También podría gustarte
- Cómo entender estadística fácilmenteDe EverandCómo entender estadística fácilmenteCalificación: 3.5 de 5 estrellas3.5/5 (2)
- Actividad2 - Estadística para NegociosDocumento5 páginasActividad2 - Estadística para NegociosRosa sanchez0% (5)
- Tema 1Documento38 páginasTema 1AlarcónAdrianAún no hay calificaciones
- Aplicaciones de La Estadistica en Al AdministracionDocumento3 páginasAplicaciones de La Estadistica en Al Administracionjohangarcia12100% (2)
- Herramientas Matemáticas III Mod 1y2Documento84 páginasHerramientas Matemáticas III Mod 1y2Angi GalderiAún no hay calificaciones
- Quimica IDocumento19 páginasQuimica IEster BarreraAún no hay calificaciones
- 01 - Guía - Estadísticas para Negocios IDocumento112 páginas01 - Guía - Estadísticas para Negocios IPaola HernandezAún no hay calificaciones
- Taller de Estadistica - ResueltoDocumento15 páginasTaller de Estadistica - ResueltoSebastian Quintero JaimesAún no hay calificaciones
- Capítulo I-Estadística DescriptivaDocumento74 páginasCapítulo I-Estadística DescriptivaGustavo SotoAún no hay calificaciones
- Estadistica para Los NegociosDocumento29 páginasEstadistica para Los NegociosAndres Manuel LopezAún no hay calificaciones
- Actividad2 - Estadística para NegociosDocumento6 páginasActividad2 - Estadística para NegociosPaola PerezAún no hay calificaciones
- Estadistica IDocumento112 páginasEstadistica IBosco Jose Diaz100% (1)
- EstadisticaDescriptivaDocumento23 páginasEstadisticaDescriptivajose roman zepedaAún no hay calificaciones
- Capitulo 1Documento5 páginasCapitulo 1Jorge Guerrero NuñezAún no hay calificaciones
- Evidencia de Aprendizaje Sem1Documento7 páginasEvidencia de Aprendizaje Sem1Magaly GonzalezAún no hay calificaciones
- Estadistica DocumentoDocumento6 páginasEstadistica DocumentoClithian ValenzuelaAún no hay calificaciones
- Conceptos Básicos de Estadística: Estadística Descriptiva Estadísticas, Estadística y EstadísticosDocumento9 páginasConceptos Básicos de Estadística: Estadística Descriptiva Estadísticas, Estadística y Estadísticosoracionescatolicas1Aún no hay calificaciones
- Tarea #1-Estadistica DescripDocumento3 páginasTarea #1-Estadistica DescripAndrea CarolinaAún no hay calificaciones
- OC 1 Bienvenido A Tu Curso y Unidad 1 Fundamentos de Estadística Descriptiva Aplicada A Los NegociosDocumento26 páginasOC 1 Bienvenido A Tu Curso y Unidad 1 Fundamentos de Estadística Descriptiva Aplicada A Los NegociosRuth C.CAún no hay calificaciones
- UntitledDocumento84 páginasUntitledPao PaoAún no hay calificaciones
- Actividad2 - Estadística para NegociosDocumento7 páginasActividad2 - Estadística para NegociosAndy CarreraAún no hay calificaciones
- Ley General de Sociedad Es Mercantile SDocumento23 páginasLey General de Sociedad Es Mercantile SCristian David VenturaAún no hay calificaciones
- Probabilidad y EstadisticaDocumento47 páginasProbabilidad y EstadisticaJacinto EspitiaAún no hay calificaciones
- Atividad 1Documento5 páginasAtividad 1carlos alberto espinal bedoyaAún no hay calificaciones
- Estadistica IDocumento112 páginasEstadistica IAxel Alfonso Vega AlvarezAún no hay calificaciones
- I Unidad de Estadistica IDocumento41 páginasI Unidad de Estadistica ILet SpeaknowJason SanduAún no hay calificaciones
- La EstadísticaDocumento45 páginasLa EstadísticaMaxi ConstancioAún no hay calificaciones
- Guia1 Estadistica1, Conceptos GeneralesDocumento7 páginasGuia1 Estadistica1, Conceptos GeneralesIrineo Moody ChowAún no hay calificaciones
- Actividad2 - Estadística para NegociosDocumento7 páginasActividad2 - Estadística para NegociosBG AlëcxAún no hay calificaciones
- Lectura de Apoyo 1.3.importancia Del MuestreoDocumento3 páginasLectura de Apoyo 1.3.importancia Del MuestreoMarioAún no hay calificaciones
- Actividad 1Documento20 páginasActividad 1Ivan Sanchez GaliciaAún no hay calificaciones
- Numeros Indice EstadisticaDocumento53 páginasNumeros Indice EstadisticamiyerikaAún no hay calificaciones
- Estadística Descriptiva: 4.0 IntroducciónDocumento17 páginasEstadística Descriptiva: 4.0 IntroducciónGenaroAún no hay calificaciones
- Unidad 1 Estadistica DescriptivaDocumento20 páginasUnidad 1 Estadistica DescriptivaAngel Rojas0% (1)
- Estadística para Negocios Semana 1 PDocumento8 páginasEstadística para Negocios Semana 1 PDaniel Gill Gill PachecoAún no hay calificaciones
- Producción Final Estadistica Enmanuel NúñezDocumento8 páginasProducción Final Estadistica Enmanuel NúñezEnma GarcíaAún no hay calificaciones
- Unidad 1 Estadistica DescriptivaDocumento44 páginasUnidad 1 Estadistica DescriptivaMichelle100% (4)
- Tema1 PDFDocumento40 páginasTema1 PDFEdwin Quevedo QuispeAún no hay calificaciones
- Pablollumiluisa Estadística 1Documento5 páginasPablollumiluisa Estadística 1Pablo LlumiluisaAún no hay calificaciones
- Manual Del Alumnocp - AdmDocumento54 páginasManual Del Alumnocp - AdmAlba InsaurraldeAún no hay calificaciones
- Tercera Unidad de FM (1ra Parte)Documento20 páginasTercera Unidad de FM (1ra Parte)Franco Camacho CanchariAún no hay calificaciones
- Guia de Trabajo #1 Del Primer EncuentroDocumento8 páginasGuia de Trabajo #1 Del Primer Encuentrogrisel martinezAún no hay calificaciones
- Actividad2 - Estadística para Negocios SofiaDocumento6 páginasActividad2 - Estadística para Negocios SofiaKatty RamirezAún no hay calificaciones
- Estadística para Negocios Semana 1 PDocumento8 páginasEstadística para Negocios Semana 1 PRaul Manzano Máster Coach100% (4)
- Material de Clases - UnidoDocumento104 páginasMaterial de Clases - UnidoPaola PérezAún no hay calificaciones
- EADS1 ConceptosBasicosDocumento14 páginasEADS1 ConceptosBasicosleoibarra20Aún no hay calificaciones
- Contenido Unidad 1 Semana 1Documento27 páginasContenido Unidad 1 Semana 1SERGIO ANDRES OSORIOAún no hay calificaciones
- Modulo 1 Estadistica Completo 2Documento49 páginasModulo 1 Estadistica Completo 2marianelaAún no hay calificaciones
- EstadisticaDocumento25 páginasEstadisticaMarcia Contreras RodriguezAún no hay calificaciones
- 95 - Fase 1Documento14 páginas95 - Fase 1maria teresa jaramillo moncadaAún no hay calificaciones
- Fase 1 Daren CaballeroDocumento7 páginasFase 1 Daren CaballeroDaren CaballeroAún no hay calificaciones
- 1 Plan de Curso Estadistica Inferencial - A2024Documento11 páginas1 Plan de Curso Estadistica Inferencial - A2024africaurteflAún no hay calificaciones
- Estadística para Negocios Semana 1 PDocumento9 páginasEstadística para Negocios Semana 1 PAnnAún no hay calificaciones
- Ejercicio - Paso - 1 - Estadistica DescriptivaDocumento5 páginasEjercicio - Paso - 1 - Estadistica DescriptivaOscar PáezAún no hay calificaciones
- EBA U1 ContenidoDocumento16 páginasEBA U1 ContenidoJuan Pablo Balderas PichardoAún no hay calificaciones
- Apuntes U 1 P 1-31 Estadist para NegociosDocumento31 páginasApuntes U 1 P 1-31 Estadist para NegociosCielo Karina (Sky)Aún no hay calificaciones
- Trabajo de Informatica Ii-1Documento12 páginasTrabajo de Informatica Ii-1Cesar Sanchez QuintanaAún no hay calificaciones
- Cuestionario 1 AnalisisDocumento8 páginasCuestionario 1 AnalisisAXEL DAVID LEIVA GONGORAAún no hay calificaciones
- Trabajo Alumno X TerminarDocumento3 páginasTrabajo Alumno X Terminarsusanbarraganechevarria1985Aún no hay calificaciones
- Trabajo Final EstadisticaDocumento18 páginasTrabajo Final EstadisticaLeonard PeñalozaAún no hay calificaciones
- Tesis Carlos Uranga 2 CorregidaDocumento147 páginasTesis Carlos Uranga 2 CorregidaCarlos UrangaAún no hay calificaciones
- Trabajo en LayoutDocumento22 páginasTrabajo en LayoutFernando Erazo NavarreteAún no hay calificaciones
- EXAMEN 2 ImprimirDocumento10 páginasEXAMEN 2 ImprimirGiselly Chuco CondorAún no hay calificaciones
- Producción Y Comercialización de Plantas Ornamentales Con Maceteros Reciclables en La Provincia de HuancayoDocumento107 páginasProducción Y Comercialización de Plantas Ornamentales Con Maceteros Reciclables en La Provincia de HuancayoJamesA̲̲̅̅l̲̲̅̅v̲̲̅̅a̲̲̅̅r̲̲̅̅a̲̲̅̅d̲̲̅'̲̲o̲̲̲̲̅̅̅̅Aún no hay calificaciones
- Ejercicios-Tema 1.2-1.4-Contrastes-Significacion PDFDocumento3 páginasEjercicios-Tema 1.2-1.4-Contrastes-Significacion PDFAntonio Velázquez BarrosoAún no hay calificaciones
- 1 Plan Curricular MDocumento34 páginas1 Plan Curricular MManuel SalcedoAún no hay calificaciones
- PRÁCTICA DIRIGIDA No. 2Documento5 páginasPRÁCTICA DIRIGIDA No. 2jimmy_guitierrez7435Aún no hay calificaciones
- Práctica Nº5 Divisibilidad AritmèticaDocumento2 páginasPráctica Nº5 Divisibilidad AritmèticaYover Crisologo NarroAún no hay calificaciones
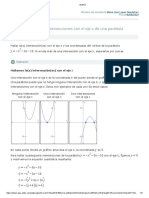
- Hallar El Vértice y Las Intersecciones Con El Eje X de Una Parábola.Documento3 páginasHallar El Vértice y Las Intersecciones Con El Eje X de Una Parábola.Maria Jose Lopez NeedhamAún no hay calificaciones
- Sesión de MatemáticaDocumento9 páginasSesión de MatemáticaSánchezRebecaAún no hay calificaciones
- Sag1 2015 SDocumento4 páginasSag1 2015 SYoshiro TrellesAún no hay calificaciones
- Tecnicas de ConteoDocumento4 páginasTecnicas de ConteoAmerica RosasAún no hay calificaciones
- Practica VI - Dinámica LinealDocumento7 páginasPractica VI - Dinámica LinealEdwin FrancoAún no hay calificaciones
- Módulo - Aritmética - 3° Año - (25 - 05)Documento5 páginasMódulo - Aritmética - 3° Año - (25 - 05)RomaleRomaleAún no hay calificaciones
- Analis Tecnico VS Analisis FundamentalDocumento1 páginaAnalis Tecnico VS Analisis FundamentalJosé Antonio CabezaAún no hay calificaciones
- Caminatas en DiagráficasDocumento16 páginasCaminatas en DiagráficasPanda100% (1)
- Matematicas Con Un Enfoque Quimico Biologico1Documento274 páginasMatematicas Con Un Enfoque Quimico Biologico1Magaly PugaAún no hay calificaciones
- Ficha Funcion Afin PDFDocumento2 páginasFicha Funcion Afin PDFAlberto MartinAún no hay calificaciones
- Trabajo 2 O1Documento4 páginasTrabajo 2 O1Gina Lisbeth Carranza VasquezAún no hay calificaciones
- Encofrado de EscaleraDocumento21 páginasEncofrado de EscaleraManuel Santisteban TuñoqueAún no hay calificaciones
- 01 em 02 Emgega Unidad1 s1Documento8 páginas01 em 02 Emgega Unidad1 s1EMMANUEL OLIVAS RODRIGUEZAún no hay calificaciones
- Taller de Funciones Vectoriales de EntregaDocumento3 páginasTaller de Funciones Vectoriales de EntregaLuz Angela Bonilla CaicedoAún no hay calificaciones
- Joseph Marie JacquardDocumento5 páginasJoseph Marie JacquardYoung Ing Angel Ruiz100% (1)
- Taller 1 Metodos Numericos (3) - 2Documento15 páginasTaller 1 Metodos Numericos (3) - 2Andres Mendoza MejiaAún no hay calificaciones
- Modulo TornoDocumento148 páginasModulo TornoAndres Cano Salvatierra100% (3)
- La Brújula de La Competitividad - Basado en CMIDocumento84 páginasLa Brújula de La Competitividad - Basado en CMIEcoserviciosAún no hay calificaciones
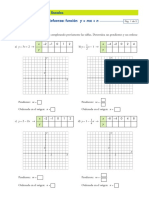
- Sem 3 - Sesión 7 - Transformación de Funciones (Traslación Vertical y Horizontal)Documento17 páginasSem 3 - Sesión 7 - Transformación de Funciones (Traslación Vertical y Horizontal)luz leon maldonadoAún no hay calificaciones
- Umbral DiferencialDocumento3 páginasUmbral Diferencialmmuelas1Aún no hay calificaciones
- CALCULO DIFERENCIAL 21 EneroDocumento1 páginaCALCULO DIFERENCIAL 21 EneroDaniel Camilo SalamancaAún no hay calificaciones
- Reducción de Los Diagramas E-R A TablasDocumento7 páginasReducción de Los Diagramas E-R A TablasManuel Eduardo GutierrezAún no hay calificaciones