También podría gustarte
- PESTEL de Avianca Holdings SDocumento4 páginasPESTEL de Avianca Holdings Sbrian barretus100% (2)
- Fijación de Precios - IKEA Tarea 4-1 para Entregar.Documento23 páginasFijación de Precios - IKEA Tarea 4-1 para Entregar.bolivar gonzalezAún no hay calificaciones
- 1 - Gestión Clínica y GRD 2014Documento43 páginas1 - Gestión Clínica y GRD 2014Patricio Orlando Quezada Olate100% (3)
- Correos Electrónicos Memorias Eroticas - Francisco Umbral PDFDocumento121 páginasCorreos Electrónicos Memorias Eroticas - Francisco Umbral PDFAndrés GarcíaAún no hay calificaciones
- Articulo IFAC PDFDocumento4 páginasArticulo IFAC PDFdicson tarazonatAún no hay calificaciones
- Medidas de Seguridad Laboral en Antenas de Telecomunicacion PDFDocumento126 páginasMedidas de Seguridad Laboral en Antenas de Telecomunicacion PDFMijaelVargas100% (1)
- Ejemplo Descripción Sobre Solución Establecidas o Relacionada Con El ProblemaDocumento4 páginasEjemplo Descripción Sobre Solución Establecidas o Relacionada Con El ProblemaAstrid Peña NevadoAún no hay calificaciones
- Ciencia de Datos Inteligencia Artificial y Sus ImpDocumento3 páginasCiencia de Datos Inteligencia Artificial y Sus ImpGustavo RojasAún no hay calificaciones
- Articulo Josue Trejos CDocumento8 páginasArticulo Josue Trejos CJosueTrejosAún no hay calificaciones
- Uso Y Análisis Estadístico de Las Tecnologías de La Información Y Comunicación en SaludDocumento9 páginasUso Y Análisis Estadístico de Las Tecnologías de La Información Y Comunicación en SaludJhonny Wilder AspiAún no hay calificaciones
- Jleditor, Vulnerabilidades Generadas Por El Uso de Las Redes Sociales, en Los Estudiantes de Bachillerato Del Centro Urbano Del CantóDocumento15 páginasJleditor, Vulnerabilidades Generadas Por El Uso de Las Redes Sociales, en Los Estudiantes de Bachillerato Del Centro Urbano Del CantóAllison R CAún no hay calificaciones
- Actividad 2Documento6 páginasActividad 2Wendy Liceth SanchezAún no hay calificaciones
- 2022-Conocimientos Sobre CiberseguridadDocumento29 páginas2022-Conocimientos Sobre CiberseguridadAlonso MaciasAún no hay calificaciones
- Angel Marcelo Rea GuamanDocumento466 páginasAngel Marcelo Rea GuamanOscar DavidAún no hay calificaciones
- Analisis Sistematico de La Inteligencia Artificial Como Servicio para La Deteccion Facial - Avance 75%Documento9 páginasAnalisis Sistematico de La Inteligencia Artificial Como Servicio para La Deteccion Facial - Avance 75%Luis Chaparro ChavezAún no hay calificaciones
- Protocolo de InvestigacionDocumento4 páginasProtocolo de InvestigacionMichelle Peralta VegaAún no hay calificaciones
- ENSAYODocumento4 páginasENSAYOEdwin Varela100% (1)
- Seminario 2poster Final - XiomyDocumento1 páginaSeminario 2poster Final - Xiomyxiomara tiqueAún no hay calificaciones
- Tendencias Investigativas en Educación en Ciberseguridad Un Estudio BibliométricoDocumento16 páginasTendencias Investigativas en Educación en Ciberseguridad Un Estudio BibliométricojaimecoloradoramirezAún no hay calificaciones
- Ayuda Proyecto BiometricoDocumento14 páginasAyuda Proyecto Biometricomv3635191Aún no hay calificaciones
- Investigación Documental (MALWARE)Documento26 páginasInvestigación Documental (MALWARE)Eduardo ZeledónAún no hay calificaciones
- InvestigaciónDocumento6 páginasInvestigaciónMELANY NICOLETTE CASTILLO CANOVAAún no hay calificaciones
- Tarea4 - Yeferson Paul Sanchez - Cod1114058891Documento7 páginasTarea4 - Yeferson Paul Sanchez - Cod1114058891yeffer paulAún no hay calificaciones
- 1698208038436Documento32 páginas1698208038436Jack KappoxAún no hay calificaciones
- Recomendaciones para El Uso de Inteligencia Artificial DocenciaDocumento32 páginasRecomendaciones para El Uso de Inteligencia Artificial DocenciaJesusAún no hay calificaciones
- Problema para Las Tecnologías Del Siglo XXIDocumento8 páginasProblema para Las Tecnologías Del Siglo XXImuseche3Aún no hay calificaciones
- 2.3 Perspectiva TeoricaDocumento16 páginas2.3 Perspectiva TeoricaElaJuradoAún no hay calificaciones
- El Uso Ético de La Inteligencia Artificial en El Aula UniversitariaDocumento7 páginasEl Uso Ético de La Inteligencia Artificial en El Aula Universitariaelenaisabel75Aún no hay calificaciones
- Art 1traducidoDocumento16 páginasArt 1traducidoana maria arias diazAún no hay calificaciones
- Guia DocentesDocumento28 páginasGuia DocentesRommel Freddy Astudillo AguilarAún no hay calificaciones
- Articulo Formato Josue Trejos CDocumento7 páginasArticulo Formato Josue Trejos CJosueTrejosAún no hay calificaciones
- 2230-Texto Del Artículo-8804-6-10-20220526Documento24 páginas2230-Texto Del Artículo-8804-6-10-20220526Nathy RomanAún no hay calificaciones
- TEXTO N°1 El Aprendizaje Inmersivo Mediante Juegos de Entrenamiento en Ambientes de Realidad Virtual en La MedicinaDocumento4 páginasTEXTO N°1 El Aprendizaje Inmersivo Mediante Juegos de Entrenamiento en Ambientes de Realidad Virtual en La Medicinayoutube comendsAún no hay calificaciones
- Anexo 4 - Formato - Entrega - Tarea4 HerramientasDocumento7 páginasAnexo 4 - Formato - Entrega - Tarea4 HerramientasJohana natalia AlzateAún no hay calificaciones
- Informacion de Riesgo o Manejo de La InformacionDocumento5 páginasInformacion de Riesgo o Manejo de La InformacionFuria Verde AlexAún no hay calificaciones
- CACIED Dorian BolañosDocumento11 páginasCACIED Dorian BolañosDorian Sebastian Bola�os Coral [Estudiante]Aún no hay calificaciones
- Cómo Ayuda La IADocumento8 páginasCómo Ayuda La IAEmanuel Torres MoralesAún no hay calificaciones
- Invu3 Equipo5Documento16 páginasInvu3 Equipo5ELIZABETH SALOME SOBRADO RUIZAún no hay calificaciones
- A+de+la+revista,+1.+artículo Sistemas+ (Psicometría)Documento7 páginasA+de+la+revista,+1.+artículo Sistemas+ (Psicometría)Cami PuertoAún no hay calificaciones
- Funda FinalizadoDocumento61 páginasFunda Finalizadoke weiAún no hay calificaciones
- Panel Buenas Practicas - ICAF - Carlos Alberto BarreraDocumento14 páginasPanel Buenas Practicas - ICAF - Carlos Alberto BarreraMIGUEL MIGUEL RIVAS SALCEDOAún no hay calificaciones
- Ia 3Documento10 páginasIa 3cohem82353Aún no hay calificaciones
- Búsqueda Avanzada en InternetDocumento9 páginasBúsqueda Avanzada en InternetJorge Luis Arana PocomuchaAún no hay calificaciones
- Producto EducomunicativoDocumento12 páginasProducto EducomunicativoNicolas SuasnavasAún no hay calificaciones
- ANTEPROYECTODocumento20 páginasANTEPROYECTOdiangel gilAún no hay calificaciones
- RetrieveDocumento29 páginasRetrievejosselyncl230Aún no hay calificaciones
- Capitilo IIDocumento20 páginasCapitilo IITood WoodAún no hay calificaciones
- Reconocimiento Facial para Mejorar Las Medidas de Vigilancia y SeguridadDocumento8 páginasReconocimiento Facial para Mejorar Las Medidas de Vigilancia y SeguridadMARIA MILAGROS FRANCIA CONDORIAún no hay calificaciones
- TA01 ProblematizaciónDocumento10 páginasTA01 ProblematizaciónFREDDY EDUARDO FLORES OBANDOAún no hay calificaciones
- Chumo - Wendy - EnsayoU1Documento6 páginasChumo - Wendy - EnsayoU1Limber Roberth Avila VeraAún no hay calificaciones
- 906-Resultados de La Investigación-2312-1-10-20210710Documento16 páginas906-Resultados de La Investigación-2312-1-10-20210710Emanuel AngelAún no hay calificaciones
- Ati. CarreraDocumento7 páginasAti. Carreravaleriapalacios05Aún no hay calificaciones
- Ensayo InglésDocumento7 páginasEnsayo InglésMaria Fernanda SalazarAún no hay calificaciones
- Aplicación de La Inteligencia Artificial en Nuestro EntornoDocumento22 páginasAplicación de La Inteligencia Artificial en Nuestro EntornoMarilyn AlvaAún no hay calificaciones
- Investigacion en CiberseguridadDocumento5 páginasInvestigacion en CiberseguridadFlacaAlejandraAún no hay calificaciones
- Tecnología de La Información (Realidad Virtual yDocumento14 páginasTecnología de La Información (Realidad Virtual yLizeth QuincheAún no hay calificaciones
- Practica Calificada No 3Documento2 páginasPractica Calificada No 3Juan Salazar CerónAún no hay calificaciones
- Tarea 5Documento8 páginasTarea 5Camilo SuarezAún no hay calificaciones
- V Resumen CongresoDocumento29 páginasV Resumen CongresoOmar ChitoAún no hay calificaciones
- S05.s1 La Paráfrasis Como Estrategia de Manejo de Información (Material) Agosto 2022Documento2 páginasS05.s1 La Paráfrasis Como Estrategia de Manejo de Información (Material) Agosto 2022Miguelo GianottiAún no hay calificaciones
- Aplicación de Seguridad Con Deep Learning en Empresas Polar 5to ADocumento10 páginasAplicación de Seguridad Con Deep Learning en Empresas Polar 5to ACarlos MorenoAún no hay calificaciones
- 2021 Tesis Mari Fernanda MantillaDocumento59 páginas2021 Tesis Mari Fernanda MantillaJohn JumboAún no hay calificaciones
- Actividad 7 - Incorporando Estrategia de Inclusión Socio-Digital A Su ProyectoDocumento4 páginasActividad 7 - Incorporando Estrategia de Inclusión Socio-Digital A Su Proyectolopezlorena2123Aún no hay calificaciones
- Taller Pena de MuerteDocumento2 páginasTaller Pena de MuerteSALOMÉ AGUILAR SOTOAún no hay calificaciones
- Seminario - RM-20 NovDocumento6 páginasSeminario - RM-20 NovYuvissa Zavaleta LozanoAún no hay calificaciones
- Miscelaneas Literarias Traducciones de Carlos Guido SpanoDocumento277 páginasMiscelaneas Literarias Traducciones de Carlos Guido SpanojesusAún no hay calificaciones
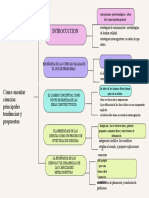
- Introcuccion: Como Enseñar Ciencias. Principales Tendencias y PropuestasDocumento1 páginaIntrocuccion: Como Enseñar Ciencias. Principales Tendencias y PropuestasEmma Ventura HernándezAún no hay calificaciones
- Barria, Mauricioel Peso de La PurezavDocumento19 páginasBarria, Mauricioel Peso de La PurezavCrispizarrosAún no hay calificaciones
- Geo 4 Triangulos - Lineas Notables - Congruencia IIDocumento13 páginasGeo 4 Triangulos - Lineas Notables - Congruencia IIEber Vargas AlanizAún no hay calificaciones
- Cuaderno de Informes 2.1Documento15 páginasCuaderno de Informes 2.1Mijael PaucarAún no hay calificaciones
- Cremonia de Sacrificio Moche - Interaccionismo SimbólicoDocumento76 páginasCremonia de Sacrificio Moche - Interaccionismo SimbólicoMARINETEAún no hay calificaciones
- Arboles de Regresion IntroduccionDocumento18 páginasArboles de Regresion IntroduccionCharo PradosAún no hay calificaciones
- TOMAR MEJORES DECISIONES CON EL BIG DATA - Rugel Coronel IvánDocumento6 páginasTOMAR MEJORES DECISIONES CON EL BIG DATA - Rugel Coronel IvánIván Rugel CoronelAún no hay calificaciones
- Producto Académico #3: Estadística General (ASUC 01275)Documento5 páginasProducto Académico #3: Estadística General (ASUC 01275)Aeli Del Carmen Revilla TacoAún no hay calificaciones
- Ensayo SatanasDocumento1 páginaEnsayo SatanasFabian SandovalAún no hay calificaciones
- Ev. MedicionDocumento4 páginasEv. MedicionKarla Rivera San CristobalAún no hay calificaciones
- Ejercicios Prácticos de SimulaciónDocumento3 páginasEjercicios Prácticos de SimulaciónAylin Rengifo100% (1)
- Matriz de Requisitos VS ProcesosDocumento7 páginasMatriz de Requisitos VS ProcesosIngrid Giraldo NaranjoAún no hay calificaciones
- Guia 1Documento4 páginasGuia 1OswaldoAmayaBautistaAún no hay calificaciones
- TDR Masinga Reservorio Con RevisionDocumento26 páginasTDR Masinga Reservorio Con RevisionAlex SHAún no hay calificaciones
- El AmarantoDocumento18 páginasEl AmarantoSandra MendezAún no hay calificaciones
- Guia 5 El Viejo TerribleDocumento4 páginasGuia 5 El Viejo Terriblemaria constanzaAún no hay calificaciones
- Matriz EricDocumento4 páginasMatriz Ericyulieth correaAún no hay calificaciones
- Anexo Plan Superior VIG. FEBRERO 2021Documento22 páginasAnexo Plan Superior VIG. FEBRERO 2021guido el pro saldivarAún no hay calificaciones
- Lim011604 Certificacion Onix Roca Oct 2020Documento20 páginasLim011604 Certificacion Onix Roca Oct 2020San EduardoAún no hay calificaciones
- Reforma ProtestanteDocumento10 páginasReforma ProtestanteEdwin Ronald Mamani MamaniAún no hay calificaciones
- Introducción Regulación ContableDocumento54 páginasIntroducción Regulación ContableSara VAún no hay calificaciones
- Ensayo Logica Juridica - Grupo 9Documento12 páginasEnsayo Logica Juridica - Grupo 9ANA CRISTINA TELLO ALIAGAAún no hay calificaciones
- Norma Técnica Colombiana NTC 5254Documento2 páginasNorma Técnica Colombiana NTC 5254Tera VidAún no hay calificaciones