También podría gustarte
- Analisis de Un Modelo Macroeconómico Dinámico de Mediano PlazoDocumento20 páginasAnalisis de Un Modelo Macroeconómico Dinámico de Mediano PlazoAndres David MgAún no hay calificaciones
- Caso Cánada PackersDocumento3 páginasCaso Cánada Packersjaime9lorzaAún no hay calificaciones
- Teoria Del Equilibrio GeneralDocumento8 páginasTeoria Del Equilibrio Generalhernan123456Aún no hay calificaciones
- Dinamica Actual de Las Finanzas InternacionalesDocumento9 páginasDinamica Actual de Las Finanzas Internacionalesmargier0% (1)
- Demanda de DineroDocumento3 páginasDemanda de DineroWanderlin Acosta EustaquioAún no hay calificaciones
- Desarrollo de Cuestionario de Preguntas, Cap8 Del Libro Administración Financiera Internacional (Recuperado Automáticamente)Documento3 páginasDesarrollo de Cuestionario de Preguntas, Cap8 Del Libro Administración Financiera Internacional (Recuperado Automáticamente)MARJORIE ESTEFANIA CASTRO PESANTEZAún no hay calificaciones
- Cuestionario Cap4,5,6-1Documento5 páginasCuestionario Cap4,5,6-1isabel gonzalezAún no hay calificaciones
- Curva de PhillipsDocumento3 páginasCurva de PhillipsDayana MatabajoyAún no hay calificaciones
- Shock Externos e Internos Política Económica IiDocumento26 páginasShock Externos e Internos Política Económica IiMary RD FrancoAún no hay calificaciones
- Factores Especificos y Distribucion de La RentaDocumento33 páginasFactores Especificos y Distribucion de La RentaCarlos GonzalesAún no hay calificaciones
- El Efectivo EmpresarialDocumento13 páginasEl Efectivo EmpresarialWil Fabi LaguatasigAún no hay calificaciones
- Visión panorámica de la macroeconomía: objetivos, instrumentos y equilibrioDocumento19 páginasVisión panorámica de la macroeconomía: objetivos, instrumentos y equilibrioLaura Isabel Ozuna100% (1)
- Actividad 7 Finanzas IntDocumento3 páginasActividad 7 Finanzas IntperyorjAún no hay calificaciones
- Syllabus Desarrollo Modelo NegocioDocumento8 páginasSyllabus Desarrollo Modelo NegociosandraAún no hay calificaciones
- Elasticidad y Tecnicas de ProyeccionDocumento12 páginasElasticidad y Tecnicas de ProyeccionRodrigo Saraya SalasAún no hay calificaciones
- Usando El Material de ReferenciaDocumento4 páginasUsando El Material de Referenciajennifher100% (1)
- Teorías Del Comercio InternacionalDocumento3 páginasTeorías Del Comercio InternacionalArmando AC0% (1)
- El Sistema MonetariocompletoDocumento8 páginasEl Sistema MonetariocompletoAnonymous XvDEeI8Aún no hay calificaciones
- TEMA 4.1 Apuntes HeterocedasticidadDocumento16 páginasTEMA 4.1 Apuntes HeterocedasticidadLeonelHerediaAltamiranoAún no hay calificaciones
- Preguntas Capítulo 1Documento4 páginasPreguntas Capítulo 1TEAM DRSAún no hay calificaciones
- Estado Actual de Los Paises Emergentes PDFDocumento8 páginasEstado Actual de Los Paises Emergentes PDFEdredones EymAún no hay calificaciones
- Ensayo Economia InternacionalDocumento2 páginasEnsayo Economia InternacionalCatherin MurciaAún no hay calificaciones
- Modelo HO y Teorema Stolper-Samuelson - Semana 4Documento35 páginasModelo HO y Teorema Stolper-Samuelson - Semana 4Contabilidad y FinanzasAún no hay calificaciones
- Microeconomía Aplicada (Comercio Internacional)Documento8 páginasMicroeconomía Aplicada (Comercio Internacional)MarcoErazo0% (1)
- El Dinero - MacroDocumento2 páginasEl Dinero - MacropetersudAún no hay calificaciones
- Ensayo Economia Global 1Documento6 páginasEnsayo Economia Global 1Lizi SánchezAún no hay calificaciones
- Matemáticas Financieras Básicas Con Excel para UJDocumento60 páginasMatemáticas Financieras Básicas Con Excel para UJEduard Daniel Guerrero Castaño0% (1)
- Tema 1. La Economía. Una Visión Global.Documento9 páginasTema 1. La Economía. Una Visión Global.Nerea Punzano DíazAún no hay calificaciones
- Determinación de Los Precios de Los Factores de La Producción.Documento8 páginasDeterminación de Los Precios de Los Factores de La Producción.Resolviendote PanamáAún no hay calificaciones
- Programa de TrabajoDocumento9 páginasPrograma de TrabajoWing's Kings Los Reyes del SaborAún no hay calificaciones
- Precios PredatoriosDocumento2 páginasPrecios Predatorioschapadany100% (1)
- Modelo Kaldor Enfoque Cambridge PDFDocumento8 páginasModelo Kaldor Enfoque Cambridge PDFEli_Lindemann20sAún no hay calificaciones
- El Ceteris ParibusDocumento1 páginaEl Ceteris ParibusCreditech SA Prestamos100% (1)
- Resolución técnica 8 - Estados contablesDocumento10 páginasResolución técnica 8 - Estados contablessvxzxvxzvxzvvAún no hay calificaciones
- Riesgo Economico y FinancieroDocumento34 páginasRiesgo Economico y FinancieroLUZ ARACELI GARCÍA CASTILLOAún no hay calificaciones
- Ensayo Regimen CambiarioDocumento3 páginasEnsayo Regimen CambiarioZayda Patricia GarciaAún no hay calificaciones
- Contrato 1Documento4 páginasContrato 1Wilson Alberto Torres CalleAún no hay calificaciones
- Banca Comercial y de DesarrolloDocumento31 páginasBanca Comercial y de DesarrolloJESUS MORALESAún no hay calificaciones
- Tema 4 - Modelo KanoDocumento23 páginasTema 4 - Modelo KanoKarenina PittiAún no hay calificaciones
- Finanzas corporativas: Activos financieros y riesgos de deudaDocumento12 páginasFinanzas corporativas: Activos financieros y riesgos de deudaIngRichard Inoa JimenezAún no hay calificaciones
- Dinamica Del Tipo de Cambio - Modelo de Sobrerreaccion (Overshooting)Documento52 páginasDinamica Del Tipo de Cambio - Modelo de Sobrerreaccion (Overshooting)FAUSTINOESTEBANAún no hay calificaciones
- Análisis Balanza de Pagos EcuadorDocumento14 páginasAnálisis Balanza de Pagos EcuadorEduardo AlarcónAún no hay calificaciones
- Las MultibancasDocumento12 páginasLas MultibancasSafiva JohnAún no hay calificaciones
- Las Razones Financieras Pueden Clasificarse en Los Siguientes GruposDocumento4 páginasLas Razones Financieras Pueden Clasificarse en Los Siguientes Gruposjuan444444Aún no hay calificaciones
- La Globalizacion y Su Impacto en Las EmpresasDocumento5 páginasLa Globalizacion y Su Impacto en Las EmpresasCharly MtzAún no hay calificaciones
- Pasos Box-Jenkings raíz unitaria ARIMA ARMADocumento20 páginasPasos Box-Jenkings raíz unitaria ARIMA ARMAAkemi Espinoza ParedesAún no hay calificaciones
- Ensayo FinanzasDocumento4 páginasEnsayo FinanzasJeniffer Mollohuanca FloresAún no hay calificaciones
- Taller 3 (1) MacroDocumento13 páginasTaller 3 (1) MacroLina Chiquillo67% (6)
- Finanzas Internac-2do Parcial-2013 (Alumnos)Documento2 páginasFinanzas Internac-2do Parcial-2013 (Alumnos)Juan Manuel Garcia Candiota75% (4)
- Microsoft Word - MODULO 3 Finanzas 20 MarzoDocumento148 páginasMicrosoft Word - MODULO 3 Finanzas 20 MarzoJUVENTINO CAJICAAún no hay calificaciones
- Sesión 03 PDFDocumento38 páginasSesión 03 PDFHermanos Julcamoro CortezAún no hay calificaciones
- Analisis Costo BeneficioDocumento7 páginasAnalisis Costo Beneficior2d2_meAún no hay calificaciones
- 03 El Entorno Del MarketingDocumento8 páginas03 El Entorno Del MarketingEdgar Melo RodriguezAún no hay calificaciones
- Efectos de Las Políticas Monetaria y Fiscal en El Modelo IS-LMDocumento7 páginasEfectos de Las Políticas Monetaria y Fiscal en El Modelo IS-LMlaegp0009Aún no hay calificaciones
- Ensayo Deuda PúblicaDocumento1 páginaEnsayo Deuda PúblicaImed SanchezAún no hay calificaciones
- Naturaleza Del Análisis de RegresiónDocumento16 páginasNaturaleza Del Análisis de Regresiónhsaavedras100% (1)
- Poster AbpDocumento1 páginaPoster AbpnataliaAún no hay calificaciones
- Modelos ARIMA conceptosDocumento12 páginasModelos ARIMA conceptosVicenteZunigaAún no hay calificaciones
- Metodo ArimaDocumento21 páginasMetodo ArimaErik Ayala LeonAún no hay calificaciones
- Arima y SarimaDocumento6 páginasArima y SarimaJeniffer Párraga100% (1)
- rESPONSABILIDAD SOCIALDocumento2 páginasrESPONSABILIDAD SOCIALAndrea AguileraAún no hay calificaciones
- Grupos de Interés SantanderDocumento2 páginasGrupos de Interés SantanderAndrea AguileraAún no hay calificaciones
- QuizDocumento1 páginaQuizAndrea AguileraAún no hay calificaciones
- ISO 26000 SantanderDocumento11 páginasISO 26000 SantanderAndrea AguileraAún no hay calificaciones
- ProyectoFinal CIDocumento14 páginasProyectoFinal CIAndrea AguileraAún no hay calificaciones
- Tarea 1 CalificadaDocumento10 páginasTarea 1 CalificadaAndrea AguileraAún no hay calificaciones
- Proyecto Final OIDocumento14 páginasProyecto Final OIAndrea AguileraAún no hay calificaciones
- Regulacion de Competencia Economica BrazilDocumento13 páginasRegulacion de Competencia Economica BrazilAndrea AguileraAún no hay calificaciones
- Desarrollo SostenibleDocumento5 páginasDesarrollo SostenibleAndrea AguileraAún no hay calificaciones
- Análisis Económico Hospital Post-CovidDocumento3 páginasAnálisis Económico Hospital Post-CovidAndrea AguileraAún no hay calificaciones
- Rut Frisby Sa Bic 22 Dic 22 H1Documento1 páginaRut Frisby Sa Bic 22 Dic 22 H1YaneryAún no hay calificaciones
- EJERCICIOS CAPITULO 4 PAGINAS 91 Y 92 VALUACION A LARGO PLAZO RevDocumento4 páginasEJERCICIOS CAPITULO 4 PAGINAS 91 Y 92 VALUACION A LARGO PLAZO RevMartha BrunAún no hay calificaciones
- Qué es la contabilidad? guía completaDocumento9 páginasQué es la contabilidad? guía completaKary GarcíaAún no hay calificaciones
- Contabilidad financiera III - Ejercicios inventarios, PPE y diferidosDocumento6 páginasContabilidad financiera III - Ejercicios inventarios, PPE y diferidosMauricio Castellanos DelgadoAún no hay calificaciones
- MII517 S1 EntregableDocumento3 páginasMII517 S1 EntregableJavier Mardones D'Appollonio100% (2)
- EMPLEABILIDADDDDocumento19 páginasEMPLEABILIDADDDApolosHidalgoCalderonAún no hay calificaciones
- Planes de pago por destajo y horas estándaresDocumento51 páginasPlanes de pago por destajo y horas estándaresfabian100% (1)
- Jacinto GutierrezDocumento3 páginasJacinto GutierrezDiego GrijalbaAún no hay calificaciones
- Pronosticos tasas interes bonos AAADocumento3 páginasPronosticos tasas interes bonos AAAWorld QuinteroAún no hay calificaciones
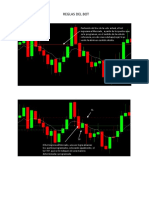
- Reglas Bot David CasasDocumento3 páginasReglas Bot David CasasLuis BaicueAún no hay calificaciones
- Qaliwarma Abril 2023Documento3 páginasQaliwarma Abril 2023Aracely Fuentes CongacheAún no hay calificaciones
- 2020 Produccion I Sesion19 032320 Practica Pepe JeansDocumento3 páginas2020 Produccion I Sesion19 032320 Practica Pepe JeansMarcos Rodrigo CordobaAún no hay calificaciones
- Social Media Community ManagersDocumento7 páginasSocial Media Community ManagersalysmarAún no hay calificaciones
- Examen Final Costos 2020Documento5 páginasExamen Final Costos 2020Laura Rivera100% (1)
- Diapositivas 3 PDFDocumento38 páginasDiapositivas 3 PDFMelany AndradeAún no hay calificaciones
- Taller N°1 - Dulcería La SonrisaDocumento2 páginasTaller N°1 - Dulcería La Sonrisalina mariaAún no hay calificaciones
- Indice de Cap. y Reglas Generales de ClasificacionDocumento7 páginasIndice de Cap. y Reglas Generales de ClasificacionNicolás Arroyo GAún no hay calificaciones
- Pagos Provisionales Personas MoralesDocumento11 páginasPagos Provisionales Personas MoralesJOSE GAMES TRUCKAún no hay calificaciones
- Ejercicio No. 22 - Almacen Las GuacamayasDocumento6 páginasEjercicio No. 22 - Almacen Las GuacamayasJuan José100% (1)
- Universidad Tecnológica de HondurasDocumento6 páginasUniversidad Tecnológica de HondurasLizbeth S. CastellonAún no hay calificaciones
- CPhacoyd CachkjDocumento199 páginasCPhacoyd CachkjGINO ARTURO MAMANI MENDOZAAún no hay calificaciones
- Surgimiento de La BancaDocumento11 páginasSurgimiento de La BancaJair AlonsoAún no hay calificaciones
- Contrato de MutuoDocumento12 páginasContrato de Mutuofrets100% (1)
- Analisis - Top - Down 04.04.2022 FINALDocumento47 páginasAnalisis - Top - Down 04.04.2022 FINALyusuni diazAún no hay calificaciones
- Financiación - TRACER 7Documento1 páginaFinanciación - TRACER 7AlbarianAún no hay calificaciones
- Act 8. Estimaciones Puntual y Por IntervaloDocumento6 páginasAct 8. Estimaciones Puntual y Por IntervaloTALAVERA MENDEZ MIGUEL ANGELAún no hay calificaciones
- Solucion FinalDocumento24 páginasSolucion FinalEduardo Maquera MurrugarraAún no hay calificaciones
- 2019 Flores-MedinaDocumento330 páginas2019 Flores-MedinaElar Hancco QuispeAún no hay calificaciones
- Conta CorporativaDocumento15 páginasConta CorporativaKaryto MitesAún no hay calificaciones
- Casos Punto de EquilibrioDocumento6 páginasCasos Punto de EquilibrioFredy MauricioAún no hay calificaciones