También podría gustarte
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Estadística inferencial aplicadaDe EverandEstadística inferencial aplicadaCalificación: 5 de 5 estrellas5/5 (1)
- Unidad5 Distribuciones de MuestreoDocumento8 páginasUnidad5 Distribuciones de MuestreoAngie CastroAún no hay calificaciones
- Teorema del límite central: Aproximación a la normalidadDocumento9 páginasTeorema del límite central: Aproximación a la normalidadYajseel SalasAún no hay calificaciones
- Error MuestralDocumento9 páginasError MuestralToñitto DIBUJA???Aún no hay calificaciones
- Semana 8. Estadística DescriptivaDocumento47 páginasSemana 8. Estadística DescriptivaROSA MARIAAún no hay calificaciones
- PARA ESTUDIANTES Estadistica-inferencial-Distribuciones MuestralesDocumento42 páginasPARA ESTUDIANTES Estadistica-inferencial-Distribuciones MuestralesMario E. CastilloAún no hay calificaciones
- Ejercicios de Distribucion MuestralDocumento10 páginasEjercicios de Distribucion MuestralJose Francisco Socarras100% (2)
- Grupo 3Documento22 páginasGrupo 3Kimberling ValdezAún no hay calificaciones
- Guía de Estudio - Distribuciones Muestrales 1Documento29 páginasGuía de Estudio - Distribuciones Muestrales 1Kenneth HurtadoAún no hay calificaciones
- Descargable U1Documento18 páginasDescargable U1JEIMMY TATIANA CARVAJAL DIAZAún no hay calificaciones
- Estadidtica TallerDocumento16 páginasEstadidtica TallerAlejandra Ledesma BerrioAún no hay calificaciones
- S2 - Ea (Obs)Documento28 páginasS2 - Ea (Obs)danna rojasAún no hay calificaciones
- Distribuciones Fundamentales para El MuestreoDocumento15 páginasDistribuciones Fundamentales para El Muestreovictor manuel vergara duarteAún no hay calificaciones
- Estadística Descriptiva Aplicada ENTREGABLE 2Documento9 páginasEstadística Descriptiva Aplicada ENTREGABLE 2Luis Gustavo Beltran FernandezAún no hay calificaciones
- Estadistica InferencialDocumento15 páginasEstadistica InferencialJesús Camargo DuncanAún no hay calificaciones
- Distribuciones muestrales de la media y la proporciónDocumento20 páginasDistribuciones muestrales de la media y la proporciónfabriziod16Aún no hay calificaciones
- Resumen EstadísticaDocumento11 páginasResumen EstadísticaCATALINA PAULA CAMPOSAún no hay calificaciones
- Teoría Inferencia Estadística 2018 2CDocumento14 páginasTeoría Inferencia Estadística 2018 2CChristian BarrosoAún no hay calificaciones
- Tema 3 Distribuciones de MuestreoDocumento9 páginasTema 3 Distribuciones de MuestreoAndrea RodriguezAún no hay calificaciones
- Distribuciones MuestralesDocumento13 páginasDistribuciones MuestralesAnita Gabrielita GarciaAún no hay calificaciones
- Capítulos 8 y 10 Del Libro Estadística SpiegelDocumento40 páginasCapítulos 8 y 10 Del Libro Estadística Spiegelfelix rinconAún no hay calificaciones
- Trabajo de Salud Publica. 2023Documento15 páginasTrabajo de Salud Publica. 2023Erick MedinaAún no hay calificaciones
- Investigación Distribuciones MuestralesDocumento15 páginasInvestigación Distribuciones MuestralesXavier DiazAún no hay calificaciones
- 2 Distribución Normal y MuestreoDocumento54 páginas2 Distribución Normal y MuestreoKatherine Álvarez100% (1)
- Apuntes EstadísticaDocumento10 páginasApuntes EstadísticaCarmen Padilla MoyaAún no hay calificaciones
- Unidad IiDocumento35 páginasUnidad IiEduardo Pedraza GallegosAún no hay calificaciones
- Teoría Elemental Del MuestreoDocumento19 páginasTeoría Elemental Del Muestreomanuel amaranth100% (2)
- NB Estadistica2 p2 U3 Clas6Documento23 páginasNB Estadistica2 p2 U3 Clas6Javier MoránAún no hay calificaciones
- 9) Estimación de ParámetrosDocumento19 páginas9) Estimación de ParámetrosLu StylesAún no hay calificaciones
- Inferencia EstadísticaDocumento51 páginasInferencia Estadísticablado1Aún no hay calificaciones
- Tarea #6 - Distribucion MuestralDocumento14 páginasTarea #6 - Distribucion MuestralNilson JavierAún no hay calificaciones
- Métodos de Investigación Cuanti-CualitativosDocumento38 páginasMétodos de Investigación Cuanti-CualitativosMelani MillAún no hay calificaciones
- TLC y Distribuciones MuestralesDocumento18 páginasTLC y Distribuciones MuestralesMarito Raymundo100% (1)
- TEORIA MUESTREODocumento17 páginasTEORIA MUESTREOsightesAún no hay calificaciones
- Apuntes Cap 5Documento44 páginasApuntes Cap 5carl jhonsonAún no hay calificaciones
- Distribuciones de Probabilidad y Sus Modelos.Documento50 páginasDistribuciones de Probabilidad y Sus Modelos.Paulina SaforaAún no hay calificaciones
- Informe 2 Muestreo y Estimacion 4Documento7 páginasInforme 2 Muestreo y Estimacion 4cristinoAún no hay calificaciones
- EXPOSICIÓN DE ESTADÍSTICA 3.0pipipiDocumento72 páginasEXPOSICIÓN DE ESTADÍSTICA 3.0pipipiPaolo De Los Santos NonatoAún no hay calificaciones
- MUESTREO (Cont)Documento7 páginasMUESTREO (Cont)BenjisanAún no hay calificaciones
- Trabajo de Salud PublicaDocumento15 páginasTrabajo de Salud PublicaErick MedinaAún no hay calificaciones
- 1.4 Distribuciones Fundamentales para El MuestreoDocumento8 páginas1.4 Distribuciones Fundamentales para El MuestreoLuis Antonio Diaz RomeroAún no hay calificaciones
- Distribuciones de probabilidad: aplicaciones clave en economía, negocios y contabilidadDocumento10 páginasDistribuciones de probabilidad: aplicaciones clave en economía, negocios y contabilidadMateo VRAún no hay calificaciones
- Distribuciones MuestralesDocumento19 páginasDistribuciones Muestralesejldlaj24Aún no hay calificaciones
- Distribucion Muestral de La Media Con EjemplosDocumento30 páginasDistribucion Muestral de La Media Con EjemplosJose Carlos Abaroa VillanuevaAún no hay calificaciones
- Distribuciones muestrales de estadísticosDocumento23 páginasDistribuciones muestrales de estadísticosFreddy Rodriguez QuinteroAún no hay calificaciones
- INVESTIGACIÓNDocumento60 páginasINVESTIGACIÓNlasalashAún no hay calificaciones
- Lección 4 ProbabilidadesDocumento18 páginasLección 4 ProbabilidadesOscar MejíaAún no hay calificaciones
- Pruebas de hipótesis con dos muestras y varias muestras de datos numéricosDocumento31 páginasPruebas de hipótesis con dos muestras y varias muestras de datos numéricosE.E.E M:R100% (1)
- Estimaciones FinalDocumento56 páginasEstimaciones FinalGabriela RodriguezAún no hay calificaciones
- Diapositiva de Distribucion MuestralDocumento63 páginasDiapositiva de Distribucion MuestralRicardo Angel Berrio PerezAún no hay calificaciones
- Resumen Distribuciones Muestrales.Documento6 páginasResumen Distribuciones Muestrales.Luis E Huchin MedinaAún no hay calificaciones
- Distribución de Muestreo - Sesión 14Documento28 páginasDistribución de Muestreo - Sesión 14incólume belitre0% (2)
- A#1 DabdrDocumento35 páginasA#1 DabdrDanny2102Aún no hay calificaciones
- Cómo Se Selecciona Una Muestra ProbabilísticaDocumento4 páginasCómo Se Selecciona Una Muestra ProbabilísticaAngel CastilloAún no hay calificaciones
- Mest1 U2 A1 RogcDocumento8 páginasMest1 U2 A1 RogcImei Pantitlan100% (1)
- Pruebas de HipótesisDocumento27 páginasPruebas de Hipótesisjasmin vides0% (1)
- Distribución T de StudentDocumento33 páginasDistribución T de StudentciagrazAún no hay calificaciones
- Muestreo y Estimacion Estadistica PDFDocumento7 páginasMuestreo y Estimacion Estadistica PDFAdolfo OrellanaAún no hay calificaciones
- Elementos de estadística para ingeniería: Un curso básicoDe EverandElementos de estadística para ingeniería: Un curso básicoAún no hay calificaciones
- Impuesto A La Renta Global de Una Persona Natural No Obligada A Llevar ContabilidadDocumento5 páginasImpuesto A La Renta Global de Una Persona Natural No Obligada A Llevar ContabilidadNestor SalvatierraAún no hay calificaciones
- Sustentabilidad - SostenibilidadDocumento7 páginasSustentabilidad - SostenibilidadBetsy ReyesAún no hay calificaciones
- Estado de Resultados AbsorbenteDocumento5 páginasEstado de Resultados AbsorbenteCamilo MoralesAún no hay calificaciones
- Evaluacion Final Direccion ComercialDocumento7 páginasEvaluacion Final Direccion ComercialJose Hoyos100% (1)
- FuncionesPolinomialesIDocumento3 páginasFuncionesPolinomialesICuenta CuentaAún no hay calificaciones
- Analisis 2 - FINANCIAL STATEMENTS ANALYSISDocumento8 páginasAnalisis 2 - FINANCIAL STATEMENTS ANALYSISJulio Hernandez100% (2)
- Tarea 3 ( ( ContabilidadDocumento6 páginasTarea 3 ( ( Contabilidadprorganic. rdAún no hay calificaciones
- Taller 21Documento14 páginasTaller 21José Luís RodríguezAún no hay calificaciones
- Grupo102039 - Fase4 (1) .... ESTE ULTIMO COLABORATIVODocumento12 páginasGrupo102039 - Fase4 (1) .... ESTE ULTIMO COLABORATIVOMelkin Caamaño HernándezAún no hay calificaciones
- Caso Práctico 5ta CategoríaDocumento19 páginasCaso Práctico 5ta CategoríagiovannaAún no hay calificaciones
- Ejercicios Productividad 2022 02Documento7 páginasEjercicios Productividad 2022 02LINDA MICHAEL RODRIGUEZ ARAUJOAún no hay calificaciones
- Especies de CompaniasDocumento14 páginasEspecies de CompaniasGrace MoreiraAún no hay calificaciones
- TallerDocumento13 páginasTallerestradaAún no hay calificaciones
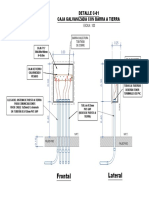
- Caja EquipotencialDocumento1 páginaCaja EquipotencialDancito RSAún no hay calificaciones
- Proyecto de Creación de Una Frutera Con Servicio 24 Horas en La Zona Sur de BarranquillaDocumento2 páginasProyecto de Creación de Una Frutera Con Servicio 24 Horas en La Zona Sur de BarranquillaLuis JimenezAún no hay calificaciones
- Así Pueden Mejorar Tu Empresa Las Sugerencias de Los EmpleadosDocumento8 páginasAsí Pueden Mejorar Tu Empresa Las Sugerencias de Los EmpleadosoriflameAún no hay calificaciones
- Preguntas Dinamizadoras 2Documento5 páginasPreguntas Dinamizadoras 2Euller Francisco Alvarado VargasAún no hay calificaciones
- Guía de ejercicios de microeconomía con solucionesDocumento114 páginasGuía de ejercicios de microeconomía con solucionesfacundo sosa100% (1)
- Wa0053.Documento1 páginaWa0053.andres morenoAún no hay calificaciones
- Evaluación 2. Grupo 1 II PARTEDocumento2 páginasEvaluación 2. Grupo 1 II PARTEMiguel Angel Muñoz MedranoAún no hay calificaciones
- Obligaciones - DianDocumento2 páginasObligaciones - DianIsaac David Altamiranda MendozaAún no hay calificaciones
- Libro Practicas de ExelDocumento18 páginasLibro Practicas de ExelNubia Ramos MontesAún no hay calificaciones
- Estrategias de fijación de precios enDocumento6 páginasEstrategias de fijación de precios enMatteo StanisciaAún no hay calificaciones
- Grupo Santo DomingoDocumento1 páginaGrupo Santo DomingoEdwin MAHECHA MUNOZAún no hay calificaciones
- 1.1.3 Precursores Del Estudio Del TrabajoDocumento2 páginas1.1.3 Precursores Del Estudio Del TrabajoIRASEMA GUADALUPE ORDUÑA ZUÑIGAAún no hay calificaciones
- Contigo c0124 CLDocumento48 páginasContigo c0124 CLCarolina OyarzunAún no hay calificaciones
- Caso PracticoDocumento9 páginasCaso PracticoLuis EnriqueAún no hay calificaciones
- Informe Gerencial FinancieroDocumento7 páginasInforme Gerencial Financieromarcela esquivel100% (2)
- Cuadro Comparativo CostosDocumento4 páginasCuadro Comparativo CostosJhonathan Estiven RAMIREZ CASTELLANOSAún no hay calificaciones
- Trabajo Decente en Panamá y Su Impacto Frente Al COVIDDocumento1 páginaTrabajo Decente en Panamá y Su Impacto Frente Al COVIDZuleyka BriggsAún no hay calificaciones