También podría gustarte
- Econometría I: manual de Eviews: Estimulación de un modelo de exportaciónDe EverandEconometría I: manual de Eviews: Estimulación de un modelo de exportaciónAún no hay calificaciones
- Clase 01 - Macroeconometría PDFDocumento160 páginasClase 01 - Macroeconometría PDFGabriela HerreraAún no hay calificaciones
- SERIES DE TIEMPO v7Documento79 páginasSERIES DE TIEMPO v7Leo Daniem Flores sanchezAún no hay calificaciones
- Ciclo Tendencia DiferenciaciònDocumento12 páginasCiclo Tendencia DiferenciaciònDavid CeliAún no hay calificaciones
- Pid 00212753-2 PDFDocumento66 páginasPid 00212753-2 PDFAlejandro Piñeiro Caro100% (1)
- Pronósticos cuantitativos modelosDocumento13 páginasPronósticos cuantitativos modelosFlor GonzalezAún no hay calificaciones
- Desarrollo de la clase: Relaciones Económicas Internacionales y Ciclos EconómicosDocumento12 páginasDesarrollo de la clase: Relaciones Económicas Internacionales y Ciclos EconómicosJOSE LUIS OROXOM QUIROAAún no hay calificaciones
- IntroEco - Clase 12 - 11may19Documento12 páginasIntroEco - Clase 12 - 11may19JOSE LUIS OROXOM QUIROAAún no hay calificaciones
- Numeros Indices (Ejercicios)Documento55 páginasNumeros Indices (Ejercicios)Guillermo Vasquez EspinozaAún no hay calificaciones
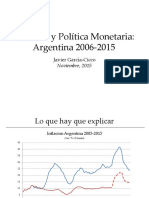
- Inflación Argentina 2006-2015: Tres enfoques explicativosDocumento47 páginasInflación Argentina 2006-2015: Tres enfoques explicativosJavier Garcia CiccoAún no hay calificaciones
- Presentación EstadisticaDocumento19 páginasPresentación EstadisticaVictoria AvilaAún no hay calificaciones
- Pronósticos cuantitativos y cualitativos para predecir la demandaDocumento33 páginasPronósticos cuantitativos y cualitativos para predecir la demandaRoger MendozaAún no hay calificaciones
- Inflación y Política Monetaria: Argentina 2006-2015: Javier García-CiccoDocumento47 páginasInflación y Política Monetaria: Argentina 2006-2015: Javier García-CiccoJavier Garcia CiccoAún no hay calificaciones
- Argentina06 14Documento42 páginasArgentina06 14Javier Garcia CiccoAún no hay calificaciones
- Estadistica: Escuela de PsicologiaDocumento31 páginasEstadistica: Escuela de PsicologiaTakeshy JaboAún no hay calificaciones
- Regresion STDocumento102 páginasRegresion STRomina OrtuñoAún no hay calificaciones
- Regresión con datos de sección cruzadaDocumento38 páginasRegresión con datos de sección cruzadaISMAEL ESTRADA CAÑASAún no hay calificaciones
- Investigacion Series de TiempoDocumento11 páginasInvestigacion Series de Tiempoadela barradasAún no hay calificaciones
- Guia 2 Derivadas.Documento5 páginasGuia 2 Derivadas.Alma Flores RiveraAún no hay calificaciones
- 1.4. Tipo de datosDocumento30 páginas1.4. Tipo de datosEstefany RivadeneiraAún no hay calificaciones
- Matemáticas. Grado Primaria. Tema 6. Estadística y Probabilidad en Educación PrimariaDocumento34 páginasMatemáticas. Grado Primaria. Tema 6. Estadística y Probabilidad en Educación PrimariaPedro PinorroAún no hay calificaciones
- Trabajo de Numeros IndicesDocumento30 páginasTrabajo de Numeros IndicesDaniela Núñez PrietoAún no hay calificaciones
- Clase 1 - Series de TiempoDocumento18 páginasClase 1 - Series de TiempomagonzalezAún no hay calificaciones
- ModeloDocumento58 páginasModeloDiana Iturbide DomínguezAún no hay calificaciones
- 1.series CronológicasDocumento35 páginas1.series Cronológicasandreemy97Aún no hay calificaciones
- Conceptos Básicos de Matemática Económica para El Manejo de Series. R. MahíaDocumento22 páginasConceptos Básicos de Matemática Económica para El Manejo de Series. R. MahíaSergio Rondón0% (1)
- 6. Modelos de Series de TiempoDocumento67 páginas6. Modelos de Series de TiempoGloria Andrea Avelino G.Aún no hay calificaciones
- Proyecto Estadistica IIDocumento14 páginasProyecto Estadistica IINefertari Huerta CaracheaAún no hay calificaciones
- APUNTE Series - Temporales PDFDocumento22 páginasAPUNTE Series - Temporales PDFMónica FríasAún no hay calificaciones
- PronosticosDocumento59 páginasPronosticosChristian Bravo ValenciaAún no hay calificaciones
- Modelos Clásicos de Volatilidad y CorrelaciónDocumento41 páginasModelos Clásicos de Volatilidad y CorrelaciónJessica Daniela Jimenez PenagosAún no hay calificaciones
- Análisis de series temporalesDocumento46 páginasAnálisis de series temporalesLoreto RuanoAún no hay calificaciones
- T4. D-Invdoc PDFDocumento8 páginasT4. D-Invdoc PDFANDREA DIAZ TEHAún no hay calificaciones
- Argentina06-12 NewDocumento43 páginasArgentina06-12 NewJavier Garcia CiccoAún no hay calificaciones
- Práctica N4Documento15 páginasPráctica N4ibeth RodriguezAún no hay calificaciones
- Trends and Cycles EspañolDocumento25 páginasTrends and Cycles EspañolTomas BalvidaresAún no hay calificaciones
- Resumen de Pronosticos y DemandaDocumento17 páginasResumen de Pronosticos y DemandaLucia BaezAún no hay calificaciones
- 2.20. La VolatilidadDocumento20 páginas2.20. La VolatilidadRashell GuevaraAún no hay calificaciones
- NUMEROS INDICEStDocumento19 páginasNUMEROS INDICEStHermann TamayoAún no hay calificaciones
- Números ÍndicesDocumento6 páginasNúmeros ÍndicesMiguel Angel Palacios BlazquezAún no hay calificaciones
- Cap. IiiiDocumento41 páginasCap. IiiiMARIA YANE AGUILAR TIRADOAún no hay calificaciones
- Unidad Ii Presupuesto de VentasDocumento5 páginasUnidad Ii Presupuesto de Ventassofia.siguenzaAún no hay calificaciones
- Remuneración mensual según sector de trabajoDocumento9 páginasRemuneración mensual según sector de trabajoEdinsson SanchezAún no hay calificaciones
- Pronostico ARIMA.: Nombre de La SerieDocumento57 páginasPronostico ARIMA.: Nombre de La SerieDiana Iturbide DomínguezAún no hay calificaciones
- Introduccion Al Eviews PDFDocumento53 páginasIntroduccion Al Eviews PDFEda Rosales CastilloAún no hay calificaciones
- ThirlwallDocumento54 páginasThirlwallAndres GonzalezAún no hay calificaciones
- Técnicas Econométricas para El Pronóstico de Series de TiempoDocumento163 páginasTécnicas Econométricas para El Pronóstico de Series de TiempoRosse RosarioAún no hay calificaciones
- Matereial de Apoyo Sobre Econometría y Estadistica InferencialDocumento22 páginasMatereial de Apoyo Sobre Econometría y Estadistica InferencialIng. Luis Fernando Restrepo100% (2)
- TEMA 5-Series CronologicasDocumento8 páginasTEMA 5-Series Cronologicastrue0666Aún no hay calificaciones
- EST APLI MKT - Series de Tiempo - Método de Descomposiciónl 2021-2Documento15 páginasEST APLI MKT - Series de Tiempo - Método de Descomposiciónl 2021-2Fernando AlvaAún no hay calificaciones
- Clase 3. PronosticoDocumento46 páginasClase 3. PronosticoSANTIAGO SANTOSAún no hay calificaciones
- Series de tiempoDocumento63 páginasSeries de tiempoGastón Ariel OrellanoAún no hay calificaciones
- Variación Cíclica: Fluctuaciones PeriódicasDocumento7 páginasVariación Cíclica: Fluctuaciones PeriódicasMarcelaChavenAún no hay calificaciones
- T4. Diaz Andrea-Invdoc PDFDocumento9 páginasT4. Diaz Andrea-Invdoc PDFANDREA DIAZ TEHAún no hay calificaciones
- BalanzDocumento8 páginasBalanzGabriel ConteAún no hay calificaciones
- XX Simposio Mercado CapitalesDocumento13 páginasXX Simposio Mercado CapitalesMarioAndresPerezLorcaAún no hay calificaciones
- Análisis de datos estadísticos en comercioDocumento20 páginasAnálisis de datos estadísticos en comercioalbertoAún no hay calificaciones
- Activ #1cálculo Medidas DispersiónDocumento2 páginasActiv #1cálculo Medidas DispersiónKaroline GarciaAún no hay calificaciones
- Gráficas de Datos EconómicosDocumento11 páginasGráficas de Datos EconómicosMarx CortesAún no hay calificaciones
- Determinación de La Rentabilidad Del Mercado para El Modelo de Valoración de Activos Financieros, CAPMDocumento7 páginasDeterminación de La Rentabilidad Del Mercado para El Modelo de Valoración de Activos Financieros, CAPMEUSEBIO MONTES PAUDAAún no hay calificaciones
- Estrés oxidativo y antioxidantes: equilibrio en o menosDocumento8 páginasEstrés oxidativo y antioxidantes: equilibrio en o menosJAVIER ANDRES BEJARANO CABIELESAún no hay calificaciones
- 1 5089565614746371008Documento101 páginas1 5089565614746371008Yohitza GalvizAún no hay calificaciones
- Contenido Programático BioquimicaDocumento5 páginasContenido Programático BioquimicaJose TrujilloAún no hay calificaciones
- Manual Comision Tesis-Udo para CarmenDocumento25 páginasManual Comision Tesis-Udo para CarmenJudith MataAún no hay calificaciones
- Nivel de Educación Media, Registro de Evaluación Continua, 2do Momento Pedagógico Período 2021-2022Documento6 páginasNivel de Educación Media, Registro de Evaluación Continua, 2do Momento Pedagógico Período 2021-2022Alexander ZerpaAún no hay calificaciones
- PDF 928Documento10 páginasPDF 928chemoltrufioAún no hay calificaciones
- Contrato académico UBA Venezuela estudios superioresDocumento4 páginasContrato académico UBA Venezuela estudios superioresJose TrujilloAún no hay calificaciones
- Libro 02 - Manual de La Comision de Tesis-UDO (2004)Documento25 páginasLibro 02 - Manual de La Comision de Tesis-UDO (2004)Jose TrujilloAún no hay calificaciones
- Contrato académico UBA Venezuela estudios superioresDocumento4 páginasContrato académico UBA Venezuela estudios superioresJose TrujilloAún no hay calificaciones
- Fuentes - Desarrollo de Videojuego de Aventuras en C# Sobre UnityDocumento57 páginasFuentes - Desarrollo de Videojuego de Aventuras en C# Sobre UnityDaniel Enrique Erazo MujicaAún no hay calificaciones
- Llamado Generalconcurso 2021Documento1 páginaLlamado Generalconcurso 2021Lizmery LuboAún no hay calificaciones
- Aranceles UCV Ajustados SmnNOV17Documento1 páginaAranceles UCV Ajustados SmnNOV17César SantanaAún no hay calificaciones
- Correlación y RegresionDocumento24 páginasCorrelación y RegresionSuárez DavidAún no hay calificaciones
- UnityDocumento46 páginasUnityluis danielAún no hay calificaciones
- Magia BasicaDocumento10 páginasMagia BasicaLuis Miguel Allcca QuispeAún no hay calificaciones
- 2do Parcial SocialesDocumento7 páginas2do Parcial SocialesJose TrujilloAún no hay calificaciones
- Contrato académico UBA Venezuela estudios superioresDocumento4 páginasContrato académico UBA Venezuela estudios superioresJose TrujilloAún no hay calificaciones
- 518-2016-09-15-Tema2 - Regresión Con Series TemporalesDocumento33 páginas518-2016-09-15-Tema2 - Regresión Con Series TemporalesBladimir RoquezAún no hay calificaciones
- Llamado Generalconcurso 2021Documento1 páginaLlamado Generalconcurso 2021Lizmery LuboAún no hay calificaciones
- D DJJ Equipaje Di Visa Sing Re SoDocumento2 páginasD DJJ Equipaje Di Visa Sing Re Socintia201993Aún no hay calificaciones
- 44 2011 Ing ElectronicaDocumento3 páginas44 2011 Ing ElectronicaAnonymous NaNAVAa4MCAún no hay calificaciones
- Correlación y RegresionDocumento24 páginasCorrelación y RegresionSuárez DavidAún no hay calificaciones
- Tema 5 ResumenDocumento82 páginasTema 5 ResumenDisg AntonioAún no hay calificaciones
- Llamado Generalconcurso 2021Documento1 páginaLlamado Generalconcurso 2021Lizmery LuboAún no hay calificaciones
- Pares CraneanosDocumento9 páginasPares CraneanosLaura GarciaAún no hay calificaciones
- Pares CraneanosDocumento9 páginasPares CraneanosLaura GarciaAún no hay calificaciones
- Regulacion No. ARCONEL 004 15Documento18 páginasRegulacion No. ARCONEL 004 15Marlon EspejoAún no hay calificaciones
- El Uso de Los Sistemas de Informacion Geografica e PDFDocumento20 páginasEl Uso de Los Sistemas de Informacion Geografica e PDFDiego MezaAún no hay calificaciones
- Teorema de BarréDocumento3 páginasTeorema de BarréEduardo G. Romero CoralAún no hay calificaciones
- Resolución de problemas matemáticos en primariaDocumento74 páginasResolución de problemas matemáticos en primariaConcepcion Merma HuisaAún no hay calificaciones
- Método de Aproximación de VogelDocumento16 páginasMétodo de Aproximación de VogelNoemi MChAún no hay calificaciones
- Cálculo Proposicional Demostración de Validez de LasDocumento16 páginasCálculo Proposicional Demostración de Validez de LasKuranashiAún no hay calificaciones
- Solucionario Practica 1Documento4 páginasSolucionario Practica 1Suleica RamosAún no hay calificaciones
- AlgoritmosDocumento92 páginasAlgoritmosJorge Luis ChinchillaAún no hay calificaciones
- 003-Expresiones Algebraicas Racionales e IrracionalesDocumento6 páginas003-Expresiones Algebraicas Racionales e IrracionalesAnalia NuñezAún no hay calificaciones
- Trayectoria, Posición y DesplazamientoDocumento5 páginasTrayectoria, Posición y DesplazamientoJean Carlos Santana LopezAún no hay calificaciones
- Guia No1Documento7 páginasGuia No1Luis H BarbosaAún no hay calificaciones
- Tesis de GradoDocumento24 páginasTesis de GradoJonathan EsperonAún no hay calificaciones
- Guia Manto. Equipo de ComputoDocumento110 páginasGuia Manto. Equipo de ComputoJuan Manuel Maya MerazAún no hay calificaciones
- Examen parcial Estadística IIDocumento9 páginasExamen parcial Estadística IIArelis RuizAún no hay calificaciones
- FactorizaciónDocumento2 páginasFactorizaciónedison aruquipaAún no hay calificaciones
- Fisica II-Reporte 2 - Principio de Arquimides, Empuje HidrostaticoDocumento16 páginasFisica II-Reporte 2 - Principio de Arquimides, Empuje HidrostaticoGeo Chavarria86% (14)
- Analisis de Datos Eje 3Documento5 páginasAnalisis de Datos Eje 3Lady Santos MontielAún no hay calificaciones
- Viscocidad - CapilaridadDocumento14 páginasViscocidad - CapilaridadmileAún no hay calificaciones
- PLCS, Programación Lineal y Estructurada (Step7 Siemens)Documento4 páginasPLCS, Programación Lineal y Estructurada (Step7 Siemens)Nazy rebolledoAún no hay calificaciones
- Tarea No. 3Documento2 páginasTarea No. 3Dayana MachadoAún no hay calificaciones
- Capitulo 9Documento18 páginasCapitulo 9Mauricio CascellaAún no hay calificaciones
- Calibración de bureta: Análisis volumétricoDocumento3 páginasCalibración de bureta: Análisis volumétricoCarlos FloresAún no hay calificaciones
- Ejercicios de Est Imac Ion Por IntervalosDocumento11 páginasEjercicios de Est Imac Ion Por IntervalosManuel Alvariño Torres0% (2)
- ESTÁTICA 6 (v2)Documento27 páginasESTÁTICA 6 (v2)Gelen MendozaAún no hay calificaciones
- Tarea 2 Corte 3Documento10 páginasTarea 2 Corte 3Abi Santamaria LpzAún no hay calificaciones
- Guia Sec Sep Evaluacion EjemploDocumento11 páginasGuia Sec Sep Evaluacion Ejemplonicolas ravezAún no hay calificaciones
- TALLER 01 - Estadística - Administración - EmpresasDocumento2 páginasTALLER 01 - Estadística - Administración - EmpresasjessicavaronAún no hay calificaciones
- Guia de Ejercicios Resueltos Movimiento de ProyectilesDocumento4 páginasGuia de Ejercicios Resueltos Movimiento de ProyectilesJOEL PALOMINO CARHUAPOMA0% (1)
- Fisica 9 1Documento2 páginasFisica 9 1Carlos berrios CanalAún no hay calificaciones
- Ed Quim RelojDocumento7 páginasEd Quim RelojFalcondrackAún no hay calificaciones
- Didáctica de la matemática en la escuela primariaDe EverandDidáctica de la matemática en la escuela primariaCalificación: 2.5 de 5 estrellas2.5/5 (3)
- La Teoría de Conjuntos y los Fundamentos de las MatemáticasDe EverandLa Teoría de Conjuntos y los Fundamentos de las MatemáticasCalificación: 5 de 5 estrellas5/5 (1)
- Metodología de la investigación científicaDe EverandMetodología de la investigación científicaCalificación: 3.5 de 5 estrellas3.5/5 (7)
- La Biblia de las Matemáticas RápidasDe EverandLa Biblia de las Matemáticas RápidasCalificación: 4.5 de 5 estrellas4.5/5 (19)
- Estadística básica: Introducción a la estadística con RDe EverandEstadística básica: Introducción a la estadística con RCalificación: 5 de 5 estrellas5/5 (8)
- Enseñar Matemática hoy: Miradas, sentidos y desafíosDe EverandEnseñar Matemática hoy: Miradas, sentidos y desafíosCalificación: 5 de 5 estrellas5/5 (1)
- Mentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraDe EverandMentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraCalificación: 4.5 de 5 estrellas4.5/5 (5)
- Curso rápido sobre magia del caos. El hobby oculto de ricos y famosos.De EverandCurso rápido sobre magia del caos. El hobby oculto de ricos y famosos.Calificación: 5 de 5 estrellas5/5 (42)
- Qué es (y qué no es) la estadística: Usos y abusos de una disciplina clave en la vida de los países y las personasDe EverandQué es (y qué no es) la estadística: Usos y abusos de una disciplina clave en la vida de los países y las personasCalificación: 4.5 de 5 estrellas4.5/5 (3)
- Introducción a la Estadística BayesianaDe EverandIntroducción a la Estadística BayesianaCalificación: 5 de 5 estrellas5/5 (2)
- Nuevo manual de Reflexología: El método más completo y actual sobre las técnicas, la práctica y la teoría de la ciencia reflexológicaDe EverandNuevo manual de Reflexología: El método más completo y actual sobre las técnicas, la práctica y la teoría de la ciencia reflexológicaCalificación: 4.5 de 5 estrellas4.5/5 (16)
- Control de calidad. Un enfoque integral y estadísticoDe EverandControl de calidad. Un enfoque integral y estadísticoCalificación: 5 de 5 estrellas5/5 (8)
- Sesgos Cognitivos: Una Fascinante Mirada dentro de la Psicología Humana y los Métodos para Evitar la Disonancia Cognitiva, Mejorar sus Habilidades para Resolver Problemas y Tomar Mejores DecisionesDe EverandSesgos Cognitivos: Una Fascinante Mirada dentro de la Psicología Humana y los Métodos para Evitar la Disonancia Cognitiva, Mejorar sus Habilidades para Resolver Problemas y Tomar Mejores DecisionesCalificación: 4.5 de 5 estrellas4.5/5 (13)
- Modelización matemática en el aula: Posibilidades y necesidadesDe EverandModelización matemática en el aula: Posibilidades y necesidadesCalificación: 5 de 5 estrellas5/5 (1)
- Mi proyecto escolar Matemáticas Lúdicas: Adaptaciones curriculares para preescolar, primaria y secundariaDe EverandMi proyecto escolar Matemáticas Lúdicas: Adaptaciones curriculares para preescolar, primaria y secundariaCalificación: 5 de 5 estrellas5/5 (5)
- Elementos de estadística en riesgo financieroDe EverandElementos de estadística en riesgo financieroAún no hay calificaciones
- Diseño y construcción de algoritmosDe EverandDiseño y construcción de algoritmosCalificación: 4 de 5 estrellas4/5 (6)
- Introducción a las ecuaciones de la física matemáticaDe EverandIntroducción a las ecuaciones de la física matemáticaCalificación: 5 de 5 estrellas5/5 (4)
- La noción de medio en la teoría de las situaciones didácticas: Una herramienta para analizar decisiones en las clases de matemáticaDe EverandLa noción de medio en la teoría de las situaciones didácticas: Una herramienta para analizar decisiones en las clases de matemáticaCalificación: 5 de 5 estrellas5/5 (1)
- Iniciación al estudio de la teoría de las situaciones didácticasDe EverandIniciación al estudio de la teoría de las situaciones didácticasCalificación: 5 de 5 estrellas5/5 (1)
- Econometría: modelos econométricos y series temporales. Tomo 2: Con los paquetes micro-TSP y TSPDe EverandEconometría: modelos econométricos y series temporales. Tomo 2: Con los paquetes micro-TSP y TSPAún no hay calificaciones
- Inteligencia artificial: Lo que usted necesita saber sobre el aprendizaje automático, robótica, aprendizaje profundo, Internet de las cosas, redes neuronales, y nuestro futuroDe EverandInteligencia artificial: Lo que usted necesita saber sobre el aprendizaje automático, robótica, aprendizaje profundo, Internet de las cosas, redes neuronales, y nuestro futuroCalificación: 4 de 5 estrellas4/5 (1)
- Cuántica: Qué significa la teoría de la ciencia más extrañaDe EverandCuántica: Qué significa la teoría de la ciencia más extrañaCalificación: 1 de 5 estrellas1/5 (1)
- El ADN espiritual: Método de iluminación espiritualDe EverandEl ADN espiritual: Método de iluminación espiritualCalificación: 4.5 de 5 estrellas4.5/5 (16)
- Métodos cuantitativos 4a Ed. Herramientas para la investigación en saludDe EverandMétodos cuantitativos 4a Ed. Herramientas para la investigación en saludCalificación: 4 de 5 estrellas4/5 (1)