También podría gustarte
- Cómo entender estadística fácilmenteDe EverandCómo entender estadística fácilmenteCalificación: 3.5 de 5 estrellas3.5/5 (2)
- ESTADISTICA - EnsayoDocumento6 páginasESTADISTICA - EnsayoYeikool Alexander ChavezAún no hay calificaciones
- EstadísticaDocumento4 páginasEstadísticaANASTASIA R&M SAS ANASTASIA R&M SASAún no hay calificaciones
- EstadísticaDocumento6 páginasEstadísticaJuana Alejandrina Contreras MojarraAún no hay calificaciones
- Grupo de Exposicion #19 de BioestadisticaDocumento10 páginasGrupo de Exposicion #19 de BioestadisticaKemer Ponce GuzmanAún no hay calificaciones
- Tipos de EstadisticaDocumento7 páginasTipos de EstadisticaMaria GanchozoAún no hay calificaciones
- MatemáticaDocumento12 páginasMatemáticaMaria Trinidad M. NeyraAún no hay calificaciones
- Actividad I Trabajo EstadisticasDocumento6 páginasActividad I Trabajo EstadisticasJonner Alberto RhlmAún no hay calificaciones
- InvestigacionesDocumento90 páginasInvestigacionesUliannys VillegasAún no hay calificaciones
- Estadistica I InformeDocumento5 páginasEstadistica I Informeayrana obispoAún no hay calificaciones
- Estadistica RamonDocumento7 páginasEstadistica RamonCarlos HernandezAún no hay calificaciones
- Estadistica IDocumento6 páginasEstadistica IOsnelly VillarroelAún no hay calificaciones
- Unidad 1 Estadística InfDocumento13 páginasUnidad 1 Estadística InfMaría Fernanda Gatica MedranoAún no hay calificaciones
- 1 Estadistica I 22Documento23 páginas1 Estadistica I 22Estefanie SalgueroAún no hay calificaciones
- Introduccion A La EstadisticaDocumento17 páginasIntroduccion A La EstadisticaAngelo UztarizAún no hay calificaciones
- Guia de Estadistica Uno UnesrDocumento20 páginasGuia de Estadistica Uno UnesrJose AvilaAún no hay calificaciones
- Aspectos Generales de La EstadísticaDocumento116 páginasAspectos Generales de La EstadísticaJonatan RamirezAún no hay calificaciones
- TP 1 EstadisticaDocumento7 páginasTP 1 EstadisticalucianaAún no hay calificaciones
- Trabajo Listo de Estadistica InferencialDocumento28 páginasTrabajo Listo de Estadistica InferencialMardeyLozadaVargasAún no hay calificaciones
- La EstadisticaDocumento7 páginasLa EstadisticaDUGLASDAVILAAún no hay calificaciones
- Estadistica-Muestreo, Frecuencias y Gráficos.Documento14 páginasEstadistica-Muestreo, Frecuencias y Gráficos.déborah_rosalesAún no hay calificaciones
- EstadisticaDocumento9 páginasEstadisticaDiego GamezAún no hay calificaciones
- La Estadistica - Montiel JanethDocumento5 páginasLa Estadistica - Montiel JanethJaneth MontielAún no hay calificaciones
- Ensayo Origen y Aplicaciones de La EstadisticaDocumento6 páginasEnsayo Origen y Aplicaciones de La EstadisticaGuille SuásteguiAún no hay calificaciones
- Estadistica DescriptivaDocumento105 páginasEstadistica Descriptivaespanhol para empresas campinasAún no hay calificaciones
- Karina Trabajo EstadisticaDocumento9 páginasKarina Trabajo EstadisticaHazelAún no hay calificaciones
- MODULO No 1 ESTADISTICA 10o. GRADO 2021Documento27 páginasMODULO No 1 ESTADISTICA 10o. GRADO 2021Shaiel BuenoAún no hay calificaciones
- Estadistica DescriptivaDocumento8 páginasEstadistica DescriptivaFRIEDA XAXBE LAVIN OLIVEROSAún no hay calificaciones
- Cuadro Sobre Generalidades e Importancia de La EstadísticaDocumento3 páginasCuadro Sobre Generalidades e Importancia de La EstadísticaArnulfo Rojas Tarazona100% (1)
- Ficha de Cátedra - Reseña Histórica de La Ciencia EstadísticaDocumento6 páginasFicha de Cátedra - Reseña Histórica de La Ciencia EstadísticaBibliotecaCEFTSAún no hay calificaciones
- Aa Integradora 2Documento8 páginasAa Integradora 2nicolas villarrealAún no hay calificaciones
- Introducción Fundamentos 2022Documento85 páginasIntroducción Fundamentos 2022Gloria DelgadoAún no hay calificaciones
- UNIVERSIDAD AUTONOMA GABRIEL RENE MORENO Analitico PrecioDocumento6 páginasUNIVERSIDAD AUTONOMA GABRIEL RENE MORENO Analitico PrecioRoxana MariscalAún no hay calificaciones
- La Estadística Es Una Disciplina Científica Que Se Ocupa de La ObtenciónDocumento8 páginasLa Estadística Es Una Disciplina Científica Que Se Ocupa de La ObtenciónJuan LariosAún no hay calificaciones
- Modulo I EstadisticaDocumento26 páginasModulo I EstadisticaJosué HernándezAún no hay calificaciones
- Población y VariableDocumento19 páginasPoblación y VariableCecilia EsquivelAún no hay calificaciones
- Unidad I Que Es La Estadistica PDFDocumento3 páginasUnidad I Que Es La Estadistica PDFtamaraAún no hay calificaciones
- Trabajo EstadisticaDocumento6 páginasTrabajo Estadisticalolydiaz.1908Aún no hay calificaciones
- Trabajo Escrito de ProbabilidadDocumento12 páginasTrabajo Escrito de ProbabilidadJesus E. ComellysAún no hay calificaciones
- Indice EstadisticaDocumento8 páginasIndice EstadisticaSergioAún no hay calificaciones
- Actividad 1Documento3 páginasActividad 1El Sucesor De LAún no hay calificaciones
- Unidad 1 Estadística (2-2021)Documento14 páginasUnidad 1 Estadística (2-2021)vanessa perez riberaAún no hay calificaciones
- Ciencia Estadística y Métodos de Relevamiento 2018 PDFDocumento14 páginasCiencia Estadística y Métodos de Relevamiento 2018 PDFRita FontaniniAún no hay calificaciones
- Evolución Histórica de La EstadísticaDocumento5 páginasEvolución Histórica de La EstadísticaKenia Aguilar TobarAún no hay calificaciones
- Introduccion A La Estadistica Descriptiva (Tercer Informe)Documento39 páginasIntroduccion A La Estadistica Descriptiva (Tercer Informe)Cristel Martes LantiguaAún no hay calificaciones
- Reseña Histórica de La EstadísticaDocumento7 páginasReseña Histórica de La Estadísticaanon_96039154Aún no hay calificaciones
- ESTADÍSTICADocumento8 páginasESTADÍSTICAJuan Lazo100% (1)
- Introducción A La Estadística. Tema IDocumento17 páginasIntroducción A La Estadística. Tema IjhosepAún no hay calificaciones
- Estadistica 24092017Documento62 páginasEstadistica 24092017BA YUAún no hay calificaciones
- Escalas de Medicion (Monografía)Documento14 páginasEscalas de Medicion (Monografía)Luiscarlys Maican100% (1)
- Introducción A La Estadística Inferencial IDocumento12 páginasIntroducción A La Estadística Inferencial IBrendi Estefanii OrnelasAún no hay calificaciones
- Unidad 1 Estadistica PDFDocumento8 páginasUnidad 1 Estadistica PDFFrailin MatosAún no hay calificaciones
- Conceptos Basicos de La Estadistica Hiram SánchezDocumento8 páginasConceptos Basicos de La Estadistica Hiram SánchezHiram SánchezAún no hay calificaciones
- TEORIA 03 EstadisticosDocumento75 páginasTEORIA 03 EstadisticosFredy Huamani MendozaAún no hay calificaciones
- Tra Uni 1 EstadisticaDocumento14 páginasTra Uni 1 EstadisticaromeliaAún no hay calificaciones
- Resumen Final EstadisticaDocumento43 páginasResumen Final EstadisticaAmbar CorvalánAún no hay calificaciones
- Apuntes 1Documento18 páginasApuntes 1Fabián OlivaresAún no hay calificaciones
- Aspectos Basicos de La EstadisticaDocumento12 páginasAspectos Basicos de La EstadisticamichaelAún no hay calificaciones
- Estadistica y Su Division Stacy MoralesDocumento8 páginasEstadistica y Su Division Stacy Moralescuentasn159Aún no hay calificaciones
- Guia Practica - Costos Por Procesos (Yheyson Soto)Documento9 páginasGuia Practica - Costos Por Procesos (Yheyson Soto)Jhonathan RodriguezAún no hay calificaciones
- Informe NIC 2 (Jhonathan)Documento4 páginasInforme NIC 2 (Jhonathan)Jhonathan RodriguezAún no hay calificaciones
- Costos Por Procesos - Ejercicio Practico N°1 (Yheyson Soto)Documento11 páginasCostos Por Procesos - Ejercicio Practico N°1 (Yheyson Soto)Jhonathan RodriguezAún no hay calificaciones
- Acciones y Teoría de Dividendos Informe Rivas, Soto y VelasquezDocumento25 páginasAcciones y Teoría de Dividendos Informe Rivas, Soto y VelasquezJhonathan RodriguezAún no hay calificaciones
- Consignaciones Informe Rivas, Soto y Velasquez Sede Menca de LeoniDocumento27 páginasConsignaciones Informe Rivas, Soto y Velasquez Sede Menca de LeoniJhonathan RodriguezAún no hay calificaciones
- Ensayo Unidad III Contabilidad Superior (Jhonathan)Documento7 páginasEnsayo Unidad III Contabilidad Superior (Jhonathan)Jhonathan RodriguezAún no hay calificaciones
- Asignación Unidad II Contabilidad SuperiorDocumento1 páginaAsignación Unidad II Contabilidad SuperiorJhonathan RodriguezAún no hay calificaciones
- Links EstadisticaDocumento2 páginasLinks EstadisticaJhonathan RodriguezAún no hay calificaciones
- Ejemplo EnsayoDocumento14 páginasEjemplo EnsayoJhonathan RodriguezAún no hay calificaciones
- Lo Que Dire en El VideoDocumento1 páginaLo Que Dire en El VideoJhonathan RodriguezAún no hay calificaciones
- Informe Estadistica by Patsy PeatersDocumento19 páginasInforme Estadistica by Patsy PeatersJhonathan RodriguezAún no hay calificaciones
- Bibliografia SamiraDocumento2 páginasBibliografia SamiraJhonathan RodriguezAún no hay calificaciones
- Como Actualizar Tu Tablet Titan 7001 A Android 2Documento17 páginasComo Actualizar Tu Tablet Titan 7001 A Android 2RedCat0120% (1)
- Causas, Conceptos y Objetivos de La Ingeniería EconómicaDocumento8 páginasCausas, Conceptos y Objetivos de La Ingeniería EconómicaNeko77Aún no hay calificaciones
- Tasas Tarifas Davivienda 01 07 2022Documento41 páginasTasas Tarifas Davivienda 01 07 2022Cristian Eduardo Zanguña RAún no hay calificaciones
- Actividad de Aprendizaje 2. Plan de NegocioDocumento6 páginasActividad de Aprendizaje 2. Plan de NegocioHernandez BvhAún no hay calificaciones
- Chlorella VulgarisDocumento1 páginaChlorella VulgarisSantiago Ospina CortesAún no hay calificaciones
- PALABRAS PARA LECTURA Aprende Con CamilitaDocumento26 páginasPALABRAS PARA LECTURA Aprende Con Camilitawilli machacaAún no hay calificaciones
- PSI-05-F01 Reporte de Acción Rev.2Documento2 páginasPSI-05-F01 Reporte de Acción Rev.2Lourdes González BernalAún no hay calificaciones
- Tema 5Documento3 páginasTema 5Yohana SalazarAún no hay calificaciones
- Vacunas Dr. PorrasDocumento7 páginasVacunas Dr. PorrasIvan GoldenbergAún no hay calificaciones
- PLAN RETORNO SEGURO PROGRAMA ELIGE VIDA SANA 2021 (Julio)Documento29 páginasPLAN RETORNO SEGURO PROGRAMA ELIGE VIDA SANA 2021 (Julio)Romina IbañezAún no hay calificaciones
- Proyecto Ucv HoyDocumento31 páginasProyecto Ucv HoyMARVIL DELGADO FLORESAún no hay calificaciones
- La Publicidad Que VieneDocumento8 páginasLa Publicidad Que VieneGordon FreemanAún no hay calificaciones
- Tuberias y Tubos PDFDocumento20 páginasTuberias y Tubos PDFJesus ViEliAún no hay calificaciones
- Proforma Tropipalma SaDocumento3 páginasProforma Tropipalma SaJhoz Alexander Cantos LitumaAún no hay calificaciones
- Curso de Algebra y Trigonometria3 PDFDocumento86 páginasCurso de Algebra y Trigonometria3 PDFSangui RojasAún no hay calificaciones
- Practica OrganigramaDocumento2 páginasPractica OrganigramaEdwin Cortes0% (1)
- Cálculo Vec U 01 ActualDocumento33 páginasCálculo Vec U 01 Actualandres islas claraAún no hay calificaciones
- Empresa Agroindustrial Pomalca S.A.ADocumento11 páginasEmpresa Agroindustrial Pomalca S.A.ASamuel BarraganAún no hay calificaciones
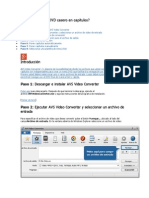
- Cómo Dividir Un DVD Casero en CapítulosDocumento6 páginasCómo Dividir Un DVD Casero en CapítulosAnton TuralyonAún no hay calificaciones
- Cadena de Valor PlantillaDocumento21 páginasCadena de Valor PlantillaWendy Yurani Moncada NeuqueAún no hay calificaciones
- Estructura de La EncuestaDocumento5 páginasEstructura de La EncuestaCelso Nolasco MoralesAún no hay calificaciones
- Practica 2Documento14 páginasPractica 2Uriel Gallegos PérezAún no hay calificaciones
- Módulo 3. Comercialización de GranosDocumento31 páginasMódulo 3. Comercialización de GranosJuan FernandezAún no hay calificaciones
- Vector Normal A Una Superficie Parametria SuaveDocumento3 páginasVector Normal A Una Superficie Parametria SuaveSofia Karolina Quiroz NombertoAún no hay calificaciones
- Reproduccion AsexualDocumento2 páginasReproduccion AsexualFernandaAún no hay calificaciones
- Tema 1. Conceptualización de Logística y Supply Chain ManagementDocumento13 páginasTema 1. Conceptualización de Logística y Supply Chain ManagementPao Simbaqueva MoralesAún no hay calificaciones
- TOP - Clase 3.4 - 12042023Documento184 páginasTOP - Clase 3.4 - 12042023Jose Otilio Hernandez FernandezAún no hay calificaciones
- Desarrollo Caso Practico 2 Sport Athletic S.A AlumnosDocumento14 páginasDesarrollo Caso Practico 2 Sport Athletic S.A AlumnosAnthonny Montalván100% (1)
- A.C.S. Tema 4. Tiempo y ClimaDocumento19 páginasA.C.S. Tema 4. Tiempo y ClimaResu Corral Ausucua100% (3)
- Tabla Comparativa Servientrega VS DHL PDFDocumento2 páginasTabla Comparativa Servientrega VS DHL PDFAC CalizAún no hay calificaciones
- Suicidología: Prevención, tratamiento psicológico e investigación de procesos suicidasDe EverandSuicidología: Prevención, tratamiento psicológico e investigación de procesos suicidasCalificación: 5 de 5 estrellas5/5 (7)
- El péndulo de sanación: Péndulo hebreo. Investigación y sistematización de la técnicaDe EverandEl péndulo de sanación: Péndulo hebreo. Investigación y sistematización de la técnicaCalificación: 4.5 de 5 estrellas4.5/5 (27)
- La curación espontánea de las creencias: Cómo librarse de los falsos límitesDe EverandLa curación espontánea de las creencias: Cómo librarse de los falsos límitesCalificación: 4.5 de 5 estrellas4.5/5 (22)
- La autopsia psicológica: Psicotanatología forenseDe EverandLa autopsia psicológica: Psicotanatología forenseAún no hay calificaciones
- El Tao de la física: Una exploración de los paralelismos entre la física moderna y el misticismo orientalDe EverandEl Tao de la física: Una exploración de los paralelismos entre la física moderna y el misticismo orientalCalificación: 5 de 5 estrellas5/5 (3)
- Neurocuántica: La nueva frontera de la neurocienciaDe EverandNeurocuántica: La nueva frontera de la neurocienciaCalificación: 5 de 5 estrellas5/5 (1)
- Neuropsicología: Los fundamentos de la materiaDe EverandNeuropsicología: Los fundamentos de la materiaCalificación: 5 de 5 estrellas5/5 (1)
- Editar: un oficio: Atajos / Rodeos /ModelosDe EverandEditar: un oficio: Atajos / Rodeos /ModelosCalificación: 5 de 5 estrellas5/5 (2)
- Metodología de la investigación social: Paradigmas: cuantitativo, sociocrítico, cualitativo, complementarioDe EverandMetodología de la investigación social: Paradigmas: cuantitativo, sociocrítico, cualitativo, complementarioCalificación: 5 de 5 estrellas5/5 (10)
- Humanos por diseño: De la evolución por azar a la transformación por elecciónDe EverandHumanos por diseño: De la evolución por azar a la transformación por elecciónCalificación: 4 de 5 estrellas4/5 (11)
- Ingeniería de Sonido. Conceptos, fundamentos y casos prácticos: CINE, TELEVISIÓN Y RADIODe EverandIngeniería de Sonido. Conceptos, fundamentos y casos prácticos: CINE, TELEVISIÓN Y RADIOCalificación: 4.5 de 5 estrellas4.5/5 (8)
- El nuevo ser humano: Toque cuántico 2.0. Descubrir y evolucionarDe EverandEl nuevo ser humano: Toque cuántico 2.0. Descubrir y evolucionarCalificación: 4.5 de 5 estrellas4.5/5 (9)
- La sabiduría del cuerpo: Recopilación de artículos de Moshe FeldenkraisDe EverandLa sabiduría del cuerpo: Recopilación de artículos de Moshe FeldenkraisCalificación: 4 de 5 estrellas4/5 (5)
- Curso Práctico de Química GeneralDe EverandCurso Práctico de Química GeneralCalificación: 4 de 5 estrellas4/5 (4)
- Introducción a los estudios del discurso multimodalDe EverandIntroducción a los estudios del discurso multimodalCalificación: 5 de 5 estrellas5/5 (1)
- Nuevo manual de Reflexología: El método más completo y actual sobre las técnicas, la práctica y la teoría de la ciencia reflexológicaDe EverandNuevo manual de Reflexología: El método más completo y actual sobre las técnicas, la práctica y la teoría de la ciencia reflexológicaCalificación: 4.5 de 5 estrellas4.5/5 (16)
- Manual de prácticas de Ingeniería de Alimentos: Propiedades, operaciones y bioprocesosDe EverandManual de prácticas de Ingeniería de Alimentos: Propiedades, operaciones y bioprocesosAún no hay calificaciones
- La quiropráctica desvelada: Confesiones de un quiropráctico heréticoDe EverandLa quiropráctica desvelada: Confesiones de un quiropráctico heréticoCalificación: 4 de 5 estrellas4/5 (5)
- Sesgos Cognitivos: Una Fascinante Mirada dentro de la Psicología Humana y los Métodos para Evitar la Disonancia Cognitiva, Mejorar sus Habilidades para Resolver Problemas y Tomar Mejores DecisionesDe EverandSesgos Cognitivos: Una Fascinante Mirada dentro de la Psicología Humana y los Métodos para Evitar la Disonancia Cognitiva, Mejorar sus Habilidades para Resolver Problemas y Tomar Mejores DecisionesCalificación: 4.5 de 5 estrellas4.5/5 (13)