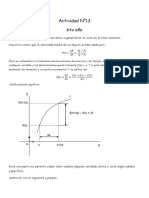
También podría gustarte
- Dinámica De Fluidos Computacional Para IngenierosDe EverandDinámica De Fluidos Computacional Para IngenierosCalificación: 4 de 5 estrellas4/5 (1)
- EJERCICIOS PROPUESTOS - Estadistica - UladechDocumento6 páginasEJERCICIOS PROPUESTOS - Estadistica - UladechKatherine BG100% (1)
- Análisis estadístico de datos multivariadosDe EverandAnálisis estadístico de datos multivariadosCalificación: 5 de 5 estrellas5/5 (1)
- Propagación de La IncertidumbreDocumento20 páginasPropagación de La IncertidumbreyorrejuelaAún no hay calificaciones
- Solucionario Beiser PDFDocumento2 páginasSolucionario Beiser PDFNicolas BarraganAún no hay calificaciones
- Problema 1 07b 15Documento1 páginaProblema 1 07b 15aleinAún no hay calificaciones
- Practica N°03 - Mae: Universidad Privada Antenor Orrego Escuela Profesional de AdministracionDocumento3 páginasPractica N°03 - Mae: Universidad Privada Antenor Orrego Escuela Profesional de AdministracionAaron SancarrancoAún no hay calificaciones
- Práctica de Laboratorio de Física AmDocumento7 páginasPráctica de Laboratorio de Física AmLiam Siles NuñezAún no hay calificaciones
- 2012-09-19 - Metodos - Parcial 1Documento3 páginas2012-09-19 - Metodos - Parcial 1Juan Manuel DommelAún no hay calificaciones
- Trabajo Colaborativo CalculoDocumento11 páginasTrabajo Colaborativo Calculoalejandra trujilloAún no hay calificaciones
- Esta Di SticaDocumento5 páginasEsta Di SticaJhonatan Chaverra50% (2)
- Informe 1 de Laboratorio de Física MecanicaDocumento4 páginasInforme 1 de Laboratorio de Física Mecanicatatiana tamayoAún no hay calificaciones
- Reporte Datos ExperimentalesDocumento8 páginasReporte Datos Experimentalesnanmate8664Aún no hay calificaciones
- Ejercicios LOGARITMODocumento7 páginasEjercicios LOGARITMOVanessa MéndezAún no hay calificaciones
- Experimento 1 Fisica MecanicaDocumento5 páginasExperimento 1 Fisica MecanicaJUAN CAMILO PULIDO MENDEZAún no hay calificaciones
- Solución Taller No.1-ConfiabilidadDocumento14 páginasSolución Taller No.1-ConfiabilidadGerardo Andrés Castro EcheverríaAún no hay calificaciones
- Pre MaestriaDocumento2 páginasPre MaestriaSaira DíAlAún no hay calificaciones
- S01 - S02 - Lab 1 Precisión de Las MedidasDocumento14 páginasS01 - S02 - Lab 1 Precisión de Las MedidasPaola SaldarriagaLazaroAún no hay calificaciones
- Péndulo SimpleDocumento11 páginasPéndulo SimpleFranco MoliniAún no hay calificaciones
- Caida LibreDocumento4 páginasCaida LibreDonnie Paredes SanchezAún no hay calificaciones
- EjerciciosDocumento12 páginasEjerciciosJessica OrtizAún no hay calificaciones
- B1 EA1 Factorización.Documento12 páginasB1 EA1 Factorización.kc8489706Aún no hay calificaciones
- A4.Jaramillo - Steven.Probabilidad EstadísticaDocumento11 páginasA4.Jaramillo - Steven.Probabilidad EstadísticaSantiago JaramilloAún no hay calificaciones
- Deivadas EcuacionesDocumento20 páginasDeivadas EcuacionesJhon hegelAún no hay calificaciones
- Taller Poblacion Muestra ModelosProbDocumento4 páginasTaller Poblacion Muestra ModelosProbS6rAún no hay calificaciones
- Cuaderno Laura CasDocumento23 páginasCuaderno Laura CasLaura CastiblancoAún no hay calificaciones
- Trabajo Colaborativo Calculo LLDocumento13 páginasTrabajo Colaborativo Calculo LLSoporte LeverIT ColombiaAún no hay calificaciones
- Aporte FisicaDocumento9 páginasAporte FisicaSara GonzalezAún no hay calificaciones
- Metodos Numericos........Documento11 páginasMetodos Numericos........Gamadiel BernalAún no hay calificaciones
- Informe Velocidad Media e InstantaneaDocumento8 páginasInforme Velocidad Media e InstantaneaMiguel Ángel Centeno GutierrezAún no hay calificaciones
- Lab2 Fisica3 O3BDocumento17 páginasLab2 Fisica3 O3BValentina RuedaAún no hay calificaciones
- 1.5 Dos Muestras Pruebas Sobre Dos Medias Utilizando La Distribución Normal y T StudentDocumento11 páginas1.5 Dos Muestras Pruebas Sobre Dos Medias Utilizando La Distribución Normal y T StudentGiovanni LedgionAún no hay calificaciones
- MollebayaDocumento15 páginasMollebayaCristhian RomeroAún no hay calificaciones
- Laboratorio 3 Fisica 3Documento9 páginasLaboratorio 3 Fisica 3Julia CastellonAún no hay calificaciones
- Solucionario-Beiser PDFDocumento3 páginasSolucionario-Beiser PDFArturo Chavez PalmaAún no hay calificaciones
- Practica de Teoría de ErroresDocumento4 páginasPractica de Teoría de ErroresVIVIANA YOLANDA ABANTO FERNANDEZAún no hay calificaciones
- Evaluacion 10Documento78 páginasEvaluacion 10Brisa J. Rojas GutierrezAún no hay calificaciones
- Cap 2 Integral DefinidaDocumento26 páginasCap 2 Integral DefinidaEdwin ChacónAún no hay calificaciones
- Informe Laboratorio 7Documento10 páginasInforme Laboratorio 7MOISES DAVID HUAMAN TORRESAún no hay calificaciones
- CD - Trabajo 2 - Colaborativo 1 - Grupo 104Documento6 páginasCD - Trabajo 2 - Colaborativo 1 - Grupo 104Maye BernalAún no hay calificaciones
- Tarea 1 Fisica ModernaDocumento16 páginasTarea 1 Fisica ModernaYendri Yepes HoyosAún no hay calificaciones
- Raices de Ecuaciones Claudia Camila Cordoba CadenaaaaDocumento6 páginasRaices de Ecuaciones Claudia Camila Cordoba CadenaaaaCamila CordobaAún no hay calificaciones
- TrigoDocumento18 páginasTrigoYurani GuamangaAún no hay calificaciones
- Bitacora 1 PDFDocumento8 páginasBitacora 1 PDFSantiago Marin BecerraAún no hay calificaciones
- Examen 3 Periodo Algebra 8Documento4 páginasExamen 3 Periodo Algebra 8Jose Luis PantojaAún no hay calificaciones
- Caida Libre y Tiro Vertical FisicaDocumento16 páginasCaida Libre y Tiro Vertical FisicaMario Velásquez GradosAún no hay calificaciones
- Actividad N13Documento4 páginasActividad N13Isa GautoAún no hay calificaciones
- FF1 Taller1 2023BDocumento1 páginaFF1 Taller1 2023BVíctor Andrés Aguilar SalcedoAún no hay calificaciones
- Primera Practica Calificada ResueltaDocumento6 páginasPrimera Practica Calificada Resueltawlen2012Aún no hay calificaciones
- 2021 Onf Examen 2Documento9 páginas2021 Onf Examen 2Luis SanchezAún no hay calificaciones
- Tarea Hidrologia 3Documento10 páginasTarea Hidrologia 3gavaledAún no hay calificaciones
- Informe MOD IIDocumento10 páginasInforme MOD IIIGNACIO EDUARDO ÁLVAREZAún no hay calificaciones
- Ejercicios Identidades TrigonométricasDocumento11 páginasEjercicios Identidades Trigonométricasjohanah19Aún no hay calificaciones
- Métodos Numéricos Inter PolaciónDocumento18 páginasMétodos Numéricos Inter PolaciónSanti MiguelinoAún no hay calificaciones
- Tarea N 3 CC - SSDocumento2 páginasTarea N 3 CC - SSJose Luis Perez RiosAún no hay calificaciones
- Informe 2Documento13 páginasInforme 2Benjamin CorreaAún no hay calificaciones
- Laboratorio Medidas ExperimentalesDocumento16 páginasLaboratorio Medidas ExperimentalesGabriela UribeAún no hay calificaciones
- Entregable Matematica 2Documento10 páginasEntregable Matematica 2angellyapaza2809Aún no hay calificaciones
- Aplicación de procesamiento cuántico de señales en la teoría waveletDe EverandAplicación de procesamiento cuántico de señales en la teoría waveletCalificación: 3 de 5 estrellas3/5 (1)
- Solution of Mathisson-Papapetrou-Dixon equations: for spinning test particles in a Kerr metricDe EverandSolution of Mathisson-Papapetrou-Dixon equations: for spinning test particles in a Kerr metricAún no hay calificaciones
- Problema 3-28 Del Sears El AutogrúaDocumento2 páginasProblema 3-28 Del Sears El AutogrúaaleinAún no hay calificaciones
- Para Obtener Los Picos Del Período. Péndulo OriginDocumento2 páginasPara Obtener Los Picos Del Período. Péndulo OriginaleinAún no hay calificaciones
- Pendulo DisipacionDocumento5 páginasPendulo DisipacionaleinAún no hay calificaciones
- Física Polimodal TapaDocumento1 páginaFísica Polimodal Tapaalein0% (2)
- Problema 6-20 Del Sears Un MuchachoDocumento2 páginasProblema 6-20 Del Sears Un MuchachoaleinAún no hay calificaciones
- Problema 5-41 Del Sears Los Dos BloquesDocumento2 páginasProblema 5-41 Del Sears Los Dos BloquesaleinAún no hay calificaciones
- Problema 5-41 Del Sears Los Dos BloquesDocumento2 páginasProblema 5-41 Del Sears Los Dos BloquesaleinAún no hay calificaciones
- Apunte de VectoresDocumento48 páginasApunte de Vectorescar8cared1Aún no hay calificaciones
- Cronograma 2do Cuatrimestre 2021Documento2 páginasCronograma 2do Cuatrimestre 2021aleinAún no hay calificaciones
- Problema 3-5 Sears Silla PlegableDocumento3 páginasProblema 3-5 Sears Silla PlegablealeinAún no hay calificaciones
- 02 Errores ExperimentalesDocumento13 páginas02 Errores ExperimentalesEdwinAún no hay calificaciones
- Problema 3-14 Del Sears Un IndividuoDocumento1 páginaProblema 3-14 Del Sears Un IndividuoaleinAún no hay calificaciones
- 3d Tiro ParabolicoDocumento15 páginas3d Tiro ParabolicoMaria Javiera Sepúlveda AlamosAún no hay calificaciones
- Nomenclatura InorgánicaDocumento42 páginasNomenclatura InorgánicaPerry Lawrence0% (1)
- Cálculo de Los Parametros Críticos de VDWDocumento4 páginasCálculo de Los Parametros Críticos de VDWaleinAún no hay calificaciones
- Cálculo de La Velocidad Media y Demás SEMINARIO 1Documento5 páginasCálculo de La Velocidad Media y Demás SEMINARIO 1aleinAún no hay calificaciones
- Instrucciones para El 1º ParcialDocumento3 páginasInstrucciones para El 1º ParcialaleinAún no hay calificaciones
- Unidad 5 Formulacion Quimica InorganicaDocumento50 páginasUnidad 5 Formulacion Quimica InorganicaFranklin Navarrete100% (1)
- TP 1Documento8 páginasTP 1aleinAún no hay calificaciones
- Instructivo Parcial ChoiceDocumento1 páginaInstructivo Parcial ChoicealeinAún no hay calificaciones
- Nomenclatura de Quimica InorganicaDocumento16 páginasNomenclatura de Quimica InorganicaSheila DSAún no hay calificaciones
- REDOX 2021 EJ 8 y 10 YANIDocumento17 páginasREDOX 2021 EJ 8 y 10 YANIaleinAún no hay calificaciones
- TP1-Cinetica Qca - Laboratorio 2C 2021 - FinalDocumento12 páginasTP1-Cinetica Qca - Laboratorio 2C 2021 - FinalaleinAún no hay calificaciones
- TP2-Termodinámica - Laboratorio 2C 2021Documento7 páginasTP2-Termodinámica - Laboratorio 2C 2021aleinAún no hay calificaciones
- Guia para La Elaboracion de Un Esquema de Trabajo PDFDocumento7 páginasGuia para La Elaboracion de Un Esquema de Trabajo PDFMarcos IllescasAún no hay calificaciones
- Ejer Cici OsDocumento14 páginasEjer Cici OsFlor DuarteAún no hay calificaciones
- 2021 - 2C - Laboratorio - Redox y Eq. SolubilidadDocumento13 páginas2021 - 2C - Laboratorio - Redox y Eq. SolubilidadaleinAún no hay calificaciones
- 2021 - 2C - Laboratorio - AcidoBase - FinalDocumento9 páginas2021 - 2C - Laboratorio - AcidoBase - FinalaleinAún no hay calificaciones
- Apunte de Estados de Oxidación y Nomenclatura de Compuestos InorgánicosDocumento12 páginasApunte de Estados de Oxidación y Nomenclatura de Compuestos InorgánicosaleinAún no hay calificaciones
- Proyecto Matematicas2 - Semana32 31-10 de Junio 2022Documento22 páginasProyecto Matematicas2 - Semana32 31-10 de Junio 2022Tonatzin RizoAún no hay calificaciones
- Ortiz Maria CBCEESTAJUS U2 T1Documento6 páginasOrtiz Maria CBCEESTAJUS U2 T1María Caridad Ortiz IdrovoAún no hay calificaciones
- Practica 1Documento7 páginasPractica 1Karly AlanocaAún no hay calificaciones
- Actividad2 - Estadística para Negocios SofiaDocumento6 páginasActividad2 - Estadística para Negocios SofiaKatty RamirezAún no hay calificaciones
- Tarea 2Documento3 páginasTarea 2EDGAR BARRENOAún no hay calificaciones
- eJEMPLOS PASO PASO DE CALCULO DE MEDIDAS DE POSICIONDocumento13 páginaseJEMPLOS PASO PASO DE CALCULO DE MEDIDAS DE POSICIONEmiliano NuñezAún no hay calificaciones
- Informe de Distribucion Bidimencional de Dos Variables - EstadisticaDocumento35 páginasInforme de Distribucion Bidimencional de Dos Variables - EstadisticaRoberth VillafuerteAún no hay calificaciones
- TAREA#5Documento4 páginasTAREA#5Javier VinuezaAún no hay calificaciones
- TRABAJO PRACTICO DE MATEMATICA Nahuel Lazaro Aguirre 6bDocumento4 páginasTRABAJO PRACTICO DE MATEMATICA Nahuel Lazaro Aguirre 6bNahuel AguirreAún no hay calificaciones
- Toma de Decisiones y Juego Gerencial - EjerciciosDocumento7 páginasToma de Decisiones y Juego Gerencial - EjerciciosEDY JOHANNA ROMEROAún no hay calificaciones
- Actividad Formativa 2 - Cuadro. Yisleidy Carrillo Psicologia-1er TrimestreDocumento4 páginasActividad Formativa 2 - Cuadro. Yisleidy Carrillo Psicologia-1er TrimestreYisleidy CarrilloAún no hay calificaciones
- EJERCICIO REGRESIÓN LINEAL MULTIPLE (Francisco)Documento11 páginasEJERCICIO REGRESIÓN LINEAL MULTIPLE (Francisco)Neko ChiroiAún no hay calificaciones
- Segundo ParcialDocumento6 páginasSegundo ParcialKELLY MISHEL NARVÁEZ VEGAAún no hay calificaciones
- Cuestionario 2 Probabilidad y Estadística C2-22Documento5 páginasCuestionario 2 Probabilidad y Estadística C2-22Luis MoraAún no hay calificaciones
- Formulas de Inferencia EstadisticaDocumento3 páginasFormulas de Inferencia EstadisticaloveyaAún no hay calificaciones
- Clase - 08 Prob y EstadisticaDocumento18 páginasClase - 08 Prob y Estadisticasarkromeo187Aún no hay calificaciones
- Estadistica Datos No Agrupados EjerciciosDocumento11 páginasEstadistica Datos No Agrupados EjerciciosKarely Michell Torres ArévaloAún no hay calificaciones
- Introduccion Al Minitab Ii ParcialDocumento35 páginasIntroduccion Al Minitab Ii Parcialkeren martinezAún no hay calificaciones
- C4 Medidas de Posición y Dispersión IIDocumento12 páginasC4 Medidas de Posición y Dispersión IIEdgardo Palma WaldronAún no hay calificaciones
- Ficha Refuerzo Tabla de Distribucion de FrecuenciasDocumento1 páginaFicha Refuerzo Tabla de Distribucion de Frecuenciasruby floresAún no hay calificaciones
- Medidas de Dispersión Datos AgrupadosDocumento9 páginasMedidas de Dispersión Datos AgrupadosRicardo CentenoAún no hay calificaciones
- 25octubrefase 3 EstadisticaDocumento15 páginas25octubrefase 3 EstadisticaJLOAún no hay calificaciones
- Estadistica RealizadoDocumento2 páginasEstadistica RealizadoDarnis RiveraAún no hay calificaciones
- Taller 1 de RiesgoDocumento18 páginasTaller 1 de RiesgoDaniel CaleroAún no hay calificaciones
- Variograma 2DDocumento36 páginasVariograma 2Dbryan salazar delgadoAún no hay calificaciones
- Tabla de Distribucion de Frecuencias para Datos No AgrupadosDocumento2 páginasTabla de Distribucion de Frecuencias para Datos No Agrupadoskeisy kimberAún no hay calificaciones
- Práctica Nº3 - Precipitación MediaDocumento10 páginasPráctica Nº3 - Precipitación MediaJoe BustamanteAún no hay calificaciones
- TRABAJO FINAL - EDYPdDocumento53 páginasTRABAJO FINAL - EDYPdELIZABETH COAGUILA AÑARIAún no hay calificaciones