También podría gustarte
- Resumen de Introducción a la Lógica y al Método Científico de Cohen y Nagel: RESÚMENES UNIVERSITARIOSDe EverandResumen de Introducción a la Lógica y al Método Científico de Cohen y Nagel: RESÚMENES UNIVERSITARIOSCalificación: 1 de 5 estrellas1/5 (1)
- Cheque EscolarDocumento22 páginasCheque EscolarAnonymous f4KdOpVwP0Aún no hay calificaciones
- Resumen Del Capitulo IiDocumento4 páginasResumen Del Capitulo IisaritaAún no hay calificaciones
- Alimentación: falsos mitos y engaños del marketingDe EverandAlimentación: falsos mitos y engaños del marketingAún no hay calificaciones
- Ficha Conceptos - y - Problemas - Que - Estudia - La - Economia - 1Documento24 páginasFicha Conceptos - y - Problemas - Que - Estudia - La - Economia - 1pablo1999-8Aún no hay calificaciones
- Epistemología y Psicoanálisis Vol. II: Análisis del psicoanálisisDe EverandEpistemología y Psicoanálisis Vol. II: Análisis del psicoanálisisCalificación: 5 de 5 estrellas5/5 (1)
- Cap 2 - ResumenDocumento9 páginasCap 2 - ResumenalanAún no hay calificaciones
- Oscar - Villalobos - Tarea 1 Fundamentos de EconomiaDocumento8 páginasOscar - Villalobos - Tarea 1 Fundamentos de EconomiaZamaritano Noble67% (6)
- Economía, 8va. Edición - David Begg-.PDF Versión 1Documento20 páginasEconomía, 8va. Edición - David Begg-.PDF Versión 1Alejo GarceteAún no hay calificaciones
- Capitulo 1 - Pensando Como Un Economista PDFDocumento6 páginasCapitulo 1 - Pensando Como Un Economista PDFAndrewEcO5Aún no hay calificaciones
- TRADUCIDO KellstedtDocumento12 páginasTRADUCIDO KellstedtPara DatosAún no hay calificaciones
- Discurso Hayek Nobel 1974 EspañolDocumento9 páginasDiscurso Hayek Nobel 1974 Españoljesus bezanilla100% (1)
- La Hipotesis Científica Variables Errores Más Comunes.Documento8 páginasLa Hipotesis Científica Variables Errores Más Comunes.JomaraAún no hay calificaciones
- Hayek La Pretensión Del ConocimientoDocumento10 páginasHayek La Pretensión Del ConocimientoFernando Sebastian Gallardo CortesAún no hay calificaciones
- Tema I. Concepto y Método de La EconomíaDocumento16 páginasTema I. Concepto y Método de La Economíalucisanchez121104Aún no hay calificaciones
- Tema 2 OpoDocumento17 páginasTema 2 OpoDaniel MayoAún no hay calificaciones
- 09 Hayek - La Pretension Del ConocimientoDocumento9 páginas09 Hayek - La Pretension Del ConocimientoElie Angles MontoyaAún no hay calificaciones
- Economia Aplicada 2Documento19 páginasEconomia Aplicada 2Sandra Escobar100% (1)
- La Economía Positiva y NormativaDocumento4 páginasLa Economía Positiva y NormativaAlessandra Jara Nicolas67% (12)
- Ensayo Naturaleza de La EconometríaDocumento12 páginasEnsayo Naturaleza de La EconometríaWeimar Fernando Zona RodriguezAún no hay calificaciones
- HIPÓTESISDocumento4 páginasHIPÓTESISNadia HoraneAún no hay calificaciones
- Generación de HipótesisDocumento3 páginasGeneración de Hipótesisflare_mx7069Aún no hay calificaciones
- Investigación EconomíaDocumento13 páginasInvestigación EconomíaHeather CarrAún no hay calificaciones
- De Qué Sirve La Teoría Económica-Teoria de JuegosDocumento14 páginasDe Qué Sirve La Teoría Económica-Teoria de JuegosAndres EscobarAún no hay calificaciones
- Qué Es La EconometríaDocumento6 páginasQué Es La EconometríaJhael AucachiAún no hay calificaciones
- Pruebas de hipótesis: tipos, errores y ejemplosDocumento16 páginasPruebas de hipótesis: tipos, errores y ejemplosAxel Brian Wilson AlonsoAún no hay calificaciones
- Matemáticas en ciencias sociales: su importancia en economía y sociologíaDocumento10 páginasMatemáticas en ciencias sociales: su importancia en economía y sociologíaKoralys BonillaAún no hay calificaciones
- Rethinking Economics - En.españolDocumento12 páginasRethinking Economics - En.españolValeria Caparó SalasAún no hay calificaciones
- Resumen Capítulo 1 GujaratiDocumento3 páginasResumen Capítulo 1 GujaratiCarlos GarciaAún no hay calificaciones
- Microeconomia MelinaDocumento1 páginaMicroeconomia MelinaEdsn Samuel UrdayAún no hay calificaciones
- Zepeda Eduardo Aplicacionpractica A2Documento9 páginasZepeda Eduardo Aplicacionpractica A2Cecilia Merari Zepeda FerreraAún no hay calificaciones
- Comprobacion de Una TeoriaDocumento13 páginasComprobacion de Una TeoriaFabianAún no hay calificaciones
- Pensar Como EconomistaDocumento1 páginaPensar Como EconomistaJesús Rodarte CuevasAún no hay calificaciones
- ¿Qué significa pensar como economista_Documento3 páginas¿Qué significa pensar como economista_damian.mirandaladAún no hay calificaciones
- Ensayo Econometría BásicaDocumento11 páginasEnsayo Econometría BásicaAlejandra G. SalgueroAún no hay calificaciones
- El Método Científico en La EconomíaDocumento4 páginasEl Método Científico en La EconomíarosarioAún no hay calificaciones
- Causalidad en Ciencias SocialesDocumento20 páginasCausalidad en Ciencias SocialesDiana ArévaloAún no hay calificaciones
- Conceptos Básicos de EconomíaDocumento5 páginasConceptos Básicos de EconomíaFernando Chacón M.Aún no hay calificaciones
- Daniel Peña Sánchez de RiveraDocumento10 páginasDaniel Peña Sánchez de RiveraGabriela GrajalesAún no hay calificaciones
- Introducción A La EconomíaDocumento17 páginasIntroducción A La EconomíaCesar LunaAún no hay calificaciones
- Correlación vs causalidad: Entendiendo la diferenciaDocumento14 páginasCorrelación vs causalidad: Entendiendo la diferenciaErasmo Avellaneda UnesrAún no hay calificaciones
- Leyes de mercado y oferta demandaDocumento3 páginasLeyes de mercado y oferta demandaFrancisco AlbertoAún no hay calificaciones
- AA Mankiw Cap 2 - WatermarkedDocumento9 páginasAA Mankiw Cap 2 - Watermarkedvalgomez2305Aún no hay calificaciones
- Probabilidad EstadisticaDocumento4 páginasProbabilidad EstadisticaTareas AgoraAún no hay calificaciones
- Ensayo de Las Teorías EconómicasDocumento7 páginasEnsayo de Las Teorías Económicasアベル ベルトランAún no hay calificaciones
- Trabajo Investigación Cuantitativa 241109Documento11 páginasTrabajo Investigación Cuantitativa 241109Lina ManriqueAún no hay calificaciones
- Resumencaptulo2mankiw 170613222448Documento7 páginasResumencaptulo2mankiw 170613222448Camila Francisca ÁlvarezAún no hay calificaciones
- I.3 RAGIN Métodos cuantitativos 213-221Documento5 páginasI.3 RAGIN Métodos cuantitativos 213-221Ana Belén MedinaAún no hay calificaciones
- Apuntes de Microeconomía I Juan Carlos AguadoDocumento114 páginasApuntes de Microeconomía I Juan Carlos AguadoDaniel AndresAún no hay calificaciones
- Cap 2 Analisis Economia de MKDDocumento12 páginasCap 2 Analisis Economia de MKDPatricia UicabAún no hay calificaciones
- Nociones básicas de economía VenezuelaDocumento19 páginasNociones básicas de economía Venezuelamoises eduardo ventura valderreyAún no hay calificaciones
- EconometriaDocumento3 páginasEconometriaJuana DuarteAún no hay calificaciones
- Clase #02 - Naturaleza Del Anàlisis de RegresiònDocumento34 páginasClase #02 - Naturaleza Del Anàlisis de RegresiònFREDERIC REY YACILA LUNAAún no hay calificaciones
- Hipótesis en investigaciónDocumento6 páginasHipótesis en investigaciónDanyRedAceAún no hay calificaciones
- El Modelo de Regresión Lineal Clásico Con Dos VariablesDocumento18 páginasEl Modelo de Regresión Lineal Clásico Con Dos VariablesKevo Pérez GarcíaAún no hay calificaciones
- Indicador de Calidad en EspañolDocumento14 páginasIndicador de Calidad en EspañolCarlos PeraltaAún no hay calificaciones
- Algunas Reflexiones en Torno A Las Técnicas EconométricasDocumento19 páginasAlgunas Reflexiones en Torno A Las Técnicas EconométricasCarlos MendietaAún no hay calificaciones
- Elección marginal y beneficiosDocumento4 páginasElección marginal y beneficiosLopez Pacheco AlfonsoAún no hay calificaciones
- 2estadistica BasicaDocumento112 páginas2estadistica BasicaGaby IniestaAún no hay calificaciones
- Micro 3 - La Función de UtilidadDocumento30 páginasMicro 3 - La Función de Utilidadmarielarenzi75Aún no hay calificaciones
- Micro 4 - La Función de Utilidad - Parte IIDocumento23 páginasMicro 4 - La Función de Utilidad - Parte IImarielarenzi75Aún no hay calificaciones
- GUIA PRACTICA Microeconomia Curso 250_1ºC2023_AK_LSDocumento16 páginasGUIA PRACTICA Microeconomia Curso 250_1ºC2023_AK_LSmarielarenzi75Aún no hay calificaciones
- EnteDocumento13 páginasEntemarielarenzi75Aún no hay calificaciones
- clase del 28 de marzo de 2023Documento6 páginasclase del 28 de marzo de 2023marielarenzi75Aún no hay calificaciones
- CLASE 2 2 2023Documento8 páginasCLASE 2 2 2023marielarenzi75Aún no hay calificaciones
- cronogramaDocumento2 páginascronogramamarielarenzi75Aún no hay calificaciones
- Practica 2 LimiteDocumento9 páginasPractica 2 LimiteRosAún no hay calificaciones
- 6 - Sistemas DE Costos ResumenDocumento2 páginas6 - Sistemas DE Costos Resumenmarielarenzi75Aún no hay calificaciones
- CLASE 1 2 2023Documento7 páginasCLASE 1 2 2023marielarenzi75Aún no hay calificaciones
- 04-guia de macroeconomía 01-21Documento14 páginas04-guia de macroeconomía 01-21marielarenzi75Aún no hay calificaciones
- Algunos consejos para estudiar en forma virtualDocumento1 páginaAlgunos consejos para estudiar en forma virtualmarielarenzi75Aún no hay calificaciones
- HistDocumento20 páginasHistmarielarenzi75Aún no hay calificaciones
- 7 - Sistemas de Costos - Resumen teoríaDocumento10 páginas7 - Sistemas de Costos - Resumen teoríamarielarenzi75Aún no hay calificaciones
- hist. preguntas y respuestas de parcialDocumento6 páginashist. preguntas y respuestas de parcialmarielarenzi75Aún no hay calificaciones
- MOCHON BECKER Economia Principios y Aplicaciones 4ta Ed-19-40Documento22 páginasMOCHON BECKER Economia Principios y Aplicaciones 4ta Ed-19-40Sebastian manceboAún no hay calificaciones
- continuacion cap.1 Monchon y beckerDocumento6 páginascontinuacion cap.1 Monchon y beckermarielarenzi75Aún no hay calificaciones
- Capitulo 1. Introduccion. Introduccion A La Economia Positiva (R. Lipsey) PDFDocumento17 páginasCapitulo 1. Introduccion. Introduccion A La Economia Positiva (R. Lipsey) PDFAnonymous f4KdOpVwP0Aún no hay calificaciones
- Mochon Capitulo 1 y 2Documento29 páginasMochon Capitulo 1 y 2nancy rodriguez martinezAún no hay calificaciones
- Oferta y Base MonetariaDocumento3 páginasOferta y Base Monetariamarielarenzi75Aún no hay calificaciones
- Tema 5 de La Logica Clasica A La Logica Simbolica (Antonio)Documento18 páginasTema 5 de La Logica Clasica A La Logica Simbolica (Antonio)Sara LeAún no hay calificaciones
- Matemáticas II: Guía Didáctica Segundo SemestreDocumento208 páginasMatemáticas II: Guía Didáctica Segundo SemestreÁngel Antonio Martínez RochinAún no hay calificaciones
- Sistema de Registro para Un HotelDocumento11 páginasSistema de Registro para Un HotelMilthon Ttito CusiAún no hay calificaciones
- Incendios 2019 PDFDocumento16 páginasIncendios 2019 PDFYanina Porcel de PeraltaAún no hay calificaciones
- Angular JSDocumento9 páginasAngular JSFËNIXAún no hay calificaciones
- Paso 4 - LALY DIDACTICA DE LAS MATEMATICASDocumento29 páginasPaso 4 - LALY DIDACTICA DE LAS MATEMATICASYesenia Castillo100% (2)
- Informe Nro 3Documento4 páginasInforme Nro 3RONALDAún no hay calificaciones
- Sonido Ondas y Comportamiento Del SonidoDocumento67 páginasSonido Ondas y Comportamiento Del SonidoBelmont Belmont0% (1)
- Pauta T3 2020-1Documento6 páginasPauta T3 2020-1BENJAMIN ALEJANDRO MEDINA GONZALEZAún no hay calificaciones
- Fisica Semana 03 Enero Marzo 2017 Pre AdesDocumento5 páginasFisica Semana 03 Enero Marzo 2017 Pre AdesRosa Melva Vera RuedaAún no hay calificaciones
- TallerEdo2 (I 20)Documento3 páginasTallerEdo2 (I 20)haroldoAún no hay calificaciones
- Capitulo I, IIDocumento46 páginasCapitulo I, IIEylyn AlejandraAún no hay calificaciones
- Config Tipo Carrier Ethernet ALU v.1.1Documento41 páginasConfig Tipo Carrier Ethernet ALU v.1.1Vladimir OceguedaAún no hay calificaciones
- Diseminacion (Latencia)Documento3 páginasDiseminacion (Latencia)neudiAún no hay calificaciones
- Manual de Servicio REFRIGETADOR CONVENCIONAL HACEBDocumento22 páginasManual de Servicio REFRIGETADOR CONVENCIONAL HACEBLeneer Cueva Ramirez33% (3)
- Control Adaptivo Con Ganancia ProgramadaDocumento4 páginasControl Adaptivo Con Ganancia ProgramadaWalther LaricoAún no hay calificaciones
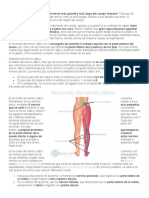
- Características y anatomía del nervio ciáticoDocumento12 páginasCaracterísticas y anatomía del nervio ciáticoLuz Liz CLAún no hay calificaciones
- Biorreactor Columna de BurbujaDocumento3 páginasBiorreactor Columna de BurbujaErick PalmiroAún no hay calificaciones
- Gráfica de pasajeros por hora del díaDocumento15 páginasGráfica de pasajeros por hora del díaKrlos MontoyaAún no hay calificaciones
- Ejercicios Ley Gauss Campo EléctricoDocumento4 páginasEjercicios Ley Gauss Campo EléctricoLaura Vanessa NegreteAún no hay calificaciones
- Ciencia moderna y sabiduría tradicionalDocumento66 páginasCiencia moderna y sabiduría tradicionalAlbaa100% (1)
- Hirens Boot CD y Moltiboot Profesional Rescue DiskDocumento14 páginasHirens Boot CD y Moltiboot Profesional Rescue DiskvictorhugoAún no hay calificaciones
- Geologia Plancha 193 YoPalDocumento165 páginasGeologia Plancha 193 YoPalAnggy Katherine Ortiz RayoAún no hay calificaciones
- Calculo de La Iluminacion Por Los 3 Metodos - 2Documento13 páginasCalculo de La Iluminacion Por Los 3 Metodos - 2Matías NussbaumAún no hay calificaciones
- Razonamiento MatemáticoDocumento6 páginasRazonamiento MatemáticoCristian BuenrostroAún no hay calificaciones
- 2.qué Es Un Proceso de ManufacturaDocumento15 páginas2.qué Es Un Proceso de Manufacturajorge enrique salazarAún no hay calificaciones
- Variador 3 G 3 FVDocumento37 páginasVariador 3 G 3 FVJulio Cesar Soles RaveloAún no hay calificaciones
- Física Exp III ENERO 2014 PDFDocumento86 páginasFísica Exp III ENERO 2014 PDFAaron Granero PimientaAún no hay calificaciones
- Elaboracion de ProyectoDocumento3 páginasElaboracion de ProyectoFrancisco RamirezAún no hay calificaciones
- Alfabeto Griego EJERCICIOSDocumento4 páginasAlfabeto Griego EJERCICIOSXimena ApolinarAún no hay calificaciones
- TDAH en Adultos. Cómo Reconocer y Tratar a un Adulto con TDAH en 30 Fáciles PasosDe EverandTDAH en Adultos. Cómo Reconocer y Tratar a un Adulto con TDAH en 30 Fáciles PasosCalificación: 4 de 5 estrellas4/5 (8)
- El péndulo de sanación: Péndulo hebreo. Investigación y sistematización de la técnicaDe EverandEl péndulo de sanación: Péndulo hebreo. Investigación y sistematización de la técnicaCalificación: 4.5 de 5 estrellas4.5/5 (27)
- Genética general: Libro de textoDe EverandGenética general: Libro de textoCalificación: 4.5 de 5 estrellas4.5/5 (11)
- Suicidología: Prevención, tratamiento psicológico e investigación de procesos suicidasDe EverandSuicidología: Prevención, tratamiento psicológico e investigación de procesos suicidasCalificación: 5 de 5 estrellas5/5 (7)
- La sabiduría del cuerpo: Recopilación de artículos de Moshe FeldenkraisDe EverandLa sabiduría del cuerpo: Recopilación de artículos de Moshe FeldenkraisCalificación: 4 de 5 estrellas4/5 (5)
- La autopsia psicológica: Psicotanatología forenseDe EverandLa autopsia psicológica: Psicotanatología forenseAún no hay calificaciones
- Neurocuántica: La nueva frontera de la neurocienciaDe EverandNeurocuántica: La nueva frontera de la neurocienciaCalificación: 5 de 5 estrellas5/5 (1)
- Técnicas de Facilitación Grupal: Tercera edición ampliadaDe EverandTécnicas de Facilitación Grupal: Tercera edición ampliadaCalificación: 1 de 5 estrellas1/5 (1)
- Curso rápido sobre magia del caos. El hobby oculto de ricos y famosos.De EverandCurso rápido sobre magia del caos. El hobby oculto de ricos y famosos.Calificación: 5 de 5 estrellas5/5 (42)
- La curación espontánea de las creencias: Cómo librarse de los falsos límitesDe EverandLa curación espontánea de las creencias: Cómo librarse de los falsos límitesCalificación: 4.5 de 5 estrellas4.5/5 (22)
- Neuropsicología: Los fundamentos de la materiaDe EverandNeuropsicología: Los fundamentos de la materiaCalificación: 5 de 5 estrellas5/5 (1)
- Estadística aplicada a la ingeniería y los negociosDe EverandEstadística aplicada a la ingeniería y los negociosCalificación: 3.5 de 5 estrellas3.5/5 (8)
- Medicina con plantas sagradas: La sabiduría del herbalismo de los aborígenes norteamericanosDe EverandMedicina con plantas sagradas: La sabiduría del herbalismo de los aborígenes norteamericanosCalificación: 4 de 5 estrellas4/5 (10)
- La Teoría de Conjuntos y los Fundamentos de las MatemáticasDe EverandLa Teoría de Conjuntos y los Fundamentos de las MatemáticasCalificación: 5 de 5 estrellas5/5 (1)
- Introducción a los estudios del discurso multimodalDe EverandIntroducción a los estudios del discurso multimodalCalificación: 5 de 5 estrellas5/5 (1)
- Energía, dime qué quieres y te diré cómo conseguirlo. Teoría y ejercicios 100% efectivos para conseguir aquello que deseas. Ley de la atracción nivel mago experimentado.De EverandEnergía, dime qué quieres y te diré cómo conseguirlo. Teoría y ejercicios 100% efectivos para conseguir aquello que deseas. Ley de la atracción nivel mago experimentado.Calificación: 4.5 de 5 estrellas4.5/5 (10)
- Estadística básica: Introducción a la estadística con RDe EverandEstadística básica: Introducción a la estadística con RCalificación: 5 de 5 estrellas5/5 (8)
- El Tao de la física: Una exploración de los paralelismos entre la física moderna y el misticismo orientalDe EverandEl Tao de la física: Una exploración de los paralelismos entre la física moderna y el misticismo orientalCalificación: 5 de 5 estrellas5/5 (3)
- Fundamentos de procesos químicosDe EverandFundamentos de procesos químicosCalificación: 5 de 5 estrellas5/5 (3)
- Introducción a la Estadística BayesianaDe EverandIntroducción a la Estadística BayesianaCalificación: 5 de 5 estrellas5/5 (2)
- Fundamentacion de la Metafisica de las CostumbresDe EverandFundamentacion de la Metafisica de las CostumbresCalificación: 5 de 5 estrellas5/5 (2)