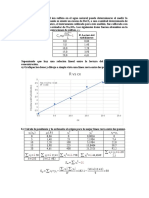
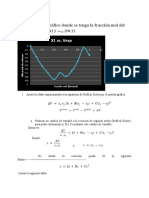
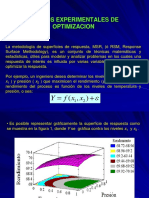
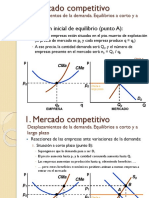
También podría gustarte
- Regresion Lineal SimpleDocumento6 páginasRegresion Lineal SimpleRooDriigoo' Lliiuya'50% (2)
- Formulario de EconometríaDocumento15 páginasFormulario de EconometríaJean Marcelo UrreloTejerina67% (3)
- Carril Neumático Final YaDocumento14 páginasCarril Neumático Final YaAglomerados LeonAún no hay calificaciones
- Actividad4.ItzeldelCarmen DelgadoTorres.2941180Documento25 páginasActividad4.ItzeldelCarmen DelgadoTorres.2941180Manuel Rodso100% (1)
- Guía de Econometría (RLS) Por Carlos BastardoDocumento48 páginasGuía de Econometría (RLS) Por Carlos BastardoCarlos Bastardo GonzálezAún no hay calificaciones
- EJ10Documento3 páginasEJ10Erick NavarreteAún no hay calificaciones
- Act 4 - EstadisticaDocumento5 páginasAct 4 - EstadisticaFabiola MancillasAún no hay calificaciones
- Práctica Regresión Lineal y CorrelaciónDocumento12 páginasPráctica Regresión Lineal y Correlaciónj100% (4)
- Tabla Nº. I.1 Análisis de Varianza para Los Equipos de La Liga NacionalDocumento8 páginasTabla Nº. I.1 Análisis de Varianza para Los Equipos de La Liga Nacionaljesus lopez100% (3)
- Matrices ProblemasDocumento17 páginasMatrices ProblemasFabio EspinosaAún no hay calificaciones
- Examen Tercer Parcial EconometriaDocumento12 páginasExamen Tercer Parcial EconometriaJONATHAN IVAN BALDERRAMA PICASOAún no hay calificaciones
- Métodos Matriciales para ingenieros con MATLABDe EverandMétodos Matriciales para ingenieros con MATLABCalificación: 5 de 5 estrellas5/5 (1)
- Econometría I: manual de Eviews: Estimulación de un modelo de exportaciónDe EverandEconometría I: manual de Eviews: Estimulación de un modelo de exportaciónAún no hay calificaciones
- Análisis de Regresion Lineal MúltipleDocumento14 páginasAnálisis de Regresion Lineal MúltipleAlan MirandaAún no hay calificaciones
- Protocolo de Investigación en ValuaciónDocumento3 páginasProtocolo de Investigación en ValuaciónJuan Carlos VidalAún no hay calificaciones
- Ejercicios PDFDocumento11 páginasEjercicios PDFLa magia de la BiologíaAún no hay calificaciones
- 2021 1 EF73 Examen FinalDocumento4 páginas2021 1 EF73 Examen FinalAlexis Tejada SantillanAún no hay calificaciones
- UD7-Regresion - ProbProp 20 y 21Documento17 páginasUD7-Regresion - ProbProp 20 y 21Paqui SaleroAún no hay calificaciones
- Tema 5 Ei 2 23BDocumento41 páginasTema 5 Ei 2 23BMauricio Canul ChanAún no hay calificaciones
- Métodos de Pronóstico CausalDocumento8 páginasMétodos de Pronóstico CausalLUZ KARIME TORRES LOZADAAún no hay calificaciones
- Regresion LinealDocumento21 páginasRegresion Linealhegumy118Aún no hay calificaciones
- Simples JojooDocumento16 páginasSimples JojooFredy ParionaAún no hay calificaciones
- Taller 8Documento10 páginasTaller 8Jimmy D. Rozo GAún no hay calificaciones
- Ejercicios SuazDocumento27 páginasEjercicios SuazDIEGO BALTAZAR HERVASAún no hay calificaciones
- Ejercicios Resueltos de Examenes Pasados-Estadistica IDocumento25 páginasEjercicios Resueltos de Examenes Pasados-Estadistica IJoel Alexander Quiroz Vargas100% (2)
- Unidad 2 - Muestreo Irrestricto Aleatorio PDFDocumento18 páginasUnidad 2 - Muestreo Irrestricto Aleatorio PDFDaniela Vallejo CadavidAún no hay calificaciones
- Tutorial Spatstat 2Documento55 páginasTutorial Spatstat 2Gerardo MartinAún no hay calificaciones
- Ejer ControlDocumento14 páginasEjer ControlHeidy FhbAún no hay calificaciones
- Material Teoria de NumerosDocumento20 páginasMaterial Teoria de NumerosLuis MiguelAún no hay calificaciones
- DescriptivaDocumento3 páginasDescriptivaosca gamAún no hay calificaciones
- Practica 2 - Datos - Calculos - Reporte 4Documento5 páginasPractica 2 - Datos - Calculos - Reporte 4Alondra GRAún no hay calificaciones
- Regresion Lineal Simple Seleccion de Actividades ResueltasDocumento20 páginasRegresion Lineal Simple Seleccion de Actividades ResueltasEduardo Sánchez HernándezAún no hay calificaciones
- Practica 2Documento9 páginasPractica 2Efrain Franco Huaylliri AjataAún no hay calificaciones
- RegresionDocumento13 páginasRegresionpervack100% (1)
- Trabajo 1Documento5 páginasTrabajo 1norma navarroAún no hay calificaciones
- Problemas Bloque 1Documento16 páginasProblemas Bloque 1María BenitoAún no hay calificaciones
- Estadistica Aplicada . - Tarea 2Documento10 páginasEstadistica Aplicada . - Tarea 2Marco OviedoAún no hay calificaciones
- Memoria Explicativa SPT CopecDocumento17 páginasMemoria Explicativa SPT CopecAntonio CortezAún no hay calificaciones
- 1.4 Cuadrados LatinosDocumento18 páginas1.4 Cuadrados LatinosLuis Wes MolesAún no hay calificaciones
- Solucion PROBLEMAS JULIO 2021Documento14 páginasSolucion PROBLEMAS JULIO 2021supanchitoAún no hay calificaciones
- Seminario Tarea 2Documento1 páginaSeminario Tarea 2Valery Sepúlveda PodestáAún no hay calificaciones
- Trabajo Práctico Encargado Gomero Aquino Ernesto AlonsoDocumento17 páginasTrabajo Práctico Encargado Gomero Aquino Ernesto AlonsoZainx XPLAún no hay calificaciones
- Precios HedonicosDocumento5 páginasPrecios HedonicosEdwin Cutipa LuqueAún no hay calificaciones
- Practicaregresionest 2016Documento5 páginasPracticaregresionest 2016maranny100% (1)
- Monitoria 1 AutocorrelaciónDocumento22 páginasMonitoria 1 AutocorrelaciónTomas UrregoAún no hay calificaciones
- DISENO FACTORIAL 2kDocumento49 páginasDISENO FACTORIAL 2kDanier Cubillo M50% (2)
- EJERCICIO2Documento22 páginasEJERCICIO2Caro MoralesAún no hay calificaciones
- Laboratorio 2 FinalDocumento110 páginasLaboratorio 2 Finalsamiraaramoss21Aún no hay calificaciones
- Regresión No Lineal AhoritaDocumento26 páginasRegresión No Lineal AhoritaPablo Zamora LeónAún no hay calificaciones
- RTARC. - Determinacion de K y N (Problema 13)Documento8 páginasRTARC. - Determinacion de K y N (Problema 13)Carlos LoachaminAún no hay calificaciones
- Ejercicios 5Documento13 páginasEjercicios 5mafe13arenasAún no hay calificaciones
- AnscombeDocumento7 páginasAnscombeFelipe GiachinoAún no hay calificaciones
- Clase 6 16-03-2022Documento21 páginasClase 6 16-03-2022Jose Maria Quintas GironAún no hay calificaciones
- Actividad 4 EstadisticaDocumento6 páginasActividad 4 Estadisticaadalit garciabernaAún no hay calificaciones
- Diseños de OptimizaciónDocumento32 páginasDiseños de OptimizaciónArnold Mamani LinaresAún no hay calificaciones
- Ortega 2013 C1 S2Documento5 páginasOrtega 2013 C1 S2JUAN SEBASTIÁN MIÑOAún no hay calificaciones
- Examen de Aplazados de Econometria II 2017-IDocumento2 páginasExamen de Aplazados de Econometria II 2017-IEingel Rap100% (1)
- Wilcoxon y Mann WhitneyDocumento11 páginasWilcoxon y Mann WhitneyMagno 92100% (2)
- Ejercicios Resueltos s6Documento4 páginasEjercicios Resueltos s6Lizbeth RangelAún no hay calificaciones
- 28 9 PDFDocumento14 páginas28 9 PDFAnaHernandezAún no hay calificaciones
- CEP1 Ejercicios SDocumento15 páginasCEP1 Ejercicios SNayla Estefania100% (1)
- Ilovepdf Merged PDFDocumento17 páginasIlovepdf Merged PDFGerman Galdamez OvandoAún no hay calificaciones
- Guia de Clases PracticasDocumento20 páginasGuia de Clases PracticasVictor GarciaAún no hay calificaciones
- Ud01 Numeros Reales Muestra I PDFDocumento46 páginasUd01 Numeros Reales Muestra I PDFJordali CastilloAún no hay calificaciones
- Geometric modeling in computer: Aided geometric designDe EverandGeometric modeling in computer: Aided geometric designAún no hay calificaciones
- Introducción a la dinámica computacional de fluidos (CFD) en Ingeniería Química.De EverandIntroducción a la dinámica computacional de fluidos (CFD) en Ingeniería Química.Aún no hay calificaciones
- Conductor Es Line A LesDocumento6 páginasConductor Es Line A LesAglomerados LeonAún no hay calificaciones
- Seminario 1 ChemaDocumento29 páginasSeminario 1 ChemaAglomerados LeonAún no hay calificaciones
- FaradayDocumento8 páginasFaradayAglomerados LeonAún no hay calificaciones
- DifraccionDocumento7 páginasDifraccionAglomerados LeonAún no hay calificaciones
- Tema7 ProbDocumento2 páginasTema7 ProbAglomerados LeonAún no hay calificaciones
- Informe Del Rozamiento Por DeslizamientoDocumento9 páginasInforme Del Rozamiento Por DeslizamientoAglomerados LeonAún no hay calificaciones
- Examenes Con Soluciones 2011 2012Documento15 páginasExamenes Con Soluciones 2011 2012Aglomerados LeonAún no hay calificaciones
- T7mov OndulatorioDocumento70 páginasT7mov OndulatorioAglomerados LeonAún no hay calificaciones
- CarrilDocumento7 páginasCarrilAglomerados LeonAún no hay calificaciones
- BrewsterDocumento8 páginasBrewsterAglomerados LeonAún no hay calificaciones
- Movimiento Ondulatorio Tubo de KundtDocumento9 páginasMovimiento Ondulatorio Tubo de KundtAglomerados LeonAún no hay calificaciones
- SolidorigidoDocumento76 páginasSolidorigidoAglomerados LeonAún no hay calificaciones
- Problemas DescriptivaDocumento35 páginasProblemas DescriptivaAglomerados LeonAún no hay calificaciones
- EDOprimer OrdenDocumento2 páginasEDOprimer OrdenAglomerados LeonAún no hay calificaciones
- Formula Rio 1Documento2 páginasFormula Rio 1Aglomerados LeonAún no hay calificaciones
- Examenes 2011Documento14 páginasExamenes 2011Aglomerados LeonAún no hay calificaciones
- Examenes Con Soluciones 2012 2013Documento19 páginasExamenes Con Soluciones 2012 2013Aglomerados LeonAún no hay calificaciones
- Tema6 ProbDocumento1 páginaTema6 ProbAglomerados LeonAún no hay calificaciones
- 8 La Empresa Como Organización EconómicaDocumento16 páginas8 La Empresa Como Organización EconómicaAglomerados LeonAún no hay calificaciones
- Examenes2013 14Documento16 páginasExamenes2013 14Aglomerados LeonAún no hay calificaciones
- Exámenes 2015-2016Documento21 páginasExámenes 2015-2016Aglomerados LeonAún no hay calificaciones
- 7 Fuentes de Financiación y Coste Del Capital - Mayo2017Documento32 páginas7 Fuentes de Financiación y Coste Del Capital - Mayo2017Aglomerados LeonAún no hay calificaciones
- 2-1 Excedente Del Consumidor y Del ProductorDocumento4 páginas2-1 Excedente Del Consumidor y Del ProductorAglomerados LeonAún no hay calificaciones
- Anexo PARTE 1 - Variaciones en La Demanda en Equilibrio de Mercado (2017)Documento3 páginasAnexo PARTE 1 - Variaciones en La Demanda en Equilibrio de Mercado (2017)Aglomerados LeonAún no hay calificaciones
- 5 Empresa y La Informacion Contable-2017Documento52 páginas5 Empresa y La Informacion Contable-2017Aglomerados LeonAún no hay calificaciones
- 6 Valoración de Proyectos de InversiónDocumento28 páginas6 Valoración de Proyectos de InversiónAglomerados LeonAún no hay calificaciones
- 3 Producción y Costes (2017)Documento88 páginas3 Producción y Costes (2017)Aglomerados LeonAún no hay calificaciones
- 4 Mercado y Estrategia. PARTE 1 - Mercado Competitivo (2017)Documento51 páginas4 Mercado y Estrategia. PARTE 1 - Mercado Competitivo (2017)Aglomerados LeonAún no hay calificaciones
- 2014 Examen Empresa JulioDocumento5 páginas2014 Examen Empresa JulioAglomerados LeonAún no hay calificaciones
- 02 Ingeniería Vial Apuntes 2 PDFDocumento24 páginas02 Ingeniería Vial Apuntes 2 PDFCamilo OrmenoAún no hay calificaciones
- 20170926110956Documento97 páginas20170926110956Gabriel Silupú MoralesAún no hay calificaciones
- Cálculo Aplicado Resumen Del TemaDocumento21 páginasCálculo Aplicado Resumen Del TemaMuñozAún no hay calificaciones
- Tarea Estadistica 6Documento7 páginasTarea Estadistica 6rominaAún no hay calificaciones
- Informe-Ley - de - Distancia y Absorcion de Rayos Gamma.Documento6 páginasInforme-Ley - de - Distancia y Absorcion de Rayos Gamma.Maria Camila AmadoAún no hay calificaciones
- Regresion Lineal SimpleDocumento14 páginasRegresion Lineal SimpleJorge RiosAún no hay calificaciones
- Syllabus Estadistica - InferencialDocumento6 páginasSyllabus Estadistica - InferencialJavier Alberto Martínez GuadarramaAún no hay calificaciones
- Final Bioestadística Medicina 03-07-2017 ResueltoDocumento8 páginasFinal Bioestadística Medicina 03-07-2017 ResueltoAitanaAún no hay calificaciones
- 2 de 5 Hands On Machine Learning With Scikit 2E (139 240) .En - EsDocumento102 páginas2 de 5 Hands On Machine Learning With Scikit 2E (139 240) .En - EsNicolas Iturrieta BerriosAún no hay calificaciones
- Trabajo de Ejercicios Matematico Grado UndecimoDocumento4 páginasTrabajo de Ejercicios Matematico Grado UndecimoHurtado LeydisAún no hay calificaciones
- Primer Avance Del TF - GRUPO 4Documento32 páginasPrimer Avance Del TF - GRUPO 4Fabiola VegaAún no hay calificaciones
- TransformacionlinealDocumento25 páginasTransformacionlinealDante Palacios ValdiviezoAún no hay calificaciones
- Espirometria Valores de ReferenciaDocumento21 páginasEspirometria Valores de ReferenciaFrancisco Astorga AAún no hay calificaciones
- Tipologia FacialDocumento64 páginasTipologia Facialtroyano1183Aún no hay calificaciones
- Teoría de La CorrelaciónDocumento8 páginasTeoría de La CorrelaciónBlady AnAún no hay calificaciones
- El Poder de Las VentasDocumento12 páginasEl Poder de Las VentasManuel Cordova Vasquez0% (1)
- FORMULARIO Métodos NuméricosDocumento23 páginasFORMULARIO Métodos NuméricosDaniel Ortiz LealAún no hay calificaciones
- Fórmulas EstadísticaDocumento7 páginasFórmulas EstadísticaGuillermo100% (1)
- Programa Psicoestadistica I - 2023Documento19 páginasPrograma Psicoestadistica I - 2023abril caylaAún no hay calificaciones
- Temas de Covarianza y Regresion en AgronomiaDocumento135 páginasTemas de Covarianza y Regresion en AgronomiaJosé Eduardo Rojas TapiaAún no hay calificaciones
- Trabajo de EstadisticaDocumento9 páginasTrabajo de EstadisticaPaul Vargas MezaAún no hay calificaciones
- Auditoría de Desempeño PDFDocumento30 páginasAuditoría de Desempeño PDFAmistad BecergAún no hay calificaciones
- Ejercicios Regresion y CorrelacionDocumento2 páginasEjercicios Regresion y CorrelacionMaryeli Ilian Castillo CarretoAún no hay calificaciones
- 2 PronosticosDocumento105 páginas2 PronosticosNicolás MayaAún no hay calificaciones
- ManuscriptDocumento13 páginasManuscriptErika Vanessa Martinez NuñezAún no hay calificaciones