También podría gustarte
- Análisis de Cluster Con El Método No Jerárquico y Método JerárquicoDocumento9 páginasAnálisis de Cluster Con El Método No Jerárquico y Método JerárquicoMario Orlando Suárez IbujésAún no hay calificaciones
- Muestreo Aleatorio Simple Con R StudioDocumento4 páginasMuestreo Aleatorio Simple Con R StudioMario Orlando Suárez IbujésAún no hay calificaciones
- EDADocumento4 páginasEDAJOHAN EDELBERTO HURTADO ENRIQUEZAún no hay calificaciones
- HIPOTESISDocumento6 páginasHIPOTESISHanzAún no hay calificaciones
- Actividad1 Laura Cuartas RiosDocumento11 páginasActividad1 Laura Cuartas RiosLaurita CuartasAún no hay calificaciones
- ESTADÍSTICA EN LA PRÁCTICADocumento12 páginasESTADÍSTICA EN LA PRÁCTICAsandra paola tunjuelo castiblancoAún no hay calificaciones
- Test HSD de Tukey ADDocumento6 páginasTest HSD de Tukey ADMario Orlando Suárez IbujésAún no hay calificaciones
- Benjamin Carrion GeneticaDocumento2 páginasBenjamin Carrion GeneticaBenjamín AlejandroAún no hay calificaciones
- Estadistica InferencialDocumento7 páginasEstadistica InferencialSus Cositas De Mi Tio MAún no hay calificaciones
- Trabajo Colaborativo Arrieta PDFDocumento21 páginasTrabajo Colaborativo Arrieta PDFfproano8091Aún no hay calificaciones
- Anguiano 21250103 U1 A1Documento7 páginasAnguiano 21250103 U1 A1Luis Enrique Anguiano GarcíaAún no hay calificaciones
- Proyecto de R WordDocumento3 páginasProyecto de R WordVane MoralesAún no hay calificaciones
- EstadisticasDocumento6 páginasEstadisticasMaizoro SabritasAún no hay calificaciones
- Proyecto de Investigación FormativaDocumento11 páginasProyecto de Investigación FormativaFederico ArévaloAún no hay calificaciones
- Análisis de datos sobre suicidios, accidentes y muertes violentasDocumento7 páginasAnálisis de datos sobre suicidios, accidentes y muertes violentasnicolas perezAún no hay calificaciones
- Preparado-virus-T-studentDocumento6 páginasPreparado-virus-T-studentDaniel ReyesAún no hay calificaciones
- Laboratorio 2 Estadística en Python - Parte 1Documento6 páginasLaboratorio 2 Estadística en Python - Parte 1Orlando SotoAún no hay calificaciones
- Laboratorio No 1 - Tutorial PDFDocumento16 páginasLaboratorio No 1 - Tutorial PDF63rm4nAún no hay calificaciones
- ¿Qué Podemos Hacer Con Los Datos? Inferencia EstadísticaDocumento17 páginas¿Qué Podemos Hacer Con Los Datos? Inferencia EstadísticaGuido ElordiAún no hay calificaciones
- Entregable 2 - Diseño de Sistemas de Aprendizaje AutomaticoDocumento12 páginasEntregable 2 - Diseño de Sistemas de Aprendizaje AutomaticoJENNIFER MELOAún no hay calificaciones
- Introducción a los análisis estadísticos en RDe EverandIntroducción a los análisis estadísticos en RAún no hay calificaciones
- Chue. El Origen de La Estadistica.Documento8 páginasChue. El Origen de La Estadistica.Jorge Rojas GeldresAún no hay calificaciones
- Procesos de Inteligencia Colectiva y Colaborativa en El Marco de Tecnologías Web 2.0, Version Corregida para PublicarDocumento24 páginasProcesos de Inteligencia Colectiva y Colaborativa en El Marco de Tecnologías Web 2.0, Version Corregida para PublicarPablo Perez VilarAún no hay calificaciones
- Proyecto - Analisis Exploratorio de DatosDocumento11 páginasProyecto - Analisis Exploratorio de Datoscrismarsan2809Aún no hay calificaciones
- Informe de Proyecto AvancesDocumento5 páginasInforme de Proyecto AvancesJessika Santos LopezAún no hay calificaciones
- Sesp U1 A3 CRGRDocumento10 páginasSesp U1 A3 CRGROlivia Guerrero Ravelo100% (2)
- Practica ControldeFlujoDocumento9 páginasPractica ControldeFlujohugo.hdez.hdez74Aún no hay calificaciones
- ProbabilidadDocumento12 páginasProbabilidadChristian JavierAún no hay calificaciones
- TECNOLOGÍA-ESTADÍSTICADocumento35 páginasTECNOLOGÍA-ESTADÍSTICAMaría Leonor100% (3)
- Cronograma 2016 Análisis Numérico Avanzado FCE-UBADocumento4 páginasCronograma 2016 Análisis Numérico Avanzado FCE-UBAno_serviceAún no hay calificaciones
- Final Grupo 100105 92Documento24 páginasFinal Grupo 100105 92CARLOS ANDRES SANTANAAún no hay calificaciones
- Infostat, Infogen Y Sas para Contrastes Mutuamente Ortogonales en Experimentos en Bloques Completos Al Azar en Parcelas SubdivididasDocumento15 páginasInfostat, Infogen Y Sas para Contrastes Mutuamente Ortogonales en Experimentos en Bloques Completos Al Azar en Parcelas SubdivididasFray Luís RDAún no hay calificaciones
- EstratificaciónDocumento4 páginasEstratificaciónNancy PérezAún no hay calificaciones
- Guía UCINETDocumento44 páginasGuía UCINETGabriel Perez Diaz100% (2)
- Trabajo Entrega Estadistica Ii PDFDocumento18 páginasTrabajo Entrega Estadistica Ii PDFConnie Aranda RuizAún no hay calificaciones
- CarlosQuan CursoAmbientalDocumento2 páginasCarlosQuan CursoAmbientalMasterUnicorn 666Aún no hay calificaciones
- Análisis de Temperaturas Global y México con NumPy y MatplotlibDocumento6 páginasAnálisis de Temperaturas Global y México con NumPy y MatplotlibAmairany Araujo FuentesAún no hay calificaciones
- Propuesta-Estadística IIDocumento4 páginasPropuesta-Estadística IILISETH PINEDA100% (1)
- González Matías Sandra Paola-402Documento52 páginasGonzález Matías Sandra Paola-402Miriam Janeth Ignacio GarciaAún no hay calificaciones
- Estadistica 2Documento16 páginasEstadistica 2Milagros CamiloagaAún no hay calificaciones
- Un Estudio LongitudinalDocumento7 páginasUn Estudio LongitudinalPamela Anaya MonzonAún no hay calificaciones
- Preguntas de Entrada Estadistica 1Documento7 páginasPreguntas de Entrada Estadistica 1Blackwhite .VAún no hay calificaciones
- Ejercicio 1 - Oscar Guzman CondeDocumento7 páginasEjercicio 1 - Oscar Guzman CondeOsCaRCoNdEeAún no hay calificaciones
- Elaboración de Un Histograma Mediante La Recopilación de Números Aleatorios en FortranDocumento9 páginasElaboración de Un Histograma Mediante La Recopilación de Números Aleatorios en FortranJoseCundapiAún no hay calificaciones
- Sesion 7 - Solucion EstDocumento4 páginasSesion 7 - Solucion EstMariana VélezAún no hay calificaciones
- La Inteligencia Artificial en La MedicinaDocumento6 páginasLa Inteligencia Artificial en La MedicinaFaridIvanArriagaAún no hay calificaciones
- Solemne 3Documento11 páginasSolemne 3Ricardo Antonio Vargas EncinaAún no hay calificaciones
- Modelo Informe Escala Wechsler de Inteligencia WISCDocumento3 páginasModelo Informe Escala Wechsler de Inteligencia WISCjungiano09100% (1)
- Unidad2 Fase3 Grupo300046 112.Documento23 páginasUnidad2 Fase3 Grupo300046 112.Angelica Maria Gonzalez OrtegaAún no hay calificaciones
- Aspectos Generales de La EstadísticaDocumento12 páginasAspectos Generales de La EstadísticaJulio Longart50% (2)
- Estimación estadística: Propiedades de los estimadores puntualesDocumento7 páginasEstimación estadística: Propiedades de los estimadores puntualesMiranda PérezAún no hay calificaciones
- 3oAvancePF - II ALP ADocumento9 páginas3oAvancePF - II ALP ADULCE JAZMIN CARVAJAL SOTUYOAún no hay calificaciones
- Estimaciones e intervalos de confianza en Seguridad PúblicaDocumento6 páginasEstimaciones e intervalos de confianza en Seguridad PúblicaIsrael Arrieta GarcíaAún no hay calificaciones
- MileidyDocumento26 páginasMileidyangelica daniela sanchez trujilloAún no hay calificaciones
- Evaluación Continua 3 - 1PM LEIIDY LUDEÑADocumento3 páginasEvaluación Continua 3 - 1PM LEIIDY LUDEÑALeidy LudeñaAún no hay calificaciones
- Guía No 6 - III Seg - Razonamiento Aleatorio - Estadística y Probabilidad - Profe Daniel Llinás 2019-IDocumento8 páginasGuía No 6 - III Seg - Razonamiento Aleatorio - Estadística y Probabilidad - Profe Daniel Llinás 2019-Ijose joséAún no hay calificaciones
- Un Software de Fotogrametría Como Herramienta para La Agricultura de Precisión - Un Estudio de Caso - SpringerLinkDocumento9 páginasUn Software de Fotogrametría Como Herramienta para La Agricultura de Precisión - Un Estudio de Caso - SpringerLinkManu YcazaAún no hay calificaciones
- Actividad 1Documento20 páginasActividad 1Ivan Sanchez GaliciaAún no hay calificaciones
- Estadística para veterinarios y zootecnistasDe EverandEstadística para veterinarios y zootecnistasCalificación: 5 de 5 estrellas5/5 (1)
- Machine Learning For Data Science - Tratamiento y Preparacion de Los InformacionDocumento35 páginasMachine Learning For Data Science - Tratamiento y Preparacion de Los InformacionJefry Gutiérrez CelisAún no hay calificaciones
- Modulo 1Documento114 páginasModulo 1Luis Villegas AjahuanaAún no hay calificaciones
- Entendimiento del negocio: Definición de la variable objetivo (TargetDocumento41 páginasEntendimiento del negocio: Definición de la variable objetivo (TargetLuis Villegas AjahuanaAún no hay calificaciones
- $RLL95WVDocumento4 páginas$RLL95WVLuis Villegas AjahuanaAún no hay calificaciones
- Reglamento del aire: preguntas DGAC sobre RPAS, vuelo y aeronáuticaDocumento14 páginasReglamento del aire: preguntas DGAC sobre RPAS, vuelo y aeronáuticaLuis Villegas Ajahuana100% (2)
- $RG35TTIDocumento3 páginas$RG35TTILuis Villegas AjahuanaAún no hay calificaciones
- AmbientedeTrabajo Miniconda 2021 (Windows)Documento6 páginasAmbientedeTrabajo Miniconda 2021 (Windows)Luis Villegas AjahuanaAún no hay calificaciones
- Catalogo FNB Junio 2022Documento133 páginasCatalogo FNB Junio 2022Luis Villegas AjahuanaAún no hay calificaciones
- $R2LA5LEDocumento2 páginas$R2LA5LELuis Villegas AjahuanaAún no hay calificaciones
- Sesión 01. - Fundamentos Del PLN y Elementos Básicos Del LenguajeDocumento95 páginasSesión 01. - Fundamentos Del PLN y Elementos Básicos Del LenguajeLuis Villegas AjahuanaAún no hay calificaciones
- $R18ARF0Documento11 páginas$R18ARF0Luis Villegas AjahuanaAún no hay calificaciones
- Guía para El Diseño de Puentes Con Vigas y LosasDocumento136 páginasGuía para El Diseño de Puentes Con Vigas y LosasJorge CastroAún no hay calificaciones
- Sist de Gestión de La Seg Vial - Mayte Saenz PDFDocumento18 páginasSist de Gestión de La Seg Vial - Mayte Saenz PDFJose Luis VargasAún no hay calificaciones
- $RMPXC9CDocumento2 páginas$RMPXC9CLuis Villegas AjahuanaAún no hay calificaciones
- $R18ARF0Documento11 páginas$R18ARF0Luis Villegas AjahuanaAún no hay calificaciones
- Brochure Monster (7643)Documento5 páginasBrochure Monster (7643)Luis Villegas AjahuanaAún no hay calificaciones
- ISO-39001-Plan-de - ImplementaciónDocumento2 páginasISO-39001-Plan-de - ImplementaciónFernando100% (2)
- 01 - Sistema de Informacion para El Modelamiento TransporteDocumento17 páginas01 - Sistema de Informacion para El Modelamiento TransporteLuis Villegas AjahuanaAún no hay calificaciones
- Sistemas Inteligentes de Transporte en Chile Jorge Minteguiaga PDFDocumento29 páginasSistemas Inteligentes de Transporte en Chile Jorge Minteguiaga PDFLuis Villegas AjahuanaAún no hay calificaciones
- Capacidad y Niveles de ServicioDocumento121 páginasCapacidad y Niveles de ServicioLoyda MarcelaAún no hay calificaciones
- Diseño Geometrico de Carreteras y Calles AASTHO-1994Documento486 páginasDiseño Geometrico de Carreteras y Calles AASTHO-1994SiDi Mohammed El Mejdoubi100% (15)
- Planos Museografia TodoDocumento23 páginasPlanos Museografia TodoLuis Villegas AjahuanaAún no hay calificaciones
- 06 Filosofia de Diseño para PuentesDocumento44 páginas06 Filosofia de Diseño para PuentesLuiz M. Collado Pantoja100% (4)
- COSTOSDocumento2 páginasCOSTOSLuis Villegas AjahuanaAún no hay calificaciones
- Planos Museografia TodoDocumento23 páginasPlanos Museografia TodoLuis Villegas AjahuanaAún no hay calificaciones
- t-13 - Xiii Conic PDFDocumento5 páginast-13 - Xiii Conic PDFLuis Villegas AjahuanaAún no hay calificaciones
- ConstruyendoCaminos 9Documento68 páginasConstruyendoCaminos 9Luis Villegas AjahuanaAún no hay calificaciones
- Tesis de Ingenieria Civil #09Documento138 páginasTesis de Ingenieria Civil #09Edu Val R100% (1)
- PROVIAS Diccionario Técnico Vial PDFDocumento235 páginasPROVIAS Diccionario Técnico Vial PDFLuis AiteAún no hay calificaciones
- DSM VDocumento32 páginasDSM Vsary32Aún no hay calificaciones
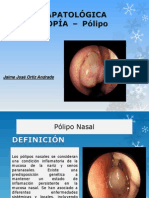
- ANATOMÍAPATOLÓGICA MACROSCOPÍA - Polipo NasalesDocumento9 páginasANATOMÍAPATOLÓGICA MACROSCOPÍA - Polipo NasalesJaime Jose Ortiz AndradeAún no hay calificaciones
- Sesion 2 - Estrategias Sanitarias Nacional de SaludDocumento13 páginasSesion 2 - Estrategias Sanitarias Nacional de SaludM Belén MGAún no hay calificaciones
- t2 (Comunicacion 1)Documento7 páginast2 (Comunicacion 1)Julio PoloAún no hay calificaciones
- Tesis Doctorado Manuel Minteguiaga. Versión BibliotecaDocumento578 páginasTesis Doctorado Manuel Minteguiaga. Versión BibliotecaNasha AbascalAún no hay calificaciones
- Tipos de BanquetesDocumento21 páginasTipos de BanquetesSantiago HernandezAún no hay calificaciones
- Guilherme Costa Fausto, Mariana Costa Fausto, Formulation Control of Equine Gastrointestinal Parasitic NematodesDocumento6 páginasGuilherme Costa Fausto, Mariana Costa Fausto, Formulation Control of Equine Gastrointestinal Parasitic NematodesGabriela BohorquezAún no hay calificaciones
- Instalaciones y Cableado Deficiente o de Seccion IncorrectaDocumento25 páginasInstalaciones y Cableado Deficiente o de Seccion Incorrectamaikey rubioAún no hay calificaciones
- Procedimiento de Montaje de Módulos Camión Grúa Articulado Rev.01 PDFDocumento11 páginasProcedimiento de Montaje de Módulos Camión Grúa Articulado Rev.01 PDFcatalina plazaAún no hay calificaciones
- FSSC 22000Documento65 páginasFSSC 22000Tacianus Velázquez80% (5)
- AracneismoDocumento35 páginasAracneismoBeatriz UgazAún no hay calificaciones
- Guía Práctica Semana 2Documento6 páginasGuía Práctica Semana 2AntoniCCisnerosAún no hay calificaciones
- BacteriasDocumento15 páginasBacteriasJonathan CoaguilaAún no hay calificaciones
- Dolor Pélvico Agudo Ludwing, Wilmary, Edgar y María - FinalDocumento15 páginasDolor Pélvico Agudo Ludwing, Wilmary, Edgar y María - FinalLudwing TorrealbaAún no hay calificaciones
- Guia Integrada - La Sexualidad.Documento10 páginasGuia Integrada - La Sexualidad.Leonardo GelvezAún no hay calificaciones
- Beneficios de La Terapia FloralDocumento2 páginasBeneficios de La Terapia FloralPsicopedagogoRojoAún no hay calificaciones
- Libro RuilDocumento56 páginasLibro RuilRichi CarrilloAún no hay calificaciones
- Tarea 2 - Análisis de CasosDocumento11 páginasTarea 2 - Análisis de CasosGilberto Zúñiga Monje89% (9)
- Anatomia CutaneaDocumento5 páginasAnatomia CutaneaFatima CejasAún no hay calificaciones
- Ante Proyecto Seguridad VialDocumento12 páginasAnte Proyecto Seguridad VialMaría HerreraAún no hay calificaciones
- Programa de Sso EscanerDocumento26 páginasPrograma de Sso EscanerMatias Torquea100% (1)
- Tuberías Circulares HidraulicaDocumento12 páginasTuberías Circulares HidraulicaFrancisco Alciviades Buñay ReinosoAún no hay calificaciones
- Guia de Pokemon Ash GrayDocumento47 páginasGuia de Pokemon Ash GrayManuel Gonzalez50% (2)
- Bodilyharm SpanishDocumento379 páginasBodilyharm SpanishLuisa EscuderoAún no hay calificaciones
- Analisis Causa Raiz-2Documento6 páginasAnalisis Causa Raiz-2RXSECAún no hay calificaciones
- Paseo Por El MarDocumento28 páginasPaseo Por El MarmonroeatlacuetzonAún no hay calificaciones
- Trabajo PrácticoDocumento4 páginasTrabajo PrácticoCiin AvilaAún no hay calificaciones
- Anatomía y ciclo vital de las garrapatasDocumento90 páginasAnatomía y ciclo vital de las garrapatasJuan Tantte RengifoAún no hay calificaciones
- Act. 1.1 ATDIDocumento11 páginasAct. 1.1 ATDIpaolaAún no hay calificaciones
- Sabores Criollos - Cosas Unicasa Venezuela PDFDocumento129 páginasSabores Criollos - Cosas Unicasa Venezuela PDFdavidAún no hay calificaciones