También podría gustarte
- Estadística inferencial aplicadaDe EverandEstadística inferencial aplicadaCalificación: 5 de 5 estrellas5/5 (1)
- Histograma de imagen: Revelando conocimientos visuales, explorando las profundidades de los histogramas de imágenes en visión por computadoraDe EverandHistograma de imagen: Revelando conocimientos visuales, explorando las profundidades de los histogramas de imágenes en visión por computadoraAún no hay calificaciones
- Trabajo Encargado de Estadistica - 2021 - Meza Flores BrigittyDocumento8 páginasTrabajo Encargado de Estadistica - 2021 - Meza Flores Brigittybrigitty meza floresAún no hay calificaciones
- Estudio Estadístico Del Uso Del Inglés en El InternetDocumento36 páginasEstudio Estadístico Del Uso Del Inglés en El InternetJorgeAún no hay calificaciones
- Guía Iii Medio Dif., EstadísticaDocumento18 páginasGuía Iii Medio Dif., Estadísticaana0278303Aún no hay calificaciones
- Idioma más popularDocumento1 páginaIdioma más popularManuel Ramos100% (2)
- Paso 5 - Presentación de Resultados - Grupo 202107095 - 168Documento17 páginasPaso 5 - Presentación de Resultados - Grupo 202107095 - 168YENI100% (1)
- Guía de Repaso tabla de frecuencia (1)Documento4 páginasGuía de Repaso tabla de frecuencia (1)Romina Reyes VegaAún no hay calificaciones
- Guía EstadisticaDocumento17 páginasGuía EstadisticaJaison Geovanni Rivera LealAún no hay calificaciones
- 1 Guía 1 Sem 1 Estadística Descriptiva MTCDocumento14 páginas1 Guía 1 Sem 1 Estadística Descriptiva MTCfranciscaAún no hay calificaciones
- Guia de Aprendizaje 1Documento7 páginasGuia de Aprendizaje 1Karlos Artvro Raziel KorreaAún no hay calificaciones
- Ede Semana 2Documento21 páginasEde Semana 2Jenny Daniela Cruz VelizAún no hay calificaciones
- Modulo 1 EstadisticaDocumento9 páginasModulo 1 EstadisticaFrancisco Pérez ValenciaAún no hay calificaciones
- Semana 03 Guía Practica 03 2023 10Documento3 páginasSemana 03 Guía Practica 03 2023 10floresalarcondarwin8Aún no hay calificaciones
- IncestoDocumento31 páginasIncestoMartin SalcedoAún no hay calificaciones
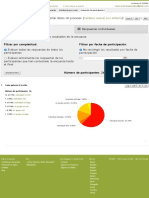
- Resumen de Las Preguntas Respuestas Individuales: Filtrar Por Completitud: Filtrar Por Fecha de ParticipaciónDocumento1 páginaResumen de Las Preguntas Respuestas Individuales: Filtrar Por Completitud: Filtrar Por Fecha de ParticipaciónJoaco RabinoAún no hay calificaciones
- Que Es Rango ?Documento2 páginasQue Es Rango ?Elizabeth ParedesAún no hay calificaciones
- E2 EstadisticaDocumento8 páginasE2 EstadisticadanielaAún no hay calificaciones
- ESTADISTICA Y PROBABILIDADES RepasoDocumento8 páginasESTADISTICA Y PROBABILIDADES RepasoVale Jiménez GallardoAún no hay calificaciones
- Tabla de frecuencias: distribución de colores favoritosDocumento9 páginasTabla de frecuencias: distribución de colores favoritosJuan Andres RivazAún no hay calificaciones
- Estadistica DescriptivaDocumento8 páginasEstadistica DescriptivaDayanna Francesca Valle tumbaAún no hay calificaciones
- ESTADISTICASDocumento10 páginasESTADISTICASJaime JerezAún no hay calificaciones
- Cultura y entorno de negocios internacionalesDocumento52 páginasCultura y entorno de negocios internacionalesLeon Benderesky PrietoAún no hay calificaciones
- Estadisticas Descritiva Variables EstadisticasDocumento20 páginasEstadisticas Descritiva Variables Estadisticasduvan hernandezAún no hay calificaciones
- Conceptos Basicos de - Estadistica Descriptiva e Inferencial PDFDocumento69 páginasConceptos Basicos de - Estadistica Descriptiva e Inferencial PDFosneider yepesAún no hay calificaciones
- HSZ 060Documento21 páginasHSZ 060JuanAún no hay calificaciones
- Estadistica 1Documento12 páginasEstadistica 1Rochy NavarroAún no hay calificaciones
- Ejercicios de MatricesDocumento2 páginasEjercicios de Matricesjuan sepulvedadAún no hay calificaciones
- Ba U2 Ea CatlDocumento15 páginasBa U2 Ea CatlCarlos HumbertoAún no hay calificaciones
- Trabajo #2 de Estadistica Listo OkeyDocumento16 páginasTrabajo #2 de Estadistica Listo OkeyYnesContrerasAún no hay calificaciones
- Actividad 3 - Tablas de FrecuenciaDocumento5 páginasActividad 3 - Tablas de FrecuenciaFRANCISCOAún no hay calificaciones
- Semana 03 Guía Practica 03-2023-20Documento3 páginasSemana 03 Guía Practica 03-2023-20JOEL PEDRO ARRISUEÑO YUCRAAún no hay calificaciones
- Semana 03 Guía Practica 03-2024-10Documento3 páginasSemana 03 Guía Practica 03-2024-1072518909Aún no hay calificaciones
- Sesión 2Documento37 páginasSesión 2Jackeline Sharon AzorsaAún no hay calificaciones
- Fracuencia Absoluta.Documento7 páginasFracuencia Absoluta.Dennise GuzmanAún no hay calificaciones
- Medidas de Tendencia CentralDocumento16 páginasMedidas de Tendencia CentralJaviera OrtízAún no hay calificaciones
- Estadística DescriptivaDocumento42 páginasEstadística DescriptivaAnto PonzoAún no hay calificaciones
- T08 DOC2 TratamientoInformacion (21 22)Documento19 páginasT08 DOC2 TratamientoInformacion (21 22)teoria historiaAún no hay calificaciones
- Medidas de Tendencia CentralDocumento8 páginasMedidas de Tendencia Centrallizeth johana mendoza morenoAún no hay calificaciones
- GRÁFICOS - Viernes de La ProfesoraDocumento35 páginasGRÁFICOS - Viernes de La ProfesoraAshly Vega LucianiAún no hay calificaciones
- Semana 03 Guía Practica 03-2024-10Documento3 páginasSemana 03 Guía Practica 03-2024-10MAURICIO ARMANDO COSIO QUISPEAún no hay calificaciones
- Análisis Descriptivo. Nociones de Probabilidad e InferenciaDocumento53 páginasAnálisis Descriptivo. Nociones de Probabilidad e InferenciaDiego GonzálezAún no hay calificaciones
- ESTADISTICADocumento9 páginasESTADISTICAAlvin VargasAún no hay calificaciones
- Diapositivas - Unidad II - VARIABLE DISCRETADocumento44 páginasDiapositivas - Unidad II - VARIABLE DISCRETAGianella MourgliaAún no hay calificaciones
- Ba U3 Ea CatlDocumento24 páginasBa U3 Ea CatlCarlos HumbertoAún no hay calificaciones
- Ejercicios AdicionalDocumento38 páginasEjercicios AdicionalMagno Rosendo Reyes BredinanaAún no hay calificaciones
- Guia 79 Meta 27 OctavoDocumento25 páginasGuia 79 Meta 27 Octavokatherine100% (1)
- 02 em 04 Empe U2 A7 Miguel Armando HernandezDocumento10 páginas02 em 04 Empe U2 A7 Miguel Armando HernandezJoe RamirezAún no hay calificaciones
- Diaz Kenia U1t5a1Documento13 páginasDiaz Kenia U1t5a1Rubius MacrausAún no hay calificaciones
- Estadistica Aplicada 2023-10Documento16 páginasEstadistica Aplicada 2023-10JesusIgnacioDavidDelaTrinidadAún no hay calificaciones
- L 02 e 01 Tablas de FrecuenciaDocumento9 páginasL 02 e 01 Tablas de FrecuenciaAndrés Romero0% (1)
- MAT2 U2 S04 Recurso - TIC - 1Documento12 páginasMAT2 U2 S04 Recurso - TIC - 1San Juan Bautista De La Salle OccopampaAún no hay calificaciones
- Histogramas Ejercicios ResueltosDocumento9 páginasHistogramas Ejercicios ResueltosJennyfer VilcaAún no hay calificaciones
- Clase 02 Estadistica 02Documento24 páginasClase 02 Estadistica 02Jhonny MaraviAún no hay calificaciones
- Los 7mos y Su Cantidad de HermanosDocumento17 páginasLos 7mos y Su Cantidad de HermanosTanjiro my belovedAún no hay calificaciones
- Elaboración de DatosDocumento61 páginasElaboración de DatosDiego Franco Mori HuivinAún no hay calificaciones
- Tabla de Distribución de Frecuencias ALUMNO (Recuperado)Documento4 páginasTabla de Distribución de Frecuencias ALUMNO (Recuperado)Kary Lenda KentaAún no hay calificaciones
- Evaluación FinalDocumento489 páginasEvaluación FinalJenny Alvarez AngelAún no hay calificaciones
- Paso 3. Análisis de La Información.Documento9 páginasPaso 3. Análisis de La Información.julianaAún no hay calificaciones
- Guía N 2° MATEMÁTICA 7° B.Documento7 páginasGuía N 2° MATEMÁTICA 7° B.Alexander ValdésAún no hay calificaciones
- Clase 6.1Documento38 páginasClase 6.1Lore GarciaAún no hay calificaciones
- CyT Módul 1 - Los Orígenes - Parte IDocumento45 páginasCyT Módul 1 - Los Orígenes - Parte ILore GarciaAún no hay calificaciones
- Clase 3b La Etnografía Como Enfoque - Continuación - Por Diana MilsteinDocumento18 páginasClase 3b La Etnografía Como Enfoque - Continuación - Por Diana MilsteinLore GarciaAún no hay calificaciones
- 4.manual de Lectocomprensión de Textos en Inglés - Unidad 3Documento7 páginas4.manual de Lectocomprensión de Textos en Inglés - Unidad 3Lore GarciaAún no hay calificaciones
- CLASE 5 PDF ESCRITURADocumento18 páginasCLASE 5 PDF ESCRITURALore GarciaAún no hay calificaciones
- 03 Clara Prestinoni de Bellora-Elsa Girotti - El Resumen o AbstractDocumento19 páginas03 Clara Prestinoni de Bellora-Elsa Girotti - El Resumen o AbstractLore GarciaAún no hay calificaciones
- Embodiment y alteraciones de la integración multisensorial en los trastornos de la conducta alimentariaDocumento275 páginasEmbodiment y alteraciones de la integración multisensorial en los trastornos de la conducta alimentariaLore GarciaAún no hay calificaciones
- 1 AAVV Catedra de Antropologia Cultural y Social El Campo de La AntropologiaDocumento35 páginas1 AAVV Catedra de Antropologia Cultural y Social El Campo de La AntropologiaLore GarciaAún no hay calificaciones
- Análisis cualitativo de entrevistas con ATLAS.tiDocumento20 páginasAnálisis cualitativo de entrevistas con ATLAS.tiLore GarciaAún no hay calificaciones
- Diálogos Entre Pueblos Indígenas y Estado. Caso de Pueblo Kitu Kara Del Distrito Metropolitano de Quito en EcuadorDocumento446 páginasDiálogos Entre Pueblos Indígenas y Estado. Caso de Pueblo Kitu Kara Del Distrito Metropolitano de Quito en EcuadorAtuk SimbañaAún no hay calificaciones
- Clase 4a Cristian (Final)Documento15 páginasClase 4a Cristian (Final)Lore GarciaAún no hay calificaciones
- Eah2018 Usuarios DocumentoDocumento35 páginasEah2018 Usuarios DocumentoLore GarciaAún no hay calificaciones
- Módulo 4 - Clase 11 - Correlación y Regresión LinealDocumento13 páginasMódulo 4 - Clase 11 - Correlación y Regresión LinealLore GarciaAún no hay calificaciones
- Clase 1 SpssDocumento11 páginasClase 1 SpssLore GarciaAún no hay calificaciones
- Módulo 3 - Clase 7 - Estadística InferencialDocumento16 páginasMódulo 3 - Clase 7 - Estadística InferencialLore GarciaAún no hay calificaciones
- Módulo 4 - Clase 9 - Analizar Datos IIDocumento17 páginasMódulo 4 - Clase 9 - Analizar Datos IILore GarciaAún no hay calificaciones
- 377787-Text de L'article-545802-1-10-20201217Documento22 páginas377787-Text de L'article-545802-1-10-20201217Lore GarciaAún no hay calificaciones
- Evolucion y Cambios Tecnicos en SociedadDocumento301 páginasEvolucion y Cambios Tecnicos en SociedadLore GarciaAún no hay calificaciones
- Los Decires y Los HaceresDocumento15 páginasLos Decires y Los HaceresJoceruizaAún no hay calificaciones
- Clase 7 PDFDocumento14 páginasClase 7 PDFLore GarciaAún no hay calificaciones
- Clase 4b Cristian (Final)Documento17 páginasClase 4b Cristian (Final)Lore GarciaAún no hay calificaciones
- Etnograficc81a y Teoricc81a en La Investigaciocc81n EducativaDocumento25 páginasEtnograficc81a y Teoricc81a en La Investigaciocc81n EducativaFelipe Antonio VasquezAún no hay calificaciones
- Memoria Pablo Arenas GonzálezDocumento174 páginasMemoria Pablo Arenas GonzálezArmando HamelAún no hay calificaciones
- El Don de La Conversación. Preguntar en El Proceso de Investigación" Parte ADocumento21 páginasEl Don de La Conversación. Preguntar en El Proceso de Investigación" Parte ALore Garcia100% (1)
- 31 76 1 PBDocumento10 páginas31 76 1 PBLore GarciaAún no hay calificaciones
- Alonso Cap 2 Sujeto y Discurso El Lugar de La Entrevista AbiertaDocumento23 páginasAlonso Cap 2 Sujeto y Discurso El Lugar de La Entrevista AbiertapaoximenaAún no hay calificaciones
- 01 Vicente Santos FDocumento17 páginas01 Vicente Santos FLore GarciaAún no hay calificaciones
- Un Acercamiento A Las Cadenas Operativas Líticas Del Complejo Huentelauquén Desde Dos Campamentos de Tarea: LV 531 Y LV 547, Pichidangui, Chile. Por B. Ballester 2009Documento59 páginasUn Acercamiento A Las Cadenas Operativas Líticas Del Complejo Huentelauquén Desde Dos Campamentos de Tarea: LV 531 Y LV 547, Pichidangui, Chile. Por B. Ballester 2009Colegio de Arqueólogos de ChileAún no hay calificaciones
- La Interpretación de Las Culturas - Clifford GeertzDocumento387 páginasLa Interpretación de Las Culturas - Clifford GeertzWagner Lira98% (58)
- Semana 10 Guía Práctica 10Documento4 páginasSemana 10 Guía Práctica 10ANGIE LESLIE MESCUA MALLMA100% (4)
- Trabajo EstadísticasDocumento40 páginasTrabajo EstadísticasNefertary Helmersen0% (1)
- Taller Unidad 1Documento31 páginasTaller Unidad 1Zayda DiazAún no hay calificaciones
- Problemario Resuelto de Dispercion Regrecion Lineal y MultipleDocumento26 páginasProblemario Resuelto de Dispercion Regrecion Lineal y MultipleJosé Carlos Rosano SuárezAún no hay calificaciones
- Apir - Manual Estadística, Experimental y PsicometríaDocumento78 páginasApir - Manual Estadística, Experimental y PsicometríaTatiana NavasAún no hay calificaciones
- TallerDocumento12 páginasTallerWilson Danilo Jaimes100% (1)
- Epidemiología 4Documento70 páginasEpidemiología 4Jaqui GinezAún no hay calificaciones
- Regresión múltiple para predecir consumo de energía en planta químicaDocumento22 páginasRegresión múltiple para predecir consumo de energía en planta químicaCarina ChacónAún no hay calificaciones
- ST TTK Análisis de Concretos 03-Ago-2022Documento2 páginasST TTK Análisis de Concretos 03-Ago-2022Sergio HerreraAún no hay calificaciones
- Grupo - 100105 - 139 - Yulieth Alejandra Martinez Molina - Paso 4. Descripción de La InformacionDocumento13 páginasGrupo - 100105 - 139 - Yulieth Alejandra Martinez Molina - Paso 4. Descripción de La InformacionYulieth Alejandra Martínez MolinaAún no hay calificaciones
- 6° PLAN DE TRABAJO ESTADISTICA I - 1er. SEMESTRE 2023Documento4 páginas6° PLAN DE TRABAJO ESTADISTICA I - 1er. SEMESTRE 2023sacsimonsenAún no hay calificaciones
- Ejercitario Resuelto Semana 9Documento21 páginasEjercitario Resuelto Semana 9Jose Hernan Garcia RiveraAún no hay calificaciones
- Estadisticas 1 Tarea 9 - ArgelisDocumento5 páginasEstadisticas 1 Tarea 9 - ArgelisArgelis De La RosaAún no hay calificaciones
- Separata Estadistica Educacion Final Final AbrilDocumento139 páginasSeparata Estadistica Educacion Final Final AbrilVania Lizeth Ponce Lopez100% (1)
- (M2-E1) Evaluación (Prueba) - FUNDAMENTOS DE ESTADÍSTICA PDFDocumento12 páginas(M2-E1) Evaluación (Prueba) - FUNDAMENTOS DE ESTADÍSTICA PDFfabiolaAún no hay calificaciones
- Tema 3Documento14 páginasTema 3Anna Redondo AlgobiaAún no hay calificaciones
- Clase 7 Correlación SerialDocumento32 páginasClase 7 Correlación SerialDaimer Mauricio DiazAún no hay calificaciones
- PP EstadisticaDocumento11 páginasPP EstadisticamarcoAún no hay calificaciones
- Grupo 3 OpeDocumento8 páginasGrupo 3 OpeRenzo EgasAún no hay calificaciones
- Trabajo Final de Estadistica 1Documento8 páginasTrabajo Final de Estadistica 1nayelin0rodriguezAún no hay calificaciones
- Investigacion EstadisticaDocumento5 páginasInvestigacion EstadisticaYenny Suarez100% (1)
- Estadística descriptiva de millas por galón y resistencia de hilosDocumento8 páginasEstadística descriptiva de millas por galón y resistencia de hilosLuis RdzAún no hay calificaciones
- Final de Estadistica IDocumento10 páginasFinal de Estadistica IANNY JIMENEZAún no hay calificaciones
- Tutorial de SpssDocumento98 páginasTutorial de SpssJuan JoseAún no hay calificaciones
- Tpn1 PDFDocumento4 páginasTpn1 PDFRamon RamonAún no hay calificaciones
- Calculo de Algunos Estaditicos - Ejercicio Eda - Variante CDocumento19 páginasCalculo de Algunos Estaditicos - Ejercicio Eda - Variante CNilson Ambrocio PeñaAún no hay calificaciones
- 4.2 Heteroscedasticidad PDFDocumento100 páginas4.2 Heteroscedasticidad PDFMarcelaGarciaAún no hay calificaciones
- Ejercicios1Distr Prob (Máster)Documento4 páginasEjercicios1Distr Prob (Máster)Eduardo Paz Gómez100% (2)
- Evaluacion U1Documento17 páginasEvaluacion U1Heriberto Gonzalez RuelasAún no hay calificaciones
- Tipos de VariableDocumento11 páginasTipos de VariableMax Serolf ZaidAún no hay calificaciones