También podría gustarte
- 2-Teoría de VoicingsDocumento10 páginas2-Teoría de VoicingsTeto Pianourquiza100% (1)
- 1-Técnica Pianistica - Uso Del Cuerpo HumanoDocumento4 páginas1-Técnica Pianistica - Uso Del Cuerpo HumanoTeto PianourquizaAún no hay calificaciones
- MELODIADocumento6 páginasMELODIASebastianGAAún no hay calificaciones
- 3-Comparativa Armonía Funcional y No FuncionalDocumento1 página3-Comparativa Armonía Funcional y No FuncionalTeto PianourquizaAún no hay calificaciones
- 2019 Historia de La Musica I 1Documento22 páginas2019 Historia de La Musica I 1Laura Educadora MusicalAún no hay calificaciones
- 8 - Estrategias para Coordinar Las Manos PDFDocumento8 páginas8 - Estrategias para Coordinar Las Manos PDFTeto PianourquizaAún no hay calificaciones
- Escalas ModalesDocumento14 páginasEscalas ModalesLuis Cotrina Vara75% (4)
- Dirección CoralDocumento5 páginasDirección CoralManuel BelgranoAún no hay calificaciones
- El Poder de La Musica Paz y Felicidad Del Ser Humano-hoja+Sencilla-okDocumento81 páginasEl Poder de La Musica Paz y Felicidad Del Ser Humano-hoja+Sencilla-okJose Ángel PassosAún no hay calificaciones
- Taller de Arte Sonoro - Módulo 5 - Síntesis de SonidoDocumento26 páginasTaller de Arte Sonoro - Módulo 5 - Síntesis de SonidoSantiagoAún no hay calificaciones
- TES III 2018 1º CuatrimestreDocumento237 páginasTES III 2018 1º Cuatrimestres cAún no hay calificaciones
- Electroacustica PDFDocumento37 páginasElectroacustica PDFnellysaidethAún no hay calificaciones
- Cuadernillo - DFA IDocumento52 páginasCuadernillo - DFA IJ Sebastian Sepulveda100% (2)
- Todo Lo Que Necesitas Saber: AudioDocumento37 páginasTodo Lo Que Necesitas Saber: AudioEmanuel Bracamonte100% (1)
- Análisis Musical-Guia Práctica CortaDocumento33 páginasAnálisis Musical-Guia Práctica CortaEduardo Toledo MuñozAún no hay calificaciones
- INTRODUCCIÓN A Los Sistemas, Estructuras y TexturasDocumento8 páginasINTRODUCCIÓN A Los Sistemas, Estructuras y TexturasManu GaunaAún no hay calificaciones
- Espacialidad Transformacion Sonido GonzalezDocumento18 páginasEspacialidad Transformacion Sonido Gonzalezmedinaalexander2Aún no hay calificaciones
- !entrenamiento Auditivo FuncionalDocumento5 páginas!entrenamiento Auditivo FuncionalTeto Pianourquiza100% (1)
- Sintesis GranularDocumento4 páginasSintesis GranularMatías Keller SarmientoAún no hay calificaciones
- La Imagen Del Sonido y La Ecritura EspectralDocumento22 páginasLa Imagen Del Sonido y La Ecritura EspectralRolandoJaimeAún no hay calificaciones
- Composición CoralDocumento6 páginasComposición CoralBruno Ponce100% (1)
- Rasguña Las Piedras - Sui GenerisDocumento2 páginasRasguña Las Piedras - Sui GenerisTeto Pianourquiza50% (2)
- Manual de Teorà - A y Terminologà - A Musical Vol II Daniel Rojas BuscagliaDocumento26 páginasManual de Teorà - A y Terminologà - A Musical Vol II Daniel Rojas BuscagliaMayeth HteyamAún no hay calificaciones
- SintetizadorDocumento76 páginasSintetizadorpuesyoAún no hay calificaciones
- La Postura EspectralDocumento5 páginasLa Postura EspectralCharlex LópezAún no hay calificaciones
- Cuadernillo - Tecnicas de Grabacion PDFDocumento39 páginasCuadernillo - Tecnicas de Grabacion PDFTeto PianourquizaAún no hay calificaciones
- 1584-2019-09-11-Tutorial Sonic VisualiserDocumento33 páginas1584-2019-09-11-Tutorial Sonic VisualiserrodroesAún no hay calificaciones
- In Memoriam Gérard Grisey - J.M.LÓPEZ-LÓPEZ PDFDocumento8 páginasIn Memoriam Gérard Grisey - J.M.LÓPEZ-LÓPEZ PDFJoluisen :DAún no hay calificaciones
- Análisis Integral (Y. Tiersenn)Documento18 páginasAnálisis Integral (Y. Tiersenn)Martín ArianoAún no hay calificaciones
- Diseno Acustico de Espacios ArquitectoniDocumento223 páginasDiseno Acustico de Espacios ArquitectoniSandra Silva Mendoza100% (1)
- Guía Formatos Tipos de PartiturasDocumento3 páginasGuía Formatos Tipos de PartiturasFrancisco Issa0% (1)
- Arte Sonoro Procesos Emergentes y ConstrDocumento23 páginasArte Sonoro Procesos Emergentes y ConstrcarolillanesAún no hay calificaciones
- Educación Musical Tema 4Documento17 páginasEducación Musical Tema 4Marco Antonio Correa100% (1)
- Planificacion Anual de Musica 3ºDocumento12 páginasPlanificacion Anual de Musica 3ºAndrea Diaz ValdesAún no hay calificaciones
- Sampleo en La MemoriaDocumento187 páginasSampleo en La MemoriaRadio AlterAtivA Media LAB - Rowinson PerezAún no hay calificaciones
- Análisis - .Heterophonie - Kagel PDFDocumento5 páginasAnálisis - .Heterophonie - Kagel PDFMary StevensonAún no hay calificaciones
- Sonido de La Hora de Los HornosDocumento22 páginasSonido de La Hora de Los HornosFernanda GarridoAún no hay calificaciones
- Trabajo de Grado ComposiciónDocumento154 páginasTrabajo de Grado ComposiciónHenry SalazarAún no hay calificaciones
- La Percepción Del Ritmo - Cap 3 - M C Aguilar - Aprender A Escuchar MúsicaDocumento6 páginasLa Percepción Del Ritmo - Cap 3 - M C Aguilar - Aprender A Escuchar MúsicaLeonardo PonceAún no hay calificaciones
- Materiamusicalyrecorridos - Jorge HorstDocumento4 páginasMateriamusicalyrecorridos - Jorge HorstAnonymous T2Qikswx6Aún no hay calificaciones
- Introducción A La Música. Lewis RowellDocumento30 páginasIntroducción A La Música. Lewis Rowelllmb656Aún no hay calificaciones
- Aura Ease Tutorial EspañolDocumento9 páginasAura Ease Tutorial EspañolAudiomatrix EcuadorAún no hay calificaciones
- PsicoacústicaDocumento6 páginasPsicoacústicaGabriel VlqzAún no hay calificaciones
- Música y La Musicología. Jornadas Interdisciplinarias de Investigación - Investigación, Creación, Recreación PDFDocumento151 páginasMúsica y La Musicología. Jornadas Interdisciplinarias de Investigación - Investigación, Creación, Recreación PDFAnonymous YSY2OVLXPAún no hay calificaciones
- Como Quemar Más GrasaDocumento5 páginasComo Quemar Más GrasaFrancisco Javier InarejosAún no hay calificaciones
- Clarinete, Flauta Traversa y OboeDocumento13 páginasClarinete, Flauta Traversa y OboeUrben Dario RamirezAún no hay calificaciones
- Ritmo Aditivo y DivisiónDocumento5 páginasRitmo Aditivo y DivisiónRodrigo Millano50% (2)
- MIYARA, Federico - LA MÚSICA POR COMPUTADORADocumento14 páginasMIYARA, Federico - LA MÚSICA POR COMPUTADORAGato Nestor AbdyAún no hay calificaciones
- Variacion Fonetica de Los Fonemas Liquidos Distensivos en El Español de Pinar Del Rio CubaDocumento36 páginasVariacion Fonetica de Los Fonemas Liquidos Distensivos en El Español de Pinar Del Rio CubaJose Luis Darias ConcepciónAún no hay calificaciones
- Planificacion Catedra - Acustica2021Documento8 páginasPlanificacion Catedra - Acustica2021Damian PayoAún no hay calificaciones
- La Sucesión de Farey y Los Armónicos Lejanos Del Violonchelo para Ver PDFDocumento27 páginasLa Sucesión de Farey y Los Armónicos Lejanos Del Violonchelo para Ver PDFAgustín Fernández Burzaco100% (1)
- Glosario SonoroDocumento5 páginasGlosario SonoroSandra GutierrezAún no hay calificaciones
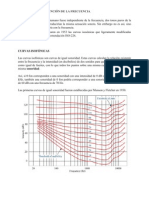
- Curvas de Audibilidad o IsosonicasDocumento4 páginasCurvas de Audibilidad o IsosonicasGerman Enrique Lizcano Duarte100% (1)
- Acerca de La Composición y Su EnseñanzaDocumento5 páginasAcerca de La Composición y Su EnseñanzaEric BarretoAún no hay calificaciones
- Tipos de SintesisDocumento3 páginasTipos de SintesisEnrique BunsterAún no hay calificaciones
- Parametros Subjetivos Del SonidoDocumento4 páginasParametros Subjetivos Del SonidoMartin CruzAún no hay calificaciones
- 1 - Saitta - Nuevas Caracterizaciones de La ActividadDocumento14 páginas1 - Saitta - Nuevas Caracterizaciones de La ActividadMaria Rocio BrizuelaAún no hay calificaciones
- Estudio Campo y Relato Experiencia Canto Armaonico en El Budismo TantricoDocumento124 páginasEstudio Campo y Relato Experiencia Canto Armaonico en El Budismo TantricoMIGUELITO IPANAQUÉAún no hay calificaciones
- Procesamiento Neurológico MusicalDocumento9 páginasProcesamiento Neurológico MusicalMagalí CésariAún no hay calificaciones
- Análisis de FuentesDocumento6 páginasAnálisis de Fuentesadrian montesAún no hay calificaciones
- 4 MetricaDocumento30 páginas4 MetricaEFRAINAún no hay calificaciones
- Ensayo Sonido y NaturalezaDocumento3 páginasEnsayo Sonido y NaturalezaMarkito HerreraAún no hay calificaciones
- ¿Qué Es Acústica - Su Definición, Concepto y SignificadoDocumento6 páginas¿Qué Es Acústica - Su Definición, Concepto y SignificadoP ZAún no hay calificaciones
- Edicion Critica Estudio Obras Guastavino PDFDocumento10 páginasEdicion Critica Estudio Obras Guastavino PDFmelerotiAún no hay calificaciones
- Tecnica de Microfonia Del ClarineteDocumento14 páginasTecnica de Microfonia Del ClarineteRodolfo BorrasAún no hay calificaciones
- Urban Sound Landscape "Soundwalk" As A Method of Integral AnalysisDocumento16 páginasUrban Sound Landscape "Soundwalk" As A Method of Integral AnalysisGilles MalatrayAún no hay calificaciones
- Ritmo MusicalDocumento18 páginasRitmo MusicalAri CanterosAún no hay calificaciones
- TextoDocumento761 páginasTextoLorena RicoAún no hay calificaciones
- ESPECTRALISMODocumento4 páginasESPECTRALISMOEl Roy M.T.100% (2)
- Curso 2ºDocumento22 páginasCurso 2ºLuis TorresAún no hay calificaciones
- Tecnicas de MicrofoneoDocumento5 páginasTecnicas de MicrofoneoviolinvillagranAún no hay calificaciones
- Clase2 AuralidadDocumento22 páginasClase2 AuralidadElias Baron Levin RojoAún no hay calificaciones
- Diego Sangri - Dark EnoughDocumento264 páginasDiego Sangri - Dark EnoughTristán TzaraAún no hay calificaciones
- Registro Audiciones MusicalesDocumento1 páginaRegistro Audiciones MusicalesPaola LissetteAún no hay calificaciones
- Bosquejos Acerca Del Arte Sonoro y La MúsicaDocumento6 páginasBosquejos Acerca Del Arte Sonoro y La MúsicaJosé Mataloni100% (1)
- Tarea Psicoacustica MusicalDocumento3 páginasTarea Psicoacustica MusicalDany ReyesAún no hay calificaciones
- 2 - Ejercicios Intervalos, Armaduras, Rítmicos PDFDocumento2 páginas2 - Ejercicios Intervalos, Armaduras, Rítmicos PDFTeto PianourquizaAún no hay calificaciones
- Armonía MenorDocumento2 páginasArmonía MenorTeto PianourquizaAún no hay calificaciones
- El Tesoro - El Mató A Un Policía Motorizado - Version Difícil - PianourquizaDocumento4 páginasEl Tesoro - El Mató A Un Policía Motorizado - Version Difícil - PianourquizaTeto Pianourquiza100% (2)
- Deshoras - BabasónicosDocumento1 páginaDeshoras - BabasónicosTeto PianourquizaAún no hay calificaciones
- !errores Comunes Al Estudiar PianoDocumento1 página!errores Comunes Al Estudiar PianoTeto PianourquizaAún no hay calificaciones
- Armonia para Hoy. TERCERA PARTEDocumento68 páginasArmonia para Hoy. TERCERA PARTEAlejandroPérezRodríguezAún no hay calificaciones
- Guido Tollio Practico Mercado BienesDocumento4 páginasGuido Tollio Practico Mercado BienesTeto PianourquizaAún no hay calificaciones
- Ejercicios para Hacer ImprimidaDocumento16 páginasEjercicios para Hacer ImprimidaFranciscoLopezAún no hay calificaciones
- Pentatonicas Melodicas PDFDocumento2 páginasPentatonicas Melodicas PDFYobani RiosAún no hay calificaciones
- Gauldin 6 de 6Documento172 páginasGauldin 6 de 6Franco ZanAún no hay calificaciones
- Tema 2: 1. Fundamentación/Justificación 2. La Melodía en La Educación MusicalDocumento9 páginasTema 2: 1. Fundamentación/Justificación 2. La Melodía en La Educación MusicaljosueAún no hay calificaciones
- ARM3 TP Estilo 1 Rimsky-SatieDocumento2 páginasARM3 TP Estilo 1 Rimsky-SatieNatasha VasiloffAún no hay calificaciones
- Mediantes y Submediantes CromáticasDocumento5 páginasMediantes y Submediantes CromáticasAnonymous 1Rb4QLrAún no hay calificaciones
- Círculo de QuintasDocumento10 páginasCírculo de QuintasAdrián RamírezAún no hay calificaciones
- El Coro en El Aula Tercer Ciclo - 3Documento13 páginasEl Coro en El Aula Tercer Ciclo - 3Elmer Rodriguez RodriguezAún no hay calificaciones
- BULGAR - Partitura CompletaDocumento11 páginasBULGAR - Partitura CompletaIván Emo-MartínezAún no hay calificaciones
- Escucha Atenta - Virus, de BjorkDocumento2 páginasEscucha Atenta - Virus, de BjorkAndrés ArenasAún no hay calificaciones
- Modos Occidentales ModernosDocumento1 páginaModos Occidentales ModernosHernando ParedesAún no hay calificaciones
- Belleza ArtísticaDocumento6 páginasBelleza ArtísticaMigue LoOpez100% (1)
- Sistema Modal Tito TipsDocumento8 páginasSistema Modal Tito TipsCuarteto PorteñoAún no hay calificaciones
- Trabajo de Formacion Cultural II-Corte IDocumento6 páginasTrabajo de Formacion Cultural II-Corte Ianon_842456617Aún no hay calificaciones
- 5to. Ciencias - Expresión ArtísticaDocumento107 páginas5to. Ciencias - Expresión ArtísticaNancy MacalAún no hay calificaciones
- Analisis Clase Mov II DebussyDocumento2 páginasAnalisis Clase Mov II Debussytlajin2100% (1)
- Dialnet MusicaAndalusiYArabe 7274872Documento19 páginasDialnet MusicaAndalusiYArabe 7274872Juan PalomoAún no hay calificaciones
- PLAN DE ESTUDIOS MUSICALES - Soacha - Sax - flauta-XIMENA PEREZ 2021Documento7 páginasPLAN DE ESTUDIOS MUSICALES - Soacha - Sax - flauta-XIMENA PEREZ 2021Ximena Cecilia Perez MejiaAún no hay calificaciones
- Capacidades Nacionales para La Educación MediaDocumento9 páginasCapacidades Nacionales para La Educación MediaAna Sofía Aguilera FernándezAún no hay calificaciones
- Tarea 8.1 Orígenes de La Música para Visuales - RaquelPadillaDocumento4 páginasTarea 8.1 Orígenes de La Música para Visuales - RaquelPadillaRaquel Alejandra PadillaAún no hay calificaciones