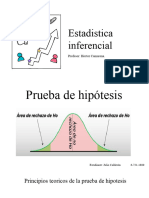
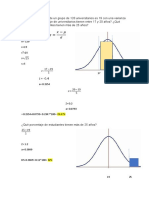
También podría gustarte
- Estadística para veterinarios y zootecnistasDe EverandEstadística para veterinarios y zootecnistasCalificación: 5 de 5 estrellas5/5 (1)
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- GRUPAL Estadistica Unidad 2 Tarea3Documento29 páginasGRUPAL Estadistica Unidad 2 Tarea3ximena sarmientoAún no hay calificaciones
- Actividades Unidad TresDocumento5 páginasActividades Unidad TresShadey Lineth Peralta CordovaAún no hay calificaciones
- Investigacion de Prueba de Hipotesis PDFDocumento32 páginasInvestigacion de Prueba de Hipotesis PDFJOSE BERNALDO TUM TIUAún no hay calificaciones
- Ensayo Estadistica InferencialDocumento16 páginasEnsayo Estadistica InferencialKarl Troublee Tesse100% (1)
- Prueba de HipotesisDocumento10 páginasPrueba de HipotesisrsemprunAún no hay calificaciones
- Unidad 3 Estadistica Inferencial 1Documento17 páginasUnidad 3 Estadistica Inferencial 1vivicann100% (2)
- Estadistica IIDocumento38 páginasEstadistica IILoaiza María CarolinaAún no hay calificaciones
- Foro HipotesisDocumento3 páginasForo HipotesisLina Marcela Pulido LandinezAún no hay calificaciones
- Metodos Estadisticos IIDocumento1 páginaMetodos Estadisticos IIBrianGarridoAún no hay calificaciones
- Hipótesis EstadisticaDocumento10 páginasHipótesis EstadisticaCarlos0% (1)
- EnsayoDocumento4 páginasEnsayoJessica SoberanoAún no hay calificaciones
- UniminutoDocumento7 páginasUniminutoBrignit SuarezAún no hay calificaciones
- Teoria Examen EstadisticaDocumento4 páginasTeoria Examen EstadisticaTobar Marcos FernandoAún no hay calificaciones
- Foro Prueba de HipótesisDocumento5 páginasForo Prueba de Hipótesisedgar armando marin ballesterosAún no hay calificaciones
- Actividad 3.1 CuestionarioDocumento8 páginasActividad 3.1 CuestionarioJavier AguileraAún no hay calificaciones
- Guía de Estudio Prueba de HipotesisDocumento11 páginasGuía de Estudio Prueba de HipotesisManuel HernándezAún no hay calificaciones
- Estadistica InferencialDocumento16 páginasEstadistica InferencialDiego VázquezAún no hay calificaciones
- Tema 6 Prueba de Hipotesis.Documento4 páginasTema 6 Prueba de Hipotesis.Jency de la cruzAún no hay calificaciones
- Estadistica Curso Ing. Alimentos Analisis SensorialDocumento73 páginasEstadistica Curso Ing. Alimentos Analisis SensorialVanesa OlivaAún no hay calificaciones
- ForoDocumento2 páginasForoAlexa GuerraAún no hay calificaciones
- PedeefeDocumento2 páginasPedeefeJhonathan RodriguezAún no hay calificaciones
- Actividades Unidad TresDocumento4 páginasActividades Unidad TresJhonatan BedollaAún no hay calificaciones
- Prueba de Hipotesis (Diapositivas)Documento22 páginasPrueba de Hipotesis (Diapositivas)Cruz JoseAún no hay calificaciones
- Est Ad Is Tic ADocumento8 páginasEst Ad Is Tic Aivanezhn8158Aún no hay calificaciones
- Conceptos de Prueba de HipótesisDocumento31 páginasConceptos de Prueba de HipótesisGardenia SaenzAún no hay calificaciones
- Prueba de HipótesisDocumento4 páginasPrueba de HipótesisAdolfo SanchezAún no hay calificaciones
- Expo Extadistica1Documento47 páginasExpo Extadistica1Juan Perez RosasAún no hay calificaciones
- SEMESTRALDocumento36 páginasSEMESTRALmarykatevegauniAún no hay calificaciones
- Apuntes-Prueba Hipotesis Una MuestraDocumento15 páginasApuntes-Prueba Hipotesis Una Muestrathe.charmed23Aún no hay calificaciones
- Prueba de Hipotesis - Estadistica AplicadaDocumento60 páginasPrueba de Hipotesis - Estadistica AplicadaJhon guzmanAún no hay calificaciones
- Métodos Estadísticos para InvestigadoresDocumento44 páginasMétodos Estadísticos para InvestigadoresGustavo Hernández100% (1)
- Caso de prueba de hipótesis acerca de una media o promedio poblacional μ y una varianza conocida σ2Documento8 páginasCaso de prueba de hipótesis acerca de una media o promedio poblacional μ y una varianza conocida σ2David Santiago BarberyAún no hay calificaciones
- Presentacion Prueba de HipotesisDocumento11 páginasPresentacion Prueba de HipotesisElizabeth AquinoAún no hay calificaciones
- Ensayo Prueba de HipotesisDocumento5 páginasEnsayo Prueba de HipotesisCarlos A Sanchez ZambranoAún no hay calificaciones
- Actividad 3.1 CuestionarioDocumento8 páginasActividad 3.1 CuestionarioJavier AguileraAún no hay calificaciones
- Presentación EstadísticaDocumento15 páginasPresentación EstadísticaFernanda SalazarAún no hay calificaciones
- ESTIMACIÓN Y PRUEBA DE HIPOTESIS (Lectura 2)Documento6 páginasESTIMACIÓN Y PRUEBA DE HIPOTESIS (Lectura 2)Rodrigo VAún no hay calificaciones
- Bio Esta Di SticaDocumento9 páginasBio Esta Di Sticakatia pAún no hay calificaciones
- Prueba de HipótesisDocumento19 páginasPrueba de HipótesisSolange VacaAún no hay calificaciones
- Problemario Pruebas de Hipotesis para ClassroomDocumento11 páginasProblemario Pruebas de Hipotesis para ClassroomNoé VázquezAún no hay calificaciones
- Uso de Pruebas Estadísticas Paramétricas y No ParamétricasDocumento13 páginasUso de Pruebas Estadísticas Paramétricas y No Paramétricasfrancisco cadenaAún no hay calificaciones
- Contraste de HipótesisDocumento14 páginasContraste de HipótesisOfelia OlivaresAún no hay calificaciones
- Qué Es Una HipótesisDocumento10 páginasQué Es Una HipótesisArticus CosmycAún no hay calificaciones
- Elementos Que Componen Una Prueba de HipotesisDocumento8 páginasElementos Que Componen Una Prueba de Hipotesispanthom090% (31)
- Presentación Prueba de Hipótesis.Documento10 páginasPresentación Prueba de Hipótesis.Cielo BritoAún no hay calificaciones
- Prueba de HipotesisDocumento12 páginasPrueba de HipotesisYuliana Gabriela González LópezAún no hay calificaciones
- Trabajo Estadistica AxloenDocumento6 páginasTrabajo Estadistica Axloenmanuel peñaAún no hay calificaciones
- Inf. Estad. - Clase 3 ADocumento32 páginasInf. Estad. - Clase 3 AKlaudia VillAún no hay calificaciones
- Inferencia Contraste de HipótesisDocumento51 páginasInferencia Contraste de HipótesisRobinson ParragaAún no hay calificaciones
- Unidad 1. Metodologia de Prueba de HipotesisDocumento4 páginasUnidad 1. Metodologia de Prueba de HipotesisJosé M. FernándezAún no hay calificaciones
- Clase2estadistica 110915113146 Phpapp02Documento44 páginasClase2estadistica 110915113146 Phpapp02Dine VanegasAún no hay calificaciones
- Prueba Hipotesis Una Muestra MedinaDocumento15 páginasPrueba Hipotesis Una Muestra MedinaJose Manuel SurielAún no hay calificaciones
- Estadistica U3 PDFDocumento19 páginasEstadistica U3 PDFMayra Milmac Millan PeraltaAún no hay calificaciones
- Revision Presaberes Inferencia Estadistica ListoDocumento4 páginasRevision Presaberes Inferencia Estadistica ListoOscar DelgadoAún no hay calificaciones
- Estadística ÁngelDocumento1 páginaEstadística ÁngelMorelia Mauricio CordovaAún no hay calificaciones
- EPIFITASDocumento19 páginasEPIFITASManuel MonroyAún no hay calificaciones
- Presentación Prueba de HipostesisDocumento13 páginasPresentación Prueba de HipostesisYuri MoraAún no hay calificaciones
- Mca de Suelos - EcuadorDocumento134 páginasMca de Suelos - EcuadorJaime Yelsin Rosales MalpartidaAún no hay calificaciones
- NM Iso 6507-2 - 2008Documento25 páginasNM Iso 6507-2 - 2008Wellington GilbertAún no hay calificaciones
- Matematicas para Los Negocios Act 3Documento11 páginasMatematicas para Los Negocios Act 3SCARLET SANCHEZAún no hay calificaciones
- Instrumento para Evaluar La Resolución de Conflictos Conflictalk PDFDocumento10 páginasInstrumento para Evaluar La Resolución de Conflictos Conflictalk PDFMarina García DíazAún no hay calificaciones
- Coso IIIDocumento35 páginasCoso IIIManuel Solares100% (1)
- Revista ChampalDocumento200 páginasRevista ChampalSolis Vásquez JavierAún no hay calificaciones
- IBM SPSS RegressionDocumento57 páginasIBM SPSS RegressionPedro Alberto Herrera LedesmaAún no hay calificaciones
- Copia de Estándares Miìnimos Resolucioìn 312 de 2019 EquidadDocumento123 páginasCopia de Estándares Miìnimos Resolucioìn 312 de 2019 EquidadSEGURIDAD WENGARAún no hay calificaciones
- Ejercicios Aux 22-04Documento6 páginasEjercicios Aux 22-04Ivana Dilia JustinianoAún no hay calificaciones
- Seminario de Investigación Apunte-1Documento85 páginasSeminario de Investigación Apunte-1Charo ColqueAún no hay calificaciones
- Fichas de Indicadores de Resultados 2016Documento82 páginasFichas de Indicadores de Resultados 2016Miguel Alejandro Flores EspinoAún no hay calificaciones
- Monitoreo 1 - Gestion de La Calidad - Cubas y GamarraDocumento7 páginasMonitoreo 1 - Gestion de La Calidad - Cubas y GamarraEstefani TaboadaAún no hay calificaciones
- Trabajo de Estadística UVIDocumento15 páginasTrabajo de Estadística UVINazareno CenozAún no hay calificaciones
- Introducción: 2021, Retos, 39, 112-119Documento8 páginasIntroducción: 2021, Retos, 39, 112-119Bakr Abselam ahmedAún no hay calificaciones
- Tesis Socavacion UNCVDocumento146 páginasTesis Socavacion UNCVEdgarFloresGonzalesAún no hay calificaciones
- S3-Proyecto 3.2 - Presentación de Tres Temas para El Proyecto de Investigación de Estadística-Grupo#7Documento7 páginasS3-Proyecto 3.2 - Presentación de Tres Temas para El Proyecto de Investigación de Estadística-Grupo#7Jordan RodriguezAún no hay calificaciones
- Actividad Donde Saca 100-1Documento3 páginasActividad Donde Saca 100-1Johan Lopez MorelAún no hay calificaciones
- Re Ing - Civil Anthony - Solano Danitza - Terrones Aplicacion - Simulacion.matematica - Software.vissim DatosDocumento97 páginasRe Ing - Civil Anthony - Solano Danitza - Terrones Aplicacion - Simulacion.matematica - Software.vissim DatosBrenerEspinalVelizAún no hay calificaciones
- Trabajo Práctico de Lógica ObservacionDocumento1 páginaTrabajo Práctico de Lógica ObservacionRocío Cruz ÁlvarezAún no hay calificaciones
- Estudio de La Caricatura Política A Través de Los Diarios El Espectador y El Tiempo en 2015Documento88 páginasEstudio de La Caricatura Política A Través de Los Diarios El Espectador y El Tiempo en 2015ANGIE STEFANNY MARQUINEZ MONTAÑOAún no hay calificaciones
- Econometría IIDocumento16 páginasEconometría IIGilberth DiazAún no hay calificaciones
- Planeador III y IV Periodo Septimo 2Documento3 páginasPlaneador III y IV Periodo Septimo 2JavierAún no hay calificaciones
- Guia ContabilidadDocumento7 páginasGuia Contabilidadmaria camila castañeda londoñoAún no hay calificaciones
- Proyecto Planta Procesadora de Pieles y CuerosDocumento28 páginasProyecto Planta Procesadora de Pieles y CuerosAngel Mendoza RamosAún no hay calificaciones
- Examn 2Documento2 páginasExamn 2Magali100% (1)
- Evaluacion de Programas y ProyectosDocumento13 páginasEvaluacion de Programas y ProyectosLu CepaAún no hay calificaciones
- Martínez Pandiani - Estrategias de Comunicación Política para ParlamentosDocumento152 páginasMartínez Pandiani - Estrategias de Comunicación Política para ParlamentosValentina SmitarelloAún no hay calificaciones
- Estadística para Las Ciencias AgropecuariasDocumento8 páginasEstadística para Las Ciencias AgropecuariasAntonioAún no hay calificaciones
- Guia 64019066 2019Documento17 páginasGuia 64019066 2019AaprAún no hay calificaciones
- Ejercicios Capítulo 4, 5, 6Documento22 páginasEjercicios Capítulo 4, 5, 6ingridAún no hay calificaciones