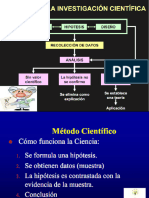
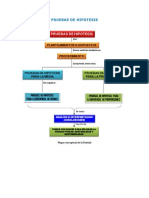
También podría gustarte
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Pruebas de HipótesisDocumento27 páginasPruebas de Hipótesisjasmin vides0% (1)
- Curva ROC y la teoría de las decisiones en las Ciencias de la SaludDe EverandCurva ROC y la teoría de las decisiones en las Ciencias de la SaludAún no hay calificaciones
- Intervalo de Confianza para La MediaDocumento26 páginasIntervalo de Confianza para La MediaRonal Sulca67% (3)
- NTC 1733Documento9 páginasNTC 1733Martha Cecilia Suarez100% (1)
- Inferencia EstadisticaDocumento18 páginasInferencia Estadisticahober0% (2)
- Informe Final Segunda Encuesta Bogota Alcaldia 2023Documento28 páginasInforme Final Segunda Encuesta Bogota Alcaldia 2023W Radio Colombia100% (2)
- Protocolo AguaDocumento40 páginasProtocolo AguaMaria Vanessa Cuba TelloAún no hay calificaciones
- 2 Prueba de HipotesisDocumento26 páginas2 Prueba de HipotesisRondo Luna JarithAún no hay calificaciones
- Pruebas para Detectar Diferencias Mínimas Significativas - Prueba (SNK) - Duncan - ScheffeDocumento46 páginasPruebas para Detectar Diferencias Mínimas Significativas - Prueba (SNK) - Duncan - ScheffeValentina Hernández100% (1)
- Clase 2. Distribución de Frecuencias, Técnicas de Agrupación de Datos, Técnicas de Muestreo e Histogramas - TereDocumento33 páginasClase 2. Distribución de Frecuencias, Técnicas de Agrupación de Datos, Técnicas de Muestreo e Histogramas - Terejorge sierra100% (1)
- Diferencias entre poblacionesDocumento48 páginasDiferencias entre poblacionesKazuto Fandubs100% (1)
- Prueba de Hipotesis I 2019-2Documento35 páginasPrueba de Hipotesis I 2019-2Ricardo Angel Berrio PerezAún no hay calificaciones
- Pruebas de Hipotesis Con Una Muestra S9Documento16 páginasPruebas de Hipotesis Con Una Muestra S9ERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Estadística GastronomiaDocumento36 páginasEstadística GastronomiaPedro Orlando Gonzalez CorderoAún no hay calificaciones
- Prueba de HipótesisDocumento21 páginasPrueba de HipótesisJoe Hoyos RamirezAún no hay calificaciones
- Clase Nro. 23 Estadística 501 - Hipótesis Dos Muestras GrandesDocumento8 páginasClase Nro. 23 Estadística 501 - Hipótesis Dos Muestras GrandesAlex SislemaAún no hay calificaciones
- Universidad Católica de Cuenca: Facultad de Ciencias MédicasDocumento41 páginasUniversidad Católica de Cuenca: Facultad de Ciencias MédicasPaola EsparzaAún no hay calificaciones
- Diseño de Experimentos y Análisis de VarianzaDocumento36 páginasDiseño de Experimentos y Análisis de VarianzaMilton Adan YongAún no hay calificaciones
- metodos estadisticos en investigacion parametrias y no parametricasDocumento57 páginasmetodos estadisticos en investigacion parametrias y no parametricasmaseasy26Aún no hay calificaciones
- Prueba para Dos Medias Cuando Las Muestras Son IndependientesDocumento12 páginasPrueba para Dos Medias Cuando Las Muestras Son IndependientesItzel MendozaAún no hay calificaciones
- Pruebas de HipótesisDocumento47 páginasPruebas de HipótesisDANILO CASTRO MARTINEZAún no hay calificaciones
- Prueba de HipotesisDocumento8 páginasPrueba de HipotesisPaloma GonzálezAún no hay calificaciones
- Prueba de Hipótesis para Dos PoblacionesDocumento14 páginasPrueba de Hipótesis para Dos PoblacionesGiulianno Tarrillo Uriarte100% (1)
- EG - Sesion14 - Prueba de Hipotesis Una PoblacionDocumento22 páginasEG - Sesion14 - Prueba de Hipotesis Una PoblacionLuis Fernando Moreto ChinchayAún no hay calificaciones
- Pruebas de Hipótesis: Procedimiento en 4 Pasos para Evaluar Datos MuestralesDocumento11 páginasPruebas de Hipótesis: Procedimiento en 4 Pasos para Evaluar Datos MuestraleswilliamAún no hay calificaciones
- ObjetivosDocumento3 páginasObjetivosmas100% (1)
- Pruebas de Hipótesis: Definición, Pasos y EjemplosDocumento20 páginasPruebas de Hipótesis: Definición, Pasos y EjemplosJulian David Garzón RamírezAún no hay calificaciones
- Unidad 1 (1.1.2)Documento43 páginasUnidad 1 (1.1.2)Ramiro CartuchiAún no hay calificaciones
- Est. Inf 17 Abr. Sobre Prueba de HipotesisDocumento10 páginasEst. Inf 17 Abr. Sobre Prueba de HipotesisGeiris Esther MartinezAún no hay calificaciones
- Clase 9Documento44 páginasClase 9Greis RubioAún no hay calificaciones
- Unidad 3. Prueba de HipotesisDocumento36 páginasUnidad 3. Prueba de HipotesisIván Darío Benítez VergaraAún no hay calificaciones
- Estadística InferencialDocumento18 páginasEstadística Inferencialjuan manaAún no hay calificaciones
- Pruebas de hipótesis estadísticas: tipos, errores y aplicacionesDocumento5 páginasPruebas de hipótesis estadísticas: tipos, errores y aplicacionesAldo AlarconAún no hay calificaciones
- Modulo (Pruebadehipotesis)Documento4 páginasModulo (Pruebadehipotesis)Bill Malba TahanAún no hay calificaciones
- Clase 2-Puebas de Hipótesis-REZPDocumento43 páginasClase 2-Puebas de Hipótesis-REZPVictor Hugo Alejo VilcaAún no hay calificaciones
- Taller PruebEstaHoDocumento6 páginasTaller PruebEstaHomary ospinaAún no hay calificaciones
- Importancia de una hipótesis bien elaboradaDocumento29 páginasImportancia de una hipótesis bien elaboradaBrayan Napa QuirozAún no hay calificaciones
- Diferencia de MediasDocumento7 páginasDiferencia de MediasKath EstradaAún no hay calificaciones
- Cap. 2 Prueba de HipótesisDocumento25 páginasCap. 2 Prueba de HipótesisAngel Pinedo Delgado33% (3)
- Parcial 3 Estadistica 2Documento12 páginasParcial 3 Estadistica 2Ingrid ZepedaAún no hay calificaciones
- M1 - Fundamentos de Estadistica - UNIDAD 5 PDFDocumento48 páginasM1 - Fundamentos de Estadistica - UNIDAD 5 PDFnikolay mezaAún no hay calificaciones
- Diapositiva Semana 6Documento56 páginasDiapositiva Semana 6David cutire sotoAún no hay calificaciones
- Tema Hipótesis Finanzas II 2022Documento16 páginasTema Hipótesis Finanzas II 2022Alcides CamargoAún no hay calificaciones
- Unidad 1Documento24 páginasUnidad 1Gianni GiulianoAún no hay calificaciones
- Solucionario 09 Práctica 9 Pruebas de Hipótesis para Una Media y Una ProporciónDocumento6 páginasSolucionario 09 Práctica 9 Pruebas de Hipótesis para Una Media y Una Proporciónsam884Aún no hay calificaciones
- Bioestadística Unidad 5.1 Prueba de HipotesisDocumento12 páginasBioestadística Unidad 5.1 Prueba de HipotesisCarlos OrbeaAún no hay calificaciones
- 6 - Dr. Mario Squillace Louhau - Prueba de H1Documento61 páginas6 - Dr. Mario Squillace Louhau - Prueba de H1Rochi MarengoAún no hay calificaciones
- IV CAPITULO P. HDocumento28 páginasIV CAPITULO P. Hrandylh2000Aún no hay calificaciones
- Clase2estadistica 110915113146 Phpapp02Documento44 páginasClase2estadistica 110915113146 Phpapp02Dine VanegasAún no hay calificaciones
- Portafolio de EstadisticaDocumento14 páginasPortafolio de EstadisticaArmenta Vazquez Jesus EduardoAún no hay calificaciones
- Prueba de Hipotesis para La Diferencia de Dos MediasDocumento28 páginasPrueba de Hipotesis para La Diferencia de Dos MediasANDRES DURAN TORRESAún no hay calificaciones
- Apuntes Pruebas de Hipótesis CD 2023-1Documento26 páginasApuntes Pruebas de Hipótesis CD 2023-1naomi mocayoAún no hay calificaciones
- Prueba de HipótesisyejerciciosDocumento8 páginasPrueba de HipótesisyejerciciosErick Cassana100% (1)
- Clase04 - Estadistica ComparativaDocumento35 páginasClase04 - Estadistica ComparativaGabriel Orlando Lopez CordovaAún no hay calificaciones
- Clase04 - Estadistica ComparativaDocumento23 páginasClase04 - Estadistica ComparativaMauricio AngelAún no hay calificaciones
- Estadística Ángeles Pastor Estefania Chávez Colin Naomi Ávila Diaz Cesar Guiovanny Teoria Del MuestreoDocumento18 páginasEstadística Ángeles Pastor Estefania Chávez Colin Naomi Ávila Diaz Cesar Guiovanny Teoria Del MuestreoESTEFANIA ANGELES PASTORAún no hay calificaciones
- HipotesisDocumento12 páginasHipotesisBetomigel Valdivia Coveñas0% (1)
- Prueba de HipotesisDocumento32 páginasPrueba de HipotesisLeonardo Astahuaman LujanAún no hay calificaciones
- Prueba de Hipótesis EstadísticaDocumento54 páginasPrueba de Hipótesis EstadísticaSergio BerriosAún no hay calificaciones
- Pruebas de Hipótesis ParametricasDocumento14 páginasPruebas de Hipótesis ParametricasyeihardAún no hay calificaciones
- Corte 2 EstadisticaDocumento13 páginasCorte 2 EstadisticaIsrael GuerraAún no hay calificaciones
- Guia de Estudio Iii 1 Bienes Publicos y Recursos Comunes 202251Documento3 páginasGuia de Estudio Iii 1 Bienes Publicos y Recursos Comunes 202251ERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Ilovepdf Merged PDFDocumento136 páginasIlovepdf Merged PDFERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Iii 1 Material Bienes Publicos y Recursos Comunes 202251Documento40 páginasIii 1 Material Bienes Publicos y Recursos Comunes 202251ERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Guia - 1 - Liderazgo Veintimilla Ricardo, Daquilema MiguelDocumento4 páginasGuia - 1 - Liderazgo Veintimilla Ricardo, Daquilema MiguelERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Derecho Esquema Familia1Documento2 páginasDerecho Esquema Familia1Octavio CorralAún no hay calificaciones
- Comportamiento de Liderazgo y Motivación (Capítulo III)Documento22 páginasComportamiento de Liderazgo y Motivación (Capítulo III)ERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Mercado Tec NiaDocumento71 páginasMercado Tec NiaERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Iii 4 Costos A Largo Plazo 202251Documento15 páginasIii 4 Costos A Largo Plazo 202251ERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Confirmación de RealizaciónDocumento1 páginaConfirmación de RealizaciónERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Guia 1 LiderazgoDocumento1 páginaGuia 1 LiderazgoANAHI CAMILA SANCHEZ CARVAJALAún no hay calificaciones
- Cultura Maya: Origen y apogeo de la avanzada civilización de MesoaméricaDocumento13 páginasCultura Maya: Origen y apogeo de la avanzada civilización de MesoaméricaERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Liderazgo Prueba 3Documento7 páginasLiderazgo Prueba 3ERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- PreguntasDocumento1 páginaPreguntasERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Ensayo Niif ContaDocumento12 páginasEnsayo Niif ContaERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- PreguntasDocumento1 páginaPreguntasERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Sociedades agrícolas superiores Formativo TardíoDocumento8 páginasSociedades agrícolas superiores Formativo TardíoERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Ensayo Niif ContaDocumento12 páginasEnsayo Niif ContaERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Liderazgo Prueba 4Documento12 páginasLiderazgo Prueba 4ERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Estadistica Inferencial Estimaciones S7Documento20 páginasEstadistica Inferencial Estimaciones S7Edid ChiliquingaAún no hay calificaciones
- LIbro Diario, MayorDocumento17 páginasLIbro Diario, MayorERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Liderazgo Prueba 5Documento4 páginasLiderazgo Prueba 5ERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Liderazgo Prueba 2Documento4 páginasLiderazgo Prueba 2ERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Examen 3er Parcial Forma 1 - Cristhian - Xavier - Vera - ZambranoDocumento22 páginasExamen 3er Parcial Forma 1 - Cristhian - Xavier - Vera - ZambranoERICK RICARDO VEINTIMILLA SALAZARAún no hay calificaciones
- Trabajo PepsiDocumento12 páginasTrabajo PepsiJavieraLaraVeraAún no hay calificaciones
- Tarea 3Documento12 páginasTarea 3Christopher Mallol GarciaAún no hay calificaciones
- Práctica CalificadaDocumento4 páginasPráctica CalificadaLuis Enrique Flores CanchumanyaAún no hay calificaciones
- Semana 09 Guía Práctica 09-2023-9 Zoraida Chivarria PaccoDocumento4 páginasSemana 09 Guía Práctica 09-2023-9 Zoraida Chivarria PaccoZORAIDA CHIVARRIA PACCOAún no hay calificaciones
- Muestreo de Aceptacion - Inspeccion PDFDocumento100 páginasMuestreo de Aceptacion - Inspeccion PDFDiegoPonceAún no hay calificaciones
- EJERCICIOS VARIANZA EstadisticaDocumento11 páginasEJERCICIOS VARIANZA EstadisticaCamilo BedoyaAún no hay calificaciones
- ACTIVIDAD 1 ESTADÍSTICA Equipo 1 Grupo 07 - 04Documento15 páginasACTIVIDAD 1 ESTADÍSTICA Equipo 1 Grupo 07 - 04JONATHAN GARCIA GOMEZ100% (1)
- Gimnasio Athletic Fit GymDocumento33 páginasGimnasio Athletic Fit GymDeyci Quinteros CaleroAún no hay calificaciones
- Tracking Electoral en El Departamento Del AtlánticoDocumento6 páginasTracking Electoral en El Departamento Del AtlánticoZonaceroAún no hay calificaciones
- Protocolo de monitoreo de emisionesDocumento25 páginasProtocolo de monitoreo de emisionesRosie ReateguiAún no hay calificaciones
- Informe Final Del Estudio de Opinión Pública IRI-IMASEN en La Región JunínDocumento49 páginasInforme Final Del Estudio de Opinión Pública IRI-IMASEN en La Región JunínTodos Hacemos PoliticaAún no hay calificaciones
- Tarea VDocumento7 páginasTarea VBladimir SánchezAún no hay calificaciones
- A#5EQ4Documento7 páginasA#5EQ4Naomi AvilaAún no hay calificaciones
- Distribuciones de Probabilidad y MuestreoDocumento37 páginasDistribuciones de Probabilidad y MuestreoFamilia Diaz Nuñez100% (1)
- Estadística conceptos básicosDocumento24 páginasEstadística conceptos básicosCami PomaAún no hay calificaciones
- Estadistica Descriptiva Univariada y BivDocumento34 páginasEstadistica Descriptiva Univariada y BivRene OssandonAún no hay calificaciones
- Estudio de MercadoDocumento45 páginasEstudio de MercadoCallejas Tamo JorgeAún no hay calificaciones
- 1.5.1. Medidas de Dispersión-3Documento5 páginas1.5.1. Medidas de Dispersión-3rox canAún no hay calificaciones
- Analisis de VariacionDocumento33 páginasAnalisis de VariacionluisAún no hay calificaciones
- Practica 1 Muestreo de AguaDocumento5 páginasPractica 1 Muestreo de AguaferlandyAún no hay calificaciones
- Cotizacion Muetreo Ambiental V1 INGEGROUND PDFDocumento2 páginasCotizacion Muetreo Ambiental V1 INGEGROUND PDFJoaquin SanchezAún no hay calificaciones
- EstadísticasDocumento18 páginasEstadísticasValentín NazarioAún no hay calificaciones
- EstadisticaDocumento6 páginasEstadisticaDeyvi La Rosa OrtegaAún no hay calificaciones
- Actividad 4 - Herramientas Clásicas de La Calidad VFDocumento15 páginasActividad 4 - Herramientas Clásicas de La Calidad VFJosé Daniel Interventoria AP MocoaAún no hay calificaciones
- Castro Gutierrez Jacqueline 2TM57 P2Documento18 páginasCastro Gutierrez Jacqueline 2TM57 P2Jacqueline Castro GutierrezAún no hay calificaciones
- PoblaciónDocumento13 páginasPoblaciónGIANELLA ALCIRA PAZ GUERRAAún no hay calificaciones