También podría gustarte
- 001 - Unicornio Nuru Manta de Apego - En.esDocumento20 páginas001 - Unicornio Nuru Manta de Apego - En.esAlexa SavarellAún no hay calificaciones
- El Enigma de Los Mapas de Piri Reis PDFDocumento180 páginasEl Enigma de Los Mapas de Piri Reis PDFBoris67% (3)
- Wittgenstein para PrincipiantesDocumento176 páginasWittgenstein para PrincipiantesAmanda Luz Mora RAún no hay calificaciones
- Intervalos de ConfianzaDocumento5 páginasIntervalos de ConfianzaSusan Guillermo Mayta60% (10)
- Tira de La PeregrinaciónDocumento108 páginasTira de La PeregrinaciónIsrael Fuentes100% (1)
- ProductividadFeliz Ejercicios Unidad02Documento2 páginasProductividadFeliz Ejercicios Unidad02cocinuka100% (1)
- Protocolowaisiv 160602151419Documento16 páginasProtocolowaisiv 160602151419Tanys PadillaAún no hay calificaciones
- Anime Sakura-3Documento26 páginasAnime Sakura-3MarisaSonne100% (1)
- Pud Inicial 2 Smart Kids - QuitoDocumento35 páginasPud Inicial 2 Smart Kids - QuitoAlejandroXavierRealpeGalárraga100% (1)
- Planner Redes Sociales SOCIÁ MXFDocumento1 páginaPlanner Redes Sociales SOCIÁ MXFImpresiones Bicentenario TalcaAún no hay calificaciones
- Ev Medidas de PosiciónDocumento4 páginasEv Medidas de PosiciónSloopyIonKAún no hay calificaciones
- Cálculo y diseño de estructuras de materiales compuestos de fibra de vidrioDe EverandCálculo y diseño de estructuras de materiales compuestos de fibra de vidrioAún no hay calificaciones
- Narrativa Audiovisual-Jesús Garcia JimenezDocumento212 páginasNarrativa Audiovisual-Jesús Garcia JimenezCaynMJ50% (2)
- Diplomas Por AlumnoDocumento64 páginasDiplomas Por AlumnoDana ValenciaAún no hay calificaciones
- Diccionario FoucaultDocumento215 páginasDiccionario FoucaultKEVIN ESTRADA BEDOYA100% (11)
- 1macaco Com Capuz Português..pt - EsDocumento8 páginas1macaco Com Capuz Português..pt - EsJanetCruzRamirezAún no hay calificaciones
- Prop 09 PLANTA CONJ (60x90)Documento1 páginaProp 09 PLANTA CONJ (60x90)oa.carlosAún no hay calificaciones
- Ajedrez en El Aula 1-81Documento1 páginaAjedrez en El Aula 1-81Carlos David ApolonioAún no hay calificaciones
- PDF 20220913 161510 0000Documento1 páginaPDF 20220913 161510 0000brisasuarez018Aún no hay calificaciones
- "Los Huicholes" - Paola CasaresDocumento7 páginas"Los Huicholes" - Paola CasaresmdusaireAún no hay calificaciones
- Desarrollo E.mprendiidor 1Documento31 páginasDesarrollo E.mprendiidor 1Noé Ramón Valadez RamosAún no hay calificaciones
- Ficha Tecnica de CristaleriaDocumento2 páginasFicha Tecnica de CristaleriaZYANYA DONAJI PEREZ DIAZAún no hay calificaciones
- Planner Redes Sociales SOCIÁ MXDocumento5 páginasPlanner Redes Sociales SOCIÁ MXImpresiones Bicentenario TalcaAún no hay calificaciones
- Historia de La LloronaDocumento5 páginasHistoria de La LloronaJUAN JOSE MUÑOZ MENDEZAún no hay calificaciones
- Sociedades MercantilesDocumento1 páginaSociedades MercantilesCesar VizaAún no hay calificaciones
- Linea Del Tiempo MedicinaDocumento11 páginasLinea Del Tiempo MedicinaMarian Briceida Moreno RubioAún no hay calificaciones
- Pasajes Carmen Blasco PDFDocumento6 páginasPasajes Carmen Blasco PDFaleskokAún no hay calificaciones
- Digest IvoDocumento24 páginasDigest IvoLaura CastilloAún no hay calificaciones
- Mapa Conceptual FilosofiaDocumento1 páginaMapa Conceptual FilosofiaLauraAún no hay calificaciones
- PeiDocumento11 páginasPeiJoão Victor MartinsAún no hay calificaciones
- Cuerpo y Temporalidad en El Envejecimiento, Capítulo de Dra. Gloria Ferrero y Lic Cristina CarriónDocumento39 páginasCuerpo y Temporalidad en El Envejecimiento, Capítulo de Dra. Gloria Ferrero y Lic Cristina CarriónMapuztecaAún no hay calificaciones
- Proyecto de VidaDocumento18 páginasProyecto de VidaKatherin Jazmin Puma QuispeAún no hay calificaciones
- UntitledDocumento140 páginasUntitledJuan Angel ItalianoAún no hay calificaciones
- AL-S4-A3 Lopez Melendez Isabela JaquelineDocumento7 páginasAL-S4-A3 Lopez Melendez Isabela JaquelineIsabela Jaqueline López MelendezAún no hay calificaciones
- 1984, Kostovski EscaneadoDocumento41 páginas1984, Kostovski EscaneadoRaúl Enrique Dutari DutariAún no hay calificaciones
- Que Vas A Llevar. Pablo BernasconiDocumento22 páginasQue Vas A Llevar. Pablo Bernasconidelsolsuc.caaca1Aún no hay calificaciones
- Caso Cerruti PDFDocumento22 páginasCaso Cerruti PDFAndrea JimenezAún no hay calificaciones
- PPT Unidad 01 Tema 01 2023 Geometría Aplicada Al Diseño (2320)Documento58 páginasPPT Unidad 01 Tema 01 2023 Geometría Aplicada Al Diseño (2320)Mckenna GcAún no hay calificaciones
- Gerontodiseño - FinalDocumento35 páginasGerontodiseño - FinalValentina SuárezAún no hay calificaciones
- Fiestas Kiddy 2024Documento9 páginasFiestas Kiddy 2024Jefe OliAún no hay calificaciones
- Open Miranda Bruce Mitford El Libro Ilustrado de Los Signos y SimbolosDocumento136 páginasOpen Miranda Bruce Mitford El Libro Ilustrado de Los Signos y SimbolosJaaziel TorresAún no hay calificaciones
- MozambiqueDocumento1 páginaMozambiqueKarla Pamela Duarte MuñozAún no hay calificaciones
- No.19 Oct.1946Documento27 páginasNo.19 Oct.1946J. Mauricio Chaves- BustosAún no hay calificaciones
- Adobe Scan 27 de Sep de 2021Documento1 páginaAdobe Scan 27 de Sep de 2021Vanessa Ochoa ArceoAún no hay calificaciones
- Juan PestanasDocumento1 páginaJuan PestanasAnonymous fH6s0ZbhMAún no hay calificaciones
- Captura de Pantalla 2023-04-26 A La(s) 5.10.59 A.M.Documento9 páginasCaptura de Pantalla 2023-04-26 A La(s) 5.10.59 A.M.luz dary orbesAún no hay calificaciones
- 15.palabras Claves para El La Dinamica Del Arbol SocialDocumento1 página15.palabras Claves para El La Dinamica Del Arbol SocialIDKAún no hay calificaciones
- Mandalas VocalesDocumento6 páginasMandalas VocalesJensi GuerraAún no hay calificaciones
- Albelda - El Juicio Final Musica Notada Zarzuela en Un ActoDocumento55 páginasAlbelda - El Juicio Final Musica Notada Zarzuela en Un ActoAnonymous kkG7iAupAún no hay calificaciones
- PPT Unid 03 2020 01 Geometria Aplic Diseño (2320)Documento67 páginasPPT Unid 03 2020 01 Geometria Aplic Diseño (2320)Fabrizio PeAún no hay calificaciones
- Armas de Fuego. Manuales Ilustrados Bell - R. HertzbergDocumento95 páginasArmas de Fuego. Manuales Ilustrados Bell - R. HertzbergSebastián MaderaAún no hay calificaciones
- 90la Chicha PDFDocumento3 páginas90la Chicha PDFAugusto RebagliatiAún no hay calificaciones
- S14.s1 Modelado de Ensamble y Representación de Planos-2Documento13 páginasS14.s1 Modelado de Ensamble y Representación de Planos-2Omar CastroAún no hay calificaciones
- PPT Unidad 02 Tema 03 Geometría Aplicada Al Diseño (2320)Documento37 páginasPPT Unidad 02 Tema 03 Geometría Aplicada Al Diseño (2320)Maje DavilaAún no hay calificaciones
- Diferencia de AsociacionesDocumento4 páginasDiferencia de Asociacionesjeferson vasquezAún no hay calificaciones
- Plantilla CanvaDocumento1 páginaPlantilla Canvacristian-delojoAún no hay calificaciones
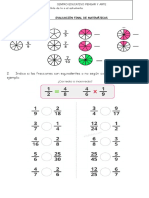
- Evaluación Final de MatesDocumento2 páginasEvaluación Final de MatesValeria FrancoAún no hay calificaciones
- Lectura para Niños Que Les Gusta LeerDocumento65 páginasLectura para Niños Que Les Gusta LeerDenisse RodzherAún no hay calificaciones
- Ilovepdf MergedDocumento157 páginasIlovepdf MergedjhossefAún no hay calificaciones
- Clasificación de Las EmpresasDocumento17 páginasClasificación de Las EmpresasNicole R. GloriaAún no hay calificaciones
- Acuerdo de Basilea 3Documento10 páginasAcuerdo de Basilea 3Nicole R. GloriaAún no hay calificaciones
- Mercado BursatilDocumento13 páginasMercado BursatilNicole R. GloriaAún no hay calificaciones
- Financiación BancariaDocumento16 páginasFinanciación BancariaNicole R. GloriaAún no hay calificaciones
- Libro 1Documento2 páginasLibro 1Nicole R. GloriaAún no hay calificaciones
- Ramirez Gloria, Flor de Basilia Nicole - Caso Practico 1Documento3 páginasRamirez Gloria, Flor de Basilia Nicole - Caso Practico 1Nicole R. GloriaAún no hay calificaciones
- FORMATO DEL LIBRO CAJA AMERICANA para Casos PracticosDocumento3 páginasFORMATO DEL LIBRO CAJA AMERICANA para Casos PracticosNicole R. GloriaAún no hay calificaciones
- Exposicion Plan de Trabajo DsyaDocumento16 páginasExposicion Plan de Trabajo DsyaNicole R. GloriaAún no hay calificaciones
- ORGANIGRAMADocumento1 páginaORGANIGRAMANicole R. GloriaAún no hay calificaciones
- NextDocumento2 páginasNextNicole R. GloriaAún no hay calificaciones
- Ficha Matematica 2Documento2 páginasFicha Matematica 2Nicole R. GloriaAún no hay calificaciones
- Separata 1 Costos Por OrdenesDocumento18 páginasSeparata 1 Costos Por OrdenesNicole R. GloriaAún no hay calificaciones
- Cuentas Fin de Año F y NDocumento2 páginasCuentas Fin de Año F y NNicole R. GloriaAún no hay calificaciones
- Horario de Clases Semestre 2023-Ii Sistema de Gestión AcadémicaDocumento2 páginasHorario de Clases Semestre 2023-Ii Sistema de Gestión AcadémicaNicole R. GloriaAún no hay calificaciones
- PORTADADocumento1 páginaPORTADANicole R. GloriaAún no hay calificaciones
- Grados de LibertadDocumento1 páginaGrados de LibertadAlejandro Colomera QuirozAún no hay calificaciones
- Intervalos de ConfianzaDocumento8 páginasIntervalos de ConfianzaJuan DavidAún no hay calificaciones
- Estadistica No ParametricaDocumento5 páginasEstadistica No ParametricaJuan José MartínAún no hay calificaciones
- 518-2016!09!15-Tema2 - Regresión Con Series TemporalesDocumento33 páginas518-2016!09!15-Tema2 - Regresión Con Series TemporalesJose TrujilloAún no hay calificaciones
- Pauta - Control 1 - 2023 - IDocumento2 páginasPauta - Control 1 - 2023 - ISebastian MartinezAún no hay calificaciones
- Estadistica Muestreo Estimacion CCSSDocumento8 páginasEstadistica Muestreo Estimacion CCSSRaul GaleanoAún no hay calificaciones
- Ecuaciones Simultaneas FinalDocumento15 páginasEcuaciones Simultaneas Finalviridiana bernalAún no hay calificaciones
- Estadistica 7 MetodologiaDocumento4 páginasEstadistica 7 MetodologiaPERUVIAN CCAHUA CCAHUAAún no hay calificaciones
- El Análisis de RegresiónDocumento27 páginasEl Análisis de RegresiónIRIS CORREDOR NIETOAún no hay calificaciones
- CONTENIDO S7.3 Teorema Central Del Limite Intervalo de ConfianzaDocumento11 páginasCONTENIDO S7.3 Teorema Central Del Limite Intervalo de ConfianzaSEBASTIAN ALEJANDRO CEVALLOS MACIASAún no hay calificaciones
- Academic Work - Power RangersDocumento22 páginasAcademic Work - Power RangersMARLON BRUNOAún no hay calificaciones
- Practica 6Documento5 páginasPractica 6GILBERTO RODRIGUEZ AVILAAún no hay calificaciones
- Tarea N 2Documento4 páginasTarea N 2JOSE ADRIAN ESMERALDAS COBEÑAAún no hay calificaciones
- Tarea4 Nicolas AraqueDocumento15 páginasTarea4 Nicolas AraqueNicolas AraqueAún no hay calificaciones
- Prueba 1Documento6 páginasPrueba 1Liliana AlbánAún no hay calificaciones
- Ejercicios de Distribución NORMAL Dibujando Campana de Gauss LeslyDocumento6 páginasEjercicios de Distribución NORMAL Dibujando Campana de Gauss LeslyLesly behaineAún no hay calificaciones
- 3 Ejemplos EstadisticaDocumento8 páginas3 Ejemplos EstadisticaGermán Felipe Hernández CastellanosAún no hay calificaciones
- Capitulo 8 CalidadDocumento8 páginasCapitulo 8 CalidadJessica TllezAún no hay calificaciones
- Espinal Starlyn DispersiónDocumento2 páginasEspinal Starlyn DispersiónStarlyn EspinalAún no hay calificaciones
- Capitulo 10 Punto Alto Punto Bajo Regresión SimpleDocumento17 páginasCapitulo 10 Punto Alto Punto Bajo Regresión SimpleMichelle OrtizAún no hay calificaciones
- Manual de Regresiön Regresión Lineal MúltipleDocumento27 páginasManual de Regresiön Regresión Lineal Múltiplejavier angulo peñaAún no hay calificaciones
- Taller EstadísticaDocumento34 páginasTaller EstadísticaViviana DuquinoAún no hay calificaciones
- ETN401 Clase7Documento14 páginasETN401 Clase7Elvis H. QuispeAún no hay calificaciones
- Medidas Central ProblemasDocumento7 páginasMedidas Central ProblemasFacundo Angel Gutierrez Castillo50% (2)
- Prueba Chi Cuadrado Tablas 2xnDocumento13 páginasPrueba Chi Cuadrado Tablas 2xnabelhenarejos-1Aún no hay calificaciones
- 15 Introduccion Al Analisis de Datos. Estimacion PuntualDocumento11 páginas15 Introduccion Al Analisis de Datos. Estimacion PuntualmkmkmAún no hay calificaciones
- Estadistica InferencialDocumento62 páginasEstadistica Inferencialsebatian chavarriaAún no hay calificaciones
- Taller 1 Estadística IIDocumento2 páginasTaller 1 Estadística IISofia RoseroAún no hay calificaciones