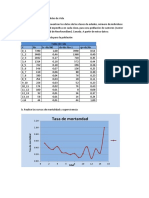
También podría gustarte
- KimberlingDocumento9 páginasKimberlingalex skalaAún no hay calificaciones
- Ejercicio en CLaseDocumento15 páginasEjercicio en CLaseMarcoOrozcoBritoAún no hay calificaciones
- Distribución Log NormalDocumento3 páginasDistribución Log Normalcarlos rodriguez bartoloAún no hay calificaciones
- Tarea 7 Caso Aplicaci N de La Regresi N Lineal y o Regresi N Lineal M LtipleDocumento5 páginasTarea 7 Caso Aplicaci N de La Regresi N Lineal y o Regresi N Lineal M LtipleRogelio Medina Rosales100% (1)
- MANUAL DE MODELACION ARIMA - Álvaro Céspedes T.Documento20 páginasMANUAL DE MODELACION ARIMA - Álvaro Céspedes T.FABIOLA DAYANA BORJA AREVALOAún no hay calificaciones
- Solución Examen FinalDocumento22 páginasSolución Examen FinalLUISA FERNANDA MANOSALVA MOYANOAún no hay calificaciones
- Variable Cuantitativa Discreta - WilsonMendozaDocumento11 páginasVariable Cuantitativa Discreta - WilsonMendozaWilson HeverlandAún no hay calificaciones
- PROBLEMAs Coimpoelto SiDocumento22 páginasPROBLEMAs Coimpoelto SiAlex Camala NinaAún no hay calificaciones
- Laboratorio - Calidad - Cepillos y LaminasDocumento9 páginasLaboratorio - Calidad - Cepillos y LaminasJeison JaraAún no hay calificaciones
- Análisis estadísticos de ventas en Modatex S.ADocumento12 páginasAnálisis estadísticos de ventas en Modatex S.AGinger Mora100% (1)
- Tarea 1Documento47 páginasTarea 1Yobana TolentinoAún no hay calificaciones
- PROBLEMA 6 - 1643912 - Jonathan VillegasDocumento2 páginasPROBLEMA 6 - 1643912 - Jonathan VillegasJonathan VillegasAún no hay calificaciones
- Taller 1Documento7 páginasTaller 1fabianAún no hay calificaciones
- Ejercicio en Clase Método Kaplan MeierDocumento4 páginasEjercicio en Clase Método Kaplan MeierTimoteoCainAún no hay calificaciones
- Problema 4Documento1 páginaProblema 4Jonathan VillegasAún no hay calificaciones
- 05a Ejemplos Dest. Equilibrio BinariosDocumento38 páginas05a Ejemplos Dest. Equilibrio BinariosMeliza Bravo CastilloAún no hay calificaciones
- Taller 1Documento12 páginasTaller 1Amparo CardenasAún no hay calificaciones
- Alfa de Cronbach y Prueba de NormalidadDocumento9 páginasAlfa de Cronbach y Prueba de Normalidadخافيير ألونسو شيروك كونتريراسAún no hay calificaciones
- Pruebas de California CMT y Wisconsin WMTDocumento7 páginasPruebas de California CMT y Wisconsin WMTMiguel AngelAún no hay calificaciones
- Inf.6-Flujo PistonDocumento10 páginasInf.6-Flujo PistonLeinaAlexandraLópezAún no hay calificaciones
- Balance de RemoliendaDocumento37 páginasBalance de RemoliendaJheny CalcinaAún no hay calificaciones
- Primera Recuperación. Bioestadística 2023Documento11 páginasPrimera Recuperación. Bioestadística 2023norman branAún no hay calificaciones
- Simulación MontecarloDocumento2 páginasSimulación MontecarloErica Adler29% (7)
- TP N4 Tablas de VidaDocumento5 páginasTP N4 Tablas de Vidaelmer taipe vargasAún no hay calificaciones
- Ejemplos de muestreo y estimación de parámetrosDocumento30 páginasEjemplos de muestreo y estimación de parámetrosANGIE JHEIMY CULQUICONDOR SALVADORAún no hay calificaciones
- Guia de Distribucion BinomialDocumento5 páginasGuia de Distribucion Binomialjanner porrasAún no hay calificaciones
- 3 Aea4257 C14 ApunteacademicoDocumento9 páginas3 Aea4257 C14 ApunteacademicoSolange DíazAún no hay calificaciones
- Ejemplos RegresionDocumento14 páginasEjemplos Regresioncecy maciazAún no hay calificaciones
- Ejercicios 910111214151618p WDocumento27 páginasEjercicios 910111214151618p Wmunicipalidad100% (3)
- Elaboración de Mermelada de PiñaDocumento3 páginasElaboración de Mermelada de PiñaNelsy Johanna Garavito JejenAún no hay calificaciones
- Informe 1Documento4 páginasInforme 1Andrés SbAún no hay calificaciones
- Trabajo Práctico: Calibración de La BuretaDocumento2 páginasTrabajo Práctico: Calibración de La BuretaEzequiel VázquezAún no hay calificaciones
- Trabajo Practico Espectroscopia Emision AtomicaDocumento4 páginasTrabajo Practico Espectroscopia Emision AtomicaBriOstoreroAún no hay calificaciones
- Solucion Practica 5 - CompletoDocumento4 páginasSolucion Practica 5 - CompletoVieri LeccaAún no hay calificaciones
- Ejercicios Propuestos Control de CalidadDocumento46 páginasEjercicios Propuestos Control de Calidadlincol huaman lopezAún no hay calificaciones
- Clases 01 2022 - Finanzas Con Excel AlumnoDocumento27 páginasClases 01 2022 - Finanzas Con Excel AlumnoJim VelasquezAún no hay calificaciones
- Pronosticos Con Funciones ExcelDocumento11 páginasPronosticos Con Funciones ExcelDamian RoblesAún no hay calificaciones
- Ejercicio Tablas de VidaDocumento3 páginasEjercicio Tablas de VidaJose Rusbel Bedoya Urrea100% (1)
- Informe IIIDocumento10 páginasInforme IIILina Maria Quevedo MoyanoAún no hay calificaciones
- Intervalo de Confianza 1Documento35 páginasIntervalo de Confianza 1Mauro Bedón SilvaAún no hay calificaciones
- Estadistica II - 1390-16-6214Documento4 páginasEstadistica II - 1390-16-6214IRVIN JOSSUE GUZMAN VILLELAAún no hay calificaciones
- Examen Io2Documento14 páginasExamen Io2Lady BarbaAún no hay calificaciones
- QSAR FarmacologíaDocumento2 páginasQSAR Farmacologíaaresquivela100% (1)
- Paso 3 Analisis de La InformacionDocumento14 páginasPaso 3 Analisis de La InformacionRubiel CandamilAún no hay calificaciones
- Gu A de Ejercicios Graficas X R Barra PDFDocumento24 páginasGu A de Ejercicios Graficas X R Barra PDFNohemy PAún no hay calificaciones
- Probabilidad de que lleguen más de 15 camionesDocumento12 páginasProbabilidad de que lleguen más de 15 camionessimon escallonAún no hay calificaciones
- Ventas ProductosDocumento6 páginasVentas ProductosVanelly Mayorga SanchezAún no hay calificaciones
- Santin Rogel SimulacionDocumento13 páginasSantin Rogel SimulacionRogel CristalAún no hay calificaciones
- TIFANNYDocumento10 páginasTIFANNYJose Maria Loango ChamorroAún no hay calificaciones
- Cadena de MarkovDocumento5 páginasCadena de MarkovOmar MartinezAún no hay calificaciones
- Taller 3 CDocumento4 páginasTaller 3 CNATALIA ORTIZ FERNANDEZAún no hay calificaciones
- Ejercicios Intervalos de Confianza (Parámetros de Dos Poblaciones)Documento3 páginasEjercicios Intervalos de Confianza (Parámetros de Dos Poblaciones)Eileen MaulénAún no hay calificaciones
- Analisis de Regresión Version 2020Documento67 páginasAnalisis de Regresión Version 2020sandra jovenAún no hay calificaciones
- Análisis ProbitDocumento4 páginasAnálisis ProbitLIliana Rodriguez De SantoyoAún no hay calificaciones
- Obst - Bioestadistica - 07Documento3 páginasObst - Bioestadistica - 07Darian MartinezAún no hay calificaciones
- UntitledDocumento8 páginasUntitledAhmed BeltranAún no hay calificaciones
- Practica 1 - Tratamiento de DatosDocumento14 páginasPractica 1 - Tratamiento de DatosLuis GuadalupeAún no hay calificaciones
- Límites de control para la tasa de errores en reclamaciones de segurosDocumento35 páginasLímites de control para la tasa de errores en reclamaciones de segurosNEYRA JOHANNA JULCA VASQUEZAún no hay calificaciones
- Cartas de control XR para variables de calidad empresarialDocumento7 páginasCartas de control XR para variables de calidad empresarialNicolas VergaraAún no hay calificaciones
- Guia Operativa de Aplicacion Del CAI Bolivia 2021Documento73 páginasGuia Operativa de Aplicacion Del CAI Bolivia 2021benjamin cutipa100% (2)
- Guía de supervisión y auditoría de datos VIHDocumento59 páginasGuía de supervisión y auditoría de datos VIHbenjamin cutipaAún no hay calificaciones
- Manual de Gestion de Riesgos Laborales MartinezDocumento285 páginasManual de Gestion de Riesgos Laborales Martinezbenjamin cutipaAún no hay calificaciones
- Aprenda A Vivir Con Diabetes LermanDocumento142 páginasAprenda A Vivir Con Diabetes Lermanbenjamin cutipaAún no hay calificaciones
- Manual para emprendedores: Calidad y productividadDocumento115 páginasManual para emprendedores: Calidad y productividadbenjamin cutipaAún no hay calificaciones
- ABCLectura CriticaDocumento97 páginasABCLectura Criticabenjamin cutipaAún no hay calificaciones
- Tecnicas e Instrumentos de Investigacion SuarezDocumento190 páginasTecnicas e Instrumentos de Investigacion Suarezbenjamin cutipa100% (1)
- Atención Primaria Integral de Salud Vega Et - AlDocumento314 páginasAtención Primaria Integral de Salud Vega Et - Albenjamin cutipaAún no hay calificaciones
- Guía de Adherencia Terapeutica en VIH SIDADocumento74 páginasGuía de Adherencia Terapeutica en VIH SIDAbenjamin cutipaAún no hay calificaciones
- Normas biomédicas comunicaciónDocumento5 páginasNormas biomédicas comunicaciónbenjamin cutipaAún no hay calificaciones
- Capacitar Atendiendo A La DemandaDocumento119 páginasCapacitar Atendiendo A La Demandabenjamin cutipaAún no hay calificaciones
- Posgrado en salud social y comunitariaDocumento218 páginasPosgrado en salud social y comunitariaJuanPabloAún no hay calificaciones
- Gestion Estrategica de La Calidad de Los Servicios Sanitarios - Jaime Varo PDFDocumento529 páginasGestion Estrategica de La Calidad de Los Servicios Sanitarios - Jaime Varo PDFSaul Vaca Villarroel87% (23)
- Gestion Clinica Desarrollo e Instrumentos OteoDocumento403 páginasGestion Clinica Desarrollo e Instrumentos Oteobenjamin cutipaAún no hay calificaciones
- Lectura Critica de Articulos CientificosDocumento77 páginasLectura Critica de Articulos Cientificosbenjamin cutipaAún no hay calificaciones
- 7 (1) 169 187Documento19 páginas7 (1) 169 187Luiz Requejo EstebanAún no hay calificaciones
- Informe Sobre La Investigación Clínica en Personas InstitucionalizadasDocumento33 páginasInforme Sobre La Investigación Clínica en Personas InstitucionalizadasAsociación Lazos Pro SolidariedadeAún no hay calificaciones
- Liborio - Definiciones de EpidemiologíaDocumento8 páginasLiborio - Definiciones de EpidemiologíaBelén BenítezAún no hay calificaciones
- DiezPasosLactanciaDocumento91 páginasDiezPasosLactanciabenjamin cutipaAún no hay calificaciones
- 0682 Estudios Epidemiológicos (STROBE) PDFDocumento6 páginas0682 Estudios Epidemiológicos (STROBE) PDFLaura Nathalia BuitragoAún no hay calificaciones
- Determinantes Culturales de La SaludDocumento4 páginasDeterminantes Culturales de La Saludbenjamin cutipaAún no hay calificaciones
- Likelihood Ratio. Definición y AplicaciónDocumento5 páginasLikelihood Ratio. Definición y AplicaciónmarcelasofiaAún no hay calificaciones
- Entrevista A J. BreihlDocumento8 páginasEntrevista A J. Breihlbenjamin cutipaAún no hay calificaciones
- Buen Vivir y Politica de Salud J. BreihlDocumento10 páginasBuen Vivir y Politica de Salud J. Breihlbenjamin cutipaAún no hay calificaciones
- Algoritmo diagnóstico VIH avances hallazgosDocumento9 páginasAlgoritmo diagnóstico VIH avances hallazgosbenjamin cutipaAún no hay calificaciones
- Epidemiología ClasicaDocumento16 páginasEpidemiología ClasicaBárbara Emperatriz Escobar Gámez100% (2)
- Atencion Del RN Expuesto Al VIH Dra. CalderonDocumento58 páginasAtencion Del RN Expuesto Al VIH Dra. Calderonbenjamin cutipaAún no hay calificaciones
- Actualizacion Manejo VIH en Niños Dr. J. RodriguezDocumento72 páginasActualizacion Manejo VIH en Niños Dr. J. Rodriguezbenjamin cutipaAún no hay calificaciones
- Factores que determinan la adherencia a la terapia antirretroviralDocumento35 páginasFactores que determinan la adherencia a la terapia antirretroviralbenjamin cutipaAún no hay calificaciones
- Autoeficacia niños adolescentesDocumento22 páginasAutoeficacia niños adolescentesArelycarOlina Verdugo0% (1)
- Recomendaciones SSTDocumento2 páginasRecomendaciones SSTpaulo536100% (1)
- It-2000 FolletoDocumento12 páginasIt-2000 FolletoEva TelloAún no hay calificaciones
- Gth-So-M-F - 002sd Fichas Tecnicas EppDocumento9 páginasGth-So-M-F - 002sd Fichas Tecnicas EppNinis YanceAún no hay calificaciones
- Wa0045Documento3 páginasWa0045ANDRES BAHAMONAún no hay calificaciones
- TAREA 3 - Psicobiología y Sus AplicacionesDocumento8 páginasTAREA 3 - Psicobiología y Sus AplicacionesAndrea katherine Motta vargasAún no hay calificaciones
- Formatos Corporativos - Actualizado - 02.08.22Documento30 páginasFormatos Corporativos - Actualizado - 02.08.22Jesus Franco PachasAún no hay calificaciones
- La Escuela InclusivaDocumento4 páginasLa Escuela InclusivaDiana CorenaAún no hay calificaciones
- La Unidad de Cuidados PostanestesicosDocumento12 páginasLa Unidad de Cuidados PostanestesicosSergio Alejandro Andrade100% (1)
- Caso Clinico GeriatricoDocumento43 páginasCaso Clinico Geriatricodaniela suarezAún no hay calificaciones
- REGLAMENTO Y ANEXOS - CompressedDocumento21 páginasREGLAMENTO Y ANEXOS - CompressedDenis Choque IllanesAún no hay calificaciones
- 2.procedimiento de Primeros AuxiliosDocumento13 páginas2.procedimiento de Primeros AuxiliosConstructora DPCAún no hay calificaciones
- Plan Operativo Anual y Presupuesto 2024 Original A EntregarDocumento42 páginasPlan Operativo Anual y Presupuesto 2024 Original A EntregarRenan MerinoAún no hay calificaciones
- Emprendimiento y Autogestión laboralDocumento5 páginasEmprendimiento y Autogestión laboralFederico BisbalAún no hay calificaciones
- Poder de La Mente para Curar o Enfermar El CuerpoDocumento4 páginasPoder de La Mente para Curar o Enfermar El CuerpoSANCUILMAS78480% (1)
- Ensayo EpilepsiaDocumento12 páginasEnsayo EpilepsiaJaqueline Godoy Alvarado100% (1)
- Sarampión: Enfermedad viral aguda eruptivaDocumento21 páginasSarampión: Enfermedad viral aguda eruptivaJohnny Alvarez JaraAún no hay calificaciones
- Pólipos en Cuerdas Vocales - Pólipos Nasales y SinusalesDocumento2 páginasPólipos en Cuerdas Vocales - Pólipos Nasales y SinusalesRoberto BigliaAún no hay calificaciones
- Anexo 8 Metodo Seguro de Trabajo Ejemplo 3Documento3 páginasAnexo 8 Metodo Seguro de Trabajo Ejemplo 3ZatieldAún no hay calificaciones
- Article - Temperamento Temprano y Desarrollo PsicosocialDocumento6 páginasArticle - Temperamento Temprano y Desarrollo PsicosocialloretoalAún no hay calificaciones
- Acentuacion GeneralDocumento4 páginasAcentuacion GeneralFA Jesús JesusAún no hay calificaciones
- Trabajo Desarrollo y Ciclo VitalDocumento11 páginasTrabajo Desarrollo y Ciclo VitalKatherine AriasAún no hay calificaciones
- Abedijena Bienestar, Org. Cont. Tortas 80 Venta e InstalaciónDocumento6 páginasAbedijena Bienestar, Org. Cont. Tortas 80 Venta e Instalación14007Aún no hay calificaciones
- Ejercicios PracticosDocumento3 páginasEjercicios PracticosCristián Alejandro Pino MolinaAún no hay calificaciones
- Exudado Vaginal CompletoDocumento8 páginasExudado Vaginal CompletoAlfonso De la FuenteAún no hay calificaciones
- Estilo de Vida SaludableDocumento23 páginasEstilo de Vida SaludableVanessa Ramos OchoaAún no hay calificaciones
- Organizador Gráfico Mapa Conceptual Creativo RosaDocumento10 páginasOrganizador Gráfico Mapa Conceptual Creativo RosaJP ArowAún no hay calificaciones
- Evaluación del dolor en caballosDocumento4 páginasEvaluación del dolor en caballosPatricia GameroAún no hay calificaciones
- Tesis 1 PDFDocumento187 páginasTesis 1 PDFRocio Calderon SanchezAún no hay calificaciones
- Cuidado al adulto mayor y salud mentalDocumento3 páginasCuidado al adulto mayor y salud mentalCarolane DuarteAún no hay calificaciones
- Problemas de física general en un año olímpicoDe EverandProblemas de física general en un año olímpicoCalificación: 5 de 5 estrellas5/5 (1)
- Estadística básica: Introducción a la estadística con RDe EverandEstadística básica: Introducción a la estadística con RCalificación: 5 de 5 estrellas5/5 (8)
- La guía definitiva en Matemáticas para el Ingreso al BachilleratoDe EverandLa guía definitiva en Matemáticas para el Ingreso al BachilleratoCalificación: 4.5 de 5 estrellas4.5/5 (9)
- La Biblia de las Matemáticas RápidasDe EverandLa Biblia de las Matemáticas RápidasCalificación: 4.5 de 5 estrellas4.5/5 (19)
- Psicoterapia psicoanalítica: Investigación, evaluación y práctica clínicaDe EverandPsicoterapia psicoanalítica: Investigación, evaluación y práctica clínicaAún no hay calificaciones
- Cuántica: Qué significa la teoría de la ciencia más extrañaDe EverandCuántica: Qué significa la teoría de la ciencia más extrañaCalificación: 1 de 5 estrellas1/5 (1)
- Sesgos Cognitivos: Una Fascinante Mirada dentro de la Psicología Humana y los Métodos para Evitar la Disonancia Cognitiva, Mejorar sus Habilidades para Resolver Problemas y Tomar Mejores DecisionesDe EverandSesgos Cognitivos: Una Fascinante Mirada dentro de la Psicología Humana y los Métodos para Evitar la Disonancia Cognitiva, Mejorar sus Habilidades para Resolver Problemas y Tomar Mejores DecisionesCalificación: 4.5 de 5 estrellas4.5/5 (13)
- El físico y el filósofo: Albert Einstein, Henri Bergson y el debate que cambió nuestra comprensión del tiempoDe EverandEl físico y el filósofo: Albert Einstein, Henri Bergson y el debate que cambió nuestra comprensión del tiempoAún no hay calificaciones
- Control de calidad. Un enfoque integral y estadísticoDe EverandControl de calidad. Un enfoque integral y estadísticoCalificación: 5 de 5 estrellas5/5 (8)
- Curso rápido sobre magia del caos. El hobby oculto de ricos y famosos.De EverandCurso rápido sobre magia del caos. El hobby oculto de ricos y famosos.Calificación: 5 de 5 estrellas5/5 (42)
- Mentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraDe EverandMentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraCalificación: 4.5 de 5 estrellas4.5/5 (5)
- Metodología de la investigación científicaDe EverandMetodología de la investigación científicaCalificación: 3.5 de 5 estrellas3.5/5 (7)
- La Teoría de Conjuntos y los Fundamentos de las MatemáticasDe EverandLa Teoría de Conjuntos y los Fundamentos de las MatemáticasCalificación: 5 de 5 estrellas5/5 (1)
- Qué es (y qué no es) la estadística: Usos y abusos de una disciplina clave en la vida de los países y las personasDe EverandQué es (y qué no es) la estadística: Usos y abusos de una disciplina clave en la vida de los países y las personasCalificación: 4.5 de 5 estrellas4.5/5 (3)
- El cerebro matemático: Cómo nacen, viven y a veces mueren los números en nuestra menteDe EverandEl cerebro matemático: Cómo nacen, viven y a veces mueren los números en nuestra menteCalificación: 4 de 5 estrellas4/5 (5)
- Nuevo manual de Reflexología: El método más completo y actual sobre las técnicas, la práctica y la teoría de la ciencia reflexológicaDe EverandNuevo manual de Reflexología: El método más completo y actual sobre las técnicas, la práctica y la teoría de la ciencia reflexológicaCalificación: 4.5 de 5 estrellas4.5/5 (16)
- Visualización: Cambie su vida en cuatro semanas utilizando la ley de atracciónDe EverandVisualización: Cambie su vida en cuatro semanas utilizando la ley de atracciónCalificación: 5 de 5 estrellas5/5 (18)
- Enseñar Matemática hoy: Miradas, sentidos y desafíosDe EverandEnseñar Matemática hoy: Miradas, sentidos y desafíosCalificación: 5 de 5 estrellas5/5 (1)
- Análisis estructural mediante el método de los elementos finitos. Introducción al comportamiento lineal elásticoDe EverandAnálisis estructural mediante el método de los elementos finitos. Introducción al comportamiento lineal elásticoCalificación: 4.5 de 5 estrellas4.5/5 (12)
- Álgebra lineal aplicada a las ciencias económicas 2edDe EverandÁlgebra lineal aplicada a las ciencias económicas 2edCalificación: 4 de 5 estrellas4/5 (1)
- Matemáticas financierasDe EverandMatemáticas financierasCalificación: 4 de 5 estrellas4/5 (7)
- Electricidad: Fundamentos y problemas de electrostática, corriente continua, electromagnetiDe EverandElectricidad: Fundamentos y problemas de electrostática, corriente continua, electromagnetiCalificación: 3.5 de 5 estrellas3.5/5 (5)