También podría gustarte
- Manual Generadores CumminsDocumento182 páginasManual Generadores CumminsSoporte SURbyte SRL85% (46)
- Flujo de Comunicacion en Las OrganizacionesDocumento2 páginasFlujo de Comunicacion en Las OrganizacionesRafael CentenoAún no hay calificaciones
- Plan de Prevencion de Riesgos Laborales Talleres de SoldaduraDocumento56 páginasPlan de Prevencion de Riesgos Laborales Talleres de Soldaduraana_abvi100% (1)
- Cómo Leer La Tabla de Carga de Una Grúa Móvil - Grúas ArlinDocumento8 páginasCómo Leer La Tabla de Carga de Una Grúa Móvil - Grúas ArlinPOWY75Aún no hay calificaciones
- Certificado Garantia Productos BoschDocumento2 páginasCertificado Garantia Productos Boschelmerarias2Aún no hay calificaciones
- Fibra OpticaDocumento17 páginasFibra OpticaDiego CaicedoAún no hay calificaciones
- Simulación y Optimización - Tema - 2Documento18 páginasSimulación y Optimización - Tema - 2carmenAún no hay calificaciones
- ProgCient - P01 - Unidad 1Documento19 páginasProgCient - P01 - Unidad 1Solange AcuñaAún no hay calificaciones
- 7 Clase Sistemas de EcuacionesDocumento10 páginas7 Clase Sistemas de EcuacionesEmpresa mineriaAún no hay calificaciones
- Markov PoissonDocumento31 páginasMarkov PoissonJuan JO NiqkoAún no hay calificaciones
- Perez Diaz Orly SeriesFurierDocumento5 páginasPerez Diaz Orly SeriesFurierdenisse maciasAún no hay calificaciones
- Algortimo de Frank and WolfeDocumento3 páginasAlgortimo de Frank and WolfeAlejandro MoralesAún no hay calificaciones
- Optimizacion VectorialDocumento32 páginasOptimizacion VectorialjoelAún no hay calificaciones
- Límite Y Sus Propiedades Introduccion A Los Límites: Recta TangenteDocumento8 páginasLímite Y Sus Propiedades Introduccion A Los Límites: Recta TangenteMelisa FrllyAún no hay calificaciones
- 2018 19 SeptiembreDocumento6 páginas2018 19 SeptiembreFrancisco PlataAún no hay calificaciones
- Clase 04 - Metodos Numericos - Seminario Ecuaciones No LinealesDocumento28 páginasClase 04 - Metodos Numericos - Seminario Ecuaciones No LinealesCARLO DANIEL QUISPE VALENZUELAAún no hay calificaciones
- Sistemas de Ecuaciones No Lineales PDFDocumento6 páginasSistemas de Ecuaciones No Lineales PDFMaria Mejias AlbornozAún no hay calificaciones
- Sesión 1 - Semana 3Documento20 páginasSesión 1 - Semana 3Nicol ChumbileAún no hay calificaciones
- 3.S2 HT Regla de La Cadena. Recta Tangente y Recta Normal 2021-2Documento2 páginas3.S2 HT Regla de La Cadena. Recta Tangente y Recta Normal 2021-2Leydi Roncal SotoAún no hay calificaciones
- Capitulo 3 - Problemas en 1D - Curso - ProblemasDocumento68 páginasCapitulo 3 - Problemas en 1D - Curso - ProblemasgermanAún no hay calificaciones
- C4 1P Deriv FTrigonmDocumento15 páginasC4 1P Deriv FTrigonmAmelia HerreraAún no hay calificaciones
- Semana 7Documento12 páginasSemana 7gustavoquinterosubsAún no hay calificaciones
- P3 - MeNu - 2017 - II Profesor Edwin Chavez UNMSM (METODOS NUMERICOS)Documento3 páginasP3 - MeNu - 2017 - II Profesor Edwin Chavez UNMSM (METODOS NUMERICOS)Javier SuarezAún no hay calificaciones
- Examen de Unidad 2 y 3 de Programacion No LinealDocumento2 páginasExamen de Unidad 2 y 3 de Programacion No Linealedwar nachoAún no hay calificaciones
- Ex 2Documento1 páginaEx 2babayaguitaa03Aún no hay calificaciones
- Aislamiento de RaicesDocumento41 páginasAislamiento de RaicesbraulioAún no hay calificaciones
- ESPAÑOL 201-345 DocumentoDocumento145 páginasESPAÑOL 201-345 Documentoana rocioAún no hay calificaciones
- Gu A No Lineal M. Goic PDFDocumento15 páginasGu A No Lineal M. Goic PDFEdu Gumer Caceres HuamanAún no hay calificaciones
- Taller 4Documento5 páginasTaller 4NickoAún no hay calificaciones
- PNLDocumento66 páginasPNLingplcAún no hay calificaciones
- Calculo II 2008-2 Solemne 2 Pauta PDFDocumento3 páginasCalculo II 2008-2 Solemne 2 Pauta PDFeaherreramAún no hay calificaciones
- Bloque3 FuncionesUnaVariableDocumento22 páginasBloque3 FuncionesUnaVariableCristian GilAún no hay calificaciones
- Examen de ingreso a la Maestría en MatemáticasDocumento42 páginasExamen de ingreso a la Maestría en MatemáticasManuel2759Aún no hay calificaciones
- Extraordinario 2018 19Documento3 páginasExtraordinario 2018 19SofiAún no hay calificaciones
- Practica de Computo CientificoDocumento5 páginasPractica de Computo CientificoYadhyra Itzel EstradaAún no hay calificaciones
- 143 2013-10-07 El Cálculo FraccionarioDocumento20 páginas143 2013-10-07 El Cálculo FraccionarioLotfi ZadehAún no hay calificaciones
- Examen2 Cálculo (2009)Documento6 páginasExamen2 Cálculo (2009)cris cayAún no hay calificaciones
- CalDiferencialDocumento15 páginasCalDiferencialKaren ArocaAún no hay calificaciones
- Cuadernillo Matemáticas-13-15Documento3 páginasCuadernillo Matemáticas-13-15Forkan XAún no hay calificaciones
- Guía Fourier Mat024 UTFSMDocumento6 páginasGuía Fourier Mat024 UTFSMCristhian UrraAún no hay calificaciones
- AyudantaEDO2 PDFDocumento3 páginasAyudantaEDO2 PDFHernán González AguirreAún no hay calificaciones
- Taller Segundo Parcial Calculo Integral UdeADocumento6 páginasTaller Segundo Parcial Calculo Integral UdeAVanessa SanteroAún no hay calificaciones
- Apuntes Profesor Juan Ignacio PadillaDocumento144 páginasApuntes Profesor Juan Ignacio PadillaLuisAún no hay calificaciones
- LimiteDocumento18 páginasLimiteEliana PareraAún no hay calificaciones
- Lista de ejercicios de cálculo integral con 9 problemasDocumento1 páginaLista de ejercicios de cálculo integral con 9 problemasAldair AlejandroAún no hay calificaciones
- Métodos iterativosDocumento45 páginasMétodos iterativosAntmel Rodriguez CabralAún no hay calificaciones
- Aproximación de La Binomial Por La NormalDocumento5 páginasAproximación de La Binomial Por La Normalapi-3697274100% (1)
- Finaldemetodos2020 2Documento2 páginasFinaldemetodos2020 2Arturo ArmandoAún no hay calificaciones
- NL 2.-Flujos en La LíneaDocumento6 páginasNL 2.-Flujos en La LíneaMatheus Felipe ValleAún no hay calificaciones
- Revision Analisis Matematico 2Documento15 páginasRevision Analisis Matematico 2migAún no hay calificaciones
- Calculo I - Límite - 2022Documento15 páginasCalculo I - Límite - 2022Guillermo maitaAún no hay calificaciones
- PRESENTACIÓNDocumento46 páginasPRESENTACIÓNCristhian Lenin Mata CabanaAún no hay calificaciones
- Series de FourierDocumento41 páginasSeries de FourierOlenka LlatasAún no hay calificaciones
- Hoja 4 - 1Documento2 páginasHoja 4 - 1alterlaboroAún no hay calificaciones
- Semana 6 - INTEGRACIÓN NUMÉRICADocumento24 páginasSemana 6 - INTEGRACIÓN NUMÉRICAJuan armAún no hay calificaciones
- Leccion 3 Par 22 - Solucion y Rubrica-1Documento4 páginasLeccion 3 Par 22 - Solucion y Rubrica-1Miguel Lopez (nigel26)Aún no hay calificaciones
- SolucinI2MAT1620 2do2021Documento6 páginasSolucinI2MAT1620 2do2021Nicolás Soto CarrascoAún no hay calificaciones
- Certamen3 2014 2Documento5 páginasCertamen3 2014 2Salomon SotoAún no hay calificaciones
- Extraordinario 2016 17Documento3 páginasExtraordinario 2016 17SofiAún no hay calificaciones
- AM Tema 4Documento95 páginasAM Tema 4Simon ll4Aún no hay calificaciones
- Clase 1Documento13 páginasClase 1felipeAún no hay calificaciones
- Examen Matemáticas I Ingeniería MecánicaDocumento1 páginaExamen Matemáticas I Ingeniería MecánicacarmenAún no hay calificaciones
- Reglas de DerivaciónDocumento10 páginasReglas de DerivaciónnmorsilloAún no hay calificaciones
- Opti CpreliminaresDocumento64 páginasOpti CpreliminaresRafael CentenoAún no hay calificaciones
- Sistemas IDocumento14 páginasSistemas IRafael CentenoAún no hay calificaciones
- Cibernetica Vs IADocumento5 páginasCibernetica Vs IARafael CentenoAún no hay calificaciones
- Sistemas I - MetodologíasDocumento12 páginasSistemas I - MetodologíasRafael CentenoAún no hay calificaciones
- 10 Propuestas Prácticas y Sencillas para Optimizar Un Proceso de Picking en Un AlmacénDocumento1 página10 Propuestas Prácticas y Sencillas para Optimizar Un Proceso de Picking en Un AlmacénRafael CentenoAún no hay calificaciones
- CasoDocumento6 páginasCasothaliacsoto21Aún no hay calificaciones
- Estimaciones de Software PDFDocumento61 páginasEstimaciones de Software PDFArcangelxp21Aún no hay calificaciones
- SlottingDocumento12 páginasSlottingRafael CentenoAún no hay calificaciones
- Redes NeuronalesDocumento14 páginasRedes NeuronalesRafael CentenoAún no hay calificaciones
- TFM J.C. Martos - Sabes Gestionar Tu Economía. Educación Financiera para Adolescentes.Documento57 páginasTFM J.C. Martos - Sabes Gestionar Tu Economía. Educación Financiera para Adolescentes.Arturo Rodriguez RodriguezAún no hay calificaciones
- Mesas de San Pedro y comunidades de Los MedinasDocumento1 páginaMesas de San Pedro y comunidades de Los MedinasRafael CentenoAún no hay calificaciones
- Primer Corte 20%Documento2 páginasPrimer Corte 20%Rafael CentenoAún no hay calificaciones
- Capitulo Ii PDFDocumento93 páginasCapitulo Ii PDFmajodatoAún no hay calificaciones
- Electronica DigitalDocumento7 páginasElectronica DigitalRafael CentenoAún no hay calificaciones
- Ensayo Rafael Centeno UIDocumento5 páginasEnsayo Rafael Centeno UIRafael CentenoAún no hay calificaciones
- Formato Del EnsayoDocumento2 páginasFormato Del EnsayoRafael CentenoAún no hay calificaciones
- Guasdualito 1x1Documento1 páginaGuasdualito 1x1Rafael CentenoAún no hay calificaciones
- Guasdualito 4 X 3Documento12 páginasGuasdualito 4 X 3Rafael CentenoAún no hay calificaciones
- Circuitos Eléctricos I: Análisis y diseño de circuitos CCDocumento11 páginasCircuitos Eléctricos I: Análisis y diseño de circuitos CCRafael CentenoAún no hay calificaciones
- Presentación 1Documento11 páginasPresentación 1Rafael CentenoAún no hay calificaciones
- Circuitos Eléctricos I: Análisis y diseño de circuitos CCDocumento11 páginasCircuitos Eléctricos I: Análisis y diseño de circuitos CCRafael CentenoAún no hay calificaciones
- Mesas de San Pedro y comunidades del sector 10 de Plan de San PedroDocumento4 páginasMesas de San Pedro y comunidades del sector 10 de Plan de San PedroRafael CentenoAún no hay calificaciones
- Circuitos Eléctricos I: Análisis y diseño de circuitos CCDocumento11 páginasCircuitos Eléctricos I: Análisis y diseño de circuitos CCRafael CentenoAún no hay calificaciones
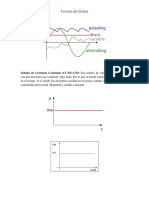
- Formas de OndasDocumento5 páginasFormas de OndasRafael CentenoAún no hay calificaciones
- Flujo de ComunicaciónDocumento2 páginasFlujo de ComunicaciónRafael CentenoAún no hay calificaciones
- Evaluación Teórica - Primer - Corte - GrafosDocumento4 páginasEvaluación Teórica - Primer - Corte - GrafosRafael CentenoAún no hay calificaciones
- Sistemas Eléctricos Gerson Rangel (Ensayo)Documento10 páginasSistemas Eléctricos Gerson Rangel (Ensayo)Rafael CentenoAún no hay calificaciones
- Resumen de Laudato Sí Capitulo 3Documento2 páginasResumen de Laudato Sí Capitulo 3Bruno Nuñez A50% (2)
- Matriz DofaDocumento2 páginasMatriz DofaEpikratosAún no hay calificaciones
- Qué es la identidad humana? Guía completaDocumento5 páginasQué es la identidad humana? Guía completaCINTHIA SUCETH HURTADO JACINTOAún no hay calificaciones
- Fórmula integral de CauchyDocumento29 páginasFórmula integral de CauchyEduardo AriasAún no hay calificaciones
- Tipos de PLCDocumento7 páginasTipos de PLCMike Angel CortesAún no hay calificaciones
- Fuente Regulada 12vDocumento6 páginasFuente Regulada 12vjlAún no hay calificaciones
- La Ley de Educacion Ambiental Integral y La Formacion Docente en GeografiaDocumento14 páginasLa Ley de Educacion Ambiental Integral y La Formacion Docente en GeografiaMelisa EstrellaAún no hay calificaciones
- Insuficiencia Activa y Pasiva Que He Aprendido by Javier CASADO Medium PDFDocumento1 páginaInsuficiencia Activa y Pasiva Que He Aprendido by Javier CASADO Medium PDFGigi VonAún no hay calificaciones
- Derecho Privado I - Unidad 1Documento24 páginasDerecho Privado I - Unidad 1Gisela AlvarezAún no hay calificaciones
- LibroDocumento2 páginasLibroJavier MoralesAún no hay calificaciones
- Diagnostico-Situacional Departamento - CundinamarcaDocumento345 páginasDiagnostico-Situacional Departamento - Cundinamarcatunja1Aún no hay calificaciones
- Volumen III Descripcion Estructura, Secciones I, II y IIIDocumento27 páginasVolumen III Descripcion Estructura, Secciones I, II y IIIDiego AguilarAún no hay calificaciones
- 2020 01 24 Es LH300Documento128 páginas2020 01 24 Es LH300Domingo ProcopioAún no hay calificaciones
- Plan de Area Fisica 2021 (Virtualidad)Documento18 páginasPlan de Area Fisica 2021 (Virtualidad)Yulian RzrzAún no hay calificaciones
- Guia Inter # 4 Grado 11Documento49 páginasGuia Inter # 4 Grado 11Carolina MercadoAún no hay calificaciones
- Cerámicas conductoras y superconductorasDocumento2 páginasCerámicas conductoras y superconductorasyasmin jumboAún no hay calificaciones
- Cv. BuendiaDocumento3 páginasCv. BuendiaMiguel Buendia QuilicheAún no hay calificaciones
- Propuesta saludableDocumento9 páginasPropuesta saludableDAYANAAún no hay calificaciones
- EXAMEN T1 8vo 2023Documento4 páginasEXAMEN T1 8vo 2023Leydy RodrÍguez MAún no hay calificaciones
- Desarrollo de La Práctica Reflexiva en El Oficio de Enseñar (Philippe Perrenoud)Documento2 páginasDesarrollo de La Práctica Reflexiva en El Oficio de Enseñar (Philippe Perrenoud)estrategiasdeltrabajAún no hay calificaciones
- Fobia Específica: Fobia A Los Ascensores: Esta Fobia Se Caracteriza PorDocumento3 páginasFobia Específica: Fobia A Los Ascensores: Esta Fobia Se Caracteriza PorGabriela RiveraAún no hay calificaciones
- LEY DE FOMENTO AL COMERCIO EXTERIOR DE SERVICIOS: Ley #29646Documento12 páginasLEY DE FOMENTO AL COMERCIO EXTERIOR DE SERVICIOS: Ley #29646Dimas Soria MonsinAún no hay calificaciones
- Tarea 8Documento3 páginasTarea 8samantha rosaAún no hay calificaciones
- Listado de personal SEGENDocumento35 páginasListado de personal SEGENfreddy lopezAún no hay calificaciones
- La enfermedad de Chagas y la lectoescrituraDocumento116 páginasLa enfermedad de Chagas y la lectoescrituraSaúl Oña MedranoAún no hay calificaciones
- Mamposteria y Fontaneria PDFDocumento8 páginasMamposteria y Fontaneria PDFangel omar peraltaAún no hay calificaciones