También podría gustarte
- Modelo Informe PsicologicoDocumento3 páginasModelo Informe PsicologicoFabian Schiaffino85% (13)
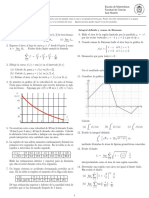
- Metodos NumericosDocumento10 páginasMetodos NumericosJordy Jimenez InfantesAún no hay calificaciones
- Ejercicios Resueltos Scilab PDFDocumento32 páginasEjercicios Resueltos Scilab PDFCarlosAntonioSanchezArias100% (1)
- Caso Clinico Desde El Enfoque Humanista 7 Semestre PsicologiaDocumento10 páginasCaso Clinico Desde El Enfoque Humanista 7 Semestre PsicologiaAngieAún no hay calificaciones
- Manual de Descripcion de Puestos y Funciones para Jefaturas Del IHSSDocumento339 páginasManual de Descripcion de Puestos y Funciones para Jefaturas Del IHSSManuel Mejia100% (1)
- Deber N 1Documento3 páginasDeber N 1Cristina AcostaAún no hay calificaciones
- Estimacion de Maxima Verosimilitud RDocumento6 páginasEstimacion de Maxima Verosimilitud RJaviera Catalina PinoAún no hay calificaciones
- Numericos Newton NUEVODocumento7 páginasNumericos Newton NUEVOnatt takahashiAún no hay calificaciones
- Tarea1 PDFDocumento28 páginasTarea1 PDFCamila Solange Soto RAún no hay calificaciones
- TP4 2006 PDFDocumento8 páginasTP4 2006 PDFhejuradoAún no hay calificaciones
- Taller Splines y Diferenciación NuméricaDocumento3 páginasTaller Splines y Diferenciación NuméricaJuan David Granja GarcesAún no hay calificaciones
- Examen Preparatorio 2021 2 BDocumento6 páginasExamen Preparatorio 2021 2 BandreaAún no hay calificaciones
- Maria Camila LeonDocumento17 páginasMaria Camila LeonAngieAún no hay calificaciones
- (CInt - 2019.01) Taller 01Documento2 páginas(CInt - 2019.01) Taller 01dragonshyruAún no hay calificaciones
- Metodos NuméricosDocumento26 páginasMetodos NuméricosPedro LpAún no hay calificaciones
- Cuadratura NuméricaDocumento11 páginasCuadratura Numéricajohan enrique aranda casasAún no hay calificaciones
- Catálogo de Métodos Numéricos - Olga González Alvarado (2016) PDFDocumento58 páginasCatálogo de Métodos Numéricos - Olga González Alvarado (2016) PDFJosé Luis Haro VeraAún no hay calificaciones
- Solución Tarea 3 PDFDocumento11 páginasSolución Tarea 3 PDFVictoria Lucia Carmona Mota100% (1)
- Estim Gammacastellano EgelaDocumento5 páginasEstim Gammacastellano EgelakaiangelAún no hay calificaciones
- INFORME 1-López Lazo Bruno-17190158Documento26 páginasINFORME 1-López Lazo Bruno-17190158BruNo LopezAún no hay calificaciones
- Apuntes Sucesiones La SalleDocumento3 páginasApuntes Sucesiones La SalleAcademia Al CuadradoAún no hay calificaciones
- 1MAT07 2023 2 Lista 3Documento3 páginas1MAT07 2023 2 Lista 3italosalazarparedesAún no hay calificaciones
- Metodos NumericosDocumento4 páginasMetodos NumericosLaura Maria Carranza CabraAún no hay calificaciones
- Deber Métodos NuméricosDocumento3 páginasDeber Métodos NuméricosChristian Galarza CruzAún no hay calificaciones
- Regla Del Trapecio InformeDocumento7 páginasRegla Del Trapecio Informealejandro.david1642Aún no hay calificaciones
- Funciones Continuas EspecialesDocumento4 páginasFunciones Continuas EspecialesNiccole MejíaAún no hay calificaciones
- Regresión Lineal - PybonacciDocumento18 páginasRegresión Lineal - PybonacciVictoria Loza BastoAún no hay calificaciones
- Scipy - Guia de ReferenciaDocumento11 páginasScipy - Guia de Referenciajoel js gomez alanocaAún no hay calificaciones
- Soluciones Libro de Algebra LinealDocumento34 páginasSoluciones Libro de Algebra LinealMauricio SalazarAún no hay calificaciones
- Método de Simpson 1 - 3 OCTAVEDocumento5 páginasMétodo de Simpson 1 - 3 OCTAVEhgygggggyhh0% (1)
- V24 1 1giraldo CokrigingDocumento12 páginasV24 1 1giraldo CokrigingedmundoAún no hay calificaciones
- Métodos BootstrapDocumento16 páginasMétodos BootstrapJhon Glidden ÑacataAún no hay calificaciones
- Informe LAB 6Documento6 páginasInforme LAB 6danielfuentesgarcia19Aún no hay calificaciones
- Listaparcial 3Documento4 páginasListaparcial 3Mark EstradaAún no hay calificaciones
- Simulación Series de FourierDocumento6 páginasSimulación Series de FourierJosé Holgado RamirezAún no hay calificaciones
- Licenciatura en Automatización y Robótica Procesamiento de Señales e Imágenes 2022 Trabajo Práctico 2 Alumno: (Juan Manuel Hornia)Documento12 páginasLicenciatura en Automatización y Robótica Procesamiento de Señales e Imágenes 2022 Trabajo Práctico 2 Alumno: (Juan Manuel Hornia)Sebastián HerreraAún no hay calificaciones
- Taller 01 (Clases 1-2)Documento2 páginasTaller 01 (Clases 1-2)Lucas roldanAún no hay calificaciones
- Sesion 2 - Interpolacion Diferenciable y Polinomios Ortogonales (Matlab)Documento38 páginasSesion 2 - Interpolacion Diferenciable y Polinomios Ortogonales (Matlab)Hernan Caviedes ManzanoAún no hay calificaciones
- ADA 3, Gráficas Con Matlab ResueltaDocumento17 páginasADA 3, Gráficas Con Matlab ResueltaAaron Solis MonteroAún no hay calificaciones
- Matlab Transformada ZDocumento7 páginasMatlab Transformada ZJ.A. CalvilloAún no hay calificaciones
- Análisis I 2019 - TP 0Documento7 páginasAnálisis I 2019 - TP 0lautiAún no hay calificaciones
- Unidad 5Documento7 páginasUnidad 5Kio Vergara Beltrán100% (1)
- Informe - Tema 01Documento36 páginasInforme - Tema 01Raul Depaz NuñezAún no hay calificaciones
- Ejercicio 1DDocumento12 páginasEjercicio 1DJesusAún no hay calificaciones
- Practica 3Documento8 páginasPractica 3AlfonsoJimenezAún no hay calificaciones
- Practicas Lab1Documento5 páginasPracticas Lab1Jarixander Perez RomeroAún no hay calificaciones
- 00 00 Problemario CalculoDocumento41 páginas00 00 Problemario Calculojuliho.castilloAún no hay calificaciones
- Problema 1Documento19 páginasProblema 1CynthiaJoAún no hay calificaciones
- Estim Beta ES EgelaDocumento4 páginasEstim Beta ES EgelakaiangelAún no hay calificaciones
- Practica7 2C22Documento5 páginasPractica7 2C22Santiago GarciaAún no hay calificaciones
- PR 4Documento5 páginasPR 4Juan Bosco García GutiérrezAún no hay calificaciones
- Natalia SanchezDocumento28 páginasNatalia SanchezAngieAún no hay calificaciones
- Guias Parte2Documento63 páginasGuias Parte2axlhellfish666Aún no hay calificaciones
- Ejercicios Impares Seccion 4.6Documento3 páginasEjercicios Impares Seccion 4.6Joss DlcruzAún no hay calificaciones
- Pre MatematicaDocumento18 páginasPre MatematicaGarcia Karol100% (1)
- Laboratorio 2Documento2 páginasLaboratorio 2Keytel Tarmeño QuispeAún no hay calificaciones
- Clase3 2 28Documento27 páginasClase3 2 28ricardoAún no hay calificaciones
- Apunte MD2020Documento39 páginasApunte MD2020JUAN ANTONIO EYZAGUIRRE ABARZUAAún no hay calificaciones
- Integración NuméricaDocumento18 páginasIntegración NuméricaGilberto BaltazarAún no hay calificaciones
- Hoja 4 ADMDocumento11 páginasHoja 4 ADMMaría Vargas MagánAún no hay calificaciones
- Trabajo Investigacion AngieDocumento6 páginasTrabajo Investigacion AngieAngieAún no hay calificaciones
- Desafío 8 Vinculación de La Investigación y La Práctica en Las IntervencionesDocumento3 páginasDesafío 8 Vinculación de La Investigación y La Práctica en Las IntervencionesAngieAún no hay calificaciones
- Cuadro Comparativo Psicoanálisis OrtodoxoDocumento5 páginasCuadro Comparativo Psicoanálisis OrtodoxoAngieAún no hay calificaciones
- Informe Final Modelos de Intervencion 1Documento12 páginasInforme Final Modelos de Intervencion 1AngieAún no hay calificaciones
- Como Fue La Definición Del TemaDocumento1 páginaComo Fue La Definición Del TemaAngieAún no hay calificaciones
- Cognitivo ConductualDocumento2 páginasCognitivo ConductualAngieAún no hay calificaciones
- Caso Modelo Cognitivo ConductualDocumento9 páginasCaso Modelo Cognitivo ConductualAngie100% (1)
- Cronograma de TratamientoDocumento1 páginaCronograma de TratamientoAngieAún no hay calificaciones
- Caso NinaDocumento9 páginasCaso NinaAngieAún no hay calificaciones
- Consentimientos InformadosDocumento3 páginasConsentimientos InformadosAngieAún no hay calificaciones
- Caso SicodinamicoDocumento3 páginasCaso Sicodinamicomariana50% (4)
- Caso Clinico Desde El Enfoque Humanista 7 Semestre PsicologiaDocumento11 páginasCaso Clinico Desde El Enfoque Humanista 7 Semestre PsicologiaAngie100% (2)
- Grupo CamilaDocumento3 páginasGrupo CamilaAngieAún no hay calificaciones
- Informe PedagógicoDocumento4 páginasInforme PedagógicoAngieAún no hay calificaciones
- Actividad 1Documento2 páginasActividad 1AngieAún no hay calificaciones
- Generalidades Del Informe PsicpedagogicoDocumento1 páginaGeneralidades Del Informe PsicpedagogicoAngieAún no hay calificaciones
- Taller Final - Ecuación Lineal - Angie Lizeth Gomez GranadaDocumento7 páginasTaller Final - Ecuación Lineal - Angie Lizeth Gomez GranadaAngieAún no hay calificaciones
- Infome Psicologico CognitivoDocumento12 páginasInfome Psicologico CognitivoAngieAún no hay calificaciones
- Analisis 16 PF A Compañera Kelly RaigozaDocumento10 páginasAnalisis 16 PF A Compañera Kelly RaigozaAngieAún no hay calificaciones
- Cuadro SinopticoDocumento4 páginasCuadro SinopticoAngieAún no hay calificaciones
- Solucion de Ejercicios de Sumas y Restas de PolinomiosDocumento4 páginasSolucion de Ejercicios de Sumas y Restas de PolinomiosAngieAún no hay calificaciones
- Foro Sobre El Modelo SistémicoDocumento2 páginasForo Sobre El Modelo SistémicoAngieAún no hay calificaciones
- Alternativas para La Resolución de ConflictosDocumento7 páginasAlternativas para La Resolución de ConflictosAngieAún no hay calificaciones
- Los Colores de La MontañaDocumento3 páginasLos Colores de La MontañaAngieAún no hay calificaciones
- Análisis Sobre Latinoamérica Discursos, Problemáticas e Intervenciones PosiblesDocumento6 páginasAnálisis Sobre Latinoamérica Discursos, Problemáticas e Intervenciones PosiblesAngieAún no hay calificaciones
- Actividades para Esta SemanaDocumento7 páginasActividades para Esta SemanaAngieAún no hay calificaciones
- Operaciones Con Entereos y FraccionariosDocumento4 páginasOperaciones Con Entereos y FraccionariosAngieAún no hay calificaciones
- Foro LomboDocumento1 páginaForo LomboAngieAún no hay calificaciones
- TRABAJO LubricantesDocumento9 páginasTRABAJO LubricantesMaria TeresaAún no hay calificaciones
- CUESTIONARIODocumento2 páginasCUESTIONARIOGerardo Alexander Azañero AlaniaAún no hay calificaciones
- ARTP Carga y Transporte de Salmuera Débil y Concentrada PDFDocumento5 páginasARTP Carga y Transporte de Salmuera Débil y Concentrada PDFRoberto Marín FuentesAún no hay calificaciones
- Nivel IV - TP Nro 5 - Laminas Sinclasticas - Paraboloide Eliptico PDFDocumento8 páginasNivel IV - TP Nro 5 - Laminas Sinclasticas - Paraboloide Eliptico PDFRASTAFARIAún no hay calificaciones
- Evaluacion de Inteligencia Tarea 5Documento4 páginasEvaluacion de Inteligencia Tarea 5ElaineAún no hay calificaciones
- Caso GISA y Tacos Bell 2Documento7 páginasCaso GISA y Tacos Bell 2Marcia Esparza CancinoAún no hay calificaciones
- Anteproyecto MetodologíaDocumento53 páginasAnteproyecto MetodologíaCAMILA COBOS MOLANOAún no hay calificaciones
- Hidrovía Amazónica-Estudio Exploratorio de La Situación SocialDocumento28 páginasHidrovía Amazónica-Estudio Exploratorio de La Situación SocialJose MejiaAún no hay calificaciones
- Impacto de La Tecnología en La MedicinaDocumento6 páginasImpacto de La Tecnología en La Medicinaxavier fonAún no hay calificaciones
- Clase TorneadoDocumento72 páginasClase Torneadojuan carlos100% (1)
- Componentes Del Aprendizaje:: Descripción de La ActividadDocumento5 páginasComponentes Del Aprendizaje:: Descripción de La Actividadisrael idrovoAún no hay calificaciones
- Parciales - Análisis de Circuitos I (1) UNIVERSIDAD DISTRITAL PDFDocumento5 páginasParciales - Análisis de Circuitos I (1) UNIVERSIDAD DISTRITAL PDFDeiVy GutierrezAún no hay calificaciones
- Ahorro de EnergiaDocumento33 páginasAhorro de EnergiaChristian Daniel ViveroAún no hay calificaciones
- Ladriillera El Diamante - Docx FINALLLLLDocumento26 páginasLadriillera El Diamante - Docx FINALLLLLJulio Cesar Cruz Trelles50% (2)
- Estudio de Intenciones de Emprendimiento en Jóvenes Universitarios Del Valle de Toluca, Antes Y Después de La Pandemia Covid-19Documento8 páginasEstudio de Intenciones de Emprendimiento en Jóvenes Universitarios Del Valle de Toluca, Antes Y Después de La Pandemia Covid-19ERLI CAMILA HIDALGO SANCHEZAún no hay calificaciones
- Teoria de SistemasDocumento72 páginasTeoria de SistemasPedro PykAún no hay calificaciones
- Dominguez MendozaDocumento14 páginasDominguez Mendozadiego dominguezAún no hay calificaciones
- Actividades ElectricidadDocumento3 páginasActividades Electricidadrra955388Aún no hay calificaciones
- 2 Llan Mirage 195/75 R16 MR200 308,404 616,807Documento1 página2 Llan Mirage 195/75 R16 MR200 308,404 616,807ADRIANA MORAAún no hay calificaciones
- 20 01 Ing - B1 - Procoto - SepDocumento26 páginas20 01 Ing - B1 - Procoto - SepÓscar NavarroAún no hay calificaciones
- Icap Inventario para La Planificacion de Servicios y Programacion IndividualDocumento19 páginasIcap Inventario para La Planificacion de Servicios y Programacion IndividualJUAN ORDOÑEZAún no hay calificaciones
- Tipos de OrganizaciónDocumento3 páginasTipos de OrganizaciónBrian DíazAún no hay calificaciones
- Modificación de La Composición CorporalDocumento64 páginasModificación de La Composición CorporalJose Carlos Oyola Sanchez100% (1)
- Razonamiento Verbal - UNMSMDocumento8 páginasRazonamiento Verbal - UNMSMLuis Alberto Mendoza Salas100% (1)
- Informe de Celos Redaccion Psicologica PDFDocumento14 páginasInforme de Celos Redaccion Psicologica PDFFran Núñez100% (1)
- Alteraciones AfectivasDocumento8 páginasAlteraciones AfectivasOrson RobertoAún no hay calificaciones
- CaudalDocumento3 páginasCaudalCristian PaoloAún no hay calificaciones
- Aspectos Positivos de La MarihuanaDocumento9 páginasAspectos Positivos de La MarihuanaAlberto CoitiñoAún no hay calificaciones
- Mexico y Sus ProblemasDocumento1 páginaMexico y Sus ProblemasangelAún no hay calificaciones