0% encontró este documento útil (0 votos)
275 vistas14 páginasUnidad 4 Procesamineto Paralelo
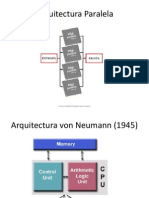
Este documento presenta información sobre procesamiento paralelo. Discuten los diferentes tipos de computación paralela incluyendo paralelismo a nivel de bit, instrucción y datos. También describe las taxonomías de computadoras paralelas y sistemas de memoria compartida y distribuida. Finalmente, analiza consideraciones sobre el rendimiento de clusters.
Cargado por
artemio hernandez gallegosDerechos de autor
© © All Rights Reserved
Nos tomamos en serio los derechos de los contenidos. Si sospechas que se trata de tu contenido, reclámalo aquí.
Formatos disponibles
Descarga como PDF, TXT o lee en línea desde Scribd
0% encontró este documento útil (0 votos)
275 vistas14 páginasUnidad 4 Procesamineto Paralelo
Este documento presenta información sobre procesamiento paralelo. Discuten los diferentes tipos de computación paralela incluyendo paralelismo a nivel de bit, instrucción y datos. También describe las taxonomías de computadoras paralelas y sistemas de memoria compartida y distribuida. Finalmente, analiza consideraciones sobre el rendimiento de clusters.
Cargado por
artemio hernandez gallegosDerechos de autor
© © All Rights Reserved
Nos tomamos en serio los derechos de los contenidos. Si sospechas que se trata de tu contenido, reclámalo aquí.
Formatos disponibles
Descarga como PDF, TXT o lee en línea desde Scribd