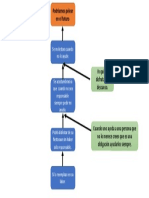
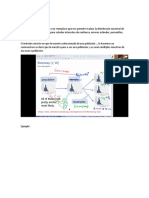
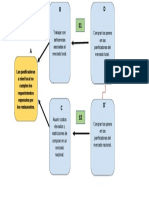
También podría gustarte
- Del inicio al fin del amor: ruptura de pareja y salud mentalDe EverandDel inicio al fin del amor: ruptura de pareja y salud mentalAún no hay calificaciones
- ALCANCES Y LIMITACIONES Guarda y CustodiaDocumento21 páginasALCANCES Y LIMITACIONES Guarda y CustodiaClaudia ViazcanAún no hay calificaciones
- Ras EspañolDocumento28 páginasRas EspañolKennedy LuiguiAún no hay calificaciones
- Propuesta de Reducción Del Inventario Multifacético de Satisfacción Marital (IMSM)Documento12 páginasPropuesta de Reducción Del Inventario Multifacético de Satisfacción Marital (IMSM)JoelPaterninaPinedaAún no hay calificaciones
- Validación Del Cuestionario para ParejasDocumento7 páginasValidación Del Cuestionario para ParejasDaruiwn Esteban Gonzalez MayorgaAún no hay calificaciones
- Parcial Machine Learning 2023Documento2 páginasParcial Machine Learning 2023GabrielCanoAún no hay calificaciones
- Bienestar CorreccionesDocumento10 páginasBienestar CorreccionesERIKA REYCY CHAVEZ MAMANIAún no hay calificaciones
- Test Atencionales ResumenDocumento5 páginasTest Atencionales Resumenandrea palmaAún no hay calificaciones
- Trabajo Colaborativo JopDocumento14 páginasTrabajo Colaborativo JopAderley Suárez100% (1)
- Discusión y ConclusionesDocumento3 páginasDiscusión y ConclusionesYocy MarianneAún no hay calificaciones
- Informe PsicologicoDocumento3 páginasInforme PsicologicoKarla Leon75% (4)
- Srs Traduccion ManualDocumento36 páginasSrs Traduccion ManualGuadalupe Gaytan100% (11)
- PRADS Traducción de Versión Cyr Et Al. 1995Documento18 páginasPRADS Traducción de Versión Cyr Et Al. 1995Diego Rosas WellmannAún no hay calificaciones
- Satisfacción Marital PDFDocumento16 páginasSatisfacción Marital PDFJuanito MaravillasAún no hay calificaciones
- Merino Arndt 2004Documento29 páginasMerino Arndt 2004KevinAngheloTairo0% (1)
- Trabajo Colaborativo Estadistica IiDocumento12 páginasTrabajo Colaborativo Estadistica Iisandra paola tunjuelo castiblancoAún no hay calificaciones
- Pruebas Parametricas y No ParametricasDocumento6 páginasPruebas Parametricas y No ParametricasJavier Camilo Mercado RiveraAún no hay calificaciones
- Tesis GottmanDocumento26 páginasTesis Gottmanwilliam medinaAún no hay calificaciones
- PortafolioDocumento20 páginasPortafolioAna AbadAún no hay calificaciones
- Terapia Psicológica 2007Documento17 páginasTerapia Psicológica 2007Yvan AliagaAún no hay calificaciones
- Paso 4 - Psicometria - Deimer Steven AlvarezDocumento13 páginasPaso 4 - Psicometria - Deimer Steven Alvarezsonia julio hAún no hay calificaciones
- Test FamiliaresDocumento25 páginasTest FamiliaresLaurent Victoria100% (1)
- Psicometria Enunciado Pec 2Documento8 páginasPsicometria Enunciado Pec 2Vanessa Ponce BorquezAún no hay calificaciones
- S13-Tarea 7Documento6 páginasS13-Tarea 7JOSELYN DARIAN MENDOZA VILLONAún no hay calificaciones
- Protocolo Estudio de Familia Cesfam Marcos Macuada OgaldeDocumento11 páginasProtocolo Estudio de Familia Cesfam Marcos Macuada OgaldeElizabetContrerasSandovalAún no hay calificaciones
- Resumen PsicometriaDocumento4 páginasResumen Psicometriacristian david zuñiga muñozAún no hay calificaciones
- Actividad 3 Teorías de Los TestDocumento10 páginasActividad 3 Teorías de Los TestValentina HoyosAún no hay calificaciones
- Cuestionario Ambiente Familiar para NiñosDocumento22 páginasCuestionario Ambiente Familiar para NiñosTania AstrayAún no hay calificaciones
- Psicoterapia de Niños - Estilo Personal Del Terapeuta y Su Relación Con Alianza TerapéuticaDocumento5 páginasPsicoterapia de Niños - Estilo Personal Del Terapeuta y Su Relación Con Alianza TerapéuticaRaihue FurnoAún no hay calificaciones
- DiazdelaCruz Alessandra Act7Documento13 páginasDiazdelaCruz Alessandra Act7gtpdv2pmksAún no hay calificaciones
- Diagnóstico Relacional PDFDocumento34 páginasDiagnóstico Relacional PDFMarce Feli Calderon100% (1)
- Papper para Gestión de Riesgos Psicosociales FinalDocumento9 páginasPapper para Gestión de Riesgos Psicosociales FinalEilyn LavínAún no hay calificaciones
- Artículo Adaptación y Validación MEEQDocumento20 páginasArtículo Adaptación y Validación MEEQMatías SantosAún no hay calificaciones
- Rendimiento Academico Variables PDFDocumento10 páginasRendimiento Academico Variables PDFD. Duarte AcevedoAún no hay calificaciones
- Estructura Del Estudio de Caso Familiar.Documento10 páginasEstructura Del Estudio de Caso Familiar.Jesus RodríguezAún no hay calificaciones
- Segunda RevisiónDocumento13 páginasSegunda RevisiónDeliainezAún no hay calificaciones
- Relaciones PersonalesDocumento14 páginasRelaciones PersonalesMario AguirreAún no hay calificaciones
- Implicancias Del Perfeccionismo en Las Relaciones de ParejaDocumento9 páginasImplicancias Del Perfeccionismo en Las Relaciones de ParejaAdriana LagoAún no hay calificaciones
- Actividad 5 LORRAINE EDocumento17 páginasActividad 5 LORRAINE ELorraine IsabelAún no hay calificaciones
- Adaptacion y Estudio Psicometrico de Dos InstrumenDocumento17 páginasAdaptacion y Estudio Psicometrico de Dos Instrumenestefanydasilva130Aún no hay calificaciones
- Amado Rozas Bienestar Laboral Intención1Documento46 páginasAmado Rozas Bienestar Laboral Intención1Esteban TerrazasAún no hay calificaciones
- Dialnet ValidezDelInventarioDePracticasDeCrianzaDocumento12 páginasDialnet ValidezDelInventarioDePracticasDeCrianzaDaniel ArizaAún no hay calificaciones
- Estadisticas Unid 6.1Documento4 páginasEstadisticas Unid 6.1yonathanAún no hay calificaciones
- Reporte de Lectura - Genogramas en La Evaluación FamiliarDocumento10 páginasReporte de Lectura - Genogramas en La Evaluación FamiliarAbraham PopocatlAún no hay calificaciones
- ¿Qué Sabemos Sobre Las Variables Que Subyacen A La Actuación Del Terapeuta Altamente Eficaz?Documento10 páginas¿Qué Sabemos Sobre Las Variables Que Subyacen A La Actuación Del Terapeuta Altamente Eficaz?Tamara BravoAún no hay calificaciones
- Clase 3 Evaluación Conductual InfantilDocumento43 páginasClase 3 Evaluación Conductual InfantilcontactoequipohorizonteAún no hay calificaciones
- Apgar Familiar TrabajoDocumento7 páginasApgar Familiar TrabajoYngrid AlbarranAún no hay calificaciones
- Laboratorio Del Amor de John Gottman PDFDocumento5 páginasLaboratorio Del Amor de John Gottman PDFAlvaro Cardenas100% (3)
- Bienvenida y Consentimiento Informado: Response Was Added On 09-19-2023 21:11Documento5 páginasBienvenida y Consentimiento Informado: Response Was Added On 09-19-2023 21:11mtralulu90Aún no hay calificaciones
- 2014 Marchesan IQ - Protocolo de Evaluación en Motricidad Orofacial em Espanhol Cap 2 P 59-102Documento27 páginas2014 Marchesan IQ - Protocolo de Evaluación en Motricidad Orofacial em Espanhol Cap 2 P 59-102Mariangel CamposAún no hay calificaciones
- Estadística No Paramétrica - Estadistica IIDocumento6 páginasEstadística No Paramétrica - Estadistica IIlizbeth millordAún no hay calificaciones
- Información de PruebasDocumento3 páginasInformación de PruebasCesarAún no hay calificaciones
- Estadística No ParamétricaDocumento6 páginasEstadística No Paramétricalizbeth millordAún no hay calificaciones
- Cuestionario de Funcionamiento Familiar (FFQ)Documento2 páginasCuestionario de Funcionamiento Familiar (FFQ)Zeuz Rodriguez0% (1)
- Jamapediatrics Mori 2019 Oi 190034.en - EsDocumento10 páginasJamapediatrics Mori 2019 Oi 190034.en - EsCarlos Alarcon AlvarezAún no hay calificaciones
- Investigacion CausalDocumento8 páginasInvestigacion CausalyanethAún no hay calificaciones
- Analisis Facyotial ConfirmatorioDocumento15 páginasAnalisis Facyotial ConfirmatorioMaritza UGAún no hay calificaciones
- Resolución de Conflictos de ParejaDocumento22 páginasResolución de Conflictos de ParejaAlbert MalArAún no hay calificaciones
- Evidencia 2 - Maria CamilaDocumento4 páginasEvidencia 2 - Maria CamilaOwen RochaAún no hay calificaciones
- Preguntas Del Taller-Analisis Video-SaganDocumento1 páginaPreguntas Del Taller-Analisis Video-SaganOwen RochaAún no hay calificaciones
- Preguntas Del Taller-Analisis Video-SaganDocumento1 páginaPreguntas Del Taller-Analisis Video-SaganOwen RochaAún no hay calificaciones
- Presentación de Rama NegativaDocumento1 páginaPresentación de Rama NegativaOwen RochaAún no hay calificaciones
- Resumen 2 ParcialllDocumento11 páginasResumen 2 ParcialllOwen RochaAún no hay calificaciones
- Nube General Proyecto HerramientaDocumento1 páginaNube General Proyecto HerramientaOwen RochaAún no hay calificaciones
- Tarea de Rama NegativaDocumento3 páginasTarea de Rama NegativaOwen RochaAún no hay calificaciones
- Adelanto Tarea ExepronDocumento3 páginasAdelanto Tarea ExepronOwen RochaAún no hay calificaciones
- Nube General Proyecto HerramientaDocumento1 páginaNube General Proyecto HerramientaOwen RochaAún no hay calificaciones
- Nube General Proyecto HerramientaDocumento1 páginaNube General Proyecto HerramientaOwen RochaAún no hay calificaciones
- Nube General Proyecto HerramientaDocumento1 páginaNube General Proyecto HerramientaOwen RochaAún no hay calificaciones
- Preguntas Del Taller-Analisis Video-SaganDocumento1 páginaPreguntas Del Taller-Analisis Video-SaganOwen RochaAún no hay calificaciones
- Necesidades FisiologicasDocumento31 páginasNecesidades FisiologicasOwen RochaAún no hay calificaciones
- Necesidades Fisiológicas - SexoDocumento9 páginasNecesidades Fisiológicas - SexoOwen RochaAún no hay calificaciones
- Necesidades PsicologicasDocumento42 páginasNecesidades PsicologicasOwen RochaAún no hay calificaciones
- Tercer Parcial Mot 2021-01Documento2 páginasTercer Parcial Mot 2021-01Owen RochaAún no hay calificaciones
- Cerebro Motivado y Emocional.8696Documento14 páginasCerebro Motivado y Emocional.8696Owen RochaAún no hay calificaciones
- SustentacionDocumento2 páginasSustentacionOwen RochaAún no hay calificaciones
- Cuestionario Del Capítulo 3 - Revisión Del IntentoDocumento5 páginasCuestionario Del Capítulo 3 - Revisión Del IntentoVivian Andrea Corredor Rojas67% (3)
- Conceptos Big DataDocumento8 páginasConceptos Big DataJerry Mechato CotosAún no hay calificaciones
- Instituto de Edudcación Superior TecnológicoDocumento50 páginasInstituto de Edudcación Superior TecnológicoDavid Martin Caceres VasquezAún no hay calificaciones
- El Ciclo de Inteligencia y Sus Limites PDFDocumento16 páginasEl Ciclo de Inteligencia y Sus Limites PDFGermánAún no hay calificaciones
- Big Data Con Python 2 9Documento1 páginaBig Data Con Python 2 9PoeAún no hay calificaciones
- Evaluacion 4 Mineria de DatosDocumento30 páginasEvaluacion 4 Mineria de DatosCarlos Daniel Gonzalez Codoceo100% (1)
- La Pata Floja de Las Comunicaciones en ChileDocumento3 páginasLa Pata Floja de Las Comunicaciones en ChileSora NuñezAún no hay calificaciones
- Estadisticas ElectricidadDocumento214 páginasEstadisticas ElectricidadMarlon Xavier Erazo PazmiñoAún no hay calificaciones
- 2 Ejemplo 1 Perceptron MulticapaDocumento19 páginas2 Ejemplo 1 Perceptron MulticapaJesus Romero MirandaAún no hay calificaciones
- 1.8 Fundamentos de Data MiningDocumento6 páginas1.8 Fundamentos de Data MiningmonicaAún no hay calificaciones
- Master Business Intelligence y Big DataDocumento35 páginasMaster Business Intelligence y Big DatahenryAún no hay calificaciones
- 1 Base de Datos DistribuidasDocumento10 páginas1 Base de Datos DistribuidasJeremias MoralesAún no hay calificaciones
- Clustering TC CRISP-DM Oscar PeñafielDocumento19 páginasClustering TC CRISP-DM Oscar PeñafielOscar PeñafielAún no hay calificaciones
- El Futuro de Los Sistemas de Informacion en La IndustriaDocumento14 páginasEl Futuro de Los Sistemas de Informacion en La IndustriaAngelo Arratea Anco100% (1)
- Trabajos 8 Sistemas de Soporte para La Toma de DecisionesDocumento7 páginasTrabajos 8 Sistemas de Soporte para La Toma de DecisionesPamela Rodríguez AguilarAún no hay calificaciones
- Análisis de Los Datos en Los Centros de DistribuciónDocumento5 páginasAnálisis de Los Datos en Los Centros de DistribuciónluiskitaAún no hay calificaciones
- NN3 BackpropagationDocumento25 páginasNN3 BackpropagationLeonardo MatteraAún no hay calificaciones
- Ensayo Data MiningDocumento5 páginasEnsayo Data MiningJorge MaytaAún no hay calificaciones
- Sem 02Documento40 páginasSem 02JEFFERSON CESAR CONDE FLORESAún no hay calificaciones
- Detección de Fraude en Tarjetas de CréditoDocumento48 páginasDetección de Fraude en Tarjetas de CréditoANTHONY HECTOR HUACCACHI ALAMOAún no hay calificaciones
- Informe EstadisticaDocumento19 páginasInforme EstadisticaRoar Mendez ParejaAún no hay calificaciones
- PDF Programa - Máster en Business Intelligence - 12022021 - 074037Documento55 páginasPDF Programa - Máster en Business Intelligence - 12022021 - 074037Horacio Jose Menendez HernandezAún no hay calificaciones
- Auditoría en Salud IPRESSDocumento39 páginasAuditoría en Salud IPRESSJulio Adrian Lazo MoscolAún no hay calificaciones
- Sistemas 6Documento7 páginasSistemas 6Kelly SantiagoAún no hay calificaciones
- Sesion5 MetodologiasDocumento19 páginasSesion5 MetodologiasCitlalli IxchelAún no hay calificaciones
- Minicasos y Aplicacionessotos 123456Documento14 páginasMinicasos y Aplicacionessotos 123456Ymanolcito Cume100% (1)
- 5.2 Business - IntelligenceDocumento18 páginas5.2 Business - IntelligenceJesus CastroAún no hay calificaciones
- Introduccion A Data Minning PDFDocumento14 páginasIntroduccion A Data Minning PDFjaimesunAún no hay calificaciones
- 6RN Con Sklearn 4Documento39 páginas6RN Con Sklearn 4VictorAún no hay calificaciones
- Inteligencia ArtificialDocumento9 páginasInteligencia ArtificialODETH DAYANNA VELIZ MACIASAún no hay calificaciones
- Psicología y trastornos de los niños en la edad evolutiva: Qué son y cómo funcionanDe EverandPsicología y trastornos de los niños en la edad evolutiva: Qué son y cómo funcionanCalificación: 5 de 5 estrellas5/5 (1)
- Neuropsicología: Los fundamentos de la materiaDe EverandNeuropsicología: Los fundamentos de la materiaCalificación: 5 de 5 estrellas5/5 (1)
- Neurociencia para vencer la depresión: La esprial ascendenteDe EverandNeurociencia para vencer la depresión: La esprial ascendenteCalificación: 4.5 de 5 estrellas4.5/5 (10)
- Medicina para el Alma, Veneno para el Ego: Las respuestas que el alma busca, pero que el ego rehuyeDe EverandMedicina para el Alma, Veneno para el Ego: Las respuestas que el alma busca, pero que el ego rehuyeCalificación: 5 de 5 estrellas5/5 (5)
- Mentiras que creemos sobre Dios (Lies We Believe About God Spanish edition)De EverandMentiras que creemos sobre Dios (Lies We Believe About God Spanish edition)Calificación: 4 de 5 estrellas4/5 (17)
- Mensajes De Ángeles, Respira y Elévate en el amor Angelicar, Luz & CompasiónDe EverandMensajes De Ángeles, Respira y Elévate en el amor Angelicar, Luz & CompasiónCalificación: 4.5 de 5 estrellas4.5/5 (14)
- Bioneuroemoción: Un método para el bienestar emocionalDe EverandBioneuroemoción: Un método para el bienestar emocionalCalificación: 5 de 5 estrellas5/5 (4)
- Quitando Capas de la Cebolla. El camino de la mente al corazón.De EverandQuitando Capas de la Cebolla. El camino de la mente al corazón.Calificación: 4 de 5 estrellas4/5 (5)
- El cerebro del niño explicado a los padresDe EverandEl cerebro del niño explicado a los padresCalificación: 4.5 de 5 estrellas4.5/5 (147)
- El Poder de la Consolidación. Aquí están los secretos para consolidar millares del personasDe EverandEl Poder de la Consolidación. Aquí están los secretos para consolidar millares del personasCalificación: 5 de 5 estrellas5/5 (6)
- Meditaciones para despertar tu poder interior. Ámate, Elimina el estrés, Llénate de virtud, Experimenta paz interior, Contempla tu yo auténtico.De EverandMeditaciones para despertar tu poder interior. Ámate, Elimina el estrés, Llénate de virtud, Experimenta paz interior, Contempla tu yo auténtico.Aún no hay calificaciones
- La conciencia en el cerebro: Descifrando el enigma de cómo el cerebro elabora nuestros pensamientosDe EverandLa conciencia en el cerebro: Descifrando el enigma de cómo el cerebro elabora nuestros pensamientosCalificación: 2.5 de 5 estrellas2.5/5 (3)
- Cómo Enamorar a Alguien (Basado en la Psicología del Amor)De EverandCómo Enamorar a Alguien (Basado en la Psicología del Amor)Calificación: 4 de 5 estrellas4/5 (148)
- Enciende tu cerebro: La clave para la felicidad, la manera de pensar y la saludDe EverandEnciende tu cerebro: La clave para la felicidad, la manera de pensar y la saludCalificación: 4.5 de 5 estrellas4.5/5 (25)
- Abrázame fuerte: Siete conversaciones para un amor duraderoDe EverandAbrázame fuerte: Siete conversaciones para un amor duraderoManu BerásteguiCalificación: 4.5 de 5 estrellas4.5/5 (13)
- Dueña de mi amor: Mujeres contra la gran estafa románticaDe EverandDueña de mi amor: Mujeres contra la gran estafa románticaCalificación: 4.5 de 5 estrellas4.5/5 (17)
- El arte del descanso: Descubre el método para dormir bien y descansar mejorDe EverandEl arte del descanso: Descubre el método para dormir bien y descansar mejorCalificación: 4.5 de 5 estrellas4.5/5 (4)
- Neuromagia: Qué pueden enseñarnos los magos (y la ciencia) sobre el funcionamiento del cerebroDe EverandNeuromagia: Qué pueden enseñarnos los magos (y la ciencia) sobre el funcionamiento del cerebroCalificación: 4 de 5 estrellas4/5 (2)
- Sobre el combate: La psicología y fisiología del conflicto letal en la guerra y en la pazDe EverandSobre el combate: La psicología y fisiología del conflicto letal en la guerra y en la pazCalificación: 4 de 5 estrellas4/5 (9)
- Ansiedad en las Relaciones - Restaura Tu Vida Amorosa Eliminando Pensamientos Negativos, los Celos y el Apego Mientras Aprendes a Identificar Tus Inseguridades, y Superar Conflictos de ParejaDe EverandAnsiedad en las Relaciones - Restaura Tu Vida Amorosa Eliminando Pensamientos Negativos, los Celos y el Apego Mientras Aprendes a Identificar Tus Inseguridades, y Superar Conflictos de ParejaCalificación: 4 de 5 estrellas4/5 (9)
- Neuropsicología Clínica y CognoscitivaDe EverandNeuropsicología Clínica y CognoscitivaCalificación: 5 de 5 estrellas5/5 (1)
- El cerebro adolescente: Una mente en construcciónDe EverandEl cerebro adolescente: Una mente en construcciónCalificación: 5 de 5 estrellas5/5 (4)
- El Desafío del Amor para Cada Día: Devocionales Diarios para ParejasDe EverandEl Desafío del Amor para Cada Día: Devocionales Diarios para ParejasCalificación: 5 de 5 estrellas5/5 (15)