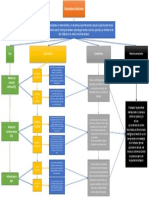
También podría gustarte
- PDT Planilla Electrónica PlameDocumento30 páginasPDT Planilla Electrónica PlameBilly Salazar del AguilaAún no hay calificaciones
- Actividad EmprendedoraDocumento8 páginasActividad EmprendedoraYenis SantiagoAún no hay calificaciones
- Tabla de Aniones y CationesDocumento1 páginaTabla de Aniones y CationesEstebanRiccardiAragunaAún no hay calificaciones
- Configuracion y Administracion de Espacio en DiscoDocumento22 páginasConfiguracion y Administracion de Espacio en DiscoRAFAELA FLORES MORALESAún no hay calificaciones
- Unidad 2 Arquitectura Del GestorDocumento33 páginasUnidad 2 Arquitectura Del Gestorロメロアンドラーデドイツ語Aún no hay calificaciones
- Análisis de Los Manejadores de Bases de DatosDocumento4 páginasAnálisis de Los Manejadores de Bases de DatosAna Karen SotoAún no hay calificaciones
- Programación del lado del servidorDocumento19 páginasProgramación del lado del servidorEnrique NájeraAún no hay calificaciones
- Fundamentos de Telecomunicaciones OSIDocumento18 páginasFundamentos de Telecomunicaciones OSIEduardo Damián100% (1)
- 3.obtencion de RequisitosDocumento5 páginas3.obtencion de RequisitosYesenia Díaz HernándezAún no hay calificaciones
- 2.1. - Organización Del Procesador-SINTESISDocumento2 páginas2.1. - Organización Del Procesador-SINTESISJose Luis Bautista Gomez100% (1)
- Puertos y Buses de Comunicación para MicrocontroladoresDocumento3 páginasPuertos y Buses de Comunicación para MicrocontroladoresJOSE ALFREDO AMARO OLAYAAún no hay calificaciones
- Comandos básicos y manejo archivosDocumento24 páginasComandos básicos y manejo archivosVictor DominguezAún no hay calificaciones
- 6-Comportamiento de Una Señal Eléctrica y ÓpticaDocumento7 páginas6-Comportamiento de Una Señal Eléctrica y ÓpticaAngel Kauil KumulAún no hay calificaciones
- UNIDAD 1 Arquitecturas de Cómputo 1.2Documento8 páginasUNIDAD 1 Arquitecturas de Cómputo 1.2Agus OliveraAún no hay calificaciones
- Instancias y Su Aplicacion de Un SGBD Sanchez Villegas Adrian IC 0601Documento4 páginasInstancias y Su Aplicacion de Un SGBD Sanchez Villegas Adrian IC 0601luis sanchezAún no hay calificaciones
- 3.4 RolesDocumento9 páginas3.4 RolesNavarro García Edwin Daniel50% (2)
- 4.3 Sistemas de Memoria Compartida: MultiprocesadoresDocumento13 páginas4.3 Sistemas de Memoria Compartida: MultiprocesadoresLiviJhacer RuizAún no hay calificaciones
- Tecnologías: 4. InalámbricasDocumento6 páginasTecnologías: 4. Inalámbricaschocky22Aún no hay calificaciones
- Mecanismos de Recuperacion de La SGBDDocumento3 páginasMecanismos de Recuperacion de La SGBDCarlosCoutiñoAún no hay calificaciones
- Requisitos de Instalacion de SGBDDocumento4 páginasRequisitos de Instalacion de SGBDdavidAún no hay calificaciones
- Expresiones RegularesDocumento7 páginasExpresiones RegularesLaura Elizabeth Gonzalez VillegasAún no hay calificaciones
- Unidad 2 Servicios de RedDocumento7 páginasUnidad 2 Servicios de RedLuis Enrique Neri VegaAún no hay calificaciones
- Dispositivos de Capas SuperioresDocumento4 páginasDispositivos de Capas SuperioresLUZ AMERICA RIVERA DE LA CRUZAún no hay calificaciones
- Metodos de BusquedaDocumento7 páginasMetodos de BusquedaAngel HTAún no hay calificaciones
- Modelos de Madurez Del ProcesoDocumento2 páginasModelos de Madurez Del ProcesoAldo CorroAún no hay calificaciones
- Guía TP - GESTIONDocumento12 páginasGuía TP - GESTIONFranco WaespechAún no hay calificaciones
- Arquitectura de Los Sistemas de ArchivosDocumento14 páginasArquitectura de Los Sistemas de ArchivosGuillermo MuñozAún no hay calificaciones
- 1.2 Analisis de Los Manejadores de Base de DatosDocumento7 páginas1.2 Analisis de Los Manejadores de Base de DatosZeu's RoblesAún no hay calificaciones
- Manejo de Espacio de Memoria Sec Und AriaDocumento18 páginasManejo de Espacio de Memoria Sec Und AriaJose Luis RodriguezAún no hay calificaciones
- Unidad IIIDocumento16 páginasUnidad IIIRamis Gutiérrez DG0% (1)
- 2.1.2 Estructuras Físicas de La Base de Datos (r92810)Documento26 páginas2.1.2 Estructuras Físicas de La Base de Datos (r92810)Humberto De Los Santos100% (1)
- 2.3 Tecnologías de ConmutaciónDocumento14 páginas2.3 Tecnologías de ConmutaciónRick Ramon AAún no hay calificaciones
- Configuración de servidores DHCP, DNS, FTP y correoDocumento15 páginasConfiguración de servidores DHCP, DNS, FTP y correoJOHAN SEBASTIAN PE�A BERNALAún no hay calificaciones
- Reporte Transformaciones 2D PDFDocumento51 páginasReporte Transformaciones 2D PDFJosè Gabriel Tellez GonzàlezAún no hay calificaciones
- Administracion y Organizacion de Datos UNIDAD II CompletoDocumento12 páginasAdministracion y Organizacion de Datos UNIDAD II CompletoangelAún no hay calificaciones
- Documento de Estandares de DiseñoDocumento20 páginasDocumento de Estandares de DiseñoOrithia PotterAún no hay calificaciones
- AmoebaDocumento19 páginasAmoebaEsteban Vargas Rosas0% (1)
- Unidad 3. Automatas Finitos IDocumento13 páginasUnidad 3. Automatas Finitos IMilo Dominguez AckermanAún no hay calificaciones
- Convergencia y RedundanciaDocumento8 páginasConvergencia y RedundanciaDominikAún no hay calificaciones
- Estructura de Memoria y Fisica de SGBDDocumento20 páginasEstructura de Memoria y Fisica de SGBDJesus CoreñoAún no hay calificaciones
- Unidad Ii-Graficación-2dDocumento12 páginasUnidad Ii-Graficación-2dJanely PerezAún no hay calificaciones
- Act2.1 Realizar Un Ensayo de Las Expresiones RegularesDocumento5 páginasAct2.1 Realizar Un Ensayo de Las Expresiones RegularesAndres Escobar MonterañoAún no hay calificaciones
- 3,1 Definicion de Espacio de Almacenamiento, Administracion de Base de Datos, Ana Karen Trinidad BuendiaDocumento6 páginas3,1 Definicion de Espacio de Almacenamiento, Administracion de Base de Datos, Ana Karen Trinidad Buendiaana karen trinidad buendia100% (1)
- DNSDocumento12 páginasDNSHusmerckAún no hay calificaciones
- Diseño Logico de La RedDocumento4 páginasDiseño Logico de La Redwilliam rojasAún no hay calificaciones
- Captura Basicas de CadenasDocumento2 páginasCaptura Basicas de CadenasSaul EspinozaAún no hay calificaciones
- Áreas de Aplicación de La GraficacionDocumento2 páginasÁreas de Aplicación de La GraficacionTeresa Zuñiga moralesAún no hay calificaciones
- Cableado Estructurado ResumenDocumento8 páginasCableado Estructurado Resumenjuan pabloAún no hay calificaciones
- Cuadro ComparativoDocumento2 páginasCuadro ComparativoMargenis CoelloAún no hay calificaciones
- Conmutación y Enrutamiento de Datos. Unidad 1Documento29 páginasConmutación y Enrutamiento de Datos. Unidad 1Leticia MendozaAún no hay calificaciones
- Modelo RelacionalDocumento27 páginasModelo RelacionalWilfredo Meza CastilloAún no hay calificaciones
- 1.1 Clasificación y Estructuras Genéricas de Los Sistemas Operativas VigentesDocumento9 páginas1.1 Clasificación y Estructuras Genéricas de Los Sistemas Operativas VigentesAlex Garza100% (1)
- Temas 5.4 & 5.5Documento21 páginasTemas 5.4 & 5.5chocky220% (1)
- Unidad 4 TelecomunicacionesDocumento12 páginasUnidad 4 TelecomunicacionesAlan VasquezAún no hay calificaciones
- Gestión archivos log MySQLDocumento14 páginasGestión archivos log MySQLJose Emmanuel Castro PalmaAún no hay calificaciones
- Servidores DHCP-DNS-FTPDocumento5 páginasServidores DHCP-DNS-FTPJose Luis Navarro RuizAún no hay calificaciones
- Enlaces TroncalesDocumento9 páginasEnlaces TroncalesDominikAún no hay calificaciones
- SOR-T1-Introducción-a-los-sistemas-operativos-en-red. Redes Windows PDFDocumento31 páginasSOR-T1-Introducción-a-los-sistemas-operativos-en-red. Redes Windows PDFrpjuAún no hay calificaciones
- Introducción A La Administración de ServidoresDocumento19 páginasIntroducción A La Administración de ServidoresLogan ReachAún no hay calificaciones
- Base de Datos ConnollyDocumento86 páginasBase de Datos ConnollyAchenryy Arias CondorAún no hay calificaciones
- 1 Bases de Datos e InstanciasDocumento83 páginas1 Bases de Datos e InstanciasLincol DoloresAún no hay calificaciones
- Conceptos Basicos Sobre Oracle DataBase 11gDocumento26 páginasConceptos Basicos Sobre Oracle DataBase 11gCarlos CruzAún no hay calificaciones
- Conceptos Básicos de La Arquitectura OracleDocumento15 páginasConceptos Básicos de La Arquitectura OracleGorrion DoradoAún no hay calificaciones
- Planificacion de Un Data WarehouseDocumento2 páginasPlanificacion de Un Data WarehouseRober Favela :vAún no hay calificaciones
- Mapa Conceptual - Actuadores ElectricosDocumento1 páginaMapa Conceptual - Actuadores ElectricosRober Favela :vAún no hay calificaciones
- Data Warehouse y Mining para Análisis y Toma de DecisionesDocumento1 páginaData Warehouse y Mining para Análisis y Toma de DecisionesRober Favela :vAún no hay calificaciones
- Data SciDocumento9 páginasData SciRober Favela :vAún no hay calificaciones
- Des Sustent Ladrillos de PlásticoDocumento7 páginasDes Sustent Ladrillos de PlásticoRober Favela :vAún no hay calificaciones
- W Efe PDFDocumento1 páginaW Efe PDFRober Favela :vAún no hay calificaciones
- Ejercicios de Integrales MultiplesDocumento20 páginasEjercicios de Integrales MultiplesreedcheckAún no hay calificaciones
- Momentos de InerciaDocumento11 páginasMomentos de InerciaOhm DlfAún no hay calificaciones
- Guía de Trabajo Actividad Práctica Simulada Fase - 4Documento8 páginasGuía de Trabajo Actividad Práctica Simulada Fase - 4maritorresg2Aún no hay calificaciones
- Taller de AlgoritmosDocumento18 páginasTaller de AlgoritmosMauro GomezAún no hay calificaciones
- Formación auxiliares mantenimiento informáticoDocumento3 páginasFormación auxiliares mantenimiento informáticoJader D. Barbosa100% (4)
- Modulo Excel Basico Formulas y Funciones - ARCHIVO de EJERCICIODocumento14 páginasModulo Excel Basico Formulas y Funciones - ARCHIVO de EJERCICIOpolaroidAún no hay calificaciones
- Ciiu - Ica BogotaDocumento35 páginasCiiu - Ica BogotaStephany Peña MonsalveAún no hay calificaciones
- Control Semana 1 INTRODUCCIÓN A LOS LENGUAJES DE PROGRAMACIÓNDocumento4 páginasControl Semana 1 INTRODUCCIÓN A LOS LENGUAJES DE PROGRAMACIÓNArnoldo Eyzaguirre SotoAún no hay calificaciones
- Practica 1 Laboratorio de DSM FimeDocumento18 páginasPractica 1 Laboratorio de DSM FimeEfrain VigilAún no hay calificaciones
- Daily EquipoDocumento61 páginasDaily EquipomariaAún no hay calificaciones
- Taller Tablas Julieth 1Documento237 páginasTaller Tablas Julieth 1Julieth RodriguezAún no hay calificaciones
- CI Trabajo Tarea 1Documento12 páginasCI Trabajo Tarea 1felipeAún no hay calificaciones
- Practica SSW05Documento32 páginasPractica SSW05lghilardi79Aún no hay calificaciones
- Primer Parcial Ecuaciones Diferenciales 2021-10 - Juan Pablo RincónDocumento2 páginasPrimer Parcial Ecuaciones Diferenciales 2021-10 - Juan Pablo Rincónjuan pablo rincon camargoAún no hay calificaciones
- Lab 1. Simulación Funcionamiento de Una Red.Documento1 páginaLab 1. Simulación Funcionamiento de Una Red.Julián Moreno LesmesAún no hay calificaciones
- El Ex de Miare - DALASReview. Ecce Homo. - Página 2555Documento15 páginasEl Ex de Miare - DALASReview. Ecce Homo. - Página 2555tekrisu relentikusAún no hay calificaciones
- Guia Proceso DevolucionesDocumento2 páginasGuia Proceso DevolucionesLoinsert CargoAún no hay calificaciones
- UNIDAD DE APRENDIZAJE (Autoguardado)Documento27 páginasUNIDAD DE APRENDIZAJE (Autoguardado)RolaMedraAún no hay calificaciones
- Maschine 2.0 Mikro Mk2 Manual SpanishDocumento730 páginasMaschine 2.0 Mikro Mk2 Manual SpanishJose RuizAún no hay calificaciones
- Temario Del Cliclo Escolar Informatica 2021-2022Documento34 páginasTemario Del Cliclo Escolar Informatica 2021-2022Cristian CruzAún no hay calificaciones
- Permiso Trabajo en AlturasDocumento2 páginasPermiso Trabajo en AlturasIsostatica Construcciones100% (1)
- Snort IDS LinuxDocumento10 páginasSnort IDS LinuxPascual CalzadaAún no hay calificaciones
- Pedestrian Detection at Daytime and Nighttime Conditions Based On YOLO-v5 Detección de Peatones en El Día y en La Noche Usando YOLO-v5Documento11 páginasPedestrian Detection at Daytime and Nighttime Conditions Based On YOLO-v5 Detección de Peatones en El Día y en La Noche Usando YOLO-v5Kamal HajariAún no hay calificaciones
- CV 2022Documento1 páginaCV 2022Elvis Gra LightAún no hay calificaciones
- Ciclogramas - Espacio vs. TiempoDocumento9 páginasCiclogramas - Espacio vs. TiempoHeber Barboza FustamanteAún no hay calificaciones
- Procedimiento de Bodega y ProduccionDocumento5 páginasProcedimiento de Bodega y ProduccionLM AdfinserAún no hay calificaciones
- Generaciones computadorasDocumento2 páginasGeneraciones computadorasDany Jafeth Murillo GuevaraAún no hay calificaciones
- 05temario de Informática y ComunicacionesDocumento168 páginas05temario de Informática y ComunicacionesSonia PradoAún no hay calificaciones
- Disponibilidad PDFDocumento10 páginasDisponibilidad PDFFredy AlvaradoAún no hay calificaciones
- T4 04 PL WsusDocumento6 páginasT4 04 PL WsusAnette DiazAún no hay calificaciones