También podría gustarte
- Dios Usa Lápiz Labial (Karen Berg)Documento223 páginasDios Usa Lápiz Labial (Karen Berg)Analia Nawrath100% (3)
- Guia de Ahumados Smoke KingDocumento118 páginasGuia de Ahumados Smoke KingPamela OsoAún no hay calificaciones
- Ejercicio 1 de Metodos NumericosDocumento10 páginasEjercicio 1 de Metodos NumericosEdwin Sanchez50% (2)
- Monografia MotoresDocumento22 páginasMonografia MotoresYitshak Vargas Yovera100% (3)
- Ejercicios Propuestos Suelos IIDocumento15 páginasEjercicios Propuestos Suelos IIPier Diego H CamAún no hay calificaciones
- Sesión de Multiploicación y División de FraccionesDocumento8 páginasSesión de Multiploicación y División de FraccionesClau MontalbanAún no hay calificaciones
- Propuesta de Investigación de MercadosDocumento1 páginaPropuesta de Investigación de MercadosMauricio OrozcoAún no hay calificaciones
- Tema 3Documento16 páginasTema 3Isaias Jaaziel MartinezAún no hay calificaciones
- Metodos EstadisticosDocumento4 páginasMetodos EstadisticosAlex SabogalAún no hay calificaciones
- CINEMATICADocumento5 páginasCINEMATICAQuispe Martinez Alberth EnriqueAún no hay calificaciones
- 2.4.1 Ejemplo Prueba KSDocumento2 páginas2.4.1 Ejemplo Prueba KSKevin GutierrezAún no hay calificaciones
- Ejercicios SimulacionDocumento3 páginasEjercicios SimulacionPedro Cabana Bautista67% (3)
- Regresion Lineal 1Documento22 páginasRegresion Lineal 1Maryory Urdaneta HerreraAún no hay calificaciones
- EjerciciosDocumento6 páginasEjerciciosyesica riveraAún no hay calificaciones
- Caida Libre CalculosDocumento3 páginasCaida Libre CalculosmarcoAún no hay calificaciones
- Quiroz Paez Melissa - Tarea InterpolacionDocumento6 páginasQuiroz Paez Melissa - Tarea InterpolacionDavid PortillaAún no hay calificaciones
- Lab. 3 Descarga Por OrificiosDocumento3 páginasLab. 3 Descarga Por OrificiosAlvaroAntezanaAún no hay calificaciones
- $RNR4KDHDocumento8 páginas$RNR4KDHFrankAún no hay calificaciones
- Medidas Dispersión EJERCICIOS RESUELTOSDocumento14 páginasMedidas Dispersión EJERCICIOS RESUELTOSRebeca Lizeth SHAún no hay calificaciones
- Tarea3 208046A 953 Camilo HuertasDocumento13 páginasTarea3 208046A 953 Camilo HuertasCamiloAún no hay calificaciones
- 9.69 9.71Documento2 páginas9.69 9.71LUIS DAVID ZU�IGA SOLISAún no hay calificaciones
- Actividad 1 TEMA 2 Regresión Lineal Multiple - Ejercicio - 2 para Resolver en ClaseDocumento4 páginasActividad 1 TEMA 2 Regresión Lineal Multiple - Ejercicio - 2 para Resolver en Claserogelio nuevo alvaradoAún no hay calificaciones
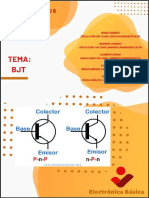
- Lab6 - Caracteristica Del BJTDocumento8 páginasLab6 - Caracteristica Del BJTJosue LaraAún no hay calificaciones
- Regresion Lineal MultipleDocumento6 páginasRegresion Lineal MultipleEDITH GONZALEZ FLORESAún no hay calificaciones
- Informe Nombre Del Trabajo InterpolacionDocumento6 páginasInforme Nombre Del Trabajo InterpolacionDavid PortillaAún no hay calificaciones
- Estadistica UnadDocumento10 páginasEstadistica UnadJeisson MedinaAún no hay calificaciones
- Interpolacion de NewtonDocumento4 páginasInterpolacion de NewtonEdson Arturo Quispe SánchezAún no hay calificaciones
- Correlacion, Altura Vs PesoDocumento2 páginasCorrelacion, Altura Vs PesoCesar SantanaAún no hay calificaciones
- Ejercicio Calculo de Poblacion FuturaDocumento7 páginasEjercicio Calculo de Poblacion Futurachilligua consorcioAún no hay calificaciones
- Practica de OndasDocumento7 páginasPractica de OndasJhovanna PaxiAún no hay calificaciones
- Unidad 9 - FormulasDocumento4 páginasUnidad 9 - Formulashellen cossioAún no hay calificaciones
- Parcial 1 Metodos NumericosDocumento7 páginasParcial 1 Metodos NumericosBryan Julian Ariza FoncecaAún no hay calificaciones
- Taller EstadisticaDocumento8 páginasTaller EstadisticaRafael QuirogaAún no hay calificaciones
- TAREASEMANA4Documento8 páginasTAREASEMANA4Branco Tiznado RodriguezAún no hay calificaciones
- Determinacion de La Permeabilidad Magnetica Del AireDocumento2 páginasDeterminacion de La Permeabilidad Magnetica Del AireCesar GonzalezAún no hay calificaciones
- Expo FisicaDocumento3 páginasExpo FisicaNoelia RojasAún no hay calificaciones
- Pronósticos RegresiónDocumento11 páginasPronósticos RegresiónMichael YoryAún no hay calificaciones
- Ejercicio de LevasDocumento4 páginasEjercicio de LevasLuis SantistebanAún no hay calificaciones
- Tablas Amortizacion ConstanteDocumento3 páginasTablas Amortizacion ConstanteHeidi Diana Asencios CcellccasccaAún no hay calificaciones
- Deber 06 MazonADocumento19 páginasDeber 06 MazonAAnonymous Lc8qmdeY1gAún no hay calificaciones
- Informe 2Documento5 páginasInforme 2Valeria Chura EstraverAún no hay calificaciones
- Ejercicios de Crecimiento Poblacional Exponencial, Interés Compuesto e Interés Compuesto ContinuamenteDocumento19 páginasEjercicios de Crecimiento Poblacional Exponencial, Interés Compuesto e Interés Compuesto Continuamentepaulna aguileraAún no hay calificaciones
- Tarea 2-2-CACERES PDFDocumento5 páginasTarea 2-2-CACERES PDFSara CáceresAún no hay calificaciones
- Estadistica UnadDocumento9 páginasEstadistica UnadJeisson MedinaAún no hay calificaciones
- Taller 2Documento7 páginasTaller 2Davyt TorresAún no hay calificaciones
- Informe 5Documento9 páginasInforme 5Wilian LopezrochaAún no hay calificaciones
- Vibracion Forzada Amortiguada-Alonso Apaza H.Documento1 páginaVibracion Forzada Amortiguada-Alonso Apaza H.alonsoAún no hay calificaciones
- Bloque II Ej 4Documento5 páginasBloque II Ej 4Alejandra FernándezAún no hay calificaciones
- InterpolacionDocumento7 páginasInterpolaciondelbhergarciamedinaAún no hay calificaciones
- Tabla de Frecuencia Num. de Lista 13Documento10 páginasTabla de Frecuencia Num. de Lista 13Victor Manuel Montiel RodriguezAún no hay calificaciones
- Grados ESPOLDocumento13 páginasGrados ESPOLkevin isaiasAún no hay calificaciones
- Análisis I.4Documento4 páginasAnálisis I.4natalia orozcoAún no hay calificaciones
- Ing. Carretera T4 - Resendiz - Zepeda.AlanJairDocumento4 páginasIng. Carretera T4 - Resendiz - Zepeda.AlanJairAlan ResendizAún no hay calificaciones
- Dispositivos ElectrónicosDocumento4 páginasDispositivos Electrónicosalex ackermanAún no hay calificaciones
- MN PérezVillacorte Carol P1 P1Documento10 páginasMN PérezVillacorte Carol P1 P1Isa OlmedoAún no hay calificaciones
- Parcial 3er CorteDocumento6 páginasParcial 3er CortepAOLA MORALESAún no hay calificaciones
- LABORATORIO. LEY DE OHM - RemovedDocumento7 páginasLABORATORIO. LEY DE OHM - RemovedJoelly Solis RamirezAún no hay calificaciones
- Taller VA (1) 12domingoDocumento14 páginasTaller VA (1) 12domingoMaria Elena Arana GutierrezAún no hay calificaciones
- Sullon Li Jaime Franksue - Examen Final EstabilidadDocumento10 páginasSullon Li Jaime Franksue - Examen Final EstabilidadfranksueAún no hay calificaciones
- Matriz de Transición de Proceso EstocásticoDocumento3 páginasMatriz de Transición de Proceso EstocásticoCarlos Sevilla100% (1)
- Deber 2Documento9 páginasDeber 2Alejandro CañarAún no hay calificaciones
- Pruebas Estadísticas 2da ParteDocumento42 páginasPruebas Estadísticas 2da ParteAlondra NavorAún no hay calificaciones
- Reforzamiento Integral-Trapezoidal-CuadraturaDocumento7 páginasReforzamiento Integral-Trapezoidal-CuadraturaCN Kenyu AlexAún no hay calificaciones
- Ejercicios 2Documento14 páginasEjercicios 2MATEO ALEJANDRO PERUGACHI PADILLAAún no hay calificaciones
- Oraciones Contra El AbortoDocumento4 páginasOraciones Contra El AbortoRicyAún no hay calificaciones
- 12 Inspiradoras Oraciones para Rezar Al Espíritu SantoDocumento7 páginas12 Inspiradoras Oraciones para Rezar Al Espíritu SantoRicyAún no hay calificaciones
- Indulgencia PlenariaDocumento22 páginasIndulgencia PlenariaRicyAún no hay calificaciones
- Oracion Evangelium Vitae Juan Pablo IIDocumento1 páginaOracion Evangelium Vitae Juan Pablo IIRicyAún no hay calificaciones
- Copia de Jeremias20BibliaJerusalenDocumento1 páginaCopia de Jeremias20BibliaJerusalenRicyAún no hay calificaciones
- Una Serie Sobre Dietrich BonhoefferDocumento26 páginasUna Serie Sobre Dietrich BonhoefferRicyAún no hay calificaciones
- Credo Del Pueblo de DiosDocumento7 páginasCredo Del Pueblo de DiosRicyAún no hay calificaciones
- 4-5 Aprendizaje ReforzadoDocumento11 páginas4-5 Aprendizaje ReforzadoRicyAún no hay calificaciones
- Así Es Como Dios Te ama-TeresaDeCalcutaDocumento6 páginasAsí Es Como Dios Te ama-TeresaDeCalcutaRicyAún no hay calificaciones
- CyberProof Smarter SOC WP Spanish 2107Documento17 páginasCyberProof Smarter SOC WP Spanish 2107RicyAún no hay calificaciones
- Zenda Chema AlonsoDocumento29 páginasZenda Chema AlonsoRicyAún no hay calificaciones
- 400 ComandosDocumento19 páginas400 ComandosRicyAún no hay calificaciones
- 10 Consejos para Un Diseño Web de ÉxitoDocumento1 página10 Consejos para Un Diseño Web de ÉxitoRicyAún no hay calificaciones
- 15 Programas para Mezclar MúsicaDocumento21 páginas15 Programas para Mezclar MúsicaRicyAún no hay calificaciones
- 4-3 Principal Component AnalysisDocumento17 páginas4-3 Principal Component AnalysisRicyAún no hay calificaciones
- 4-6 MDPDocumento13 páginas4-6 MDPRicyAún no hay calificaciones
- 4.2.6 Herramientas Que Se Pueden Usar para La Rendicion de CuentasDocumento6 páginas4.2.6 Herramientas Que Se Pueden Usar para La Rendicion de CuentasRicyAún no hay calificaciones
- Autoevaluacion Etica de IA para Actores Del Ecosistema Emprendedor Guia de AplicacionDocumento72 páginasAutoevaluacion Etica de IA para Actores Del Ecosistema Emprendedor Guia de AplicacionRicyAún no hay calificaciones
- Recomendaciones para Director de ProyectoDocumento2 páginasRecomendaciones para Director de ProyectoRicyAún no hay calificaciones
- 4.2.5 Ejemplos - de - Monitoreo - de - Sistemas - de - IA - Desde - GobiernoDocumento1 página4.2.5 Ejemplos - de - Monitoreo - de - Sistemas - de - IA - Desde - GobiernoRicyAún no hay calificaciones
- Lista de Verificación de IA Robusta y ResponsableDocumento6 páginasLista de Verificación de IA Robusta y ResponsableRicyAún no hay calificaciones
- Desensamblador Idapro y OdaDocumento3 páginasDesensamblador Idapro y OdaRicyAún no hay calificaciones
- Plantilla para Taller de FactibilidadDocumento26 páginasPlantilla para Taller de FactibilidadRicyAún no hay calificaciones
- Anexo1 Ficha de Diseño y FactibilidadDocumento11 páginasAnexo1 Ficha de Diseño y FactibilidadRicyAún no hay calificaciones
- Auditoria Algoritmica para Sistemas de Toma o Soporte de DecisionesDocumento27 páginasAuditoria Algoritmica para Sistemas de Toma o Soporte de DecisionesRicyAún no hay calificaciones
- Informe Técnico ForenseDocumento2 páginasInforme Técnico ForenseRicyAún no hay calificaciones
- Lista de Verificación para El Director Del ProyectoDocumento2 páginasLista de Verificación para El Director Del ProyectoRicyAún no hay calificaciones
- Práctica para Medicina Humana #01Documento2 páginasPráctica para Medicina Humana #01Ydelza CastroAún no hay calificaciones
- Pro II Ejemplos 2Documento98 páginasPro II Ejemplos 2Jose Miguel Lopez DelgadoAún no hay calificaciones
- Actividad Entregable 2 Matematica AplicadaaaaDocumento7 páginasActividad Entregable 2 Matematica AplicadaaaaRïčhäřđ BëřňäłAún no hay calificaciones
- 4.-ESPECIFICACIONES TECNICAS Pueblo LibreDocumento21 páginas4.-ESPECIFICACIONES TECNICAS Pueblo LibreEliot CarhuaAún no hay calificaciones
- Cuestionario OPE Parte 3Documento6 páginasCuestionario OPE Parte 3dianaitahAún no hay calificaciones
- Reparar Arranque 2Documento3 páginasReparar Arranque 2Gabo EnriqueAún no hay calificaciones
- U1-A2 Cálculo DiferencialDocumento4 páginasU1-A2 Cálculo DiferencialLizbeth Patiño BayonaAún no hay calificaciones
- 1 t2 Maquinas Termicas 18-19 PDFDocumento25 páginas1 t2 Maquinas Termicas 18-19 PDFRubén Barroso BlazqezAún no hay calificaciones
- Estudio Hidrologico Canal QuilishDocumento25 páginasEstudio Hidrologico Canal QuilishdanielAún no hay calificaciones
- Extracción de ColorantesDocumento10 páginasExtracción de Colorantesnorma0% (1)
- 4BV1 OptoacopladoresDocumento27 páginas4BV1 OptoacopladoresMartin Higuera PeñaAún no hay calificaciones
- Ecuaciones Incompletas de 2do GradoDocumento4 páginasEcuaciones Incompletas de 2do GradoRosa Amel ElfierroAún no hay calificaciones
- Simulacro Vias 1Documento16 páginasSimulacro Vias 1Jhonatan RamirezAún no hay calificaciones
- FIS120 Control1 PDFDocumento6 páginasFIS120 Control1 PDFGuillermo Córdova CastilloAún no hay calificaciones
- Primera Actividad (10%)Documento2 páginasPrimera Actividad (10%)AriannysmonAún no hay calificaciones
- Documents - Tips Problemas Capitulo 18 Wayne TomasiDocumento7 páginasDocuments - Tips Problemas Capitulo 18 Wayne TomasiFajardo AndreiAún no hay calificaciones
- Nia 530Documento10 páginasNia 530PABLO ROBERTO RUIZ MALDONADOAún no hay calificaciones
- Informe - Practica 1 - Capacidad Amortiguadora de Soluciones Buffer y Valoración Ácido Base de Un AminoácidoDocumento7 páginasInforme - Practica 1 - Capacidad Amortiguadora de Soluciones Buffer y Valoración Ácido Base de Un Aminoácidojeferort4912Aún no hay calificaciones
- Clase 05 Mirror, Attach, Scale, StretchDocumento8 páginasClase 05 Mirror, Attach, Scale, StretchMarlon Francisco Rincon ReyesAún no hay calificaciones
- Vocabulario GeográficoDocumento10 páginasVocabulario Geográficolucia castel RuzAún no hay calificaciones
- Geometría 5to AñoDocumento97 páginasGeometría 5to AñoJoEl Perez0% (1)
- Caracteristicas de La InstrumentacionDocumento11 páginasCaracteristicas de La InstrumentacionJael CarrascoAún no hay calificaciones
- Funciones de Uso PrácticoDocumento14 páginasFunciones de Uso Prácticoalejandro cuadrosAún no hay calificaciones
- Teoria de ColasDocumento12 páginasTeoria de ColasFabian andres Gelvez villamizarAún no hay calificaciones