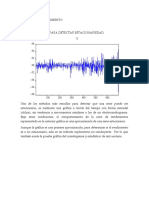
También podría gustarte
- Variable de RendimientoDocumento5 páginasVariable de RendimientoGina AsisterAún no hay calificaciones
- Series N-P No EstacionariasDocumento8 páginasSeries N-P No EstacionariasYosef CGAún no hay calificaciones
- Acercadelapruebaestadsticadela UNE689Documento13 páginasAcercadelapruebaestadsticadela UNE68906trahosAún no hay calificaciones
- Eviews PracticaDocumento19 páginasEviews PracticaMARIA MAYTHEE RUBIO MORENOAún no hay calificaciones
- Parcial 2 Econometria 2 PDFDocumento22 páginasParcial 2 Econometria 2 PDFJeferson Cortés GutiérrezAún no hay calificaciones
- Presentación 7 IIDocumento44 páginasPresentación 7 IILimbert CondoriAún no hay calificaciones
- Trabajo EconometriaDocumento16 páginasTrabajo EconometriaMaldonado91Aún no hay calificaciones
- Tema 3Documento15 páginasTema 3paula bermejo moratillaAún no hay calificaciones
- U5A2 - Vanessa Lopez Sanchez - 25-03-2023 - v9Documento7 páginasU5A2 - Vanessa Lopez Sanchez - 25-03-2023 - v9Vany LozanoAún no hay calificaciones
- S10. Pruebas de Raiz UnitariaDocumento23 páginasS10. Pruebas de Raiz Unitariadamaris pintaAún no hay calificaciones
- MIC - Unidad 4 - Sesión 7Documento55 páginasMIC - Unidad 4 - Sesión 7AIDITA DAYANA AGUILA ORTEGAAún no hay calificaciones
- Svar VeranoDocumento15 páginasSvar VeranoAlex Carmona NuñezAún no hay calificaciones
- EconometríaDocumento8 páginasEconometríaPablo RendonAún no hay calificaciones
- Ejerecicios M Independientes Grupo N°3Documento8 páginasEjerecicios M Independientes Grupo N°3Alexánder J. ApóstolAún no hay calificaciones
- Simulacro PC2 2022-II-1Documento19 páginasSimulacro PC2 2022-II-1Alexander Meza EspinarAún no hay calificaciones
- Primer Parcial AESM 2020-1Documento5 páginasPrimer Parcial AESM 2020-1Carlos MontenegroAún no hay calificaciones
- Prueba de HipotesisDocumento12 páginasPrueba de HipotesisMario Chavez ChicomaAún no hay calificaciones
- Clase 4. Inferencia Estadística IIDocumento50 páginasClase 4. Inferencia Estadística IIValentina ContrerasAún no hay calificaciones
- Unidad V Regresion Lineal Equipo 5Documento11 páginasUnidad V Regresion Lineal Equipo 5Alain A. Gómez CárdenasAún no hay calificaciones
- TP2 Larrea-Selvaggi PDFDocumento15 páginasTP2 Larrea-Selvaggi PDFSantiagoAún no hay calificaciones
- Prueba Ryan-Joiner Prueba Shappiro - WilkDocumento23 páginasPrueba Ryan-Joiner Prueba Shappiro - WilkrobertoAún no hay calificaciones
- Prueba Chi CuadradoDocumento8 páginasPrueba Chi CuadradoSkafronDiazAún no hay calificaciones
- 01 Prueba de Bondad de Ajuste (Introduccion)Documento39 páginas01 Prueba de Bondad de Ajuste (Introduccion)Jazmin Zamudio VelázquezAún no hay calificaciones
- Taller 1 Análisis Exploratorio Multivariado de Datos e Inferencia MultivariadaDocumento6 páginasTaller 1 Análisis Exploratorio Multivariado de Datos e Inferencia Multivariadadeisy quirogaAún no hay calificaciones
- Estadística Clase16Documento6 páginasEstadística Clase16ximenatubillasulfeAún no hay calificaciones
- Homework #3 - Metrics II (Adrian Tejeda)Documento11 páginasHomework #3 - Metrics II (Adrian Tejeda)Adrian TejedaAún no hay calificaciones
- Prueba de Hipotesis para Muestras RelacionadasDocumento2 páginasPrueba de Hipotesis para Muestras RelacionadasIsrael Santos RamosAún no hay calificaciones
- Informe EstacionalidadDocumento8 páginasInforme EstacionalidadyhirosebastianlobatoAún no hay calificaciones
- Taller de Métodos para Determinar La Distribucion NormalDocumento13 páginasTaller de Métodos para Determinar La Distribucion NormalAriana VillaAún no hay calificaciones
- 01 Chicuadrado-Ejemplo ResueltosDocumento37 páginas01 Chicuadrado-Ejemplo ResueltosheliariasAún no hay calificaciones
- Pruebas de HipótesisDocumento27 páginasPruebas de HipótesisLeovaldo FariaAún no hay calificaciones
- S04.s2 - MaterialDocumento25 páginasS04.s2 - MaterialAlainAedoAún no hay calificaciones
- Práctica Contrastación de Hipótesis CuantitativaDocumento4 páginasPráctica Contrastación de Hipótesis Cuantitativa05-ES-HU-JESBY LADY LEIVA ARAUCOAún no hay calificaciones
- Trabajo Final ControlDocumento26 páginasTrabajo Final ControlDavid Fernando Dongo ChiraAún no hay calificaciones
- EIlabo 01Documento8 páginasEIlabo 01Serj LeskAún no hay calificaciones
- IGBC: Un Modelo de Pronóstico para Sus RetornosDocumento6 páginasIGBC: Un Modelo de Pronóstico para Sus Retornosjeffer_rojasAún no hay calificaciones
- PRONÓSTICOSDocumento16 páginasPRONÓSTICOSCC LobatoAún no hay calificaciones
- Exposición - Chi CuadradoDocumento22 páginasExposición - Chi CuadradoAldair HidalgoAún no hay calificaciones
- Ejercicio Aplicacion S12 - SolucionDocumento25 páginasEjercicio Aplicacion S12 - SolucionNikol Solsol JaraAún no hay calificaciones
- Constraste de HipótesisDocumento18 páginasConstraste de HipótesisKazu Diaz RaymundoAún no hay calificaciones
- Prueba 1 Estadística IIDocumento4 páginasPrueba 1 Estadística IIJosh Moser SharpAún no hay calificaciones
- Estadistica TrabajoDocumento20 páginasEstadistica TrabajoJuan Merino LunaAún no hay calificaciones
- Pruebas de Hipótesis para La Varianza y El Cociente de Varianza ..Documento24 páginasPruebas de Hipótesis para La Varianza y El Cociente de Varianza ..Yanina AlvarezAún no hay calificaciones
- Estadistica InferencialDocumento17 páginasEstadistica InferencialFranco De La Cruz VargasAún no hay calificaciones
- Trabajo EstadisticaDocumento87 páginasTrabajo EstadisticaRichard MoralesAún no hay calificaciones
- Nha OoooooooDocumento30 páginasNha OooooooogsaomissAún no hay calificaciones
- Lab 1 EstadísticaDocumento9 páginasLab 1 EstadísticaFranchesca MuñozAún no hay calificaciones
- Probabilidad y Estadistica Act 1T5Documento8 páginasProbabilidad y Estadistica Act 1T5Miriam YoungAún no hay calificaciones
- Ejemplo Prueba o Contraste de HipotesisDocumento24 páginasEjemplo Prueba o Contraste de HipotesisjosheinvargasAún no hay calificaciones
- 14-TP3 - Grupo 14Documento14 páginas14-TP3 - Grupo 14Ezequiel OlguinAún no hay calificaciones
- Ajuste y BondadDocumento11 páginasAjuste y Bondaddavid12t0% (1)
- Econometría Cap 4 y 5Documento24 páginasEconometría Cap 4 y 5KAREN DANIELA FAJARDO MATALLANAAún no hay calificaciones
- Captura de Pantalla 2023-04-01 A La(s) 7.56.16 P.M.Documento31 páginasCaptura de Pantalla 2023-04-01 A La(s) 7.56.16 P.M.Karla EscalanteAún no hay calificaciones
- Clase 1.7 Econometria Septima Parte Test de HipotesisDocumento22 páginasClase 1.7 Econometria Septima Parte Test de HipotesisAlejandra Aravena Rojas100% (1)
- Aplicacion Box JenkinsDocumento72 páginasAplicacion Box JenkinsGonzalo Pasiche ManriqueAún no hay calificaciones
- Contrastes BioestadísticaDocumento12 páginasContrastes BioestadísticaVlad DanceaAún no hay calificaciones
- Presentación de Análisis Estadístico Acerca Del Tema Prueba de Hipotesis.Documento15 páginasPresentación de Análisis Estadístico Acerca Del Tema Prueba de Hipotesis.z54v6nsb7qAún no hay calificaciones
- Septima PracticaDocumento23 páginasSeptima PracticaSamir DjSatchAún no hay calificaciones
- Ejemplo ArimaDocumento33 páginasEjemplo ArimaRICARDOAún no hay calificaciones
- Guia de Actividades Agosto 2020Documento23 páginasGuia de Actividades Agosto 2020arthurmarston314Aún no hay calificaciones
- Ventajas Comp(s) y Diferenciacion Red BullDocumento2 páginasVentajas Comp(s) y Diferenciacion Red BullYesenia Brenda Salas Janampa0% (1)
- Acuerdo 5.10.23 Textiles Toluca Vs Jose Cherem 49 CivilDocumento3 páginasAcuerdo 5.10.23 Textiles Toluca Vs Jose Cherem 49 Civil419027355Aún no hay calificaciones
- Actividad de Aprendizaje #01: Datos InformativosDocumento1 páginaActividad de Aprendizaje #01: Datos InformativosCarlos Paredes VasquezAún no hay calificaciones
- Trabajo Final de Planeamiento y ControlDocumento19 páginasTrabajo Final de Planeamiento y ControlPablo Amado del Carpio0% (1)
- Actividad 3 CCSS 2°Documento3 páginasActividad 3 CCSS 2°jesalva1331100% (1)
- Fundamentos en Mercadotecnia Unidad 1 - 2Documento224 páginasFundamentos en Mercadotecnia Unidad 1 - 2Nathaly VillavicencioAún no hay calificaciones
- INFORME SOCIOECONOMICO Pablo FernándezDocumento4 páginasINFORME SOCIOECONOMICO Pablo Fernándezclcaceresj71% (7)
- Proceso Contravencional y Coactivo FCMDocumento14 páginasProceso Contravencional y Coactivo FCMANGELA MORAAún no hay calificaciones
- Cadena de SuministroDocumento7 páginasCadena de SuministroCristal Montero BenzánAún no hay calificaciones
- Clase 02 Medicion de PresionDocumento33 páginasClase 02 Medicion de PresionWilliam Yoel CcalloAún no hay calificaciones
- REPORTE - LAB - FISI1 - S06 - 2LN (1) .Docx TERMINADODocumento4 páginasREPORTE - LAB - FISI1 - S06 - 2LN (1) .Docx TERMINADOLidwin Mitjael Matheus MirandaAún no hay calificaciones
- Producto Académico N°2 Laboratorio de InnovaciónDocumento11 páginasProducto Académico N°2 Laboratorio de InnovaciónMICHAEL QUISPE PEZOAún no hay calificaciones
- Carta Anulacion Declaracion Retencion IslrDocumento1 páginaCarta Anulacion Declaracion Retencion IslrYosangelAún no hay calificaciones
- 160848-Alfredo - Mesa Conclusiones - SDS I Foro DANA 21-01-20 - DefDocumento8 páginas160848-Alfredo - Mesa Conclusiones - SDS I Foro DANA 21-01-20 - DefFrancisco LopezAún no hay calificaciones
- Comisiones: Cuenta Sueldo / Cuenta Previsional Concepto Precio (1) Periodicidad de CobroDocumento5 páginasComisiones: Cuenta Sueldo / Cuenta Previsional Concepto Precio (1) Periodicidad de Cobroastolfo buñueloAún no hay calificaciones
- M2 Actividades A Ejecutar en El Desarrollo de La Interventoria Preventiva e IntegralDocumento40 páginasM2 Actividades A Ejecutar en El Desarrollo de La Interventoria Preventiva e IntegralCarlosAlbertoGomezAmarisAún no hay calificaciones
- Agua, Ebullicion y MovimientoDocumento5 páginasAgua, Ebullicion y MovimientoRoger BrenerAún no hay calificaciones
- Aplicaiones de La Función CuadráticaDocumento1 páginaAplicaiones de La Función CuadráticaEfrain ReyesAún no hay calificaciones
- Tema 4.1.1 Aplicacion de Los Datos Estandar en Operaciones de MaquinadoDocumento9 páginasTema 4.1.1 Aplicacion de Los Datos Estandar en Operaciones de MaquinadoJavierAún no hay calificaciones
- Test de Razonamiento Abstracto N°1 - JoveneswebDocumento17 páginasTest de Razonamiento Abstracto N°1 - Jovenesweb0913012191Aún no hay calificaciones
- Anotaciones Entrega Jueves 29Documento1 páginaAnotaciones Entrega Jueves 29javi_ariAún no hay calificaciones
- Tipos de CongeladoresDocumento8 páginasTipos de CongeladoresAndrés CeballosAún no hay calificaciones
- Requisitos para Inscribirse Registro CampesinoDocumento3 páginasRequisitos para Inscribirse Registro CampesinoAlejandro Arvelaiz86% (7)
- Investigación ExplorativaDocumento7 páginasInvestigación ExplorativaraulAún no hay calificaciones
- CreeloDocumento1 páginaCreeloJulian CorreaAún no hay calificaciones
- Especificaciones de PlantillasDocumento4 páginasEspecificaciones de PlantillasAlanAún no hay calificaciones
- Acta de Reparo FiscalDocumento16 páginasActa de Reparo FiscalmiguelAún no hay calificaciones
- Tarea 1Documento5 páginasTarea 1Hesler GuevaraAún no hay calificaciones
- Mdm002 Modelo Calculo Distancia Entre ConductoresDocumento4 páginasMdm002 Modelo Calculo Distancia Entre ConductoresOswaldo Ccoñas SandovalAún no hay calificaciones