0% encontró este documento útil (0 votos)
443 vistas25 páginasAnálisis ANOVA de Palomitas de Maíz
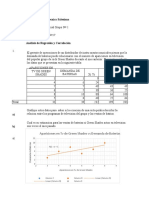
Este resumen describe un experimento que aplica el método ANOVA de un solo factor para determinar si existen diferencias significativas entre 4 marcas de palomitas de maíz para microondas en términos de granos sin reventar. Se midió el número de granos sin reventar para cada marca en 4 réplicas. Los resultados se analizaron estadísticamente utilizando Minitab para generar un diagrama de caja y un ANOVA. El ANOVA no encontró diferencias estadísticamente significativas entre las marcas, aunque la prueba F sugiere posibles
Cargado por
YourFriendlyNeighborhoodMexicanDerechos de autor
© © All Rights Reserved
Nos tomamos en serio los derechos de los contenidos. Si sospechas que se trata de tu contenido, reclámalo aquí.
Formatos disponibles
Descarga como PDF, TXT o lee en línea desde Scribd
0% encontró este documento útil (0 votos)
443 vistas25 páginasAnálisis ANOVA de Palomitas de Maíz
Este resumen describe un experimento que aplica el método ANOVA de un solo factor para determinar si existen diferencias significativas entre 4 marcas de palomitas de maíz para microondas en términos de granos sin reventar. Se midió el número de granos sin reventar para cada marca en 4 réplicas. Los resultados se analizaron estadísticamente utilizando Minitab para generar un diagrama de caja y un ANOVA. El ANOVA no encontró diferencias estadísticamente significativas entre las marcas, aunque la prueba F sugiere posibles
Cargado por
YourFriendlyNeighborhoodMexicanDerechos de autor
© © All Rights Reserved
Nos tomamos en serio los derechos de los contenidos. Si sospechas que se trata de tu contenido, reclámalo aquí.
Formatos disponibles
Descarga como PDF, TXT o lee en línea desde Scribd