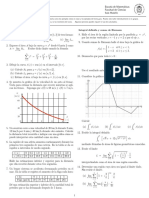
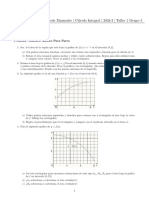
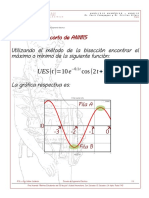
También podría gustarte
- Estim Beta ES EgelaDocumento4 páginasEstim Beta ES EgelakaiangelAún no hay calificaciones
- Guia 13 VerosimilitudDocumento2 páginasGuia 13 VerosimilitudJosé Eduardo Chávez CabanillasAún no hay calificaciones
- Comandos de R PDFDocumento4 páginasComandos de R PDFByron Carrion LmAún no hay calificaciones
- AnalisisMultivariado Tarea 2 2021 1Documento2 páginasAnalisisMultivariado Tarea 2 2021 1jresendiznAún no hay calificaciones
- Examen Ordinario 2020 2021Documento2 páginasExamen Ordinario 2020 2021Rodrigo PérezAún no hay calificaciones
- Isc03 Lab1Documento6 páginasIsc03 Lab1Lucas Velazquez Gordillo0% (1)
- Regresion Lineal (Metodo Minimos Cuadrados)Documento8 páginasRegresion Lineal (Metodo Minimos Cuadrados)Charles Zambrano0% (1)
- Ayudant Ia 4: 1. Regresi On MultivariadaDocumento5 páginasAyudant Ia 4: 1. Regresi On MultivariadaJavier AlvarezAún no hay calificaciones
- SergioSuarez ExtempDocumento17 páginasSergioSuarez ExtempAngieAún no hay calificaciones
- Derivada Parte 2Documento8 páginasDerivada Parte 2Camila De Los SantosAún no hay calificaciones
- Tarea 1Documento3 páginasTarea 1starwars172003Aún no hay calificaciones
- Estimacion de Maxima Verosimilitud RDocumento6 páginasEstimacion de Maxima Verosimilitud RJaviera Catalina PinoAún no hay calificaciones
- Valores Propios TransformacionesDocumento11 páginasValores Propios TransformacionesJuan Carlos AvilaAún no hay calificaciones
- ACFrOgDsc9jWcACzvs6hY7BYV6s jePMzkrb95b8q 6cG9HyWEn7kycyi5vUm2YcmtYfHqV0GfxbDmd3D8nrS3xVh JXP ACZTHlMBueduyKVmxu84lzrRSLNDsIRO4qwpF2eeIz2ui3LqBogRpODocumento5 páginasACFrOgDsc9jWcACzvs6hY7BYV6s jePMzkrb95b8q 6cG9HyWEn7kycyi5vUm2YcmtYfHqV0GfxbDmd3D8nrS3xVh JXP ACZTHlMBueduyKVmxu84lzrRSLNDsIRO4qwpF2eeIz2ui3LqBogRpONICOL YAJAIRA GONZALEZ MENESESAún no hay calificaciones
- Contenido Activador Unidad 3 EconometríaDocumento22 páginasContenido Activador Unidad 3 Econometríaalmendra4943Aún no hay calificaciones
- Practica 2Documento4 páginasPractica 2José Eduardo Chávez CabanillasAún no hay calificaciones
- Informe N°2 Fisica 1Documento13 páginasInforme N°2 Fisica 1Denis Rodas GutierrezAún no hay calificaciones
- Tema 4 EjerciciosDocumento3 páginasTema 4 Ejerciciosmkarygames22Aún no hay calificaciones
- Statistical Mechanics PDFDocumento10 páginasStatistical Mechanics PDFpedro pablo rosario vargasAún no hay calificaciones
- Ordinario MatematicasI-2021-22Documento1 páginaOrdinario MatematicasI-2021-22hugotorrecillasaenz12Aún no hay calificaciones
- CL1 2022 Practico 12 IntegralesIIDocumento5 páginasCL1 2022 Practico 12 IntegralesII业余SanSebAún no hay calificaciones
- Semana 3 Mod Mat EcoDocumento16 páginasSemana 3 Mod Mat EcoFox JoshuaAún no hay calificaciones
- Apuntes Profesor Juan Ignacio PadillaDocumento144 páginasApuntes Profesor Juan Ignacio PadillaLuisAún no hay calificaciones
- Integración Por Monte CarloDocumento22 páginasIntegración Por Monte CarloJobs29Aún no hay calificaciones
- Talle 1 Topologia RN Funciones ContinuasDocumento2 páginasTalle 1 Topologia RN Funciones ContinuasDavid EinsteinAún no hay calificaciones
- Wuolah Free Examen Ordinaria 2023 ResueltoDocumento4 páginasWuolah Free Examen Ordinaria 2023 ResueltoAlbertoAún no hay calificaciones
- Examen de Estadística ComputacionalDocumento21 páginasExamen de Estadística ComputacionalLopez S DalilaAún no hay calificaciones
- Examen Preparatorio 2021 2 BDocumento6 páginasExamen Preparatorio 2021 2 BandreaAún no hay calificaciones
- Cálculo Numérico - Elementos de Cálculo Numérico - Recuperatorio Del Segundo ParcialDocumento2 páginasCálculo Numérico - Elementos de Cálculo Numérico - Recuperatorio Del Segundo ParcialChesse GodAún no hay calificaciones
- Guia FVV PDFDocumento11 páginasGuia FVV PDFFelipe R RodriguezAún no hay calificaciones
- TEMA 2 Vectores 2018 19Documento13 páginasTEMA 2 Vectores 2018 19Isaac Sanchis SoleraAún no hay calificaciones
- (CInt - 2019.01) Taller 01Documento2 páginas(CInt - 2019.01) Taller 01dragonshyruAún no hay calificaciones
- Cálculo de Integrales de Funciones Expresadas Como Series de TaylorDocumento5 páginasCálculo de Integrales de Funciones Expresadas Como Series de TaylorKeyti Astrea CisnerosAún no hay calificaciones
- Clase 1 InterpolaciónDocumento21 páginasClase 1 InterpolaciónarturoAún no hay calificaciones
- Problemas de Cálculo Diferencial e Integral PDFDocumento526 páginasProblemas de Cálculo Diferencial e Integral PDFJorge100% (3)
- Cálculo (1º Bloque Enero 1819) - G. I. Aeroespacial en V. A PDFDocumento1 páginaCálculo (1º Bloque Enero 1819) - G. I. Aeroespacial en V. A PDFAlicia LopezAún no hay calificaciones
- Lab04 521230 2018 PDFDocumento10 páginasLab04 521230 2018 PDFAndres LAún no hay calificaciones
- Sol Ef CF2C1 2022 2Documento7 páginasSol Ef CF2C1 2022 2Julcam IndustriasAún no hay calificaciones
- SimpsonDocumento3 páginasSimpsonDavid Eccoña CastilloAún no hay calificaciones
- Examen Matemáticas I Ingeniería MecánicaDocumento1 páginaExamen Matemáticas I Ingeniería MecánicacarmenAún no hay calificaciones
- Pasos para La Regresion Logistica en SPSSDocumento7 páginasPasos para La Regresion Logistica en SPSSYamir EncarnacionAún no hay calificaciones
- GUICEG065EM32-A17V1 Función Potencia - PRO PDFDocumento16 páginasGUICEG065EM32-A17V1 Función Potencia - PRO PDFPamela Loren ArriagadaAún no hay calificaciones
- Guía #5 Función Cuadrática y ExponencialDocumento9 páginasGuía #5 Función Cuadrática y ExponencialAndyAún no hay calificaciones
- BiugigDocumento3 páginasBiugigAlex DiazAún no hay calificaciones
- Bma01 PD6 2019 2Documento3 páginasBma01 PD6 2019 2Jose CarlosAún no hay calificaciones
- 2 AplicacionesDocumento3 páginas2 AplicacionesNicolette BelenAún no hay calificaciones
- Taller1integral 2024Documento4 páginasTaller1integral 2024estorosAún no hay calificaciones
- Resumen Cálculo Vectorial 2019B EPNDocumento69 páginasResumen Cálculo Vectorial 2019B EPNKAGGHGAún no hay calificaciones
- Resumen Cálculo Vectorial 2019A EPNDocumento88 páginasResumen Cálculo Vectorial 2019A EPNKAGGHGAún no hay calificaciones
- 114 6 13052015231314 PDFDocumento37 páginas114 6 13052015231314 PDFEdwin Alonso Guevara BecerraAún no hay calificaciones
- Integrales Dobles y TriplesDocumento34 páginasIntegrales Dobles y TriplesEdy Christian Chaupin MejiaAún no hay calificaciones
- TP4 2006 PDFDocumento8 páginasTP4 2006 PDFhejuradoAún no hay calificaciones
- UIOPOSTERDocumento1 páginaUIOPOSTERJulio PerezAún no hay calificaciones
- 2 - X - 5.°uni TDocumento64 páginas2 - X - 5.°uni TMarcelo AZBAún no hay calificaciones
- Tarea 2Documento5 páginasTarea 2Aleja CoronadoAún no hay calificaciones
- Deber N 1Documento3 páginasDeber N 1Cristina AcostaAún no hay calificaciones
- HW 02Documento3 páginasHW 02Alonso CasanovaAún no hay calificaciones
- Ejercicio de Clasificacion de Series Con TaylorDocumento2 páginasEjercicio de Clasificacion de Series Con Taylorshirley mendezAún no hay calificaciones
- Las Garantías Constitucionales en El PerúDocumento3 páginasLas Garantías Constitucionales en El PerúkaiangelAún no hay calificaciones
- La DemocraciaDocumento4 páginasLa DemocraciakaiangelAún no hay calificaciones
- 10 Principios de Economia de MankiwDocumento4 páginas10 Principios de Economia de MankiwkaiangelAún no hay calificaciones
- Cartel de La Problemática Pedagógica InstitucionalDocumento2 páginasCartel de La Problemática Pedagógica InstitucionalkaiangelAún no hay calificaciones
- La Educacion en El Peru de Hoy SDocumento2 páginasLa Educacion en El Peru de Hoy SkaiangelAún no hay calificaciones
- Mapas ConceptualesDocumento5 páginasMapas ConceptualesHildorien50% (2)
- Cultura de PazDocumento3 páginasCultura de PazkaiangelAún no hay calificaciones
- Cartel de La Problemática Pedagógica InstitucionalDocumento2 páginasCartel de La Problemática Pedagógica InstitucionalkaiangelAún no hay calificaciones
- Propuesta de GestiónDocumento6 páginasPropuesta de GestiónkaiangelAún no hay calificaciones
- El Valor Pedagógico de Un Aula y Un AuditorioDocumento2 páginasEl Valor Pedagógico de Un Aula y Un AuditoriokaiangelAún no hay calificaciones
- Plan de Trabajo Aniversario 2013Documento4 páginasPlan de Trabajo Aniversario 2013kaiangel76% (17)
- Conductismo y ConstructivismoDocumento6 páginasConductismo y ConstructivismoYesenia Merida AriasAún no hay calificaciones
- La Educacion en El Peru de Hoy SDocumento2 páginasLa Educacion en El Peru de Hoy SkaiangelAún no hay calificaciones
- La Importancia de Las Estrategias de AulaDocumento9 páginasLa Importancia de Las Estrategias de AulakaiangelAún no hay calificaciones
- Libro de Metodologia de La InvestigaciónDocumento96 páginasLibro de Metodologia de La Investigacióndam810% (1)
- La Importancia de Las Estrategias de AulaDocumento9 páginasLa Importancia de Las Estrategias de AulakaiangelAún no hay calificaciones
- Samuel Morse Nació en CharlestownDocumento2 páginasSamuel Morse Nació en CharlestownkaiangelAún no hay calificaciones
- Los Problemas de La EducaciónDocumento2 páginasLos Problemas de La EducaciónkaiangelAún no hay calificaciones
- Primer Bloque-EconometriaDocumento12 páginasPrimer Bloque-EconometriaYenifer LeonAún no hay calificaciones
- Resumen de PolinomiosDocumento3 páginasResumen de PolinomiosJAIME ANDRÉS SAUÑI ESPIRITUAún no hay calificaciones
- Segunda Ley de La TermodinámicaDocumento6 páginasSegunda Ley de La TermodinámicaValeria Michelle Villagrana AlvaradoAún no hay calificaciones
- S07.s1 - Material-Distribución Binomial y PoissonDocumento24 páginasS07.s1 - Material-Distribución Binomial y PoissonDaniel MontalbanAún no hay calificaciones
- DiabloDocumento18 páginasDiabloJoel CastilloAún no hay calificaciones
- Clase PEDocumento11 páginasClase PESEBASTIAN AARON SAAVEDRA GUTIÉRREZAún no hay calificaciones
- 05.1 Sistemas DinamicosDocumento4 páginas05.1 Sistemas DinamicosjavierAún no hay calificaciones
- Lab 2Documento16 páginasLab 2MauroHerreraAún no hay calificaciones
- Capítulo 6 AplicacionesDocumento18 páginasCapítulo 6 AplicacionesPablo Jesús Rosales J.Aún no hay calificaciones
- Tarea 4 - 2020 2Documento2 páginasTarea 4 - 2020 2Edna Dayana Guerrero ArevaloAún no hay calificaciones
- 3.4 Anulador Parte 3Documento16 páginas3.4 Anulador Parte 3ingeniero.saban22803Aún no hay calificaciones
- Proceso de Firma DigitalDocumento30 páginasProceso de Firma Digitalrobinson100% (1)
- Ejemplo Del Método SimplexDocumento3 páginasEjemplo Del Método Simplexyamileth colinaAún no hay calificaciones
- Unidad 2 Etapa 2 - Modelar El Sistema Dinámico en El Dominio de La FrecuenciaDocumento8 páginasUnidad 2 Etapa 2 - Modelar El Sistema Dinámico en El Dominio de La Frecuenciamarcos andres nieves gulloAún no hay calificaciones
- Yennis Entrega de GrestionDocumento28 páginasYennis Entrega de GrestionJose VillaAún no hay calificaciones
- Ejercicios de Teoria de Inventarios31Documento4 páginasEjercicios de Teoria de Inventarios31Jacobo VillaAún no hay calificaciones
- Circuito Hamiltoniano Dirigido y No-DirigidoDocumento2 páginasCircuito Hamiltoniano Dirigido y No-Dirigidorolando_condor_61408Aún no hay calificaciones
- Observadores de EstadoDocumento12 páginasObservadores de EstadoDerlis RomeroAún no hay calificaciones
- Metodos NumericosDocumento17 páginasMetodos NumericosAngel Gabriel Ramirez BautistaAún no hay calificaciones
- DividirYConquistr 1x1Documento118 páginasDividirYConquistr 1x1Lic Rodriguez Mejia LeonnyAún no hay calificaciones
- Algebra (Potencia, Radicacion, Ecuaciones Exponenciales, Polinomios y Productos Notables)Documento4 páginasAlgebra (Potencia, Radicacion, Ecuaciones Exponenciales, Polinomios y Productos Notables)Lizbeth BorjaAún no hay calificaciones
- Tema2 Parte2Documento5 páginasTema2 Parte2Ben A CogerAún no hay calificaciones
- SPOILER Examenes de ANN115 - 2017 - EntregarDocumento6 páginasSPOILER Examenes de ANN115 - 2017 - EntregarVladi GuevaraAún no hay calificaciones
- Informe de Los Métodos de Punto Fijo y SecanteDocumento6 páginasInforme de Los Métodos de Punto Fijo y SecanteKriz LojanoAún no hay calificaciones
- Interpretación La Definición de MSRDocumento7 páginasInterpretación La Definición de MSRKarelys CetrangoloAún no hay calificaciones
- Reyes - Carlos Actividad #8Documento14 páginasReyes - Carlos Actividad #8CARLOS DIONISIO REYES AYALAAún no hay calificaciones
- Prueba y Error PresentacionDocumento14 páginasPrueba y Error Presentacionrobert19864Aún no hay calificaciones
- Guia 4Documento5 páginasGuia 4Marco AndréeAún no hay calificaciones
- Act. Reporte 3 "Algoritmos Recursivos".Documento7 páginasAct. Reporte 3 "Algoritmos Recursivos".Dylan Ovalle GarciaAún no hay calificaciones
- Interpolación de Newton y LagrangeDocumento12 páginasInterpolación de Newton y LagrangeAlberto OlivaresAún no hay calificaciones