También podría gustarte
- Fisica Tolo TallerDocumento5 páginasFisica Tolo Tallercristiandromer100% (2)
- 5 Shortenings AceitesDocumento2 páginas5 Shortenings AceitescristiandromerAún no hay calificaciones
- Mapa Conceptual El Elogio de La DificultadDocumento3 páginasMapa Conceptual El Elogio de La DificultadcristiandromerAún no hay calificaciones
- Manual Tecnico Pexgol PDFDocumento48 páginasManual Tecnico Pexgol PDFmaldonadovvvAún no hay calificaciones
- DamonDocumento33 páginasDamonFra RazAún no hay calificaciones
- Ejercicio Inteligencia EmocionalDocumento1 páginaEjercicio Inteligencia EmocionalcristiandromerAún no hay calificaciones
- Productos NaturalesDocumento2 páginasProductos NaturalescristiandromerAún no hay calificaciones
- Mapa Del Recorrido Del Cliente y DiagramaDocumento3 páginasMapa Del Recorrido Del Cliente y DiagramacristiandromerAún no hay calificaciones
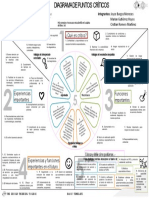
- Diagrama de Elementos CríticosDocumento1 páginaDiagrama de Elementos CríticoscristiandromerAún no hay calificaciones
- Mapa Del Recorrido Del ClienteDocumento1 páginaMapa Del Recorrido Del ClientecristiandromerAún no hay calificaciones
- Presupuesto Implementación de SGCDocumento2 páginasPresupuesto Implementación de SGCcristiandromerAún no hay calificaciones
- Taller 6. Acciones Preventivas y CorrectivasDocumento8 páginasTaller 6. Acciones Preventivas y CorrectivascristiandromerAún no hay calificaciones
- Análisis de Tecnicas Lean - Mantenimiento en ProcesoDocumento1 páginaAnálisis de Tecnicas Lean - Mantenimiento en ProcesocristiandromerAún no hay calificaciones
- Taller 3 - Fuentes de InformacionDocumento3 páginasTaller 3 - Fuentes de InformacioncristiandromerAún no hay calificaciones
- Taller - Plan de Accion PoaDocumento3 páginasTaller - Plan de Accion PoacristiandromerAún no hay calificaciones
- Taller - Matriz RiceDocumento3 páginasTaller - Matriz RicecristiandromerAún no hay calificaciones
- Guia #2 Grado 4ºiiDocumento30 páginasGuia #2 Grado 4ºiicristiandromerAún no hay calificaciones
- Casos Clinicos Toxicologia.Documento5 páginasCasos Clinicos Toxicologia.cristiandromerAún no hay calificaciones
- Violencias de GéneroDocumento12 páginasViolencias de GénerocristiandromerAún no hay calificaciones
- Universidad de Sucre FUENTE DE INFORMACION GISELA ANDREA ROMERO MARTINEZDocumento16 páginasUniversidad de Sucre FUENTE DE INFORMACION GISELA ANDREA ROMERO MARTINEZcristiandromerAún no hay calificaciones
- Guion Radial RadioDocumento6 páginasGuion Radial Radiocristiandromer100% (2)
- Productos Lácteos HeladoDocumento10 páginasProductos Lácteos HeladocristiandromerAún no hay calificaciones
- Articulo ExcergiaDocumento18 páginasArticulo ExcergiacristiandromerAún no hay calificaciones
- Agua Envasada en Sincelejo PDFDocumento9 páginasAgua Envasada en Sincelejo PDFcristiandromerAún no hay calificaciones
- Examen de Educación FísicaDocumento6 páginasExamen de Educación Físicacristiandromer100% (4)
- Taller 2. Diseño de Plantas - Métodos de Localización (Parte 1) PDFDocumento3 páginasTaller 2. Diseño de Plantas - Métodos de Localización (Parte 1) PDFcristiandromerAún no hay calificaciones
- Diseño de PlatasDocumento7 páginasDiseño de PlatascristiandromerAún no hay calificaciones
- Diseño de PlantasDocumento3 páginasDiseño de PlantascristiandromerAún no hay calificaciones
- Perfil 1 PDFDocumento30 páginasPerfil 1 PDFcristiandromerAún no hay calificaciones
- Informe Determinación Del Contenido de PectinaDocumento6 páginasInforme Determinación Del Contenido de PectinacristiandromerAún no hay calificaciones
- Metodos Sensoriales Básicos para La Evaluacion de AlimentosDocumento184 páginasMetodos Sensoriales Básicos para La Evaluacion de AlimentosKaren VargasAún no hay calificaciones
- Informe PARDEAMIENTO ENZIMATICODocumento10 páginasInforme PARDEAMIENTO ENZIMATICOcristiandromerAún no hay calificaciones
- Quimica - Quiz 1 - Semana 3Documento3 páginasQuimica - Quiz 1 - Semana 3Lina Marcela Calderón RondónAún no hay calificaciones
- Proyecto Resistencia de Unidad y Muro de Adobe Con Cemento - Lliuya y Rodríguez - HuarazDocumento31 páginasProyecto Resistencia de Unidad y Muro de Adobe Con Cemento - Lliuya y Rodríguez - HuarazOscar Rios EguizabalAún no hay calificaciones
- Unidad 2 Expresiones AlgebraicasDocumento45 páginasUnidad 2 Expresiones AlgebraicasSimón Muñoz CaroAún no hay calificaciones
- Los Accidentes de TransitoDocumento336 páginasLos Accidentes de TransitoFrancisco100% (1)
- 4358 - Mapa de Peligros Plan de Usos Del Suelo Ante Desastres y Medidas de Mitigacion de La Ciudad de AmboDocumento178 páginas4358 - Mapa de Peligros Plan de Usos Del Suelo Ante Desastres y Medidas de Mitigacion de La Ciudad de AmboFresia M IngaAún no hay calificaciones
- Procedimiento de Tendido de CablesDocumento10 páginasProcedimiento de Tendido de CablesJorge CriolloAún no hay calificaciones
- 5º - FISICA - Campo TematicoDocumento4 páginas5º - FISICA - Campo TematicoJDennisAún no hay calificaciones
- Hitachi Air ConDocumento12 páginasHitachi Air ConDing RenAún no hay calificaciones
- Manual de Prácticas para El Laboratorio de Comunicaciones AnalógicasDocumento68 páginasManual de Prácticas para El Laboratorio de Comunicaciones AnalógicasEduardo Gauss GaloisAún no hay calificaciones
- SECCION 11 Extraccion Por Solventes Por Extractantes de OrganofosfinaDocumento14 páginasSECCION 11 Extraccion Por Solventes Por Extractantes de OrganofosfinaJesus Alberto Huamayalli IzaguirreAún no hay calificaciones
- WarruoDocumento3 páginasWarruojorge7casmaAún no hay calificaciones
- Colas de Poisson EspecializadasDocumento60 páginasColas de Poisson EspecializadasEdgar Aguilar100% (1)
- Tipología de TraviesasDocumento17 páginasTipología de TraviesasJose FaustinoAún no hay calificaciones
- Mecánica de FluidosDocumento82 páginasMecánica de FluidosRoberto AulestiaAún no hay calificaciones
- Producción de 1-Bromobutano A Partir Del Alcohol N ButanolDocumento6 páginasProducción de 1-Bromobutano A Partir Del Alcohol N ButanolSebastian Barbosa AvellanedaAún no hay calificaciones
- Matematica IIIDocumento63 páginasMatematica IIIAlexito Melgarejo Guillermo100% (1)
- Capitulo VII DE SEG MILITARDocumento57 páginasCapitulo VII DE SEG MILITARDavid Alonso FernandezAún no hay calificaciones
- Informe de Laboratorio N°6Documento28 páginasInforme de Laboratorio N°6Cristian Suarez0% (1)
- Memoria de CálculoDocumento49 páginasMemoria de CálculoMarco AmadorAún no hay calificaciones
- Ficha ProporcionalidadDocumento2 páginasFicha ProporcionalidadMaría RodríguezAún no hay calificaciones
- Potenciometria 345678Documento30 páginasPotenciometria 345678meltovarAún no hay calificaciones
- Sintesis Del Sulfonato de Alquilbenceno Lineal - LabsDocumento5 páginasSintesis Del Sulfonato de Alquilbenceno Lineal - LabsLUIS XVAún no hay calificaciones
- Biografia de Coulomb y GaussDocumento13 páginasBiografia de Coulomb y GaussSheylyn PerézAún no hay calificaciones
- UNIDAD 5 Transformaciones LinealesDocumento10 páginasUNIDAD 5 Transformaciones LinealesGeovani Herrera67% (3)
- Eva Final Estadistica IDocumento7 páginasEva Final Estadistica IcatalinaAún no hay calificaciones
- Calcula La Constante Del Aparato Mediante La RelaciónDocumento4 páginasCalcula La Constante Del Aparato Mediante La RelaciónDavid GarciaAún no hay calificaciones
- Delta 800 EspDocumento9 páginasDelta 800 EspRoni NiskanenAún no hay calificaciones
- Experimento PotenciaDocumento2 páginasExperimento PotenciamiaAún no hay calificaciones