También podría gustarte
- Aplicaciones - Microarrays1Documento0 páginasAplicaciones - Microarrays1Victor Vasquez MatsudaAún no hay calificaciones
- Paper ClasificacionAvesDocumento7 páginasPaper ClasificacionAvesArnold P. AchanccarayAún no hay calificaciones
- Protocolos y Métodos de Aprendizaje Automático - Experimentos de Springer NatureDocumento24 páginasProtocolos y Métodos de Aprendizaje Automático - Experimentos de Springer NatureDontyr GarciaAún no hay calificaciones
- Microarrays PDFDocumento56 páginasMicroarrays PDFYanira Sermin100% (1)
- MG RastDocumento13 páginasMG RastRobert Caballero BardalesAún no hay calificaciones
- BioinformaticaDocumento24 páginasBioinformaticaFelicita DureAún no hay calificaciones
- Transcriptómica (mARN y Mir)Documento5 páginasTranscriptómica (mARN y Mir)QWERTYAún no hay calificaciones
- Aplicación de La Secuenciación Masiva y La BioinformáticaDocumento13 páginasAplicación de La Secuenciación Masiva y La BioinformáticaAlice Cortez GavilanesAún no hay calificaciones
- A Qué Se Denominan Técnicas de Biología MolecularDocumento4 páginasA Qué Se Denominan Técnicas de Biología Molecularmarmergoz81Aún no hay calificaciones
- Aplicación de La Secuenciación Masiva y La BioinformáticaDocumento13 páginasAplicación de La Secuenciación Masiva y La BioinformáticaAlice Cortez GavilanesAún no hay calificaciones
- TFM Carlos QuijanoSanMartínDocumento62 páginasTFM Carlos QuijanoSanMartínCarlos CsmAún no hay calificaciones
- LAplicación de La Secuenciación Masiva y Labioinformática Al Diagnóstico MicrobiológicoDocumento12 páginasLAplicación de La Secuenciación Masiva y Labioinformática Al Diagnóstico MicrobiológicoKirianova GodoyAún no hay calificaciones
- Tecnología NANOPOREDocumento8 páginasTecnología NANOPOREGIANCARLOS ISAAC PADILLA FALCONIAún no hay calificaciones
- Aproximaciones Ómicas Al Estudio de Los Sistemas BiológicosDocumento4 páginasAproximaciones Ómicas Al Estudio de Los Sistemas BiológicosTamiSandobalAún no hay calificaciones
- Reporte 6Documento9 páginasReporte 6Oscar Jesus Aguilar VenturaAún no hay calificaciones
- Informe Exposición Grupo N2 BioinformáticaDocumento4 páginasInforme Exposición Grupo N2 BioinformáticaNADIA NICOLE CELI BOHORQUEZAún no hay calificaciones
- PIA1 Biotecnologia Informática 171Documento26 páginasPIA1 Biotecnologia Informática 171Cristoper Ariel López VenegasAún no hay calificaciones
- Tarea - Sem 3-1Documento11 páginasTarea - Sem 3-1PaulAún no hay calificaciones
- Unidad 1 BIOINFORMATICADocumento67 páginasUnidad 1 BIOINFORMATICAAscencio Alvarez Daniela AlejandraAún no hay calificaciones
- Manipulación GenéticaDocumento6 páginasManipulación GenéticaMagaly Castillo OrtizAún no hay calificaciones
- Informe 7 BioinformáticaDocumento17 páginasInforme 7 BioinformáticaCatalina Merino Yunnissi0% (2)
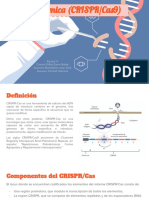
- CRISPRCas 9Documento17 páginasCRISPRCas 9omar barreraAún no hay calificaciones
- 2002-Microarrays y Biochips de Adn-Document 130273164878Documento56 páginas2002-Microarrays y Biochips de Adn-Document 130273164878RagnarAún no hay calificaciones
- Año Lectivo: 2023: Universidad Nacional de Río Cuarto Facultad de Ciencias Exactas, Físico-Químicas y Naturales 2023Documento8 páginasAño Lectivo: 2023: Universidad Nacional de Río Cuarto Facultad de Ciencias Exactas, Físico-Químicas y Naturales 2023Nicole BenedictoAún no hay calificaciones
- Informe 13 - BioinfomaticaDocumento9 páginasInforme 13 - Bioinfomaticajavier ramosAún no hay calificaciones
- Ngs Introduccion PDFDocumento8 páginasNgs Introduccion PDFAndres BenavidesAún no hay calificaciones
- Informe de Actividades de Practicas Profecionales Del Grupo de Investigacion en Evolucion y Sistematica MolecularDocumento9 páginasInforme de Actividades de Practicas Profecionales Del Grupo de Investigacion en Evolucion y Sistematica MolecularEdgardo Galofre Diaz-GranadosAún no hay calificaciones
- Micro Arreglo SDocumento28 páginasMicro Arreglo SSteve Vladimir Acedo LazoAún no hay calificaciones
- Métodos Rápidos J.E. MartinezDocumento3 páginasMétodos Rápidos J.E. MartinezJorgeAún no hay calificaciones
- Empleo Real Time PCRDocumento2 páginasEmpleo Real Time PCRMARIA LISSETH BRAVO MEZAAún no hay calificaciones
- Actividad 2. Análisis Comparativo de Los Métodos de SecuenciaciónDocumento4 páginasActividad 2. Análisis Comparativo de Los Métodos de SecuenciaciónJonathan Yair Hernández BecerrilAún no hay calificaciones
- Cuestionario P12Documento2 páginasCuestionario P12Diana RamosAún no hay calificaciones
- Clase - 11 - Reaccion de La Cadena de Polimerasa y Secuenciacion PDFDocumento23 páginasClase - 11 - Reaccion de La Cadena de Polimerasa y Secuenciacion PDFFernando YumbayAún no hay calificaciones
- MicroarreglosDocumento14 páginasMicroarreglositscoralfuentes97Aún no hay calificaciones
- PCR en Tiempo RealDocumento20 páginasPCR en Tiempo RealAndrea Colana100% (1)
- Mantenimiento 4.0 Implementación de Un Modelo de Mantenimiento Prescriptivo BrújulaDocumento39 páginasMantenimiento 4.0 Implementación de Un Modelo de Mantenimiento Prescriptivo BrújulaFran jimenezAún no hay calificaciones
- Microarrays - Grupo 2Documento26 páginasMicroarrays - Grupo 2HAROL ANDRÉS BEDOYA CHAPARRO100% (1)
- Detección de Malware Con Modelo de Lenguaje y Su Clasificación Mediante SVMDocumento9 páginasDetección de Malware Con Modelo de Lenguaje y Su Clasificación Mediante SVMAlex ValenciaAún no hay calificaciones
- Vector pSIM24 KanRDocumento3 páginasVector pSIM24 KanRJavier Andres Matamala MoyanoAún no hay calificaciones
- Secuenciador ADNDocumento4 páginasSecuenciador ADNDanielQCAún no hay calificaciones
- TrabajoDocumento26 páginasTrabajoJennifer PalmaAún no hay calificaciones
- Informe #01 Biotecnologia Maria Cutire VargasDocumento23 páginasInforme #01 Biotecnologia Maria Cutire Vargasmaria cutireAún no hay calificaciones
- Bio ChipsDocumento8 páginasBio ChipsJipson UrestoAún no hay calificaciones
- MicroarreglosDocumento31 páginasMicroarreglosCinthya Leon100% (1)
- Palazuelos Navarro - Silva Sánchez - Reporte2 U4Documento18 páginasPalazuelos Navarro - Silva Sánchez - Reporte2 U4Oscar Ramon Palazuelos NavarroAún no hay calificaciones
- P5. Diseño de PrimersDocumento6 páginasP5. Diseño de PrimersMarjorie Lizbeth P.Aún no hay calificaciones
- Genoma 02Documento17 páginasGenoma 02Milena VargasAún no hay calificaciones
- PCR in Real TimeDocumento14 páginasPCR in Real TimeEdwin Jose CeballosAún no hay calificaciones
- EdisonBorda 201529A 614 Bioinformática1Documento14 páginasEdisonBorda 201529A 614 Bioinformática1GOYITAAún no hay calificaciones
- Técnicas Moleculares para Enfermedades RespiratoriasDocumento22 páginasTécnicas Moleculares para Enfermedades RespiratoriasJennifer PalmaAún no hay calificaciones
- Taller PCRDocumento6 páginasTaller PCRLia VelásquezAún no hay calificaciones
- Real Time Quantitative PCR A Tool For Absolute and Relative - En.esDocumento13 páginasReal Time Quantitative PCR A Tool For Absolute and Relative - En.esMEYLING LIZANDRA VILCAPOMA DIAZAún no hay calificaciones
- Barrero MicroarraysDocumento10 páginasBarrero MicroarraysMiriam AcostaAún no hay calificaciones
- Qué Es Un MicrDocumento5 páginasQué Es Un Micrjose manuel peñaAún no hay calificaciones
- TranscriptomicaDocumento13 páginasTranscriptomicaPaolaAún no hay calificaciones
- Actividad No 4 - Investigación Métodos de Minería de DatosDocumento10 páginasActividad No 4 - Investigación Métodos de Minería de DatosKnowledge AttacksAún no hay calificaciones
- Brochure ML QUIMICA ExtDocumento8 páginasBrochure ML QUIMICA ExtKEVIN ENDER TAYPE HUANCAAún no hay calificaciones
- Auditoría de seguridad informática. IFCT0109De EverandAuditoría de seguridad informática. IFCT0109Calificación: 5 de 5 estrellas5/5 (1)
- Ajuste a La Calificación Del Riesgo De Mercado De Las Emisoras Más Activas Que Cotizan En La Bolsa Mexicana De Valores, Con La Implementación De Una Red Neuronal Artificial Clasificadora: Adjustment to the Market Risk Rating of the Most Active Issuers Listed on the Mexican Stock Exchange with the Implementation of an Artificial Neural Network ClassifierDe EverandAjuste a La Calificación Del Riesgo De Mercado De Las Emisoras Más Activas Que Cotizan En La Bolsa Mexicana De Valores, Con La Implementación De Una Red Neuronal Artificial Clasificadora: Adjustment to the Market Risk Rating of the Most Active Issuers Listed on the Mexican Stock Exchange with the Implementation of an Artificial Neural Network ClassifierAún no hay calificaciones
- Seguridad en equipos informáticos. IFCT0109De EverandSeguridad en equipos informáticos. IFCT0109Aún no hay calificaciones
- Juan Esteban Mera VillegasDocumento1 páginaJuan Esteban Mera Villegasbairon mera100% (1)
- Curso Avanzado de Trading LODFXDocumento3 páginasCurso Avanzado de Trading LODFXjoel50% (2)
- Solicito Carta de Presentación Practicas 1Documento2 páginasSolicito Carta de Presentación Practicas 1MichelAún no hay calificaciones
- DominicanaDocumento169 páginasDominicanaChepeluis LanzaAún no hay calificaciones
- Contactos Mujeres Usera Particular en MadridDocumento2 páginasContactos Mujeres Usera Particular en MadridConocer mujeres en MadridAún no hay calificaciones
- Carrera Diplomatica y ConsularDocumento2 páginasCarrera Diplomatica y ConsularJuan Pablo Rincon SayasAún no hay calificaciones
- Presentacion Final Ernesto BarredaDocumento38 páginasPresentacion Final Ernesto BarredaPlutarco Chuquihuanga CórdovaAún no hay calificaciones
- Tipos de Constantes en CDocumento8 páginasTipos de Constantes en CAlejandro AlcocerAún no hay calificaciones
- FyEP U1 AA1 Mercado Uveg OkDocumento6 páginasFyEP U1 AA1 Mercado Uveg OkKarla CargutieAún no hay calificaciones
- Tasas de Interes Banco Central Del EcuadorDocumento3 páginasTasas de Interes Banco Central Del EcuadorRichard RodriguezAún no hay calificaciones
- Solicito Se Me Consigne en Mo Boleta de Pago El Concepto Del QuinquenioDocumento1 páginaSolicito Se Me Consigne en Mo Boleta de Pago El Concepto Del QuinquenioErwin EduardoAún no hay calificaciones
- COBERTURA ACTUALIZADA 23 DE Marzo (4) .OdsDocumento12.067 páginasCOBERTURA ACTUALIZADA 23 DE Marzo (4) .OdsTomás David Bermúdez MéndezAún no hay calificaciones
- Codigo Conducta SEPDocumento2 páginasCodigo Conducta SEPVictor Alfonso BarreraAún no hay calificaciones
- S02.s2 - Arbol de DecisionDocumento19 páginasS02.s2 - Arbol de DecisionFlor Arévalo JuárezAún no hay calificaciones
- Práctica 02 - Método de Bisección PDFDocumento3 páginasPráctica 02 - Método de Bisección PDFAnonymous W1mMU5ZAún no hay calificaciones
- Practica 1Documento5 páginasPractica 1Jean Pool Bj Yajo AlarcónAún no hay calificaciones
- Estado de Situacion FinancieraDocumento11 páginasEstado de Situacion FinancieraRené Pérez100% (6)
- Laboratorio #6 - Polarizacion Del Transistor BJTDocumento8 páginasLaboratorio #6 - Polarizacion Del Transistor BJTDAVID NICOLAS MURILLO NOVAAún no hay calificaciones
- Acto Modelo Notificacion de AudienciaDocumento1 páginaActo Modelo Notificacion de AudienciaPedro Cruz100% (5)
- SH Lab 5 PDFDocumento8 páginasSH Lab 5 PDFA̶l̶d̶a̶i̶r̶ C̶a̶s̶a̶f̶r̶a̶n̶c̶a̶Aún no hay calificaciones
- Coca Cola R.S - GrupalDocumento15 páginasCoca Cola R.S - GrupalHenry HCAún no hay calificaciones
- Taller Teoría ConsumidorDocumento3 páginasTaller Teoría ConsumidorDavid CasasAún no hay calificaciones
- Mapa Conceptual de Emprendimiento 10Documento1 páginaMapa Conceptual de Emprendimiento 10Christian RomeroAún no hay calificaciones
- Tarea Tema 2Documento97 páginasTarea Tema 2LukeAún no hay calificaciones
- Icia-Pmtd-Picb1 2021Documento62 páginasIcia-Pmtd-Picb1 2021Francisco Tapia0% (1)
- Instrucciones Modulos HochikiDocumento27 páginasInstrucciones Modulos Hochikizdiego84Aún no hay calificaciones
- 12 VESDA Display Modules TDS A4 Spanish LoresDocumento2 páginas12 VESDA Display Modules TDS A4 Spanish LoresMRO_999Aún no hay calificaciones
- Trabajo TIA 2 - Karla Palacio, Diana Castañeda, Isabel Sanchez PDFDocumento5 páginasTrabajo TIA 2 - Karla Palacio, Diana Castañeda, Isabel Sanchez PDFIvanna PalacioAún no hay calificaciones
- Wuolah-Free-Tema 6 (I) - La Oferta AgregadaDocumento9 páginasWuolah-Free-Tema 6 (I) - La Oferta Agregadatoneterh dauderAún no hay calificaciones
- Informe de Reloj DigitalDocumento22 páginasInforme de Reloj DigitalWilliams Molina EspirituAún no hay calificaciones