También podría gustarte
- Ciencia de datos: La serie de conocimientos esenciales de MIT PressDe EverandCiencia de datos: La serie de conocimientos esenciales de MIT PressCalificación: 5 de 5 estrellas5/5 (1)
- Plan-Estrategico Entel FinalDocumento55 páginasPlan-Estrategico Entel FinalJuan Carlos Gabrieles Fuentes75% (8)
- Cómo entender estadística fácilmenteDe EverandCómo entender estadística fácilmenteCalificación: 3.5 de 5 estrellas3.5/5 (2)
- Caso Practico Unidad 3Documento6 páginasCaso Practico Unidad 3Angelica SerratoAún no hay calificaciones
- Ensayo To Pedagogico Del Tercer MundoDocumento6 páginasEnsayo To Pedagogico Del Tercer Mundodamarisrodriguez100% (2)
- EL SISTEMA PICTOGRÁFICO DE COMUNICACIÓ1 ResumenDocumento3 páginasEL SISTEMA PICTOGRÁFICO DE COMUNICACIÓ1 ResumenMar GreyAún no hay calificaciones
- Actividad 1 - Utilidad de La Estadística DescriptivaDocumento4 páginasActividad 1 - Utilidad de La Estadística DescriptivaPatrik suarezAún no hay calificaciones
- NetnografiaDocumento14 páginasNetnografiaBryant Castillo Gonzalez100% (1)
- Analisis de Sentimientos de Las Elecciones PublicaDocumento10 páginasAnalisis de Sentimientos de Las Elecciones Publicaleomatias7Aún no hay calificaciones
- Big Dta en La PNPDocumento31 páginasBig Dta en La PNPAngel zurcoAún no hay calificaciones
- Dialnet ModeloDeGestionYControlDeProcesosInformaticosEstud 702522Documento113 páginasDialnet ModeloDeGestionYControlDeProcesosInformaticosEstud 702522Daniela HurtadoAún no hay calificaciones
- EBA U1 EA NoFranciscoMartinezDocumento12 páginasEBA U1 EA NoFranciscoMartinezcitassat.1991Aún no hay calificaciones
- Tarea 4 - Jenny PicaguaDocumento6 páginasTarea 4 - Jenny PicaguaDavid mezaAún no hay calificaciones
- Ejemplo Marco MetodologicoDocumento26 páginasEjemplo Marco MetodologicoVictor Hugo Flores IsunzaAún no hay calificaciones
- Informe - de - Fuentes GA1-220501092-AA1-EV01Documento6 páginasInforme - de - Fuentes GA1-220501092-AA1-EV01Segura COMPAÑIA DE PROTECCIONAún no hay calificaciones
- Caso Practico 26-07-2023Documento5 páginasCaso Practico 26-07-2023felipe rAún no hay calificaciones
- Proposta Informe FinalDocumento13 páginasProposta Informe FinalLuciano Salazar FloresAún no hay calificaciones
- Tarea 2.3 y 2.4Documento8 páginasTarea 2.3 y 2.4Moises MartinezAún no hay calificaciones
- Big Data Aplicada A La PNP 1Documento36 páginasBig Data Aplicada A La PNP 1Angel zurcoAún no hay calificaciones
- Guia #1 Procesar - Tecnologo NuevaDocumento8 páginasGuia #1 Procesar - Tecnologo NuevajeisonAún no hay calificaciones
- ResumenesDocumento5 páginasResumenesJhonatan VegaAún no hay calificaciones
- Métodos de Investigación DigitalDocumento3 páginasMétodos de Investigación DigitalJose Carlos Cedillo ZuloagaAún no hay calificaciones
- ForoDocumento2 páginasForoSandra PitaAún no hay calificaciones
- Practica Laboratorio Machine LearningDocumento5 páginasPractica Laboratorio Machine LearningFelipe HerreraAún no hay calificaciones
- Miner Ia Deopiniones Sobre en TwitterDocumento5 páginasMiner Ia Deopiniones Sobre en TwitterEric L.Aún no hay calificaciones
- Big Data Aplicada A La PNP 11111111Documento30 páginasBig Data Aplicada A La PNP 11111111Angel zurcoAún no hay calificaciones
- TFG Jesús Castañón RincónDocumento192 páginasTFG Jesús Castañón RincónJesús Castañón100% (1)
- Unidad 2 La Ciencia de Datos en El Sector GubernamentalDocumento4 páginasUnidad 2 La Ciencia de Datos en El Sector GubernamentalAleja IbarraAún no hay calificaciones
- Tares 6 Investigacion de MercadoDocumento7 páginasTares 6 Investigacion de Mercadodaniel eduardo olivares alvaradoAún no hay calificaciones
- Avance 2 Desarrollo de Unplan de PublicidadDocumento7 páginasAvance 2 Desarrollo de Unplan de Publicidadlis batistaAún no hay calificaciones
- Guía Del Programa - MIT - Machine - LearningDocumento12 páginasGuía Del Programa - MIT - Machine - LearningHERNAN RICARDO DORADO GALEANOAún no hay calificaciones
- Fase 1 - David GarcíaDocumento11 páginasFase 1 - David GarcíaHEAVENAún no hay calificaciones
- Actividad 1 Julian ArdilaDocumento4 páginasActividad 1 Julian ArdilaAnyela Del PierryAún no hay calificaciones
- (UNCUYO) - Visualización y Data MiningDocumento9 páginas(UNCUYO) - Visualización y Data MiningLuis Eduardo Garcia CarrilloAún no hay calificaciones
- Paso 2 - Aplicar Las Etapas Estadísticas A La Problemática - Grupo - 360Documento27 páginasPaso 2 - Aplicar Las Etapas Estadísticas A La Problemática - Grupo - 360alezzAún no hay calificaciones
- U1 - Evidencia de AprendizajeDocumento11 páginasU1 - Evidencia de Aprendizajegladiatore19Aún no hay calificaciones
- Métodos de Investigación PDFDocumento20 páginasMétodos de Investigación PDFGuadalupe Victoriano GarcíaAún no hay calificaciones
- Fase2 - Andrea RamirezDocumento14 páginasFase2 - Andrea RamirezAngie Caterine Vallejo HernandezAún no hay calificaciones
- Leonardo - Guzman - Actividad - 2.1 - Cuadro AnalisisDocumento13 páginasLeonardo - Guzman - Actividad - 2.1 - Cuadro Analisiscompartirtintal100% (1)
- Análisis de Sentimientos en Trip AdvisorDocumento11 páginasAnálisis de Sentimientos en Trip AdvisorMarcos Ariel Leiva VasconcellosAún no hay calificaciones
- Proyecto 1Documento6 páginasProyecto 1viridiana alejandra perez garciaAún no hay calificaciones
- ¿Cómo Usar Una Base de Datos en Grafo?Documento94 páginas¿Cómo Usar Una Base de Datos en Grafo?P. J. A BarrientosAún no hay calificaciones
- Vergara y Rodriguez de La Fuente 2023Documento6 páginasVergara y Rodriguez de La Fuente 2023Francisco Sanabria MunévarAún no hay calificaciones
- Tesis CompletaDocumento281 páginasTesis Completaalexfcn2007Aún no hay calificaciones
- Actividad 4 Recleccion de Datos Cuantitativos 10 de NoviembreDocumento18 páginasActividad 4 Recleccion de Datos Cuantitativos 10 de Noviembremaria isabel murallas buenoAún no hay calificaciones
- Analisis EstadisticoDocumento57 páginasAnalisis EstadisticoChristian Ruiz VargasAún no hay calificaciones
- Syllabus de Sistemas de InformaciónDocumento4 páginasSyllabus de Sistemas de InformaciónIsrael Pardo AAún no hay calificaciones
- Métodos y Técnicas de Análisis de DatosDocumento21 páginasMétodos y Técnicas de Análisis de DatosMichael AriasAún no hay calificaciones
- MÓDULODocumento12 páginasMÓDULOEmmanuelAún no hay calificaciones
- M Valenzuela Investigación Interdisciplinaria Pregrado 2020 PUCV PDFDocumento7 páginasM Valenzuela Investigación Interdisciplinaria Pregrado 2020 PUCV PDFMiguel Ignacio Valenzuela ParadaAún no hay calificaciones
- Aca 2 de AnalisisDocumento16 páginasAca 2 de AnalisisDuban Alexander Reina MarroquinAún no hay calificaciones
- 71 0617 IsDocumento176 páginas71 0617 IslegerAún no hay calificaciones
- Fase 1 - Reconocimiento de Conceptos Previos de La Inferencia Estadí SticaDocumento10 páginasFase 1 - Reconocimiento de Conceptos Previos de La Inferencia Estadí SticaLedherzon Contreras0% (1)
- Procesamiento de DatosDocumento5 páginasProcesamiento de DatosLuis HuAún no hay calificaciones
- Paso 2. Ejecutar El Proyecto. 15-05-2022Documento17 páginasPaso 2. Ejecutar El Proyecto. 15-05-2022Janderley Atehortua GutiérrezAún no hay calificaciones
- ? Semana 16 - Tema 01 Tarea - Aplicación de Estrategias en El Manejo de Fuentes para El Examen Final (Terminado)Documento13 páginas? Semana 16 - Tema 01 Tarea - Aplicación de Estrategias en El Manejo de Fuentes para El Examen Final (Terminado)Fernando Esteban Llontop100% (1)
- Las Etapas de Lan Investigación EstadísticaDocumento11 páginasLas Etapas de Lan Investigación EstadísticaSusiie ArianaAún no hay calificaciones
- Guia-Procesar La InformacionDocumento8 páginasGuia-Procesar La InformacionFidias Antonio Manyoma100% (1)
- Mineria de DatosDocumento13 páginasMineria de DatosNancy PatiñoAún no hay calificaciones
- Tesd S4a4Documento8 páginasTesd S4a4TeresaAún no hay calificaciones
- Tig - SdpysDocumento32 páginasTig - SdpysCarlos EnriqueAún no hay calificaciones
- Análisis Espacial de Datos y Sus Aplicaciones en PythonDocumento6 páginasAnálisis Espacial de Datos y Sus Aplicaciones en PythonJonathan Piñeros PintoAún no hay calificaciones
- Libro Esta Webada PDFDocumento12 páginasLibro Esta Webada PDFJuan Carlos Gabrieles FuentesAún no hay calificaciones
- La Tienda PDFDocumento12 páginasLa Tienda PDFJuan Carlos Gabrieles FuentesAún no hay calificaciones
- Informe de Avance de Prácticas Pre Profesionales Fred - 2Documento3 páginasInforme de Avance de Prácticas Pre Profesionales Fred - 2Juan Carlos Gabrieles FuentesAún no hay calificaciones
- Cultura y Clima OrganizacionalDocumento4 páginasCultura y Clima OrganizacionalJean carlos Salinas cervabtesAún no hay calificaciones
- Evaluación Final - Revisión Del Intento1Documento4 páginasEvaluación Final - Revisión Del Intento1JANIT100% (1)
- DESCARTES John CottinghamDocumento14 páginasDESCARTES John CottinghamAlejandro GodoyAún no hay calificaciones
- Perspectivas Conductistas y Cognoscitiva Del AprendizajeDocumento7 páginasPerspectivas Conductistas y Cognoscitiva Del AprendizajeJunior Villa86% (7)
- BarbarismoDocumento8 páginasBarbarismoSantorito GabrielAún no hay calificaciones
- Semana 1 Lectura 01 FilosofiaDocumento5 páginasSemana 1 Lectura 01 FilosofiaCarlos Alejandro Gutierrez ColchadoAún no hay calificaciones
- Actividad Estrategias de La Inclusión Educativa en La Convivencia EscolarDocumento3 páginasActividad Estrategias de La Inclusión Educativa en La Convivencia EscolarmaleguiAún no hay calificaciones
- SugerenciasDocumento41 páginasSugerenciasJuanAún no hay calificaciones
- A.A Producimos Un Texto Argumentativo DomitilaDocumento2 páginasA.A Producimos Un Texto Argumentativo DomitilakikichonAún no hay calificaciones
- Unidad 5 - Admón. de OperacionesDocumento43 páginasUnidad 5 - Admón. de OperacionesKesha Ariadna Lopez Hernandez100% (3)
- Guia de Actividades y Rúbrica de Evaluación - Fase 5 - DivulgaciónDocumento7 páginasGuia de Actividades y Rúbrica de Evaluación - Fase 5 - DivulgaciónLeidy BuraiAún no hay calificaciones
- L.E.1 Teorias e Instituciones Contemporaneas de EducacionDocumento4 páginasL.E.1 Teorias e Instituciones Contemporaneas de Educacionalex2405740% (1)
- ED Realiza Mantenimiento CorrectivoDocumento7 páginasED Realiza Mantenimiento Correctivoisain23Aún no hay calificaciones
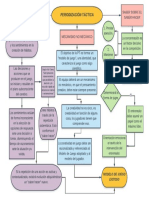
- Periodizacion TacticaDocumento1 páginaPeriodizacion TacticaYair Navarrete RochaAún no hay calificaciones
- Reglamento Tecnologico AzangaroDocumento38 páginasReglamento Tecnologico AzangaroYago YagoAún no hay calificaciones
- Diagrama de VennDocumento1 páginaDiagrama de Vennparkjimin inmidaAún no hay calificaciones
- Actividad 4Documento19 páginasActividad 4Erika NoreñaAún no hay calificaciones
- Matriz de Estrategias de EnseñanzaDocumento4 páginasMatriz de Estrategias de EnseñanzaMarianita Guisselle Garcia Sandoval0% (1)
- G1 Sandoval Moreira Jose LiderazgoDocumento21 páginasG1 Sandoval Moreira Jose LiderazgoJosho SandovalAún no hay calificaciones
- Tarea de Evaluacion Final Final POADocumento5 páginasTarea de Evaluacion Final Final POAJaner BanosAún no hay calificaciones
- Comentario Léxico-Semántico Becerra IDEASDocumento1 páginaComentario Léxico-Semántico Becerra IDEASAna Efe EmeAún no hay calificaciones
- Guía de Actividades y Rúbrica de Evaluación - Paso 4 - Transferir A Una Red Social y EvaluarDocumento13 páginasGuía de Actividades y Rúbrica de Evaluación - Paso 4 - Transferir A Una Red Social y EvaluarAngie Rodriguez SierraAún no hay calificaciones
- Hemisferio Izquierdo y DerechoDocumento4 páginasHemisferio Izquierdo y DerechoGabriela NoriegaAún no hay calificaciones
- B.-Tipo de Test: A.-Nombre Del Test Y de Los AutoresDocumento3 páginasB.-Tipo de Test: A.-Nombre Del Test Y de Los AutoresCamila Nicol Loaiza ZapataAún no hay calificaciones
- Informe de Prácticas ProfesionalesDocumento76 páginasInforme de Prácticas ProfesionalesBarbara LoveraAún no hay calificaciones
- Ambito de InvestigacionDocumento30 páginasAmbito de InvestigacionWilbert Ricardo Falconi VizcarraAún no hay calificaciones
- Caso GriseldaDocumento2 páginasCaso GriseldaCarmen PárragaAún no hay calificaciones
- Guia de Aprendizaje N°2Documento18 páginasGuia de Aprendizaje N°2Laura LlanosAún no hay calificaciones