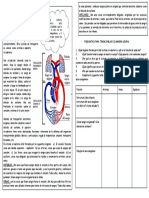
También podría gustarte
- ESTADÍSTICADocumento13 páginasESTADÍSTICANatalia Hernandez100% (1)
- Razonamiento cuantitativo, 2ª edición: Notas de claseDe EverandRazonamiento cuantitativo, 2ª edición: Notas de claseCalificación: 5 de 5 estrellas5/5 (1)
- Inv Estadistica 1Documento5 páginasInv Estadistica 1Yael PsAún no hay calificaciones
- 1 Actividad Estadistica 31-07-2023Documento3 páginas1 Actividad Estadistica 31-07-2023Lina Marcela Pulido LandinezAún no hay calificaciones
- La Estadistica ResumenDocumento8 páginasLa Estadistica ResumenAllan SuárezAún no hay calificaciones
- BIOESTADISTICADocumento10 páginasBIOESTADISTICAAdrianni muñozAún no hay calificaciones
- Actividad de Consulta MatematicasDocumento19 páginasActividad de Consulta MatematicasEDWAR BUITRAGOAún no hay calificaciones
- ESTADISTICADocumento6 páginasESTADISTICAPIXELART SJAún no hay calificaciones
- Generalidades de La EstadisticaDocumento4 páginasGeneralidades de La EstadisticaOswaldo DuranAún no hay calificaciones
- Laboratorioestadistico 3Documento22 páginasLaboratorioestadistico 3Dl DenhisAún no hay calificaciones
- Rigoberto - Ef1 - Probabilidad y EstadisticaDocumento10 páginasRigoberto - Ef1 - Probabilidad y EstadisticaRIGOBERTO MARIN OVIEDOAún no hay calificaciones
- Estadistica 2Documento18 páginasEstadistica 2BrendelbashnJoseDanielCarrasquelAún no hay calificaciones
- Fundamentos Básicos de La EstadisticaDocumento23 páginasFundamentos Básicos de La EstadisticaMarta PérezAún no hay calificaciones
- BIOESTADÍSTICADocumento13 páginasBIOESTADÍSTICAAlex BukeleAún no hay calificaciones
- Foro Académico de Estadísticas y Representación GráficaDocumento10 páginasForo Académico de Estadísticas y Representación GráficaGabriela OrtizAún no hay calificaciones
- Informe EstadisticaDocumento9 páginasInforme EstadisticaRobbelys Maryelin Rangel YamarteAún no hay calificaciones
- La EstadísticaDocumento9 páginasLa EstadísticaYermaing MataAún no hay calificaciones
- Definición de DeterminantesDocumento16 páginasDefinición de Determinantesjose19miguelAún no hay calificaciones
- Investigacion UNIDAD 1Documento9 páginasInvestigacion UNIDAD 1Arleth Lopez AntonioAún no hay calificaciones
- Las Medidas de Tendencia Central Son Medidas Estadísticas Que Pretenden Resumir en Un Solo Valor A Un Conjunto de ValoresDocumento6 páginasLas Medidas de Tendencia Central Son Medidas Estadísticas Que Pretenden Resumir en Un Solo Valor A Un Conjunto de ValoresEnrique HernandezAún no hay calificaciones
- Lectura y Acercamiento A La SoluciónDocumento10 páginasLectura y Acercamiento A La SoluciónLaura TolozaAún no hay calificaciones
- Población y Muestra AleatoriaDocumento12 páginasPoblación y Muestra AleatoriaLuzysonido Dance Stars100% (1)
- Conceptos Basicos de La Estadistica: Estadística y Control de CalidadDocumento7 páginasConceptos Basicos de La Estadistica: Estadística y Control de CalidadWilbert CabreraAún no hay calificaciones
- Actividad 1 Razonamiento CuantitativoDocumento5 páginasActividad 1 Razonamiento CuantitativoEdgar CabarcasAún no hay calificaciones
- Estadistica (Valentina)Documento5 páginasEstadistica (Valentina)irama araqueAún no hay calificaciones
- Glosario de Estadist 157584 Downloadable 5222674Documento7 páginasGlosario de Estadist 157584 Downloadable 5222674Josue Oliver Gonzalez ArellanoAún no hay calificaciones
- Concepto y Utilidad de La EstadísticaDocumento6 páginasConcepto y Utilidad de La EstadísticaSiulGR100% (1)
- MATEMATICASDocumento9 páginasMATEMATICASduendemendoza666Aún no hay calificaciones
- Portafolio Estadistica DescriptivaDocumento38 páginasPortafolio Estadistica DescriptivaDarlin Oscar Santana AlvaradoAún no hay calificaciones
- La EstadisticaDocumento4 páginasLa Estadisticaashley quinteroAún no hay calificaciones
- MODULO III EstadísticaDocumento27 páginasMODULO III EstadísticaAmelia CamargoAún no hay calificaciones
- 2 Marco TeoricoDocumento8 páginas2 Marco TeoricoAlexander MontañoAún no hay calificaciones
- Tarea 3 EstadisticaDocumento7 páginasTarea 3 EstadisticaTommy Orrala MAún no hay calificaciones
- Matematicas Nivel IntermedioDocumento12 páginasMatematicas Nivel IntermedioURIELES CONTRERASAún no hay calificaciones
- Matematicas Guia 10 y 11 Ciclo VDocumento10 páginasMatematicas Guia 10 y 11 Ciclo VMilena MachadoAún no hay calificaciones
- Romina Gonzalez, Tarea 5Documento5 páginasRomina Gonzalez, Tarea 5RominaAún no hay calificaciones
- Cifras Significativas y RedondeoDocumento29 páginasCifras Significativas y RedondeoBazan Antequera Ruddy100% (2)
- Probabilidad y EstadísticaDocumento9 páginasProbabilidad y EstadísticaNayvelin GonzálezAún no hay calificaciones
- CUESTIONARIO para LeerDocumento12 páginasCUESTIONARIO para LeerEsmarly OzoriaAún no hay calificaciones
- Estadistica Descriptiva ConceptosDocumento9 páginasEstadistica Descriptiva ConceptosAriel Montenegro LedezmaAún no hay calificaciones
- Abp 2Documento12 páginasAbp 2Victor :/Aún no hay calificaciones
- Qué Es La EstadísticaDocumento10 páginasQué Es La EstadísticaJesus DiazAún no hay calificaciones
- Sintesis EstadisticaDocumento8 páginasSintesis EstadisticaKatherin EscobarAún no hay calificaciones
- Estadistica. 1°Documento9 páginasEstadistica. 1°Damian HasturAún no hay calificaciones
- Trabajo Final ProbabilidadDocumento111 páginasTrabajo Final ProbabilidadKhabib SánchezAún no hay calificaciones
- Unidad I Herramientas Estadisticas 1.1 Introducción A La Estadistica EstadísticaDocumento10 páginasUnidad I Herramientas Estadisticas 1.1 Introducción A La Estadistica EstadísticaJuan Diego HolguinAún no hay calificaciones
- SumatoriaDocumento15 páginasSumatoriaLuigi Milo ElijahAún no hay calificaciones
- Lectura y Acercamiento A La Solución. Est.Documento4 páginasLectura y Acercamiento A La Solución. Est.Kennerth PomboAún no hay calificaciones
- Estadistica PreguntasDocumento3 páginasEstadistica PreguntasRlxndo GuzmánAún no hay calificaciones
- EP2. Realización de Investigación de Conceptos Básicos de La Estadística.Documento4 páginasEP2. Realización de Investigación de Conceptos Básicos de La Estadística.Mayel Adrian Hernandez MooAún no hay calificaciones
- Estadistica DescriptivaDocumento11 páginasEstadistica DescriptivaOscar SaenzAún no hay calificaciones
- Estadistica Basica - Unidad DosDocumento9 páginasEstadistica Basica - Unidad DosAndrey GuzmanAún no hay calificaciones
- Fase 4 Medidas EstadísticasDocumento31 páginasFase 4 Medidas EstadísticasdarwinyandreaAún no hay calificaciones
- Actividad 13Documento9 páginasActividad 13Juan MallamaAún no hay calificaciones
- Introduccion A La EstadisticaDocumento5 páginasIntroduccion A La EstadisticaAngiee HerreraAún no hay calificaciones
- Tarea 1 EstadisticaDocumento12 páginasTarea 1 EstadisticaJennifer CastilloAún no hay calificaciones
- Informe Sobre Las Estadísticas DescriptivasDocumento16 páginasInforme Sobre Las Estadísticas Descriptivasronald corderoAún no hay calificaciones
- Introducción A Estadística DescriptivaDocumento6 páginasIntroducción A Estadística DescriptivaMichael Lahoz SosaAún no hay calificaciones
- EstadísticaDocumento7 páginasEstadísticaLis DelgadoAún no hay calificaciones
- C45 Análisis de Bonos Duración y ConvexidadDocumento6 páginasC45 Análisis de Bonos Duración y ConvexidadJorge RuizAún no hay calificaciones
- MetafísicaDocumento4 páginasMetafísicaViviana CalelAún no hay calificaciones
- Qué Es La Cultura MayaDocumento4 páginasQué Es La Cultura MayaViviana CalelAún no hay calificaciones
- La Sociología Es UnaDocumento2 páginasLa Sociología Es UnaViviana CalelAún no hay calificaciones
- Monedas BilletesDocumento3 páginasMonedas BilletesViviana CalelAún no hay calificaciones
- Antonimos en Ingles y EspañolDocumento3 páginasAntonimos en Ingles y EspañolViviana CalelAún no hay calificaciones
- Cuento Fabulaleyebda Mito Tira ComicaDocumento9 páginasCuento Fabulaleyebda Mito Tira ComicaViviana CalelAún no hay calificaciones
- Carta de RecomendacionDocumento1 páginaCarta de RecomendacionViviana CalelAún no hay calificaciones
- YOOOOOODocumento1 páginaYOOOOOOViviana CalelAún no hay calificaciones
- AGROECOLOGIADocumento195 páginasAGROECOLOGIABretna MinayaAún no hay calificaciones
- Conjuros Clerigo Nivel 2Documento2 páginasConjuros Clerigo Nivel 2Nicolàs Temachtiani Aranda AlvarezAún no hay calificaciones
- Semana 2 Psicologia AeronauticaDocumento28 páginasSemana 2 Psicologia AeronauticadavalderAún no hay calificaciones
- Unidad 9Documento20 páginasUnidad 9YURI RAMAún no hay calificaciones
- El Organigrama de Siete DivisionesDocumento2 páginasEl Organigrama de Siete DivisionessalashAún no hay calificaciones
- URP 2021-II EEI Guia 2 Ley de Corrientes de KirchoffDocumento5 páginasURP 2021-II EEI Guia 2 Ley de Corrientes de KirchoffMilton MezaAún no hay calificaciones
- Categorización Ambiental de Los Hogares de Costa Rica PDFDocumento176 páginasCategorización Ambiental de Los Hogares de Costa Rica PDFSilvia Soto CordobaAún no hay calificaciones
- Rit CorpsicDocumento26 páginasRit CorpsicRenzoGarciaEstebanAún no hay calificaciones
- Planeacion Del 23 Al 27 de OctubreDocumento12 páginasPlaneacion Del 23 Al 27 de OctubreLili Gonzalez100% (1)
- 16 - Técnicas de RebobinadoDocumento7 páginas16 - Técnicas de Rebobinadoremberto caceresAún no hay calificaciones
- Topicos Selectos de Tecnologias de La InformacionDocumento64 páginasTopicos Selectos de Tecnologias de La InformacionEduardo FigueirasAún no hay calificaciones
- 19 Copias A ColorDocumento1 página19 Copias A ColorMica LeguizamonAún no hay calificaciones
- Ejercicio 1-4 Hibbeller Rev1Documento2 páginasEjercicio 1-4 Hibbeller Rev1Estefany SanchezAún no hay calificaciones
- Puente de ScheringDocumento12 páginasPuente de ScheringCarlos GalindoAún no hay calificaciones
- 8448171721Documento42 páginas8448171721Jonathan OvandoAún no hay calificaciones
- Tectonica de Placas - GG1Documento60 páginasTectonica de Placas - GG1VladimirIvanZavalaRiverosAún no hay calificaciones
- Educativos Concursos 2021 - atDocumento41 páginasEducativos Concursos 2021 - atJUAN CARLOSAún no hay calificaciones
- CAPÍTULO No 2 - GEOMETRÍA ANÁLITICA EN R3Documento10 páginasCAPÍTULO No 2 - GEOMETRÍA ANÁLITICA EN R3diegoAún no hay calificaciones
- Manual TOP DOG CorregidoDocumento41 páginasManual TOP DOG CorregidoAlexis Briseño100% (2)
- Lab 13 Aplicaciones Transformada de Laplace 2023 - 1Documento6 páginasLab 13 Aplicaciones Transformada de Laplace 2023 - 1Junior LimaAún no hay calificaciones
- Pregunta1 13Documento7 páginasPregunta1 13Escobar Gabidia PragaAún no hay calificaciones
- Tipos de SustratosDocumento13 páginasTipos de SustratosAbelAntonioCruzParadaAún no hay calificaciones
- Un Hermoso Observatorio de La Oralidad: Los Géneros de Textos InstitucionalizadosDocumento16 páginasUn Hermoso Observatorio de La Oralidad: Los Géneros de Textos InstitucionalizadosPaulaCNavarroAún no hay calificaciones
- IET - Modulo 3 201600303Documento20 páginasIET - Modulo 3 201600303Cecilia LonghiAún no hay calificaciones
- 10 - La Pregunta de InvestigaciónDocumento2 páginas10 - La Pregunta de InvestigaciónChristian AugustoAún no hay calificaciones
- Guía N°3 Conjuntos Numéricos y #Enteros-4to Medio-135 CopiasDocumento4 páginasGuía N°3 Conjuntos Numéricos y #Enteros-4to Medio-135 CopiasalberAún no hay calificaciones
- 8 Acta General AcordsDocumento4 páginas8 Acta General AcordsAdriAún no hay calificaciones
- Asesinato de MayfairDocumento3 páginasAsesinato de MayfairImmanuel CristianAún no hay calificaciones
- Guia Resuelta 3Documento1 páginaGuia Resuelta 3Luzmila CantilloAún no hay calificaciones
- Tema 4 TRANSFORMACIONES GEOMETRICAS 2o Bach Part A INVERSION-V8Documento58 páginasTema 4 TRANSFORMACIONES GEOMETRICAS 2o Bach Part A INVERSION-V8Francisco Aguilar GuzmanAún no hay calificaciones