinaAún no hay calificaciones
- Guia MU - Bioinformatica - Bioestadistica - 20162Documento12 páginasGuia MU - Bioinformatica - Bioestadistica - 20162mparrapAún no hay calificaciones
- Antologa I A Las Neurociencias 142 1Documento124 páginasAntologa I A Las Neurociencias 142 1Gama Cayo VeraAún no hay calificaciones
- Herramientas para el análisis estadístico de datos biológicos en RDe EverandHerramientas para el análisis estadístico de datos biológicos en RAún no hay calificaciones
- Syllabus Bioinformática 2022-IIDocumento8 páginasSyllabus Bioinformática 2022-IIJohan Sebastián Ríos ZAún no hay calificaciones
- Interfaces cerebro-computador para el reconocimiento automático del habla silenciosaDe EverandInterfaces cerebro-computador para el reconocimiento automático del habla silenciosaCalificación: 2 de 5 estrellas2/5 (1)
- Informe 1 - Lab. GenéticaDocumento12 páginasInforme 1 - Lab. GenéticaSaúl FernándezAún no hay calificaciones
- Genómica Sintética: Usar la modificación genética para crear nuevo ADN o formas de vida completasDe EverandGenómica Sintética: Usar la modificación genética para crear nuevo ADN o formas de vida completasAún no hay calificaciones
- Biología MolecularDocumento41 páginasBiología MolecularRebeca MendozaAún no hay calificaciones
- PRACTICA 4 - Bioinformática y Curvas Estándares Con QPCR - 1Documento9 páginasPRACTICA 4 - Bioinformática y Curvas Estándares Con QPCR - 1saioa coronadoAún no hay calificaciones
- Alineamiento y Construcción de Un Árbol Filogenético Gen Nifh (Gen de Fijación Biológica de Nitrógeno)Documento39 páginasAlineamiento y Construcción de Un Árbol Filogenético Gen Nifh (Gen de Fijación Biológica de Nitrógeno)María Fernanda Lima Totocayo100% (1)
- Ejercicios Del Práctico de PCRDocumento1 páginaEjercicios Del Práctico de PCRManuel Eduardo Peña ZúñigaAún no hay calificaciones
- Herramientas en BioinformáticaDocumento55 páginasHerramientas en BioinformáticaGuillermo UCAún no hay calificaciones
- P3 - Bioinformática - Sánchez Zamorano Julio CésarDocumento10 páginasP3 - Bioinformática - Sánchez Zamorano Julio CésarJulio César Sánchez ZamoranoAún no hay calificaciones
- Bioinformatica BioingenieriaDocumento20 páginasBioinformatica BioingenierialjpsoftAún no hay calificaciones
- PROTEÒMICADocumento11 páginasPROTEÒMICAjessicaAún no hay calificaciones
- Bioinformática NovatosDocumento31 páginasBioinformática NovatosAlejandro BrenaAún no hay calificaciones
- Trabajo de Aplicación (Bioinformática)Documento55 páginasTrabajo de Aplicación (Bioinformática)Crhistian Mark Montenegro ValderramaAún no hay calificaciones
- 07 Técnicas EnvasadoDocumento5 páginas07 Técnicas EnvasadoRocío Martínez MartínezAún no hay calificaciones
- Ejercicios Bioinformatica para Alumnos Del Grado en QuimicaDocumento30 páginasEjercicios Bioinformatica para Alumnos Del Grado en Quimicalidia_profeparticulaAún no hay calificaciones
- Libro BioinformaticaDocumento101 páginasLibro BioinformaticaAlejandro Brena100% (6)
- Bioinformática Práctica: PROCESAMIENTO DE CADENAS Y SECUENCIAS BIOLÓGICASDocumento16 páginasBioinformática Práctica: PROCESAMIENTO DE CADENAS Y SECUENCIAS BIOLÓGICASJacobo Hernández V100% (9)
- Practica #05 - Mega DnaDocumento14 páginasPractica #05 - Mega DnaXiory Estefany100% (1)
- Utilidad en La Administración de La Justicia, Repercusión Social y Aspectos ÉticosDocumento8 páginasUtilidad en La Administración de La Justicia, Repercusión Social y Aspectos ÉticosYeison Andres TobonAún no hay calificaciones
- Practicas Biotecnologia 305689Documento26 páginasPracticas Biotecnologia 305689pablomafe100% (1)
- Bases de Datos en BioinformáticaDocumento10 páginasBases de Datos en BioinformáticaJoselyn ChambiAún no hay calificaciones
- Programa Curso BioinformaticaDocumento1 páginaPrograma Curso BioinformaticaCristian BossolascoAún no hay calificaciones
- Biotecnologia Capitulo 1 PearsonDocumento25 páginasBiotecnologia Capitulo 1 PearsonAficiompAún no hay calificaciones
- BTMAV INFORME Practicas Diseño de Primers para PCRDocumento20 páginasBTMAV INFORME Practicas Diseño de Primers para PCRAndrea Pignatelli100% (1)
- Bioinformatica y Biologia MolecularDocumento105 páginasBioinformatica y Biologia MolecularArcadio Maldonado RodriguezAún no hay calificaciones
- BioinformáticaDocumento6 páginasBioinformáticaDawson AbigailAún no hay calificaciones
- Taller ADN RecombinanteDocumento6 páginasTaller ADN RecombinanteMaría Juliana Rojas MoncadaAún no hay calificaciones
- Manual de Prácticas de HistologíaDocumento121 páginasManual de Prácticas de HistologíaAnna100% (1)
- Universidad Nacional de Moquegua: Facultad de IngenieríaDocumento22 páginasUniversidad Nacional de Moquegua: Facultad de IngenieríaNora Quispe Camaticona100% (1)
- Virología, IntroducciónDocumento18 páginasVirología, IntroducciónmarinaAún no hay calificaciones
- Manual BioinformaticaDocumento62 páginasManual BioinformaticaKevin Yukino100% (1)
- Unidad 4 Biot. I 2020Documento103 páginasUnidad 4 Biot. I 2020ezeAún no hay calificaciones
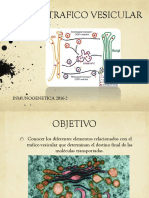
- 12.trafico Vesicular PDFDocumento18 páginas12.trafico Vesicular PDFBrayan LaraAún no hay calificaciones
- PDF. Biología Molecular y Citogenética. Tema 12Documento12 páginasPDF. Biología Molecular y Citogenética. Tema 12mpm0028Aún no hay calificaciones
- Monografia Tumores NeuroendocrinosDocumento86 páginasMonografia Tumores Neuroendocrinoschristian navarro palmaAún no hay calificaciones
- BioinformáticaDocumento65 páginasBioinformáticaCarlos de Paz100% (3)
- Bioquimica Clinica Alla-GawDocumento145 páginasBioquimica Clinica Alla-GawaliasjoseAún no hay calificaciones
- Biología 2 ZootecniaDocumento11 páginasBiología 2 ZootecniaAngie Hernández OlivaAún no hay calificaciones
- Atlas de HistologíaDocumento17 páginasAtlas de Histologíajake lolAún no hay calificaciones
- Gastrulación y NeurulaciónDocumento30 páginasGastrulación y NeurulaciónHeyssel WittersheimAún no hay calificaciones
- Cristalizacion Proteinas-3Documento238 páginasCristalizacion Proteinas-3Valentin GuzmanAún no hay calificaciones
- AtlasDocumento151 páginasAtlasNata Bolivar OsornoAún no hay calificaciones
- Guia DidacticaDocumento122 páginasGuia DidacticaMAJOAún no hay calificaciones
- 10 Consejos para Aprovechar Tu FCT de Laboratorio Clínico y BiomédicoDocumento24 páginas10 Consejos para Aprovechar Tu FCT de Laboratorio Clínico y BiomédicoFrancis Vallecillo PadillaAún no hay calificaciones
- Diferenciación Celular IiDocumento18 páginasDiferenciación Celular IiJuan Pablo Castro JaraAún no hay calificaciones
- Introduccion A La Citometria de FlujoDocumento44 páginasIntroduccion A La Citometria de FlujoCarola HernandezAún no hay calificaciones
- Cuestionario de InmunologíaDocumento59 páginasCuestionario de InmunologíaLeandro Miguel BidondoAún no hay calificaciones
- 1.temario de BionformaticaDocumento3 páginas1.temario de Bionformaticamaveick100% (1)
- Guía de Virología 1.0Documento50 páginasGuía de Virología 1.0juan carlos salazarAún no hay calificaciones
- Lab GeneticaMolecularDocumento100 páginasLab GeneticaMolecularPaulino Sanchez100% (4)
- +informes de Microbiologia +Documento16 páginas+informes de Microbiologia +Aura MariaAún no hay calificaciones
- Examen Acumulativo de Biologia 6 Correspondiente Al Ii Periodo Académico 2020Documento2 páginasExamen Acumulativo de Biologia 6 Correspondiente Al Ii Periodo Académico 2020Jhon Jairo Rodriguez QuinteroAún no hay calificaciones
- Tipos y Mecanismos de Reproducción en PecesDocumento13 páginasTipos y Mecanismos de Reproducción en PecesTatiana CastañedaAún no hay calificaciones
- Exposicion BiologiaDocumento7 páginasExposicion BiologiaJorge Cano PeñaAún no hay calificaciones
- Ensayo DengueDocumento9 páginasEnsayo DengueRosaAún no hay calificaciones
- Novedades Sobre La Norma ISO 11133-2014 IelabDocumento35 páginasNovedades Sobre La Norma ISO 11133-2014 Ielabmbarpar100% (1)
- Peligros BiológicosDocumento15 páginasPeligros BiológicosCRISTIAN DAVID ANDRADE BECERRAAún no hay calificaciones
- Mancha MantecosaDocumento4 páginasMancha MantecosaArtola Jose RicardoAún no hay calificaciones
- Enfermedades de Las PlantasDocumento8 páginasEnfermedades de Las PlantasRocola LocaAún no hay calificaciones
- Semana #03: Guía de AprendizajeDocumento15 páginasSemana #03: Guía de AprendizajeMaykol SanchezAún no hay calificaciones
- TiburonesDocumento9 páginasTiburonesRekii YumuraAún no hay calificaciones
- NematodosDocumento8 páginasNematodosFrancisco SautuaAún no hay calificaciones
- Practica de Nutricion de OnogastricosDocumento2 páginasPractica de Nutricion de OnogastricosjamesAún no hay calificaciones
- FicheroDocumento7 páginasFicheroSantiagoAún no hay calificaciones
- Expo - Bacteria - Equipo 4Documento12 páginasExpo - Bacteria - Equipo 4brandonalexissanchezdelacruzAún no hay calificaciones
- ED1 - Panel y Exposición en La Que, Se Expliquen y Discutan Las Funciones de Los Tejidos de Las Plantas.Documento8 páginasED1 - Panel y Exposición en La Que, Se Expliquen y Discutan Las Funciones de Los Tejidos de Las Plantas.Leobeth del Carmen Villalobos SaizAún no hay calificaciones
- Practica de Laboratorio 2Documento16 páginasPractica de Laboratorio 2ELSY AMAIRANY CASILLAS SALTOAún no hay calificaciones
- Texto Expositivo - Testigos Del PasadoDocumento4 páginasTexto Expositivo - Testigos Del PasadoRossanaRiosAún no hay calificaciones
- Estudio de Una Mutación en Papaya (Carica Papaya L.) Que Produce Letalidad de Plantas FemeninasDocumento6 páginasEstudio de Una Mutación en Papaya (Carica Papaya L.) Que Produce Letalidad de Plantas FemeninasCAROLINA LOPEZAún no hay calificaciones
- BiologiaDocumento23 páginasBiologiaDebra Lucia Cedeño TorresAún no hay calificaciones
- Pasto JaraguaDocumento16 páginasPasto JaraguaKeyla Abigail MartínezAún no hay calificaciones
- Álbum de CienciasDocumento2 páginasÁlbum de Cienciasfheren blandon galeanoAún no hay calificaciones
- Árbol Filogenético de Los RatitesDocumento3 páginasÁrbol Filogenético de Los RatitesJoséAún no hay calificaciones
- La AbejaDocumento3 páginasLa AbejaLittlongerAún no hay calificaciones
- Ficha Cyt 23-05Documento2 páginasFicha Cyt 23-05Tyli CinthyaAún no hay calificaciones
- Del Carpio & Mendoza 2017Documento12 páginasDel Carpio & Mendoza 2017thonikond3100Aún no hay calificaciones
- Eclipta Prostrata - Ficha InformativaDocumento8 páginasEclipta Prostrata - Ficha InformativaAlejandroAún no hay calificaciones
- Clase BiorremediacionDocumento6 páginasClase BiorremediacionVeronicaGonzalez100% (1)
- FarmaceúticasDocumento49 páginasFarmaceúticasAnonymous 5oLTGeOAún no hay calificaciones
- Reglas Calificacion AlfalfaDocumento24 páginasReglas Calificacion AlfalfaDavid Calvo MoralesAún no hay calificaciones
- Homo antecessor: El nacimiento de una especieDe EverandHomo antecessor: El nacimiento de una especieCalificación: 5 de 5 estrellas5/5 (1)
- 50 técnicas de mindfulness para la ansiedad, la depresión, el estrés y el dolor: Mindfulness como terapiaDe Everand50 técnicas de mindfulness para la ansiedad, la depresión, el estrés y el dolor: Mindfulness como terapiaCalificación: 4 de 5 estrellas4/5 (37)
- Cerebro y silencio: Las claves de la creatividad y la serenidadDe EverandCerebro y silencio: Las claves de la creatividad y la serenidadCalificación: 5 de 5 estrellas5/5 (2)
- Anatomía del caballo: Guía práctica ilustradaDe EverandAnatomía del caballo: Guía práctica ilustradaCalificación: 4 de 5 estrellas4/5 (9)
- Liberación del trauma: Perdón y temblor es el caminoDe EverandLiberación del trauma: Perdón y temblor es el caminoCalificación: 4 de 5 estrellas4/5 (4)
- Cuerpo Tóxico: Como Liberar Tu Cuerpo De Las Toxinas Externas E Internas, Y Evitar Asi Los Efectos De Los Radicales LibresDe EverandCuerpo Tóxico: Como Liberar Tu Cuerpo De Las Toxinas Externas E Internas, Y Evitar Asi Los Efectos De Los Radicales LibresCalificación: 5 de 5 estrellas5/5 (2)
- Batidos Verdes Depurativos y Antioxidantes: Aumenta tu Vitalidad con Smoothie Detox Durante 10 Días Para Adelgazar y Bajar de Peso: Aumenta tu vitalidad con smoothie detox durante 10 días para adelgazar y bajar de pesoDe EverandBatidos Verdes Depurativos y Antioxidantes: Aumenta tu Vitalidad con Smoothie Detox Durante 10 Días Para Adelgazar y Bajar de Peso: Aumenta tu vitalidad con smoothie detox durante 10 días para adelgazar y bajar de pesoCalificación: 5 de 5 estrellas5/5 (2)
- GuíaBurros Análisis clínicos: Todo lo que necesitas saber para entender tus análisisDe EverandGuíaBurros Análisis clínicos: Todo lo que necesitas saber para entender tus análisisCalificación: 4 de 5 estrellas4/5 (9)
- Sesgos Cognitivos: Una Fascinante Mirada dentro de la Psicología Humana y los Métodos para Evitar la Disonancia Cognitiva, Mejorar sus Habilidades para Resolver Problemas y Tomar Mejores DecisionesDe EverandSesgos Cognitivos: Una Fascinante Mirada dentro de la Psicología Humana y los Métodos para Evitar la Disonancia Cognitiva, Mejorar sus Habilidades para Resolver Problemas y Tomar Mejores DecisionesCalificación: 4.5 de 5 estrellas4.5/5 (13)
- Resumen de Pensar rápido pensar despacio de Daniel KahnemanDe EverandResumen de Pensar rápido pensar despacio de Daniel KahnemanCalificación: 4.5 de 5 estrellas4.5/5 (11)
- Las Enfermedades comienzan y terminan en tu mente: Una guía para la autosanaciónDe EverandLas Enfermedades comienzan y terminan en tu mente: Una guía para la autosanaciónCalificación: 4 de 5 estrellas4/5 (4)
- Parásitos: El extraño mundo de las criaturas más peligrosas de la naturalezaDe EverandParásitos: El extraño mundo de las criaturas más peligrosas de la naturalezaCalificación: 4.5 de 5 estrellas4.5/5 (47)
- Química orgánica: ejercicios de aplicaciónDe EverandQuímica orgánica: ejercicios de aplicaciónCalificación: 5 de 5 estrellas5/5 (3)
- Las matemáticas de la biología: De las celdas de las abejas a las simetrías de los virusDe EverandLas matemáticas de la biología: De las celdas de las abejas a las simetrías de los virusCalificación: 4 de 5 estrellas4/5 (1)
- 200 tareas en terapia breve: 2ª ediciónDe Everand200 tareas en terapia breve: 2ª ediciónCalificación: 4.5 de 5 estrellas4.5/5 (33)
- Contacto & Relación en Psicoterapia: Reflexiones sobre terapia GestaltDe EverandContacto & Relación en Psicoterapia: Reflexiones sobre terapia GestaltCalificación: 3 de 5 estrellas3/5 (2)
- El nacimiento del pensamiento científico: Anaximandro de MiletoDe EverandEl nacimiento del pensamiento científico: Anaximandro de MiletoCalificación: 4.5 de 5 estrellas4.5/5 (4)
- Grasas inteligentes: Come más grasa. Pierde más peso. Mantente más sanoDe EverandGrasas inteligentes: Come más grasa. Pierde más peso. Mantente más sanoCalificación: 4 de 5 estrellas4/5 (10)
- Neuroanatomía: Fundamentos de neuroanatomía estructural, funcional y clínicaDe EverandNeuroanatomía: Fundamentos de neuroanatomía estructural, funcional y clínicaCalificación: 4 de 5 estrellas4/5 (16)
- Un científico en el lavadero: Manchas, olores, ciencia, tecnología y suciedadDe EverandUn científico en el lavadero: Manchas, olores, ciencia, tecnología y suciedadCalificación: 5 de 5 estrellas5/5 (2)
- Psicología forense: Estudio de la mente criminalDe EverandPsicología forense: Estudio de la mente criminalCalificación: 4.5 de 5 estrellas4.5/5 (18)