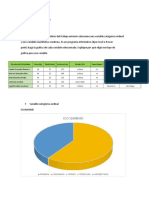
También podría gustarte
- Estadística inferencial aplicadaDe EverandEstadística inferencial aplicadaCalificación: 5 de 5 estrellas5/5 (1)
- Entrevista Conductual EstructuradaDocumento38 páginasEntrevista Conductual Estructuradatrabuco_the_dog100% (1)
- Examen Parcial - Semana 4 - Ra - Segundo Bloque-Analisis y Verificacion de Algoritmos - (Grupo1) - Carlos SabinoDocumento6 páginasExamen Parcial - Semana 4 - Ra - Segundo Bloque-Analisis y Verificacion de Algoritmos - (Grupo1) - Carlos SabinoCarlos Augusto Sabino CañizaresAún no hay calificaciones
- Medidas de Tendencia Central Maria AuxiliadoraDocumento16 páginasMedidas de Tendencia Central Maria AuxiliadoraANTONY LEONEL ZAMATA CONDORIAún no hay calificaciones
- 4.1 Tendencia CentralDocumento25 páginas4.1 Tendencia CentralAlexis PradoAún no hay calificaciones
- Laboratorio de Ejercicios 2010207 Ivan DelgadilloDocumento16 páginasLaboratorio de Ejercicios 2010207 Ivan DelgadilloIván DelgadilloAún no hay calificaciones
- Estadistica y Probabilidades - Semana 3Documento19 páginasEstadistica y Probabilidades - Semana 3Christian MillerAún no hay calificaciones
- 8° Matemática Estadística MedidasDocumento16 páginas8° Matemática Estadística MedidasLuis del NidoAún no hay calificaciones
- Semana 05-06 Estaditica - 1Documento63 páginasSemana 05-06 Estaditica - 1Jose Ivan C. BAún no hay calificaciones
- SolucionDocumento8 páginasSolucionJeisson Andrés Pinilla ReyesAún no hay calificaciones
- Estadistica 12-12Documento12 páginasEstadistica 12-12Richard EncaladaAún no hay calificaciones
- Medidas de Tendencia Central y DispersionDocumento45 páginasMedidas de Tendencia Central y DispersionPhony CüntAún no hay calificaciones
- Clase 2 MedidasDocumento60 páginasClase 2 MedidasRoth SchildAún no hay calificaciones
- Medidas de Tendencia CentralDocumento56 páginasMedidas de Tendencia Centralcalin2875Aún no hay calificaciones
- 02.1 - Presentación 1. Módulo 3. Elementos Básicos de La Estadística-1Documento23 páginas02.1 - Presentación 1. Módulo 3. Elementos Básicos de La Estadística-1Sergio CastrilloAún no hay calificaciones
- 3 . Videoconferencia: Estadística BásicaDocumento23 páginas3 . Videoconferencia: Estadística BásicaMartin CarmonaAún no hay calificaciones
- 10° ESTADISTICA 1entrega IIIPDocumento5 páginas10° ESTADISTICA 1entrega IIIPElkin Yesid GonzalezAún no hay calificaciones
- Tendencia CentralDocumento41 páginasTendencia CentralCaterine Rey DuqueAún no hay calificaciones
- GUÍA SESIÓN No 2 - Medidas de Tendencia Central y DispersiónDocumento6 páginasGUÍA SESIÓN No 2 - Medidas de Tendencia Central y Dispersiónyorlycamila67Aún no hay calificaciones
- T2. EstadísticaDocumento26 páginasT2. Estadísticarca_rodrigo0% (1)
- Medidas de Tendencia CentralDocumento9 páginasMedidas de Tendencia Centralsgdc8330Aún no hay calificaciones
- Guía de Repaso Tabla de FrecuenciaDocumento4 páginasGuía de Repaso Tabla de FrecuenciaRomina Reyes VegaAún no hay calificaciones
- Cap8. Medidas de Tendencia CentralDocumento17 páginasCap8. Medidas de Tendencia CentralLuis MatusAún no hay calificaciones
- Medidas de Tendencia CentralDocumento36 páginasMedidas de Tendencia CentralSILVIA UMAJINGAAún no hay calificaciones
- 009 Nociones Básicas de Estadística Descriptiva-1Documento43 páginas009 Nociones Básicas de Estadística Descriptiva-1SILVIA DANITZA HUAMAN PINTADOAún no hay calificaciones
- Taller 3 Estadistica y Probabilidades - Caterine Rey Duque PDFDocumento41 páginasTaller 3 Estadistica y Probabilidades - Caterine Rey Duque PDFCaterine Rey DuqueAún no hay calificaciones
- TESIS I - Seminario #4-Medidas de Tendencia Central y DispersiónDocumento30 páginasTESIS I - Seminario #4-Medidas de Tendencia Central y DispersiónJason Mario Flores HidalgoAún no hay calificaciones
- 5 Medidas de Tendencia Central Datos Agrupados y No AgrupadosDocumento30 páginas5 Medidas de Tendencia Central Datos Agrupados y No AgrupadosIvonne Janeth BarcoAún no hay calificaciones
- Medidas de Tendencia CentralDocumento10 páginasMedidas de Tendencia CentraljsinformaticAún no hay calificaciones
- Media Moda EstadisticaDocumento9 páginasMedia Moda EstadisticaJoan Manuel ZabalaAún no hay calificaciones
- GUÍA No 2 - Medidas de Tendencia Central y Dispersión - RRR PDFDocumento6 páginasGUÍA No 2 - Medidas de Tendencia Central y Dispersión - RRR PDFOrlando K'rmona Martinez100% (1)
- Medidas Numéricas para Datos No Agrupados y Datos AgrupadosDocumento64 páginasMedidas Numéricas para Datos No Agrupados y Datos AgrupadosfaroddriguezAún no hay calificaciones
- Fase 2 - Milanis BuzónDocumento26 páginasFase 2 - Milanis Buzónwilson andres quintana gamboaAún no hay calificaciones
- Clase 6Documento11 páginasClase 6Ikiki MejiaAún no hay calificaciones
- DispersionyformaDocumento47 páginasDispersionyformaIgor Sadaba100% (1)
- SESION 03 Medidas de Tendencia IME PDFDocumento28 páginasSESION 03 Medidas de Tendencia IME PDFRonald Vitor RuizAún no hay calificaciones
- Medidas de Tendencia CentralDocumento9 páginasMedidas de Tendencia CentralDiana QuinteroAún no hay calificaciones
- Estadistica (Primera Clase)Documento48 páginasEstadistica (Primera Clase)omarAún no hay calificaciones
- TESIS I - Seminario 04-Medidas de Tendencia Central y DispersiónDocumento29 páginasTESIS I - Seminario 04-Medidas de Tendencia Central y DispersiónJosé GómezAún no hay calificaciones
- MTC y MDDocumento36 páginasMTC y MDIvan OtazuAún no hay calificaciones
- S03 S1-MedidastendenciacentralDocumento23 páginasS03 S1-MedidastendenciacentralGerardo SanchezAún no hay calificaciones
- Ejercicio MTCDocumento3 páginasEjercicio MTCjenisAún no hay calificaciones
- Cgeu Cgeu-114 Ejercicio t005Documento15 páginasCgeu Cgeu-114 Ejercicio t005alonsocupe1Aún no hay calificaciones
- Medidas de Tendencia CentralDocumento22 páginasMedidas de Tendencia CentralLucía SantanaAún no hay calificaciones
- Apuntes. Medidas de Tendencia CentralDocumento8 páginasApuntes. Medidas de Tendencia CentralMaria JoseAún no hay calificaciones
- Scastilloa@upao Edu PeDocumento23 páginasScastilloa@upao Edu Pedalia inga vilchezAún no hay calificaciones
- Elementos de Estadistica DescriptivaDocumento51 páginasElementos de Estadistica Descriptivamayeli.perezAún no hay calificaciones
- Clase 28 Estadística DescriptivaDocumento29 páginasClase 28 Estadística DescriptivaJOSE EDWARD ORTEGA GALEANOAún no hay calificaciones
- Semana 4 - Medidas EstadísticasDocumento22 páginasSemana 4 - Medidas EstadísticasANYELI MARIEL VASQUEZ AGUILARAún no hay calificaciones
- Apuntes Estadística 3º MedioDocumento10 páginasApuntes Estadística 3º MediopepepepinoAún no hay calificaciones
- Unidad No. 02 Análisis EstadísticoDocumento17 páginasUnidad No. 02 Análisis Estadísticoaxelmrd100% (1)
- Distribución de FrecuenciaDocumento32 páginasDistribución de Frecuenciasteam kitAún no hay calificaciones
- Estadistica, Medidas de Tendencia Central Datos No Agrupados y AgrupadosDocumento46 páginasEstadistica, Medidas de Tendencia Central Datos No Agrupados y Agrupadosnatalia quirogaAún no hay calificaciones
- Unidad3 Epi en Practica MédicaDocumento45 páginasUnidad3 Epi en Practica Médicaluis ivanAún no hay calificaciones
- Sesión 21 Matemática Iii BimestreDocumento9 páginasSesión 21 Matemática Iii BimestreDanner Arnold Rebaza RodriguezAún no hay calificaciones
- TEMA 2 MEDIDAS DE FRECUENCIA 1ra - ParteDocumento57 páginasTEMA 2 MEDIDAS DE FRECUENCIA 1ra - ParteadonayAún no hay calificaciones
- Estadística DescriptivaDocumento6 páginasEstadística DescriptivaRocio CarreraAún no hay calificaciones
- Estadística DescriptivaDocumento8 páginasEstadística DescriptivaJOSE ARMANDO VARGAS MAYORGAAún no hay calificaciones
- Medidas de Tendencia CentralDocumento12 páginasMedidas de Tendencia CentralJhohan AguilarAún no hay calificaciones
- Unidad 3. ESTADÍSTICA DESCRIPTIVADocumento43 páginasUnidad 3. ESTADÍSTICA DESCRIPTIVAcampo jojoaAún no hay calificaciones
- Material MatematicaDocumento46 páginasMaterial MatematicaSERGIO GABRIEL ATO FRIASAún no hay calificaciones
- TItuaña - Investigación Sobre Medidas de Tendencia Central, Dispersión y PosiciónDocumento17 páginasTItuaña - Investigación Sobre Medidas de Tendencia Central, Dispersión y PosiciónCarlosAún no hay calificaciones
- Tarea - caso-1-GESTION y Control Costos-2023Documento5 páginasTarea - caso-1-GESTION y Control Costos-2023FERNANDA ESTEFANIA ULLOA MARIMAN0% (1)
- Taller 3Documento5 páginasTaller 3FERNANDA ESTEFANIA ULLOA MARIMANAún no hay calificaciones
- Red PL Dinamica ProbabilisticaDocumento4 páginasRed PL Dinamica ProbabilisticaFERNANDA ESTEFANIA ULLOA MARIMANAún no hay calificaciones
- Ética y Legislación AplicadaDocumento16 páginasÉtica y Legislación AplicadaFERNANDA ESTEFANIA ULLOA MARIMANAún no hay calificaciones
- Ética y Legislación Aplicada: Semana: La ResponsabilidadDocumento12 páginasÉtica y Legislación Aplicada: Semana: La ResponsabilidadFERNANDA ESTEFANIA ULLOA MARIMANAún no hay calificaciones
- Tarea - Taller caso-3-GESTION y Control CostosDocumento7 páginasTarea - Taller caso-3-GESTION y Control CostosFERNANDA ESTEFANIA ULLOA MARIMANAún no hay calificaciones
- Clase 2 Tipos de Funciones y Función InversaDocumento22 páginasClase 2 Tipos de Funciones y Función InversaFERNANDA ESTEFANIA ULLOA MARIMANAún no hay calificaciones
- Indo1041 U3 s12 Caso n03 PDFDocumento5 páginasIndo1041 U3 s12 Caso n03 PDFFERNANDA ESTEFANIA ULLOA MARIMANAún no hay calificaciones
- Fisica 1Documento19 páginasFisica 1FERNANDA ESTEFANIA ULLOA MARIMANAún no hay calificaciones
- Material de Estudio Semana 7Documento3 páginasMaterial de Estudio Semana 7FERNANDA ESTEFANIA ULLOA MARIMANAún no hay calificaciones
- Clase 4. Regresión - 27 - 07Documento19 páginasClase 4. Regresión - 27 - 07FERNANDA ESTEFANIA ULLOA MARIMANAún no hay calificaciones
- Prueba de Hipotesis para Dos Medias 2018 - IIDocumento21 páginasPrueba de Hipotesis para Dos Medias 2018 - IIcesar rodriguez bejar100% (1)
- TP2. Planificacion de La Investigacion. Santiago BarraganDocumento36 páginasTP2. Planificacion de La Investigacion. Santiago BarraganAlyson GuilhermeAún no hay calificaciones
- Estimacion de Incertidumbre de Medida en Metrologia Dimensional - Ing Raizel Farid Sanabria SandiDocumento40 páginasEstimacion de Incertidumbre de Medida en Metrologia Dimensional - Ing Raizel Farid Sanabria SandiDiego Tobr100% (1)
- Actividad 8 Trabajo Colaborativo 2 - NEGOCIACIONDocumento5 páginasActividad 8 Trabajo Colaborativo 2 - NEGOCIACIONDiana PinedaAún no hay calificaciones
- Medición de La Satisfaccion Laboral MonografiaDocumento14 páginasMedición de La Satisfaccion Laboral MonografiaMayra rosas salazarAún no hay calificaciones
- For-Ls-006 - Formato de Consolidación UnidimensionalDocumento6 páginasFor-Ls-006 - Formato de Consolidación Unidimensionalangel patiñoAún no hay calificaciones
- Formato Word CompasDocumento2 páginasFormato Word CompasCamila CogolloAún no hay calificaciones
- DanzaDocumento35 páginasDanzaGrandez Grandez LeinaAún no hay calificaciones
- Practica 4 Semana 2021Documento6 páginasPractica 4 Semana 2021Daniel David Romero GameroAún no hay calificaciones
- Planificación - Conocimiento PreliminarDocumento11 páginasPlanificación - Conocimiento PreliminarCesar AlexanderAún no hay calificaciones
- Análisis Del Sector Camaronero EcuatorianoDocumento8 páginasAnálisis Del Sector Camaronero EcuatorianoBrando CeliAún no hay calificaciones
- Análisis e Interpretación de Resultados BrownieDocumento4 páginasAnálisis e Interpretación de Resultados BrownieAyleen SerranoAún no hay calificaciones
- Evaluacion Del Desempeño LaboralDocumento40 páginasEvaluacion Del Desempeño LaboralAarón TorresAún no hay calificaciones
- Evaluación de Desempeño LapDocumento8 páginasEvaluación de Desempeño LapMaria Fernanda Salcedo AnayaAún no hay calificaciones
- Silabo TEIDocumento6 páginasSilabo TEIAntuane ValdivaAún no hay calificaciones
- Contraste de Hipótesis. Comparación de Más de Dos Medias Independientes Mediante Pruebas No Paramétricas: Prueba de Kruskal-WallisDocumento6 páginasContraste de Hipótesis. Comparación de Más de Dos Medias Independientes Mediante Pruebas No Paramétricas: Prueba de Kruskal-WallisHector LealAún no hay calificaciones
- 669-Article Text-2119-1-10-20200724Documento21 páginas669-Article Text-2119-1-10-20200724JessicaK.CutipaAún no hay calificaciones
- Mitutoyo PDFDocumento428 páginasMitutoyo PDFJaime Alberto Hernández OlivaAún no hay calificaciones
- Tarea 3 Metodologia JulioDocumento7 páginasTarea 3 Metodologia JulioArgonautaMaster 00Aún no hay calificaciones
- Proyectos Socioculturales 1Documento6 páginasProyectos Socioculturales 1Raquel Graciela Crespo RomeroAún no hay calificaciones
- F.obr.6.08.07 Protocolo Verificación de Taquímetros en ObraDocumento1 páginaF.obr.6.08.07 Protocolo Verificación de Taquímetros en ObraWalter MillalenAún no hay calificaciones
- Capitulo IV MetodologíaDocumento7 páginasCapitulo IV MetodologíaGustavo PerezAún no hay calificaciones
- Diseño Experimental-Prueba TDocumento13 páginasDiseño Experimental-Prueba Trodrigo claveriAún no hay calificaciones
- Solución Estadística.Documento12 páginasSolución Estadística.Gianfranco JulcaAún no hay calificaciones
- Laboratorio-Final III UNIDA ECONODocumento50 páginasLaboratorio-Final III UNIDA ECONOharoldcr94Aún no hay calificaciones
- Estudio de TiemposDocumento3 páginasEstudio de TiemposMayra BautistaAún no hay calificaciones
- Clase 02 - Diag OrganizacionalDocumento3 páginasClase 02 - Diag OrganizacionalRocío Ortega GutiérrezAún no hay calificaciones
- Unidad 2 Problema y Objetivos de Investigación Nuevo Diseño 2022 SEGDocumento9 páginasUnidad 2 Problema y Objetivos de Investigación Nuevo Diseño 2022 SEGsofimx66Aún no hay calificaciones