Documentos de Académico
Documentos de Profesional
Documentos de Cultura
Manual Base de Datos Relacionales
Cargado por
Administrador AndroidTítulo original
Derechos de autor
Formatos disponibles
Compartir este documento
Compartir o incrustar documentos
¿Le pareció útil este documento?
¿Este contenido es inapropiado?
Denunciar este documentoCopyright:
Formatos disponibles
Manual Base de Datos Relacionales
Cargado por
Administrador AndroidCopyright:
Formatos disponibles
Enero, 2015
MANUAL DE BASE DE DATOS RELACIONALES
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 1
Por Joseph Arquímedes Collado & José Luis López González
MANUAL BASE DE DATOS
RELACIONALES
Manual Base de Datos Relaciones
Primera edición:
Enero 2015
Elaborado por:
Joseph Arquímedes Collado Tineo & José Luis López González
Santo Domingo, Rep. Dom.
Índice
Introducción ............................................................................................................................... 1
Acerca de los autores ................................................................................................................. 2
Concepto de Base de Datos........................................................................................................ 3
¿Qué es una Base de Datos? .................................................................................................. 4
Tipos de Bases de Datos ........................................................................................................ 5
Bases de Datos Jerárquicas ................................................................................................ 5
Bases de Datos de Red ....................................................................................................... 6
Bases de Datos Relacionales .............................................................................................. 7
Entidad y atributos ................................................................................................................. 8
Diagramas Entidad-Relación ................................................................................................... 10
Lógica de creación de tablas .................................................................................................... 13
Reglas de normalización ...................................................................................................... 14
Primera Forma Normal .................................................................................................... 15
Segunda Forma Normal ................................................................................................... 15
Tercera Forma Normal ..................................................................................................... 16
Esquemas y objetos de esquemas en SQL Server .................................................................... 20
Objetos de Esquemas ........................................................................................................... 22
Entorno Microsoft SQL Server ................................................................................................ 25
Creación de usuarios y asignación de permisos ................................................................... 28
Backup y restauración de una base de datos ........................................................................ 31
Creación y modificación de tablas ........................................................................................... 34
CREATE TABLE ................................................................................................................ 35
ALTER TABLE ................................................................................................................... 36
DROP TABLE ..................................................................................................................... 37
DELETE .............................................................................................................................. 37
Columnas calculadas ............................................................................................................ 38
Tipos de datos .......................................................................................................................... 40
Numéricos exactos ............................................................................................................... 41
Numéricos aproximados ...................................................................................................... 42
Fecha y hora ......................................................................................................................... 42
Cadena de caracteres ............................................................................................................ 43
Cadena de caracteres Unicode ............................................................................................. 43
Cadenas binarias .................................................................................................................. 44
Implementación de integridad de datos ................................................................................... 45
Integridad de datos ............................................................................................................... 46
Integridad referencial ........................................................................................................... 46
Restricciones ........................................................................................................................ 47
Uso de restricciones ......................................................................................................... 48
Definición de restricciones .............................................................................................. 49
Control de restricciones ................................................................................................... 51
Insertar registros: INSERT ...................................................................................................... 52
Concepto de la instrucción INSERT .................................................................................... 53
Inserción individual ......................................................................................................... 53
Inserción múltiple ............................................................................................................ 55
Consulta de datos usando la sentencia SELECT ..................................................................... 56
Selección de datos ................................................................................................................ 57
Especificaciones de la instrucción ................................................................................... 57
Crear una tabla a partir de una consulta ........................................................................... 60
Rendimiento de consultas ................................................................................................ 62
Evaluar el uso de DISTINCT ............................................................................................... 63
Recuperar solamente datos de interés .................................................................................. 63
El operador TOP .................................................................................................................. 63
Uso de operadores en la cláusula WHERE .......................................................................... 64
Uso de NOT IN .................................................................................................................... 64
Mejores prácticas en el uso del operador LIKE ................................................................... 65
El operador OR .................................................................................................................... 65
Uso de GROUP BY ............................................................................................................. 66
Actualización de datos: UPDATE ........................................................................................... 67
Sentencia UPDATE ............................................................................................................. 68
Eliminación de datos: DELETE & TRUNCATE TABLE ...................................................... 70
Sentencia DELETE .............................................................................................................. 71
Concepto de TRUNCATE TABLE ..................................................................................... 72
Diferencias entre DELETE y TRUNCATE TABLE ........................................................... 72
Caso de estudio ........................................................................................................................ 74
Planteamiento del caso ......................................................................................................... 75
Presentacion del caso de estudio .......................................................................................... 76
Consultando múltiples tablas con JOIN ................................................................................... 77
Concepto de JOIN ................................................................................................................ 78
Características de JOIN.................................................................................................... 78
Tipos de JOIN .................................................................................................................. 78
INNER JOIN ........................................................................................................................ 79
Forma explícita vs implícita............................................................................................. 83
LEFT JOIN .......................................................................................................................... 83
RIGHT JOIN ........................................................................................................................ 86
FULL JOIN .......................................................................................................................... 87
CROSS JOIN ....................................................................................................................... 88
Funciones de fecha y formas de conversión de datos .............................................................. 89
Funciones de fecha ............................................................................................................... 90
Funciones para manipular cadenas ...................................................................................... 92
Funciones de conversión de datos........................................................................................ 94
Uso de Sub - Consultas ............................................................................................................ 95
Definición de Sub – Consulta .............................................................................................. 96
Sub – consulta para un único registro .................................................................................. 97
¿Cómo retornar un solo registro con una sub - consulta? .................................................... 97
Sub – consulta para múltiples registros ............................................................................... 98
¿Cómo retornar múltiples registros con una sub - consulta? ............................................... 99
Introducción
El profesional de la informática es aquel que posee el conocimiento y maneja las técnicas
necesarias para responder a las distintas necesidades tecnológicas que la sociedad manifieste.
Su importancia es tal, que en cualquier tipo de actividad, empresarial, económica, personal,
política, su participación es vital para el correcto manejo de las herramientas e información
que las tecnologías de la información ponen a nuestra disposición.
Las Bases de Datos, como repositorio de toda esa información que se genera en las
actividades mencionadas anteriormente, juegan un papel protagónico dentro de todas las
disciplinas y ramificaciones de la informática, es por esto que aprender a diseñar, administrar
o desarrollar Bases de Datos es de mucha importancia, tanto para los profesionales como los
estudiantes.
Este Manual de Base de Datos Relacionales ha sido preparado con el objetivo de explicar los
conceptos del diseño lógico del modelo relacional, creación y modificación de tablas,
funciones, integridad referencial, consultas avanzadas y muchos otros conceptos y ejemplos
prácticos, de manera que el lector obtenga un conocimiento adecuado para así adentrase del
todo en el mundo de las bases de datos.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 1
Acerca de los autores
Joseph Arquímedes Collado Tineo nació en Santo Domingo, R.D., en el año 1990,
actualmente es estudiante de término de Ingeniería de Sistemas en la Universidad Católica
Santo Domingo, en ese rol brinda servicios de administración y desarrollo de base de datos,
desarrollo de sistemas informáticos a nivel administrativo, imparte talleres de capacitación y
asesora a pequeñas empresas en cuanto a la implementación de sistemas informáticos.
Los principales sectores en los que se ha desempeñado son: telecomunicaciones,
programación, SQA, mini markets, farmacias, almacenes y análisis de sistemas.
José Luis López González nació en santo domingo, RD en el año 1990 y actualmente es
estudiante universitario de la carrera de Ingeniería de Sistemas en la Universidad Católica
Santo Domingo. Su experiencia en la informática se enfoca básicamente en el desarrollo.
Actualmente utiliza C# como lenguaje de programación para los proyectos en los que
participa además de impartir cursos de base de datos en SQL Server.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 2
UNIDAD I
Concepto de Base de Datos
Metas de Aprendizaje:
Tener un concepto preciso de Base de Datos
Conocer los principales tipos de modelos de Base de Datos
Entender qué son las entidades y atributos
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 3
¿Qué es una Base de Datos?
Es ampliamente mencionado que la información es uno de los activos más importantes que
tenemos los seres humanos como sociedad organizada y moderna, es por eso que su correcto
almacenamiento y uso apropiado es de suma importancia, y más aún en tiempos como estos
en los que grandes cantidades de datos son manejados por casi cualquier tipo de
organización, empresa, gobierno, etc.
Una Base de Datos es cualquier conjunto de datos organizados para su almacenamiento en la
memoria de una o varias computadoras, diseñado para facilitar su acceso y actualización.
Estas a su vez están compuestas por una estructura de filas y columnas que en una Base de
Datos tradicional se llaman registros y campos respectivamente. Al conjunto de varios
registros se le llama archivo.
Durante las décadas de los 60 y 70 surge el concepto de las Bases de Datos; sin embargo, el
objetivo principal siempre ha sido la administración óptima de la información y el uso que se
le puede dar a la misma. Una analogía válida sería la de una guía telefónica; estas contienen
una lista de registros, cada uno de los cuales consiste en tres campos básicos: nombre,
dirección y número de teléfono.
Los sistemas encargados de automatizar el uso de las base de datos son llamados Sistemas de
Gestión de Base de Datos (SGBD); este tipo de software muy específico se dedica a servir de
interfaz entre la Base de Datos, el usuario y las aplicaciones que la utilizan. Se compone de
un lenguaje de definición, un lenguaje de manipulación y un lenguaje de consulta de datos.
Entre las principales características de los Sistemas de Gestión de Base de Datos podemos
mencionar:
Independencia lógica y física de los datos.
Redundancia mínima.
Acceso concurrente por parte de múltiples usuarios.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 4
Integridad de los datos.
Consultas complejas optimizadas.
Seguridad de acceso y auditoría.
Respaldo y recuperación.
Acceso a través de lenguajes de programación estándar.
Tipos de Bases de Datos
Las Bases de Datos pueden clasificarse de distintas maneras, ya sea por la viabilidad de los
datos almacenados o por el modelo de administración que utilice. Por su modelo de
administración pueden clasificarse en:
Bases de Datos Jerárquicas
Éstas son Bases de Datos que, como su nombre indica, almacenan su información en una
estructura jerárquica. En este modelo los datos se organizan en una forma similar a un árbol
(visto al revés), en donde un nodo padre de información puede tener varios hijos. El nodo que
no tiene padres es llamado raíz, y a los nodos que no tienen hijos se los conoce como hojas.
Figura 1 – Modelo de Base de Datos Jerárquica.
Una de las principales limitaciones de este modelo es su incapacidad de representar
eficientemente la redundancia de datos.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 5
Bases de Datos de Red
Éste es un modelo ligeramente distinto del jerárquico; su diferencia fundamental es la
modificación del concepto de nodo: se permite que un mismo nodo tenga varios padres
(posibilidad no permitida en el modelo jerárquico).
Fue una gran mejora con respecto al modelo jerárquico, ya que ofrecía una solución eficiente
al problema de redundancia de datos; pero, aun así, la dificultad que significa administrar la
información en una Base de Datos de Red ha significado que sea un modelo utilizado en su
mayoría por programadores más que por usuarios finales.
Figura 2 – Modelo de Bases de Datos de Red.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 6
Bases de Datos Relacionales
Éste es el modelo utilizado en la actualidad para modelar problemas reales y administrar
datos dinámicamente. Las Bases de Datos Relacionales se basan en el uso de tablas (también
se las llama relaciones). Las tablas se representan gráficamente como una estructura
rectangular formada por filas y columnas. Cada columna almacena información sobre una
propiedad determinada de la tabla (se le llama también atributo). Cada fila posee una
ocurrencia o un ejemplar de la instancia o relación representada por la tabla (a las filas se las
llama también tuplas).
En este modelo, el lugar y la forma en que se almacenen los datos no tienen relevancia (a
diferencia de otros modelos como el jerárquico y el de red). Esto tiene la considerable ventaja
de que es más fácil de entender y de utilizar para un usuario esporádico de la base de datos.
La información puede ser recuperada o almacenada mediante “consultas” que ofrecen una
amplia flexibilidad y poder para administrar la información.
El lenguaje más habitual para construir las consultas a Bases de Datos relacionales es SQL
(Structured Query Lenguage) o Lenguaje Estructurado de Consultas, un estándar
implementado por los principales motores o sistemas de gestión de Bases de Datos
relacionales.
Durante su diseño, una base de datos relacional pasa por un proceso al que se le conoce como
normalización de una base de datos.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 7
Figura 3 – Modelo de Base de Datos Relacional.
Entidad y atributos
El objeto básico que se representa en un modelo Entidad/Relación es la entidad: una “cosa”
del mundo real con autonomía de las demás entidades. Éstas pueden ser un objeto con
existencia física (una persona, auto, casa, etc.), o un objeto con existencia conceptual (una
compañía, un curso universitario, etc.).
Una entidad está descrita y se representa por sus características o atributos. Por ejemplo, la
entidad Persona tiene las características nombre, apellido, género, estatura, peso, fecha de
nacimiento.
Los atributos definen o identifican las características de las entidades. Cada entidad contiene
uno o más atributos que dan información sobre dicha entidad.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 8
Figura 4 - Representación de una entidad con sus atributos.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 9
UNIDAD II
Diagramas Entidad-Relación
Metas de Aprendizaje:
Conocer la importancia de los diagramas Entidad-Relación
Saber cómo está conformado un diagrama Entidad-Relación
Identificar cada tipo de atributos de un diagrama Entidad-Relación
Aprender los distintos tipos de relaciones existentes entre varias entidades
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 10
Los diagramas Entidad Relación, denominados por sus siglas como E/R, son un modelo que
representa a la realidad a través de un esquema gráfico empleando la terminología de
entidades, que son objetos que existen y son los elementos principales que se identifican en el
problema a resolver con el diagramado y se distinguen de otros por sus características
particulares denominadas atributos. El enlace que rige la unión de las entidades está
representado por la relación del modelo.
A continuación se presentan las figuras correspondientes en un diagrama Entidad Relación:
Atributo
Entidad Relación Entidad
Atributo simple: son aquellos atributos que poseen un único valor y su ocurrencia es
siempre necesaria, o sea, no puede obviarse.
Atributo opcional: son aquellos que poseen un único valor y puede darse el caso en que
su ocurrencia es nula.
Atributo único o principal: es aquel que identifica a cada instancia como única y no
repetible.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 11
Atributo multivalor: como su nombre lo indica, este puede estar formado por uno o varios
valores correspondientes a la misma instancia.
Otro componente importante de cualquier modelo relacional es de qué forma esas relaciones
se asocian entre sí. Esas asociaciones, o relaciones, se vinculan en forma significativa, lo que
contribuye a garantizar la integridad de los datos de modo que una acción realizada en una
relación no repercuta negativamente en los datos de otra relación.
Hay tres tipos principales de relaciones:
Una a una (1,1): una relación entre dos relaciones en la cual una tupla en la primera
relación esté relacionada con al menos una tupla en la segunda relación, y viceversa.
Una a varias (1,M): una relación entre dos relaciones en la cual una tupla en la
primera relación esté relacionada con ninguna, una o más tuplas en la segunda
relación, y una tupla en la segunda relación esté relacionada con al menos una tupla
de la primera.
Varias a varias (M,M): una relación entre dos relaciones en la cual una tupla en la
primera relación esté relacionada con ninguna, una o más tuplas en la segunda
relación, y viceversa.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 12
UNIDAD III
Lógica de creación de tablas
Metas de Aprendizaje:
Comprender la lógica tras la creación de tablas en el modelo relacional
Aprender los antecedentes históricos de las formas normales
Conocer las tres principales reglas de normalización
Saber identificar la redundancia de datos en las tablas
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 13
Reglas de normalización
La parte central de los principios del modelo relacional es el concepto de normalización, una
técnica para producir un conjunto de relaciones que poseen un conjunto de ciertas
propiedades que minimizan los datos redundantes y preservan la integridad de los datos
almacenados tal como se mantienen (añadidos, actualizados y eliminados). El proceso fue
desarrollado por E.F. Codd en 1972, y el nombre es un chiste político debido a que el
presidente Nixon estaba “normalizando” relaciones con China en ese momento. Codd
imaginó que si las relaciones con un país pueden normalizarse, entonces seguramente podría
normalizar las relaciones de la base de datos. La normalización se define por un conjunto de
normas, que se conocen como formas normales, que proporcionan una directriz específica de
cómo los datos son organizados para evitar anomalías que den lugar a inconsistencias y
pérdida de los datos tal como se mantienen almacenados en la base de datos.
La normalización es un proceso en el cual se transforman datos complejos a un conjunto de
estructuras de datos más pequeñas, que además de ser más simples y estables, son más fáciles
de mantener. La normalización se adoptó porque el viejo estilo de poner todos los datos en un
solo lugar, como un archivo o una tabla de la base de datos, era ineficiente y conducía a
errores de lógica cuando se trataban de manipular los datos.
La normalización también hace las cosas más fáciles de entender. Los seres humanos
tenemos la tendencia de simplificar las cosas al máximo. Lo hacemos con casi todo, desde los
animales hasta con los automóviles. Vemos una imagen de gran tamaño y la hacemos más
simples agrupando cosas similares juntas. Las guías que la normalización provee crean el
marco de referencia para simplificar una estructura de datos compleja.
Otra ventaja de la normalización de base de datos es el consumo de espacio. Una base de
datos normalizada ocupa menos espacio en disco duro que una no normalizada. Hay menos
repetición de datos, lo que tiene como consecuencia un mucho menor uso de espacio de
disco.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 14
Existen básicamente tres niveles de normalización: Primera Forma Normal (1FN), Segunda
Forma Normal (2FN) y Tercera Forma Normal (3FN). Cada una de estas formas tiene sus
propias reglas. Cuando una base de datos se conforma a un nivel, se considera normalizada a
esa forma de normalización.
Primera Forma Normal
La regla de la Primera Forma Normal establece que las columnas repetidas deben eliminarse
y colocarse en tablas separadas.
Poner la base de datos en la Primera Forma Normal resuelve el problema de los encabezados
de columna múltiples. Muy a menudo, los diseñadores de bases de datos inexpertos harán
algo similar a la tabla no normalizada. Una y otra vez, crearán columnas que representen los
mismos datos. La normalización ayuda a clarificar la base de datos y a organizarla en partes
más pequeñas y más fáciles de entender. En lugar de tener que entender una tabla gigantesca
y monolítica que tienen muchos diferentes aspectos, sólo tenemos que entender los objetos
pequeños y más tangibles, así como las relaciones que guardan con otros objetos también
pequeños.
Segunda Forma Normal
La regla de la Segunda Forma Normal establece que todas las dependencias parciales se
deben eliminar y separar dentro de sus propias tablas. Una dependencia parcial es un término
que describe a aquellos datos que no dependen de la llave primaria de la tabla para
identificarlos.
Una vez alcanzado el nivel de la Segunda Forma Normal, se controla la mayoría de los
problemas de lógica. Podemos insertar un registro sin un exceso de datos en la mayoría de las
tablas.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 15
Tercera Forma Normal
Una tabla está normalizada en esta forma si todas las columnas que no son llave son
funcionalmente dependientes por completo de la llave primaria y no hay dependencias
transitivas. Una dependencia transitiva es aquella en la cual existen columnas que no son
llave que dependen de otras columnas que tampoco son llave.
Cuando las tablas están en la Tercera Forma Normal se previenen errores de lógica cuando se
insertan o borran registros. Cada columna en una tabla está identificada de manera única por
la llave primaria, y no debe haber datos repetidos. Esto provee un esquema limpio y elegante,
que es fácil de trabajar y expandir.
Para ilustrar el procedimiento de normalización presentamos el siguiente ejemplo:
Al examinar estos registros, podemos darnos cuenta que contienen un grupo repetido para
NUM_ITEM, DESC_ITEM, CANT y PRECIO. La 1FN prohíbe los grupos repetidos, por lo
tanto tenemos que convertir a la primera forma normal. Los pasos a seguir son:
Tenemos que eliminar los grupos repetidos.
Tenemos que crear una nueva tabla con la PK (Primary Key) de la tabla base y el
grupo repetido.
Los registros quedan ahora conformados en dos tablas que llamaremos ORDENES y
ARTICULOS_ORDENES.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 16
ORDENES
ARTICULOS_ORDENES
Ahora procedemos a aplicar la segunda forma normal 2FN, es decir, tenemos que eliminar
cualquier columna no llave que no dependa de la llave primaria de la tabla. Los pasos a seguir
son:
Determinar cuáles columnas que no son llave no dependen de la llave primaria de la tabla.
Eliminar esas columnas de la tabla base.
Crear una segunda tabla con esas columnas y la(s) columna(s) de la PK de la cual
dependen.
La tabla ORDENES está en 2FN. Cualquier valor único de ID_ORDEN determina un solo
valor para cada columna. Por lo tanto, todas las columnas son dependientes de la llave
primaria ID_ORDEN.
Por su parte, la tabla ARTICULOS_ORDENES no se encuentra en 2FN ya que las columnas
PRECIO y DESC_ITEM son dependientes de NUM_ITEM, pero no son dependientes de
ID_ORDEN. Lo que haremos a continuación es eliminar estas columnas de la tabla
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 17
ARTICULOS_ORDENES y crear una tabla ARTICULOS con dichas columnas y la llave
primaria de la que dependen.
Las tablas quedan ahora de la siguiente manera:
ARTICULOS_ORDENES
ARTICULOS
La tercera forma normal nos dice que tenemos que eliminar cualquier columna no llave que
sea dependiente de otra columna no llave. Los pasos a seguir son:
Determinar las columnas que son dependientes de otra columna no llave.
Eliminar esas columnas de la tabla base.
Crear una segunda tabla con esas columnas y con la columna no llave de la cual son
dependientes.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 18
Al observar las tablas que hemos creado, nos damos cuenta que tanto la tabla ARTICULOS,
como la tabla ARTICULOS_ORDENES se encuentran en 3FN. Sin embargo, la tabla
ORDENES no lo está, ya que NOM_CLIENTE y ESTADO son dependientes de
ID_CLIENTE, y esta columna no es la llave primaria.
Para normalizar esta tabla, moveremos las columnas no llave y la columna llave de la cual
dependen dentro de la nueva tabla CLIENTES. Las nuevas tablas CLIENTES y ORDENES
se muestran a continuación:
ORDENES
CLIENTES
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 19
UNIDAD IV
Esquemas y objetos de esquemas en SQL Server
Metas de Aprendizaje:
Entender el concepto de Esquemas en SQL Server
Comprender cómo está organizada la estructura de SQL Server
Saber cuáles son los objetos de Esquema
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 20
El entorno SQL es un conjunto de partes que tienen un papel que desempeñar, y estos a su
vez se dividen de manera jerárquica en sus diversos componentes. Cada uno de estos
componentes, sean Agentes SQL, Clientes SQL, identificadores de autorización, catálogos,
etc., trabajan de manera relacional para respaldar las operaciones de SQL tales como la
creación y modificación de objetos, almacenamiento y consulta de información, o
modificación y eliminación de datos.
Los esquemas forman parte de los Catálogos, estos últimos son una estructura jerárquica en el
cual estos componen el objeto primario y los esquemas como los objetos secundarios como se
muestra en la siguiente figura:
Figura 5 - Representación modelo de Entorno SQL
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 21
El esquema actúa como un contenedor de objetos (tablas, vistas, dominios, tipos definidos
por el usuario, etc.), los que a su vez almacenan los datos SQL o realizan otras funciones con
datos relacionados. Cada esquema, los objetos contenidos en el esquema y los datos SQL
dentro de esos objetos son propiedad del identificador de autorización asociado con ese
esquema.
A diferencia de los catálogos, los esquemas son ampliamente implementados en los SGBD.
Sin embargo, como con los catálogos, SQL deja la mayor parte de los detalles de
implementación a los proveedores de dichos sistemas, aun cuando el estándar proporciona un
lenguaje para la creación y eliminación de esquemas. Para crear un esquema se usa la
instrucción CREATE SCHEMA, y para eliminar un esquema se usa la instrucción DROP
SCHEMA.
Objetos de Esquemas
En la parte inferior del nivel del catálogo jerárquico se ubican los objetos de esquema. Los
objetos de esquema son un conjunto de componentes relacionados que están contenidos
dentro de un esquema. Éste es el nivel en el que se almacenan los datos SQL, será capaz de
definir los objetos de SQL, modificar esas definiciones, y almacenar y manipular los datos de
SQL dentro de los objetos.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 22
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 23
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 24
UNIDAD V
Entorno Microsoft SQL Server
Metas de Aprendizaje:
Conocer el entorno básico de Microsoft SQL Server Management Studio
Aprender a crear un usuario
Saber cómo asignar permisos a un usuario
Aprender a hacer una copia de seguridad de una base de datos
Aprender a restaurar una copia de seguridad de una base de datos
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 25
SQL Server es un sistema de administración de bases de datos relacionales desarrollado por
Microsoft, el cual posee una serie de características como soporte de transacciones,
procedimientos almacenados y un completo entorno gráfico que permite el uso de comandos
DDL y DML de manera gráfica.
Al abrir el SQL Server, el servidor nos solicitará el tipo y el nombre del servidor al cual
queremos conectarnos y el tipo de autenticación. SQL Server admite dos modos de
autenticación, el modo de autenticación de Windows y el modo mixto. La autenticación de
Windows es el modo predeterminado, y a menudo se denomina seguridad integrada debido a
que este modelo de seguridad de SQL Server está integrado estrechamente en Windows. Para
iniciar sesión en SQL Server, se confía en las cuentas de usuario y grupo específicas de
Windows. Los usuarios de Windows que ya hayan sido autenticados no tienen que presentar
credenciales adicionales.
Figura 6 – Ventana de autenticación de SQL Server
El modo mixto admite la autenticación tanto de Windows como de SQL Server. Los pares de
nombre de usuario y contraseña se mantienen en SQL Server.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 26
Una vez accedamos estaremos en el entorno principal del servidor. En el desarrollo de este
tema estaremos utilizando el motor de base de datos o “Database Engine”.
Figura 7 – Interfaz básica de SQL Server Management Studio
La configuración básica de la interfaz de SQL Server está conformada por una barra de
herramientas, el explorador de objetos y la pestaña de consultas donde se escriben las
consultas.
La barra de herramientas está conformada por una serie de accesos directos a las opciones
más utilizadas como la lista de las bases de datos disponibles, abrir una nueva consulta, abrir,
guardar e imprimir un archivo, entre otros.
El explorador de objetos proporciona una interfaz jerárquica para ver y administrar los
objetos de cada instancia de SQL Server. El panel de detalles del explorador de objetos
muestra una vista tabular de los objetos de instancia y la capacidad de buscar objetos
específicos. Las funciones del explorador de objetos varían ligeramente según el tipo de
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 27
servidor, aunque, por lo general, incluyen características de desarrollo de bases de datos y
características de administración para todo tipo de servidores.
La pestaña o ventana de consulta es el editor de texto en el cual se diseñan las consultas con
las que manejaremos nuestra información. El lenguaje utilizado en el motor de base de datos
es el Transact-SQL, el cual permite el manejo de variables, control de transacciones y el
manejo de errores y excepciones.
Creación de usuarios y asignación de permisos
El SQL Server permite la creación de usuarios de manera gráfica; estos son asignados a un
objeto de esquema específico o a una base de datos según los permisos que le sean asignados.
Para crear un nuevo usuario de SQL Server primero hay que estar conectado bajo la
autenticación de Windows y de esta manera tener acceso a las opciones de seguridad del
servidor.
A continuación se expande la carpeta seguridad ubicada en el explorador de objetos, luego
click derecho sobre Logins y click en New Login.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 28
Figura 8 – Explorador de Objetos de SQL Server Management Studio
En la ventana de nuevo Login se debe asignar un nombre de usuario, activar la opción SQL
Server authentication, se llenan las casillas de contraseña y en la parte inferior asignar una
base de datos predeterminada.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 29
Figura 9 – Ventana de Nuevo Usuario
Al presionar el botón OK se está asignando un nuevo usuario a la base de datos que se
determinó, sin embargo, este usuario no tiene permisos a los objetos de dicha base de datos,
los cuales deben ser asignados a través de las opciones de seguridad en el menú expandible
de la base de datos en el explorador de objetos.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 30
Figura 10 – Ventana de permisos de usuario
Para asignar permisos al usuario recién creado, debemos ir a las opciones desplegables de la
base de datos a la cual le hemos asignado el nuevo usuario, entramos a la opción de
seguridad, usuarios y hacemos click derecho en el usuario y luego a propiedades.
En esta ventana podemos asignar los permisos o roles que deseamos, siempre y cuando
tengamos los permisos para eso.
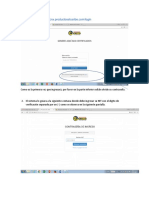
Backup y restauración de una base de datos
La capacidad de poder recuperar nuestra información en caso de pérdida es una facultad
inmensurable, pues existen distintas amenazas que ponen en riesgo la integridad de nuestros
datos. SQL Server Management Studio nos brinda esa opción haciendo Backup o copia de
seguridad a nuestra base de datos.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 31
Hacer una copia de seguridad de nuestra base de datos es relativamente fácil y consta de los
siguientes pasos:
Al acceder a nuestro usuario de SQL Server, debemos hacer click derecho sobre la base de
datos que queremos hacer copia de seguridad, luego a la opción task y seguido a copia de
seguridad o Backup.
Figura 11 – Ventana de copia de seguridad de una base de datos
En la ventana que nos muestra debemos asignar un nombre al archivo, elegir una ruta en la
cual se va a guardar y presionar el botón OK.
Para restaurar una copia de seguridad el proceso es bastante sencillo. Hacemos click sobre la
carpeta Database en nuestro explorador de objetos, luego a Restore Database.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 32
Figura 12 – Ventana de restauración de una base de datos
En esta nueva ventana asignamos un nombre a la base de datos a restaurar, seguido de
seleccionar la opción From device, en la cual vamos a buscar la ubicación de nuestro archivo
y presionamos OK.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 33
UNIDAD VI
Creación y modificación de tablas
Metas de Aprendizaje:
Aprender a crear tablas
Saber cómo modificar una tabla
Saber cómo borrar los datos de una tabla
Aprender cómo borrar una tabla
Saber cómo crear columnas calculadas
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 34
En el entorno SQL, las tablas son la unidad básica de gestión de datos. La mayoría de la
programación que se hace en SQL se relaciona directa o indirectamente con esas tablas.
Como resultado, antes de insertar la información en la base de datos o modificar esa
información, las tablas apropiadas deben haberse creado.
Actualmente existen tres instrucciones básicas que permiten definir, cambiar o eliminar las
definiciones de tablas en SQL. Se puede utilizar la instrucción CREATE TABLE para añadir
una tabla, la instrucción ALTER TABLE para modificar esa definición, o la instrucción
DROP TABLE para eliminar la tabla y sus datos de la base de datos. Veamos a continuación
un análisis más detallado de estas y otras instrucciones de manejo de tablas.
CREATE TABLE
Para comprender la sintaxis SQL para CREATE TABLE es preciso tener una buena idea de
cómo está conformada una tabla. Las tablas se dividen en filas y columnas. Cada fila
representa una parte de los datos, y cada columna puede pensarse como la representación de
un componente de aquella parte de los datos. Entonces, un ejemplo para explicar esta sintaxis
sería el siguiente:
El ejemplo anterior se compone de varias partes: primero está la instrucción CREATE
TABLE quien da inicio a la instrucción, seguido del nombre que se le asigna a la tabla.
Dentro de los paréntesis se encuentra la definición de los campos de la tabla automóviles,
con el nombre del campo, seguido por el tipo de datos que recibe dicho campo, su longitud
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 35
máxima y las restricciones NULL y NOT NULL, las cuales determinan cuales campos son
obligatorios o no.
ALTER TABLE
La instrucción ALTER TABLE se utiliza básicamente para la modificación de tablas
almacenadas en la base de datos. Ésta nos permite tomar varias acciones diferentes: añadir
columnas, modificar columnas, eliminar columnas o modificar restricciones.
Para agregar una columna se utiliza la cláusula ADD. Ésta a su vez va acompañada del
nombre de la columna y el tipo de datos que va a recibir. Ejemplo:
En el ejemplo anterior se utilizó la instrucción ALTER TABLE para agregar una columna a
la tabla clientes, seguido por la cláusula ADD, el nombre de la columna que se va a incluir en
la tabla y el tipo de datos que va a recibir.
Otra manera de utilizar la instrucción ALTER TABLE es en la modificación de columnas; ya
sea el tipo de datos que recibe o las restricciones que tienen asignada. Para ilustrar un
ejemplo para una tabla llamada facturas, en la cual se requiera cambiar el tipo de datos que
recibe la columna nombre a varchar(60).
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 36
A diferencia del ejemplo anterior en el que agregábamos una nueva columna utilizando la
cláusula ADD, en este podemos observar una nueva cláusula llamada ALTER COLUMN
seguida por el nombre de la columna a la que queremos cambiar el tipo de datos y luego el
tipo de dato, en este caso varchar(60).
Para la eliminación de una columna se utiliza la cláusula DROP COLUMN seguido por el
nombre de la columna. Ejemplo:
DROP TABLE
La eliminación definitiva de una tabla es un procedimiento poco común, pero aun así es un
procedimiento básico y su definición es bastante sencilla. Para la eliminación definitiva de
una tabla se utiliza la instrucción DROP TABLE seguida del nombre de la tabla. Ejemplo:
DELETE
La instrucción DELETE permite eliminar registros de una tabla. Su sintaxis es simple, puesto
que solo debemos indicar a qué tabla nos referimos, luego señalamos qué registro deseamos
eliminar mediante la cláusula WHERE. La siguiente consulta elimina todos los registros de la
tabla inventario en las que el valor en la columna cantidad sea igual a cero:
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 37
Columnas calculadas
Una columna calculada es una columna que deduce sus filas del resultado de una operación
entre los valores de dos o más columnas distintas. Éstas pueden obtenerse mediante una
instrucción SELECT, modificando la definición existente de una columna o creando una
nueva.
Para mostrar un ejemplo de una consulta de una columna calculada podemos utilizar un
ejemplo en el que se necesite calcular el monto total luego de aplicar un descuento en la tabla
artículos:
Nótese que se utilizan los principios algebraicos básicos agrupando los valores en paréntesis
y luego realizando el resto de la operación.
Otro ejemplo sería el de modificación de tablas utilizando la instrucción ALTER TABLE, por
ejemplo, agregamos una columna a la tabla artículos cuyos valores sean los requeridos en la
consulta SELECT anterior:
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 38
Por último, si se requiere crear una tabla con las características presentadas en los ejemplos
anteriores se utiliza la instrucción CREATE TABLE de la misma manera:
Nótese que en la definición de la columna precio_total, al igual que en el ejemplo de ALTER
TABLE, no se requiere especificar el tipo de datos de la columna en cuestión.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 39
UNIDAD VII
Tipos de datos
Metas de Aprendizaje:
Conocer los tipos de datos numéricos
Saber cuáles son los tipos de datos de cadena de caracteres
Aprender sobre los tipos de datos binarios
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 40
Cada vez que se define una columna en la instrucción CREATE TABLE, al menos debe
proporcionarse un nombre para la columna y un tipo de dato asociado. El tipo de datos limita
los valores que pueden introducirse en esa columna. Por ejemplo, algunos tipos de datos
limitan los valores de una columna a números, mientras que otros tipos de datos permiten que
se introduzca cualquier carácter. Veamos a continuación un análisis más detallado de los
tipos de datos soportados por SQL.
Numéricos exactos
Tipo de datos
Descripción
Tipo de dato numérico que utiliza valores enteros con un intervalo
Bigint
de (-9,223.372.036.854.775.808 hasta 9,223.372.036.854.775.807)
Tipo de dato numérico que utiliza valores enteros con un intervalo
int
de (-2,147,483,648 hasta 2,147,483,647)
Tipo de dato numérico que utiliza valores enteros con un intervalo
smallint
de (-32,768 hasta 32,767)
Tipo de dato numérico que utiliza valores enteros con un intervalo
tinyint
de (0 hasta 255)
Tipo de dato numérico que tiene precisión y escala fija. Cuando se
decimal utiliza la precisión máxima, los valores válidos se sitúan entre -
10^38 + 1 y 10^38 - 1.
Tipo de dato numérico que tiene precisión y escala fija. Cuando se
utiliza la precisión máxima, los valores válidos se sitúan entre -
numeric
10^38 + 1 y 10^38 - 1. Este tipo de dato es funcionalmente igual al
decimal.
Tipo de dato que representa valores monetarios o de moneda. Tiene
money un intervalo de (-922,337,203,685,477.5808 hasta
922,337,203,685,477.5807)
Tipo de dato que representa valores monetarios o de moneda. Tiene
smallmoney
un intervalo de (- 214.748,3648 a 214.748,3647)
bit Tipo de datos entero que puede aceptar los valores 1, 0 o NULL.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 41
Numéricos aproximados
Tipo de datos
Descripción
Tipo de dato numérico aproximado que utiliza datos numéricos de
Float
coma flotante, o sea, no requiere un rango de exactitud específico.
Real
Fecha y hora
Tipo de datos
Descripción
Date Tipo de dato SQL que define una fecha.
Define una fecha que se combina con una hora del día basada en un
reloj de 24 horas. Puede considerarse como una extensión del tipo
Datetime2 date time, pues tiene un rango de fechas mayor, un valor
predeterminado de precisión fraccionaria y una precisión opcional
especificada por el usuario.
Define una fecha que se combina con una hora del día con fracciones
Datetime
de segundos basada en un reloj de 24 horas.
Define una fecha que se combina con una hora del día con
Datetimeoffset
reconocimiento de la zona horaria y basada en un reloj de 24 horas.
Define una fecha que se combina con una hora del día. La hora está
Smalldatetime en un formato de día de 24 horas, con segundos siempre a cero (:00)
y sin fracciones de segundo.
Define una hora de un día. Éste no distingue la zona horaria y está
Time
basada en un reloj de 24 horas.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 42
Cadena de caracteres
Tipo de datos
Descripción
Datos de cadena no Unicode de longitud fija. La longitud definida
Char
debe ser un valor entre 1 y 8000.
Datos de cadena no Unicode de longitud variable. La longitud
Varchar definida debe ser un valor entre 1 y 8000. A diferencia del char, el
varcha solo almacena la longitud real de los datos especificados.
Datos no Unicode de longitud variable en la página de códigos del
Text
servidor y con una longitud máxima de cadena de (2.147.483.647).
Define una fecha que se combina con una hora del día con
Datetimeoffset
reconocimiento de la zona horaria y basada en un reloj de 24 horas.
Define una fecha que se combina con una hora del día. La hora está
Smalldatetime en un formato de día de 24 horas, con segundos siempre a cero (:00)
y sin fracciones de segundo.
Define una hora de un día. Éste no distingue la zona horaria y está
Time
basada en un reloj de 24 horas.
Cadena de caracteres Unicode
Tipo de datos
Descripción
Nchar Datos de cadena Unicode de longitud fija entre 1 y 4000.
Datos de cadena Unicode de longitud variable en la cual solo se
Nvarchar
ocupa el tamaño de la cadena introducida.
Datos Unicode de longitud variable con una longitud máxima de
Ntext
cadena de 2^30 – 1.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 43
Cadenas binarias
Tipo de datos
Descripción
Datos binarios de longitud fina con una longitud de n bytes, donde n
Binary es un valor que oscila entre 1 y 8000. El tamaño de almacenamiento
es de n bytes.
Datos binarios de longitud variable, n puede ser un valor de 1 a
Varbinary
8000.
Datos Unicode de longitud variable con una longitud máxima de
Ntext
cadena de 2^30 – 1.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 44
UNIDAD VIII
Implementación de integridad de datos
Metas de Aprendizaje:
Conocer el concepto de integridad de datos
Exponer la importancia que tiene la integridad de datos
Enumerar las restricciones de datos más relevantes
Explicar su implementación
Conocer y evaluar su lógica de desarrollo
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 45
Integridad de datos
La integridad de datos hace referencia a los valores reales que se almacenan y se manejan en
las estructuras de datos de la aplicación. Una aplicación debe ejecutar un control sobre los
datos que manejan los procesos de la misma para garantizar la corrección permanente de esos
datos. La exigencia de controlar la integridad de los datos avala la calidad de los datos de la
base de datos.
Garantizar la integridad de los datos es posible gracias a la implementación rigurosa del
concepto de claves primarias y foráneas como las que se presentan a continuación:
Normalizar datos: explica el proceso de perfeccionar las definiciones de datos para
eliminar registros o grupos repetidos y dependencias innecesarias.
Definir reglas de la organización: es la forma en que las políticas de la empresa
controlan la gestión de los datos.
Proporcionar integridad referencial: describe la forma en que la integridad
referencial evita el daño de los datos.
Validación de datos: En esta parte se maneja la validación de campos y validación de
datos.
Integridad referencial
La integridad referencial significa que la clave externa de una tabla de referencia debe
referirse a una fila validad de la tabla a la cual se haga la referencia. El objetivo de la
integridad referencial es mantener una relación sincronizada entre dos tablas durante las
operaciones de actualización y eliminación de datos. Por otro lado, SQL Server ofrece una
gama de restricciones que nos facilitan controlar e implementar integridad de datos y
referencial.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 46
Restricciones
Existen tres tipos de restricciones de integridad
Restricciones relacionadas con tablas
Afirmaciones
Restricciones de dominio
Dentro de estas tres categorías las restricciones más implementadas son las
restricciones relacionadas con tablas y esta se divide en: restricciones de tabla y
restricciones de columna. Una restricción de columna se declara cuando se define una
nueva columna, mientras que las restricciones de tabla se incluyen como un elemento
de tabla.
Restricciones de columna
NOT NULL
CHECK
FOREIGN KEY
PRIMARY KEY
UNIQUE
Restricciones de tabla
UNIQUE
FOREIGN KEY
PRIMARY KEY
CHECK
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 47
Uso de restricciones
NOT NULL: en el momento que se requiere que un campo sea obligatorio, ósea que no se
pueda quedar vacío, usted debe utilizar dicha restricción.
DEFAULT: si se requiere especificar un valor en un campo el cual no se han insertado datos,
se utiliza la restricción DEFAULT si el campo no recibe datos, obtenga un valor por defecto.
CHECK: Cuando se requiera verificar la información que va a contener un campo, se debe
usar esta restricción ya que permite validar la información que va a contener ese campo según
la restricción CHECK.
UNIQUE: Se utiliza cuando se necesita que un campo contenga valores únicos, ósea valores
que sean significativos que identifique a cada fila de todas las demás.
PRIMARY KEY: Solo se puede definir un PRIMARY KEY en una tabla, esta restricción al
igual que la UNIQUE se utiliza cuando se requiere que un campo contenga valores únicos.
FOREIGN KEY: Esta restricción se encarga de mantener la integridad relacional de los
datos, en el sentido de que si el valor de un campo de una tabla hace referencia a otro campo
de una segunda tabla que contiene ese mismo valor, no se podrá eliminar ese valor ya que
esta referenciado y relacionado en otra tabla. Sin una restricción FOREIGN KEY se pierde la
integridad relacional de cierto conjunto de datos que se encuentren relacionados.
Nota
*El uso de restricciones tiene una relevancia muy importante en el diseño de una base
de datos, porque no solo establece seguridad, sino que también, garantiza la integridad
de la información contenida en una base de datos*.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 48
Definición de restricciones
Definir una restricción en una tabla sigue dos formas, por ejemplo:
1) Se definen restricciones de columna para una tabla llamada Factura
CREATE TABLE Factura
(
id_factura int identity(1,1) PRIMARY KEY,
id_cliente int NOT NULL,
id_usuario int NOT NULL,
monto_total float NOT NULL,
monto_recibido float NOT NULL,
devuelta float NOT NULL,
fecha date
)
Figura
Definición del problema
El nombre de esta tabla es Factura, se declara un campo que identificara la tabla de manera
única llamado id_factura el cual utilizara la secuencia auto-incremental identity que
procederá a generar una secuencia de números desde el 1 a 1. Podemos ver el uso de la
restricción de columna NOT NULL.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 49
2) Se definen restricciones de tabla y columna para las tablas Factura, Cliente y
Usuarios
CREATE TABLE Facturas
(
id_factura int identity(1,1),
id_cliente int NOT NULL,
id_usuario int NOT NULL,
monto_total float NOT NULL,
monto_recibido float NOT NULL,
devuelta float NOT NULL,
fecha date,
CONSTRAINT pk PRIMARY KEY(id_factura),
CONSTRAINT fore FOREIGN KEY(id_cliente)
REFERENCES Cliente(id_cliente),
CONSTRAINT f_k FOREIGN KEY(id_usuario)
REFERENCES Usuarios(id_usuario)
)
CREATE TABLE Cliente
(
id_cliente int identity(1,1),
nombre varchar(60) NOT NULL,
apellido varchar(60) NOT NULL,
cedula varchar(13) NOT NULL,
direccion varchar(100) NOT NULL,
celular varchar(12) NOT NULL,
fecha_registro date,
CONSTRAINT pi_k PRIMARY KEY(id_cliente)
CREATE TABLE Usuarios
(
id_usuario int identity(1,1),
nombre varchar(60) NOT NULL,
apellido varchar(60) NOT NULL,
nombre_usuario varchar(60) NOT NULL,
contrasena varbinary(128) NOT NULL,
id_rol int NOT NULL,
fecha_registro date
CONSTRAINT p_k PRIMARY KEY(id_usuario)
)
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 50
Definición del problema
En este caso se declara tanto restricciones de columna ósea NOT NULL y restricciones de
tabla como los CONSTRAINT. Recuerde que después de los FOREIGN KEY, en los
REFERENCES es que va a separar por comas. Se aplican restricciones de tabla FOREIGN
KEY y PRIMARY KEY y restricciones de columna NOT NULL. Las restricciones
FOREIGN KEY están haciendo referencias a los campos id_cliente y id_usuario de manera
que, si en la tabla Factura existe un id_usuario = 1 y en la tabla Usuario existe un id_usuario
= 1, para eliminar esa o esas facturas donde el id_usuario = 1, tendremos que desactivar
ese FOREIGN KEY ya que como esta restricción establece una integridad relacional entre
dos campos de diferentes tablas y si estos datos coinciden no se podrán eliminar a menos que
desactive la restricción FOREIGN KEY.
Control de restricciones
Utilizando los dos casos anteriores de la tabla Factura, Para deshabilitar
un CONSTRAINT:
ALTER TABLE Factura NOCHECK CONSTRAINT Fore
Para habilitar un CONSTRAINT:
ALTER TABLE Factura CHECK CONSTRAINT Fore
Si quiere definir una restricción de una tabla en el caso de que no las estableció en la
creación, use ALTER para modificar la tabla:
ALTER TABLE Factura
ADD CONSTRAINT fore FOREIGN KEY (id_cliente) REFERENCES
Cliente(id_cliente)
Si desea eliminar ese CONSTRAINT use el comando ALTER y DROP:
ALTER TABLE Orders
DROP CONSTRAINT fore
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 51
UNIDAD IX
Insertar registros: INSERT
Metas de Aprendizaje:
Conocer el uso de la sentencia insert.
Especificar los tipos de insert.
Describir su forma.
Evaluar su importancia.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 52
Concepto de la instrucción INSERT
Para almacenar datos en una base de datos debemos insertar filas en las tablas. Para eso SQL
pone a disposición la sentencia INSERT. La sentencia INSERT es una de las instrucciones
más simples; esta tiene dos modos de trabajo, está la inserción única y la inserción múltiple.
Inserción individual
Para poder realizar la inserción individual de filas en las tablas de la base de datos, debemos
usar la sentencia INSERT INTO. Esta es la inserción que más será utilizada en este curso.
INSERT INTO <nombre_tabla>
[(<campo1>[,<campo2>,...])]
values
(<valor1>,<valor2>,...);
Algo muy importante a destacar es que si queremos omitir un campo en la sentencia INSERT
INTO este campo tiene que permitir valores nulos, ósea, que el campo debe contar con la
restricción de columna NULL, que por defecto al momento de crear una tabla si no se
especifica una restricción de columna, esta admite inmediatamente valores nulos.
Figura tabla usuarios
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 53
Para poder hacer una inserción individual en la Tabla Usuarios tenemos dos opciones. La
primera es especificar todos los campos después de INTO y luego especificar las expresiones.
Por ejemplo:
INSERT INTO
Usuarios(nombre,apellido,nombre_usuario,contrasena,id_rol,fech
a_registro)
VALUES('Emmanuel','DeLeon
Guzman','Emmanuel','12345',1,GETDATE())
Por otro lado, tenemos la opción de realizar una inserción en todos los campos sin necesidad
de especificarlos:
INSERT INTO Usuarios
VALUES('Emmanuel','DeLeon
Guzman','Emmanuel','12345',1,GETDATE())
La diferencia está en que si se quiere insertar un nuevo registro y se van a completar todos los
campos de la tabla, no se tienen que especificar todos los campos, solamente haciendo
INSERT INTO Usuarios VALUES (Expr) es suficiente. Ahora si se necesita insertar datos
solamente en algunos campos en específico, deben definirse cuales serán esos campos.
Este es un ejemplo de una inserción que se va a realizar pero solamente en dos campos:
INSERT INTO Usuarios(nombre,apellido)
VALUES('Emmanuel','De Leon Guzman')
Recuerde que a menos que los demás campos de la Tabla Usuarios permitan valores nulos, se
podrá ejecutar esta inserción, de lo contrario, SQL Server le mostrara el mensaje 515,
mostrándole que los campos que tienen una restricción de columna NOT NULL no permiten
valores nulos y que deben ser completados con un valor.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 54
Inserción múltiple
Para lograr realizar una inserción múltiple, SQL Server permite combinar la sentencia
INSERT con la sentencia SELECT. El resultado que se produce es una inserción basada en
las filas retornadas por la sentencia SELECT.
Figura Tabla Factura
Definición del problema
Actualmente, la empresa x cuenta con una tabla llamada Factura. El problema está en que se
quiere realizar una transferencia de esas facturas a una tabla llamada Historial_Factura, pero
solamente de las facturas emitidas en el año 2014 suponiendo que la tabla Historial_Factura
tiene la misma estructura que la tabla Factura.
Solución:
INSERT INTO Historial_Factura
SELECT
*
FROM Factura
WHERE fecha='2014-01-01'
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 55
UNIDAD X
Consulta de datos usando la sentencia SELECT
Metas de Aprendizaje:
Definir la función y estructura de la sentencia select.
Demostrar el potencial de la instrucción.
Detallar el orden de procesamiento lógico de la sentencia select
Analizar y evaluar el rendimiento de cada consulta
Interpretar un plan de ejecución
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 56
Selección de datos
Esta instrucción recupera las filas de una base de datos y habilita la selección de varias filas y
columnas de tablas que se encuentran contenidas dentro de una base de datos. El proceso más
relevante que podemos llevar a cabo en una base de datos es la consulta de los datos. No
serviría de nada contar con una base de datos si no pudiéramos consultarla. Esta es una de las
instrucciones más utilizadas en el mundo de las bases de datos.
Su estructura es la siguiente:
SELECT [ALL | DISTINCT ]
<nombre_campo> [{,<nombre_campo>}]
FROM <nombre_tabla>|<nombre_vista>
[{,<nombre_tabla>|<nombre_vista>}]
[WHERE <condicion> [{ AND | OR <condicion>}]]
[GROUP BY <nombre_campo> [{,<nombre_campo >}]]
[HAVING <condicion>[{ AND|OR <condicion>}]]
[ORDER BY <nombre_campo>|<indice_campo> [ASC | DESC]
[{,<nombre_campo>|<indice_campo> [ASC | DESC ]}]]
Especificaciones de la instrucción
SELECT: Palabra clave y reservada que indica que la sentencia de SQL que queremos
ejecutar es de selección.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 57
ALL: Indica que queremos seleccionar todos los valores. Es el valor por defecto y no suele
especificarse casi nunca.
DISTINCT: Indica que queremos seleccionar sólo los valores distintos no repetidos.
FROM: Indica la tabla desde la que queremos recuperar los datos. En el caso de que exista
más de una tabla se hace una combinación de tablas usando la instrucción JOIN. En las
consultas combinadas es necesario aplicar una condición de combinación a través de una
cláusula WHERE.
WHERE: Especifica una condición que debe cumplirse para que los datos sean devueltos
por la consulta. Admiten los operadores lógicos AND y OR.
GROUP BY: Especifica la agrupación que se da a los datos. Se usa siempre en combinación
con funciones agregadas.
HAVING: Especifica una condición que debe cumplirse para que los datos sean devueltos
por la consulta. Su funcionamiento es similar al de WHERE pero aplicado al conjunto de
resultados devueltos por la consulta. Debe aplicarse siempre junto a GROUP BY y la
condición debe estar referida a los campos contenidos en ella.
ORDER BY: Presenta el resultado ordenado por las columnas indicadas. El orden puede
expresarse con ASC “orden ascendente” y DESC “orden descendente”. El valor
predeterminado es ASC.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 58
Ejemplo básico
Figura tabla Usuarios
“La figura muestra la estructura de la tabla Usuarios. Esta contiene siete campos”.
SELECT
*
FROM Usuarios
SELECT
nombre,apellido
FROM Usuarios
Figura resultados de las consultas
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 59
Crear una tabla a partir de una consulta
En algunas ocasiones, no solo se necesita obtener el resultado de una consulta usando la
instrucción SELECT, sino que también se necesita almacenar los datos retornados por la
instrucción y almacenarlos en una tabla persistente. Esta operación se puede realizar de la
siguiente manera:
Definición del problema
Se necesita obtener el nombre y apellido de los usuarios que están contenidos en la Tabla
Usuarios la cual contiene cinco registros para luego almacenarlos en una nueva tabla
persistente llamada Historial_Usuarios.
Solución
Usar INTO después de la selección de los campos en la instrucción SELECT, a partir de esto
se creara una nueva tabla persistente. El uso de INTO debe efectuarse en momentos donde no
se hagan muchas consultas al servidor.
SELECT
nombre,apellido
INTO dbo.Historial_Usuarios
FROM Usuarios
SELECT
nombre,apellido
FROM dbo.Historial_Usuarios
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 60
Figura muestra las filas afectadas y el resultado de la consulta
Si existe una situación en la cual se tenga que almacenar datos en una tabla, pero, no se
necesita que esta tabla sea persistente, se tiene que hacer uso de las tablas temporales globales
o locales.
Solución
Se pueden almacenar esos registros en una tabla temporal local o global. El resultado es el
mismo, lo que cambia es el concepto de la tabla.
SELECT
nombre,apellido
INTO ##Mi_Tabla_Temporal
FROM Usuarios
SELECT
*
FROM ##Mi_Tabla_Temporal
SELECT
nombre,apellido INTO #Mi_Tabla_Temporal
FROM Usuarios
SELECT
nombre,apellido FROM #Mi_Tabla_Temporal
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 61
Rendimiento de consultas
Mejorar rendimiento de UNION
Imagine un caso en el cual se quiera mezclar dos conjuntos de datos:
SELECT column_name1, column_name2
FROM table_name1
WHERE column_name1 = some_value
UNION
SELECT column_name1, column_name2
FROM table_name1
WHERE column_name2 = some_value
Para obtener un mayor rendimiento de esta consulta, con DISTINCT se obtiene los registros
únicos aunque se repitan en la tabla, si existen cinco registros No.1 solo mostrara un solo
registro del No.1, la consulta es dela siguiente manera:
SELECT DISTINCT column_name1, column_name2
FROM table_name1
WHERE column_name1 = some_value OR column_name2 = some_value
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 62
Evaluar el uso de DISTINCT
Un aspecto relativo al rendimiento es la evaluación del uso de la sentencia DISTINCT.
Muchos desarrolladores aplican esta sentencia por defecto. Sólo debe usarse si sabemos que
la consulta puede retornar registros duplicados. Además esto puede provocar un mal
funcionamiento de la aplicación que hace uso de los datos.
Recuperar solamente datos de interés
Un retorno de datos y campos innecesarios reduce el rendimiento y aumenta la degradación
del sistema. Cuando se realiza un SELECT *, este retorna todos los campos y datos de la
tabla impidiendo el uso de índices y incrementando así el tiempo de la consulta ya que se
tienen que recorrer todas las filas y columnas. Por tal razón, se debe evitar el uso de SELECT
*.
El operador TOP
Si se requiere desarrollar una aplicación en la que los usuarios tengan que ejecutar consultas,
la recomendación seria implementar el uso del operador TOP, ya que el usuario va a ejecutar
sus consultas pero, estas consultas estarán limitas a las filas especificadas por el usuario.
Usar esta técnica ayuda a que el usuario no tenga que retornar todos los datos que se
encuentran almacenados en una tabla.
SELECT
TOP(2) nombre,apellido
FROM Usuarios
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 63
Figura uso del operador TOP
“Esta figura muestra que usando el operador TOP se limita el retorno de filas. La tabla Usuarios contiene
cinco registros”.
Uso de operadores en la cláusula WHERE
El uso de operadores dentro de la cláusula WHERE aumenta el rendimiento de una consulta,
lista de operadores siguiendo un orden bueno malo, bueno malo etc.
=
>, >=, <, <=
LIKE
<>
Uso de NOT IN
Como administrador de base de datos, se tiene que evitar el uso de este operador, ya que este
obliga al SQL Server Optimizer a realizar una búsqueda (“Scan”). En lugar de eso, utilice una
de estas tres recomendaciones:
Usar EXISTS o NOT EXISTS
Usar IN
Usar LEFT OUTER JOIN
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 64
Mejores prácticas en el uso del operador LIKE
No es lo mismo usar LIKE ‘%P’ que LIKE ‘P%’, la segunda opción es más óptima porque si
existe un índice puede agilizar el proceso de búsqueda por carácter.
El operador OR
Es posible que las QUERIES que lancemos nos encontremos que existen operadores OR que
muchas veces pueden reescribirse mediante la sentencia UNION ALL, de cara a mejorar el
rendimiento de la QUERY. Por ejemplo echemos un vistazo a la siguiente consulta:
SELECT
nombre,apellido
FROM names
WHERE nombre = 'Miguel' or Apellido = 'Collado Tineo'
Esta consulta tiene tres condiciones en la cláusula WHERE separadas. De cara a que esta
consulta use un indice, debemos tener un indice sobre todas las columnas que están en dicha
cláusula. Este ejemplo puede ser reescrito usando un UNION ALL en lugar de un OR, tal y
como muestra el ejemplo:
SELECT
nombre,apellido
FROM Usuarios
WHERE nombre = 'Miguel'
UNION ALL
SELECT
nombre,apellido
FROM Usuarios
WHERE Apellido = 'Collado Tineo'
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 65
Uso de GROUP BY
No debe hacer uso de GROUP BY si no existe ningún campo que esté trabajando bajo una
función de agregación. GROUP BY tiene mejor rendimiento que DISTINCT.
Forma incorrecta
SELECT
id_cliente,id_usuario,monto_factura
FROM Factura
GROUP BY id_cliente,id_usuario,monto_factura
Forma correcta
SELECT
id_cliente,id_usuario,AVG(monto_factura)
FROM Factura
GROUP BY id_cliente,id_usuario
“Recuerde que siempre debe especificar en el GROUP BY las columnas que no están
bajo una función de agregación”.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 66
UNIDAD XI
Actualización de datos: UPDATE
Metas de Aprendizaje:
Conocer la función de la sentencia update.
Especificar su operación.
Dominar el proceso de actualización combinando tablas.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 67
Sentencia UPDATE
Esta sentencia se utiliza para cambiar el contenido de uno o varios registros de una o varias
columnas de una base de datos. A continuación se presentara su estructura:
UPDATE nombre_tabla
SET columna1 = nuevo_valor1, columna2 = nuevo_valor2
WHERE columna3 = valor_contenido_en_la_tabla
La estructura de esta sentencia es muy fácil, donde luego de UPDATE se especifica el
nombre de la tabla la cual se va a realizar una actualización. En la parte de SET, se
especifican las columnas de la tabla las cuales van a recibir un nuevo valor, y por último esta
la cláusula WHERE, en esta se define cual será la condición o condiciones para que un
registro sea actualizado.
En la siguiente tabla se muestra un ejemplo en el cual se quiere actualizar el campo
monto_recibido cuando el id_cliente sea igual a uno.
UPDATE Factura
SET monto_recibido=500
WHERE id_cliente=1
Pero recuerde que en algunas situaciones se necesitan actualizar todos los registros y por tal
razón no es necesario el uso de WHERE ya que esta cláusula permite actualizar un registro o
un conjunto de registros bajo una condición.
UPDATE Factura
SET monto_recibido=500
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 68
En este siguiente ejemplo, se puede notar que en SET podemos definir todas las columnas
que se requieran actualizar de una tabla.
UPDATE Factura
SET monto_recibido=500,id_usuario=1
WHERE monto_total>=2500 AND monto_total<=@3000
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 69
UNIDAD XII
Eliminación de datos: DELETE & TRUNCATE TABLE
Metas de Aprendizaje:
Entender su uso y consecuencias de la misma.
Describir las diferencias entre delete y truncate.
Determinar cuándo hacer uso de delete o truncate.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 70
Sentencia DELETE
Esta sentencia se utiliza para eliminar uno o varios registros de una misma tabla. En una
instrucción DELETE en la cual se desee eliminar registro de más de una tabla, se debe
incluir el nombre de la tabla. Si se especifica más de una tabla en una instrucción DELETE,
estas deben tener una relación muchos a uno. Algo importante que cabe destacar es que si se
quiere proceder a eliminar todos los registros de una tabla, es mejor eliminar la tabla que usar
la sentencia DELETE, porque esta consume muchos recursos.
Una consulta de borrado no elimina solo los datos en campos específicos, sino todos los
registros de una tabla, claro, si no se define una condición usando WHERE.
La siguiente instrucción no es eficiente, porque elimina todos los registros de una tabla, y si
esa tabla contara con dos millones de registros, esta consumiría muchos recursos, así que
sería mejor aplicar un DROP sobre la tabla.
DELETE FROM Factura
Puede aplicar instrucciones como esta porque solo eliminara uno o algunos registros de la
tabla.
DELETE FROM Factura
WHERE id_cliente IN(1,2,3)
DELETE FROM Factura
WHERE monto_recibido>=2500
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 71
Concepto de TRUNCATE TABLE
Truncate table es similar a la instrucción DELETE, pero esta no hace uso de la cláusula
WHERE y es más rápida y consume menos recursos de registro de transacciones y del
sistema.
No puede utilizar TRUNCATE TABLE en las siguientes tablas:
Tablas a las que se hace referencia mediante una restricción FOREIGN KEY. (Puede
truncar una tabla que tenga una clave externa que haga referencia a sí misma).
Tablas que participan en una vista indexada.
Tablas que se publican mediante replicación transaccional o replicación de mezcla.
Si la tabla contiene una columna de identidad, el contador para dicha columna se restablece al
valor de inicialización definido para ella. Si no se define ningún valor de inicialización, se
utiliza el valor predeterminado 1. Para conservar el contador de identidad, utilice DELETE.
Solamente con especificar TRUNCATE TABLE <Nombre de la tabla>, inmediatamente la
tabla es truncada.
TRUNCATE TABLE Factura
Diferencias entre DELETE y TRUNCATE TABLE
Truncate
Es una operación DDL.
No permite el borrado selectivo. TRUNCATE TABLE elimina todo el contenido de la
tabla.
No se puede ejecutar, si la tabla tiene asociadas, aun si no existiesen registros en la
tabla que contiene la FK.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 72
Es la forma más rápida de eliminar el contenido de una tabla.
No se activa ningún TRIGGER al ejecutarse (a partir de SQL Server 2005, es posible
capturar el evento mediante un DDL TRIGGER, pero a modo de auditoría, no es
posible tener acceso a los valores que fueron eliminados).
En caso que la tabla tuviese un campo Identity, se resetea el valor a 1 (o al valor base
determinado en el campo).
TRUNCATE TABLE desasocia (deallocate) las páginas de datos de la tabla.
El logueo en el transaction log es mínimo. Solo registra el dealloc de las páginas de
datos.
No puede ser ejecutado si la tabla tiene asociadas vistas indexadas.
Delete
Es una operación DML.
Permite el borrado selectivo, mediante la cláusula WHERE.
Se puede ejecutar si hay FK asociadas a la tabla, pero siempre y cuando no tenga
registros asociados o la FK este deshabilitada.
Es más lenta.
Puede activarse el TRIGGER de ON DELETE y poder determinar que registros están
siendo eliminados. siendo eliminados.
No resetea el valor del campo Identity, en caso que la tabla tuviese uno.
DELETE FROM marca cada registro afectado, como eliminado.
Loguea cada operación sobre los registros afectados.
Se puede ejecutar si la tabla tiene vistas indexadas.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 73
UNIDAD XIII
Caso de estudio
Metas de Aprendizaje:
Aplicar las técnicas y procedimientos necesarios para desarrollar una base de
datos
Especificar las entidades y atributos necesarios
Determinar la lógica y orden de un proceso
Relacionar las entidades de manera correcta
Especificar los tipos de datos usados
Enumerar las restricciones utilizadas
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 74
Planteamiento del caso
Sugar Company S.A es un restaurante perfecto para comer bien y degustar una excelente
comida en la cena o almuerzo, y muy especialmente, para cenas Románticas. Se encuentra en
un entorno de amplios jardines con piscina y terrazas llenas de encanto.
Benjamin Fernandez, propietario de la empresa Sugar Company S.A, ha decidido
implementar un nuevo sistema para su restaurante que le permita gestionar y controlar todas
las operaciones que se realizan en todo el dia dentro del restaurante. Todas las operaciones
como: asignaciones de mesas, verificacion de mesas disponibles y facturacion se realizan
manualmente. El nuevo sistema debe tener la capacidad de automatizar estas y las demas
operaciones que se realizan, desde la entrada del cliente hasta su respectiva salida del lugar.
Requerimientos:
Automatizar las operaciones que realizan los camareros, cajeros, recepcionistas y
cocineros dentro del restaurante.
Analizar y desarrollar los procesos pertinentes para la automatizacion de las
operaciones dentro del restaurante.
Contar con una base de datos que permita registrar y gestionar toda la informacion y
las operaciones que se realizan en el restaurante.
Segmentar las entidades que trabajaran en este nuevo sistema.
La informacion que va a gestionar este nuevo sistema tiene que ser almacenada bajo
una perfecta estructura relacional.
Se necesita que los procesos sean claros y eficientes.
No se puede eliminar la informacion permanentemente, porque esta sera usada para
realizar estudios estadisticos.
Se debe presentar el diagrama entidad – relacion desarrollado.
El sistema debe contar con la capacidad de poder asignar privilegios a los usuarios,
digase camarero, cajero entre otros.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 75
Presentacion del caso de estudio
El caso de estudio debera ser presentado en el aula, a traves de una presentacion en Power
Point. El tiempo de la presentacion es minimo 25 minutos y la presnetacion debe contener
lo siguiente:
Agenda
Descripcion del problema
Descripcion de procesos
Esquemas definidos
Entidades y atributos implementados
Tipo de datos
Restricciones utilizadas
Diagrama entidad – relacion
Recomendación
Describir su experiencia trabajando en este proyecto
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 76
UNIDAD XIV
Consultando múltiples tablas con JOIN
Metas de Aprendizaje:
Comprender el concepto e implementación de un join
Identificar qué tipo de join se debe aplicar en cada situación
Conocer las ventajas que proporcionan los join
Aprender a utilizar las relaciones entre dos o más tablas
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 77
Concepto de JOIN
Esta sentencia que proporciona SQL nos permite hacer una consulta combinando registros de
una o varias tablas en una base de datos relacional. Existen tres tipos de JOIN: interno,
externo y cruzado. En casos especiales, es necesario que se tenga que combinar una tabla con
si misma; este tipo de JOIN se le conoce como SELF-JOIN.
Características de JOIN
Un join se utiliza para consultar datos de más de una tabla.
La condición de un join que se vaya a establecer en una consulta, debe definirse en la
cláusula WHERE. Aunque se recomienda que se establezcan en la cláusula FROM.
Si se va a combinar una tabla por un campo donde ambos campos tengan el mismo
nombre, se deberá especificar un alias para ambas tablas.
Tipos de JOIN
INNER JOIN
LEFT JOIN
RIGHT JOIN
FULL JOIN
CROSS JOIN
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 78
INNER JOIN
Con esta operación se calcula el producto cruzado de todos los registros; así cada registro en
la tabla A es combinado con cada registro de la tabla B; pero solo permanecen aquellos
registros en la tabla combinada que satisfacen las condiciones que se especifiquen. Este es el
tipo de JOIN más utilizado, por lo que es considerado el tipo de combinación
predeterminado.
Existen dos formas de hacer un INNER JOIN: de manera explícita e implícita. Ambas son
similares solo cambia la forma de expresión. Por ejemplo:
“Se necesita obtener los id de facturas, él monto recibido y el nombre del usuario que
efectuó esa factura”
Tabla Facturas Tabla Usuarios
Tabla Clientes
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 79
CREATE TABLE Clientes
(
id_cliente int identity(1,1),
nombre varchar(60) NOT NULL,
apellido varchar(60) NOT NULL,
cedula varchar(13) NOT NULL,
direccion varchar(100) NOT NULL,
celular varchar(12) NOT NULL,
fecha_registro date,
CONSTRAINT pi_k PRIMARY KEY(id_cliente)
INSERT INTO Clientes VALUES('Carlos','Reyes','001-9876542-3','Calle El
Manantial esquina Nicolas de Ovando #45','829-345-6789',GETDATE())
INSERT INTO Clientes VALUES('Royel','Rodriguez','402-9898542-9','Calle D
#95','849-987-4567',GETDATE())
INSERT INTO Clientes VALUES('Cesar','Cordero','223-4567542-3','Calle
Osvaldo Jerez #66 Mi Hogar','829-335-0265',GETDATE())
CREATE TABLE Usuarios
(
id_usuario int identity(1,1),
nombre varchar(60) NOT NULL,
apellido varchar(60) NOT NULL,
nombre_usuario varchar(60) NOT NULL,
contrasena varchar(128) NOT NULL,
id_rol int NOT NULL,
fecha_registro date
CONSTRAINT p_k PRIMARY KEY(id_usuario)
)
INSERT INTO Usuarios
VALUES('Alexander','Gil','AlexGil','12345',1,GETDATE())
INSERT INTO Usuarios
VALUES('Ivan','Alburquerque','Ivan02','987654321',2,GETDATE())
INSERT INTO Usuarios
VALUES('Begni','Martinez','Begni9876','7685432',1,GETDATE())
INSERT INTO Usuarios VALUES('Jose','Lopez','JLopez','876543',2,GETDATE())
CREATE TABLE Facturas
(
id_factura int identity(1,1),
id_cliente int NOT NULL,
id_usuario int NOT NULL,
monto_total float NOT NULL,
monto_recibido float NOT NULL,
devuelta float NOT NULL,
fecha date,
CONSTRAINT pk PRIMARY KEY(id_factura),
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 80
CONSTRAINT fore FOREIGN KEY(id_cliente)
REFERENCES Cliente(id_cliente),
CONSTRAINT f_k FOREIGN KEY(id_usuario)
REFERENCES Usuarios(id_usuario)
)
INSERT INTO Facturas VALUES(2,1,4500,5000,500,GETDATE())
INSERT INTO Facturas VALUES(1,2,3800,4000,200,GETDATE())
INSERT INTO Facturas VALUES(1,3,350,400,50,GETDATE())
Forma explicita:
SELECT
f.id_factura,f.monto_recibido,u.nombre
FROM Facturas f
INNER JOIN Usuarios u ON(f.id_usuario=u.id_usuario)
Forma implícita:
SELECT
id_factura,monto_recibido,nombre
FROM Facturas,Usuarios
WHERE Facturas.id_usuario=Usuarios.id_usuario
Análisis de resultados
Observe que los resultados de la consulta usando el INNER JOIN de manera explícita e
implícita retorna el mismo resultado.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 81
Por qué solo los id_factura 1, 2 y 3?
La razón es sencilla, el INNER JOIN hace una combinación de registros que son equivalentes
entre sí, solamente va a combinar los registros de las tablas Facturas y Usuarios cuando los
id_usuario de la tabla Factura coincidan con los id_usuario de la tabla Usuarios.
Note que se insertaron 3 registros en la tabla Facturas, donde se especificaron los id_usuario
1, 2 y 3.
INSERT INTO Facturas VALUES(2,1,4500,5000,500,GETDATE())
INSERT INTO Facturas VALUES(1,2,3800,4000,200,GETDATE())
INSERT INTO Facturas VALUES(1,3,350,400,50,GETDATE())
Se insertaron 4 registros en la tabla Usuarios, como la sentencia INSERT solamente permite
insertar un registro por vez, los 3 primeros en este caso serían Alexander, Ivan y Begni. En la
tabla Facturas se especificaron los id_usuario 1,2 y 3, por eso, es que solamente aparecen
esas facturas de esos usuarios por que el INNER JOIN solamente combina los registros que
son equivalentes entre sí.
INSERT INTO Usuarios
VALUES('Alexander','Gil','AlexGil','12345',1,GETDATE())
INSERT INTO Usuarios
VALUES('Ivan','Alburquerque','Ivan02','987654321',2,GETDATE())
INSERT INTO Usuarios
VALUES('Begni','Martinez','Begni9876','7685432',1,GETDATE())
INSERT INTO Usuarios VALUES('Jose','Lopez','JLopez','876543',2,GETDATE())
Además que la condición del INNER JOIN se estableció en la cláusula ON. Cuando los
id_usuario de la tabla Facturas sean igual a los id_usuario de la tabla Usuarios.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 82
Forma explícita:
SELECT
f.id_factura,f.monto_recibido,u.nombre
FROM Facturas f
INNER JOIN Usuarios u ON(f.id_usuario=u.id_usuario)
Forma implícita:
SELECT
id_factura,monto_recibido,nombre
FROM Facturas,Usuarios
WHERE Facturas.id_usuario=Usuarios.id_usuario
Forma explícita vs implícita
La más usada es la forma explícita, por la razón de que esta permite establecer alias para las
tablas y es más fácil identificar las columnas mencionadas en una consulta porque se
mencionan por medio del alias y se evita así la confusión de pensar ¿De cual tabla es la
columna?
LEFT JOIN
La sentencia LEFT JOIN retorna la pareja de todos los valores de la izquierda con los valores
de la tabla de la derecha correspondientes, o retorna un valor nulo NULL en caso de no
correspondencia. El operador de combinación LEFT JOIN, indica que todas las filas de la
primera tabla se deben incluir en los resultados, con independencia si hay datos coincidentes
en la segunda tabla.
El resultado de esta operación siempre contiene todos los registros de la tabla de la izquierda
(la primera tabla que se menciona en la consulta), aun cuando no exista un registro
correspondiente en la tabla de la derecha para uno de la izquierda. La sentencia LEFT
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 83
OUTER JOIN retorna la pareja de todos los valores de la tabla izquierda con los valores de la
tabla de la derecha correspondientes, o retorna un valor nulo NULL en caso de no
correspondencia.
Usando el ejemplo anterior utilizado en INNER JOIN de tablas y registros, aplicaremos lo
siguiente:
Deshabilitaremos los CONSTRAINT para poder insertar nuevos registros para la prueba de la
sentencia LEFT JOIN
ALTER TABLE Clientes NOCHECK CONSTRAINT ALL
ALTER TABLE Facturas NOCHECK CONSTRAINT ALL
ALTER TABLE Usuarios NOCHECK CONSTRAINT ALL
Insertaremos dos nuevos registros en la tabla Factura
INSERT INTO Facturas VALUES(20,11,350,400,50,GETDATE())
INSERT INTO Facturas VALUES(35,15,350,400,50,GETDATE())
Ahora, consultaremos la tabla Factura usando LEFT JOIN. Esta consulta retornara los id de
factura, el monto recibido y el nombre del cliente
Análisis de resultados
SELECT
f.id_factura,f.monto_recibido,c.nombre
FROM Facturas f
LEFT JOIN Clientes c ON(f.id_cliente=c.id_cliente)
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 84
Observe que el resultado de la consulta retorna dos valores null de la columna nombre. ¿Por
qué?
La sentencia LEFT JOIN retorna los registros de la tabla izquierda que coincidan con los de
la derecha y retorna valores null cuando no existe correspondencia. Recuerde que se
insertaron 3 registros en la tabla clientes.
INSERT INTO Clientes VALUES('Carlos','Reyes','001-9876542-3','Calle El
Manantial esquina Nicolas de Ovando #45','829-345-6789',GETDATE())
INSERT INTO Clientes VALUES('Royel','Rodriguez','402-9898542-9','Calle D
#95','849-987-4567',GETDATE())
INSERT INTO Clientes VALUES('Cesar','Cordero','223-4567542-3','Calle
Osvaldo Jerez #66 Mi Hogar','829-335-0265',GETDATE())
En la tabla Factura, se insertaron 2 nuevas facturas, las instrucciones son:
INSERT INTO Facturas VALUES(20,11,350,400,50,GETDATE())
INSERT INTO Facturas VALUES(35,15,350,400,50,GETDATE())
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 85
Observe que se usaron como id_usuario los id 20 y 35 que no existen en la tabla ya que solo
registramos anteriormente 4, pero, estamos asumiendo que si existían y que fueron
eliminados de la tabla Usuarios. Por otro lado, los id_cliente que se especificaron en las
sentencias INSERT fueron 11 y 15 que estamos asumiendo que existían en la tabla Clientes
pero que fueron eliminados para alcanzar el objetivo de la demostración de LEFT JOIN.
Cuando consultamos la tabla usando la sentencia LEFT JOIN, esta retorna el siguiente
resultado:
La razón de los valores null es porque el LEFT JOIN que especificamos en la cláusula ON
establece la condición cuando los id_cliente de la tabla Facturas sean igual a los id_cliente de
la tabla Clientes y ya que los id_cliente 20 y 35 no existen en la tabla Clientes, la consulta
retorna valores null en el campo nombre.
RIGHT JOIN
Esta operación es inversa a la anterior; el resultado de esta operación siempre contiene todos
los registros de la tabla de la derecha (la segunda tabla que se menciona en la consulta), aun
cuando no exista un registro correspondiente en la tabla de la izquierda para uno de la
derecha. La sentencia RIGHT OUTER JOIN retorna la pareja de todos los valores de la tabla
derecha con los valores de la tabla de la izquierda correspondiente, o retorna un valor nulo
NULL en caso de no correspondencia, por ejemplo:
SELECT
f.id_factura,f.monto_recibido,c.nombre
FROM Facturas f
RIGHT JOIN Clientes c ON(f.id_cliente=c.id_cliente)
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 86
Esta consulta retornaría el id_factura, monto_recibido y nombre de la tabla Factura
combinada con la tabla Clientes cuando el id_cliente de la tabla derecha, ósea Clientes,
coincida o no en la tabla izquierda ósea Factura.
Esta consulta retorna los nombres de los clientes, pero, como es un RIGHT JOIN, los
id_cliente no existen en la tabla Factura. Por tal razón, los id_factura y monto_recibido se
reflejan como NULL.
FULL JOIN
Esta operación presenta los resultados de tabla izquierda y tabla derecha aunque no tengan
correspondencia en la otra tabla. La tabla combinada contendrá, entonces, todos los registros
de ambas tablas y presentará valores null para registros sin pareja.
SELECT
f.id_factura,f.monto_recibido,c.nombre
FROM Facturas f
FULL JOIN Clientes c ON(f.id_cliente=c.id_cliente)
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 87
La consulta retorna los registros que coinciden o no pero de ambas tablas.
CROSS JOIN
Presenta el producto cartesiano de todos los registros de las dos tablas. Este omite la
condición en el JOIN. El código SQL para realizar este producto cartesiano enuncia las tablas
que serán combinadas, pero no incluye algún predicado que filtre el resultado.
SELECT
f.*,c.*
FROM Facturas f
CROSS JOIN Clientes c
CROSS JOIN combina todos los campos sin ninguna condición.
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 88
UNIDAD XV
Funciones de fecha y formas de conversión de datos
Metas de Aprendizaje:
Comprender el uso de las funciones de fecha
Aprender a convertir tipos de datos
Conocer las ventajas y desventajas de las funciones de fecha
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 89
Funciones de fecha
Función Descripción
DATEADD
Retorna un valor date con el intervalo number
especificado, agregado a un valor
DATEPART especificado de ese valor date.
DATEADD (datepart , number , date)
DECLARE @FECHA DATE = '1-8-2011'
SELECT 'YEAR' 'PERIODO ',
DATEADD(YEAR,1,@FECHA) 'NUEVA
FECHA'
UNION ALL
SELECT
'QUARTER',DATEADD(QUARTER,1,@FECHA)
UNION ALL
SELECT
'MONTH',DATEADD(MONTH,1,@FECHA)
UNION ALL
SELECT 'DAY',DATEADD(DAY,1,@FECHA)
UNION ALL
SELECT 'WEEK',DATEADD(WEEK,1,@FECHA)
GO
DATEDIFF Retorna el número de límites DATEPART de
fecha y hora entre dos fechas especificadas.
SET DATEFORMAT DMY
DECLARE @FECHAINICIAL DATE = '01-08-
2011';
DECLARE @FECHAFINAL DATE = '01-09-
2011';
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 90
SELECT DATEDIFF(DAY,
@FECHAINICIAL,@FECHAFINAL) AS
'DURACION'
DATENAME Retorna una cadena de caracteres que
representa el DATEPART especificado de la
fecha especificada.
DATENAME ( datepart , date )
SELECT DATENAME(MONTH, GETDATE()) AS
'MES';
DATEPART Retorna un entero que representa el
DATEPART especificado del date
especificado.
DATEPART ( datepart , date )
SELECT DATEPART(MONTH, GETDATE()) AS
'MES';
DAY Devuelve un entero que representa la parte
del día DATEPART de la fecha especificada.
SELECT DAY('01/9/2011') AS 'DÍA DEL
MES';
GETDATE() Retorna la fecha del sistema
SELECT GETDATE() 'FECHA DEL SISTEMA';
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 91
MONTH
Retorna un entero que representa el mes de
date especificado. MONTH devuelve el
mismo valor que DATEPART (month, date).
SELECT MONTH(GETDATE()) AS 'MES DE LA
FECHA DE
SISTEMA';
YEAR Retorna un entero que representa el año de
date especificado. YEAR devuelve el mismo
valor que DATEPART (year, date).
SELECT YEAR(GETDATE()) AS 'AÑO DE LA
FECHA DE SISTEMA';
Funciones para manipular cadenas
Función Descripción
LEFT() Retorna la parte izquierda de una cadena de
caracteres con el número de caracteres
especificado.
LEFT(expresión_caracter,
integer_expression)
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 92
LEN() Retorna el número de caracteres de la
expresión de cadena especificad, excluidos
los espacios en blanco finales.
LEN(string)
LOWER() Retorna una expresión de caracteres después
de convertir en minúsculas los datos de
caracteres en mayúsculas.
LOWER(expresion_caracter)
LTRIM() Retorna una expresión de caracteres tras
quitar todos los espacios iniciales en blanco.
LTRIM(expresion_caracter)
RTRIM() Retorna una cadena de caracteres después de
truncar todos los espacios en blanco finales.
RTRIM(expresion_caracter)
UPPER() Retorna una expresión de caracteres con
datos de caracteres en minúsculas convertidos
a mayúsculas.
UPPER(expresion_caracter)
SUBSTRING() Devuelve parte de una expresión de
caracteres, binaria, de texto o de imagen.
SUBSTRING(valor_expresion,
inicio_expresion,
longitud_expresion)
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 93
Funciones de conversión de datos
Función Descripción
CAST() Esta función convierte una expresión a un
tipo de dato.
CAST(expresión AS
tipo_dato[(longitud)])
CONVERT() Convierte una expresión a un tipo de dato,
pero, con un estilo.
CONVERT(tipo_dato [(longitud)],
expresión [, estilo])
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 94
UNIDAD XVI
Uso de Sub - Consultas
Metas de Aprendizaje:
Comprender el uso de las funciones de fecha
Aprender a convertir tipos de datos
Conocer las ventajas y desventajas de las funciones de fecha
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 95
Definición de Sub – Consulta
Una sub - consulta es una sentencia SELECT que aparece dentro de otra sentencia SELECT.
Normalmente se utilizan para filtrar una cláusula WHERE o HAVING con el conjunto de
resultados de la sub - consulta, aunque también pueden utilizarse en la lista de selección.
Consideraciones para hacer una sub – consulta:
Primero se ejecuta la sub – consulta y luego la consulta principal.
Se analiza el resultado que retorna la sub – consulta, para luego ser utilizado en la
consulta principal.
Es necesario encerrar las sub – consultas entre paréntesis.
No usar clausulas ORDER BY dentro de una sub – consulta.
Utilice operadores para consultas que trabajaran sobre varios registros.
Tipos de sub - consultas
Por un solo registros
Por múltiples registros
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 96
Sub – consulta para un único registro
En este tipo de sub – consultas solo se necesita retornar un solo valor. Para hacer una sub
– consulta que tenga que retornar un solo valor, se necesitan usar operadores lógicos de
comparación. Por ejemplo:
Operador Significado
= Igual que
> Mayor que
< Menor que
>= Mayor igual que
<= Menor igual que
<> Diferente de
¿Cómo retornar un solo registro con una sub - consulta?
Utilizando funciones de grupo como MIN() o MAX(). También haciendo uso de la cláusula
WHERE o HAVING para obtener un solo resultado. Recuerde que los SELECT que están
dentro de paréntesis son las sub – consultas.
SELECT
f.id_factura,f.monto_recibido,c.nombre
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 97
FROM Facturas f
INNER JOIN Clientes c ON(f.id_cliente=c.id_cliente)
WHERE c.id_cliente= (SELECT id_cliente FROM Clientes WHERE id_cliente=2)
SELECT
f.id_factura,f.monto_recibido,c.nombre
FROM Facturas f
INNER JOIN Clientes c ON(f.id_cliente=c.id_cliente)
WHERE c.id_cliente= (SELECT MIN(id_cliente) FROM Clientes)
SELECT
f.id_factura,f.monto_recibido,c.nombre,c.apellido
FROM Facturas f
INNER JOIN Clientes c ON(f.id_cliente=c.id_cliente)
WHERE c.id_cliente= (SELECT MIN(id_cliente) FROM Clientes WHERE
apellido='Rodriguez')
SELECT
f.id_factura,SUM(f.monto_recibido),c.nombre,c.apellido
FROM Facturas f
INNER JOIN Clientes c ON(f.id_cliente=c.id_cliente)
GROUP BY f.id_factura,c.nombre,c.apellido
HAVING SUM(f.monto_recibido)= (SELECT MAX(monto_recibido) FROM Facturas)
Sub – consulta para múltiples registros
Para retornar múltiples registros utilizando una sub – consulta se deben utilizar operadores de
comparación. La siguiente tabla muestra los operadores que se deben utilizar:
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 98
Operador Descripción
IN Compara si uno o más de los elementos
retornados por la sub - consulta coinciden
con los de la lista de la consulta principal.
ANY Compara el valor de la consulta por
cualquiera de los valores que son retornados
por la sub - consulta.
ALL Compara el valor de la consulta con todos los
valores que retorna la sub - consulta.
¿Cómo retornar múltiples registros con una sub - consulta?
Usando los operadores ANY, IN y ALL se puede conseguir hacer una consulta que retorne
múltiples registros.
SELECT
f.id_factura,SUM(f.monto_recibido),c.nombre,c.apellido
FROM Facturas f
INNER JOIN Clientes c ON(f.id_cliente=c.id_cliente)
WHERE f.monto_recibido IN(SELECT MIN(monto_recibido) FROM Facturas)
GROUP BY f.id_factura,c.nombre,c.apellido
SELECT
f.id_factura,SUM(f.monto_recibido),c.nombre,c.apellido
FROM Facturas f
INNER JOIN Clientes c ON(f.id_cliente=c.id_cliente)
WHERE f.monto_recibido >ALL(SELECT MIN(monto_recibido) FROM Facturas)
GROUP BY f.id_factura,c.nombre,c.apellido
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 99
Bibliografía
Microsoft Developer Network (MSDN)
Guille SQL
Pinal Dave (SQL Authority)
Fundamentos de SQL – Autor: Andy Oppel & Robert Sheldon
POR JOSEPH ARQUIMEDES COLLADO & JOSE LUIS LOPEZ GONZALEZ 100
También podría gustarte
- Cuaderno de Derecho Administrativo 1 - Lecturas-1Documento76 páginasCuaderno de Derecho Administrativo 1 - Lecturas-1David RomeroAún no hay calificaciones
- Ética Empresarial CalzadoDocumento77 páginasÉtica Empresarial Calzadofrancisco hernandezAún no hay calificaciones
- Toledo Valeska HPI201-9025-2022 Semana3y4Documento15 páginasToledo Valeska HPI201-9025-2022 Semana3y4Valeska GaunaAún no hay calificaciones
- Dislexia, Adecuar para aprender en equidad: Herramientas, soportes y andamiajes que transformanDe EverandDislexia, Adecuar para aprender en equidad: Herramientas, soportes y andamiajes que transformanAún no hay calificaciones
- Puente Peatonal MaderaDocumento18 páginasPuente Peatonal MaderaLizLozaChipaAún no hay calificaciones
- Guía Investigación Delitos CorrupciónDocumento96 páginasGuía Investigación Delitos CorrupciónClemencia Toj MendozaAún no hay calificaciones
- Asun 3794821 20181213 1544721094Documento192 páginasAsun 3794821 20181213 1544721094Juan MatzAún no hay calificaciones
- Instituto Tecnologico de Chetumal PortadaDocumento99 páginasInstituto Tecnologico de Chetumal PortadaAlondra Rodriguez PecheAún no hay calificaciones
- Apunte TEORIA Hasta PlateasDocumento75 páginasApunte TEORIA Hasta PlateasSebastian JacoboAún no hay calificaciones
- Manual Excel 2016Documento100 páginasManual Excel 2016Carlos Salas MurilloAún no hay calificaciones
- Manual Usuario SGDE ESSALUD V1.0Documento52 páginasManual Usuario SGDE ESSALUD V1.0Ernesto SamameAún no hay calificaciones
- Proyecto Merca 3Documento200 páginasProyecto Merca 3Rosibel AlemanAún no hay calificaciones
- 05 Material Curso - Juicios-EJERCICIOS-927Documento8 páginas05 Material Curso - Juicios-EJERCICIOS-927cecilia cafferataAún no hay calificaciones
- Castellano 7Documento190 páginasCastellano 7Pacers07Aún no hay calificaciones
- Diseño de Una Solución SAN para Centralizar LDocumento287 páginasDiseño de Una Solución SAN para Centralizar LAnonymous 6fiVfeQAún no hay calificaciones
- PandoraFMS 5.1 Manual Usos Avanzados ES PDFDocumento431 páginasPandoraFMS 5.1 Manual Usos Avanzados ES PDFmiguelib2009Aún no hay calificaciones
- Bienvenido Al Curso de WPFDocumento374 páginasBienvenido Al Curso de WPFrodolfojavier1982Aún no hay calificaciones
- Administración Bases de DatosDocumento82 páginasAdministración Bases de DatosErnesto MascorroAún no hay calificaciones
- Documento de Help DeskDocumento64 páginasDocumento de Help DeskEnrique AñezAún no hay calificaciones
- Manual de ECLDocumento157 páginasManual de ECLJeampierr JIMENEZ MARQUEZAún no hay calificaciones
- La Practica de La Terapia en FamiliaDocumento14 páginasLa Practica de La Terapia en FamiliaIvonneAún no hay calificaciones
- Mi Plan de VidaDocumento2 páginasMi Plan de VidaSantiago Herrera0% (1)
- Estudio Proceso de Ejecucion en La Via de ApremioDocumento9 páginasEstudio Proceso de Ejecucion en La Via de ApremioAngela GarciaAún no hay calificaciones
- El Estrés en El TrabajoDocumento28 páginasEl Estrés en El TrabajoMiguel Angel FigueroaAún no hay calificaciones
- GchilladocxDocumento17 páginasGchilladocxCarlos Andres Contreras GajardoAún no hay calificaciones
- Manual Teoria PDFDocumento128 páginasManual Teoria PDFjorghelaldoAún no hay calificaciones
- Percepcion y Toma de Decisiones - TerminadoDocumento42 páginasPercepcion y Toma de Decisiones - TerminadoKenny Kakiyama VergaraAún no hay calificaciones
- Actividades Lúdicas de Recuperación EmocionalDocumento72 páginasActividades Lúdicas de Recuperación EmocionalSARA CORRALESAún no hay calificaciones
- Tus Derechos en El Trabajo 6 Indice PDFDocumento9 páginasTus Derechos en El Trabajo 6 Indice PDFlaboro57170% (1)
- ¡No vendas, haz que te compren! Neuroventas: 7 Pasos un caminoDe Everand¡No vendas, haz que te compren! Neuroventas: 7 Pasos un caminoAún no hay calificaciones
- Wuolah Free Curso Aleman A1Documento59 páginasWuolah Free Curso Aleman A1Pau BelmonteAún no hay calificaciones
- Kiu Administrador 2.0Documento62 páginasKiu Administrador 2.0Jose PulidoAún no hay calificaciones
- Excel 2016 nivel avanzado - funciones y herramientasDocumento122 páginasExcel 2016 nivel avanzado - funciones y herramientasTHALIA YAJAIRA RIMAC VEGA100% (4)
- Guia Genero y CalidadDocumento91 páginasGuia Genero y Calidadvisaelisa1Aún no hay calificaciones
- ClarosDocumento72 páginasClarosJorge ClarosAún no hay calificaciones
- Gago Miguel Neuroliderazgo para El Alto DesempeoDocumento172 páginasGago Miguel Neuroliderazgo para El Alto DesempeoDirk LozanoAún no hay calificaciones
- Ebook Autodisciplina FitnessDocumento45 páginasEbook Autodisciplina FitnessJuan PErez100% (5)
- SCC Guia UsuarioDocumento42 páginasSCC Guia UsuarioAlonso RamosAún no hay calificaciones
- Seo TestDocumento210 páginasSeo TestvinyolsAún no hay calificaciones
- Aplicación de Estadística Descriptiva en El Sistema de Comercialización en La Heladería SoleilDocumento33 páginasAplicación de Estadística Descriptiva en El Sistema de Comercialización en La Heladería SoleilBayron ReloadedAún no hay calificaciones
- Apadrinamiento 0001Documento58 páginasApadrinamiento 0001José Manuel Perera GarcíaAún no hay calificaciones
- Lunes 24 de Julio OrientacionDocumento3 páginasLunes 24 de Julio OrientacionRaquel Parra ParraAún no hay calificaciones
- 1primer Papel de TrabajoDocumento3 páginas1primer Papel de TrabajoLUIS NT BELTRAN BERROCALAún no hay calificaciones
- González 2020Documento146 páginasGonzález 2020Preuniversitario ACesorAún no hay calificaciones
- Seminario Practico de Desarrollo de Ventas Digitales y Gestión de Un Negocio DigitalDocumento38 páginasSeminario Practico de Desarrollo de Ventas Digitales y Gestión de Un Negocio DigitalEdgar Arellano cortezAún no hay calificaciones
- Irrazábal G., Doctrina Social de La Iglesia y Etica Política 2009Documento191 páginasIrrazábal G., Doctrina Social de La Iglesia y Etica Política 2009ArielAún no hay calificaciones
- Integrador1 AvanzazadoDocumento12 páginasIntegrador1 Avanzazadoalexis ronald guevara espinozaAún no hay calificaciones
- Proyecto Final 1Documento33 páginasProyecto Final 1juan pablo masaiAún no hay calificaciones
- Zxyel Macho Seductortzw PDFDocumento69 páginasZxyel Macho Seductortzw PDFEsver VicenteAún no hay calificaciones
- Secme 19274Documento194 páginasSecme 19274GerardoAún no hay calificaciones
- Gomez Torrego Leonardo - La Impersonalidad GramaticalDocumento69 páginasGomez Torrego Leonardo - La Impersonalidad GramaticalNicolas CortesAún no hay calificaciones
- PERSUADIR PARA INFLUIR EN EL PROJIMO: PSICOLOGIADe EverandPERSUADIR PARA INFLUIR EN EL PROJIMO: PSICOLOGIAAún no hay calificaciones
- El proceso de la investigación social cualitativaDe EverandEl proceso de la investigación social cualitativaAún no hay calificaciones
- Tipo DocuDocumento1 páginaTipo DocuAdministrador AndroidAún no hay calificaciones
- Afiliaciones SistemaDocumento4 páginasAfiliaciones SistemaAdministrador AndroidAún no hay calificaciones
- AfiliacionesDocumento4 páginasAfiliacionesAdministrador AndroidAún no hay calificaciones
- UntitledDocumento4 páginasUntitledAdministrador AndroidAún no hay calificaciones
- Afiliaciones RUAF ShirleyDocumento2 páginasAfiliaciones RUAF ShirleyAngela GHAún no hay calificaciones
- COSTOhhjhjDocumento1 páginaCOSTOhhjhjAdministrador AndroidAún no hay calificaciones
- Certificación para Cambio de VersiónDocumento1 páginaCertificación para Cambio de VersiónAdministrador AndroidAún no hay calificaciones
- UntitledDocumento4 páginasUntitledAdministrador AndroidAún no hay calificaciones
- Costo MayoDocumento2 páginasCosto MayoAdministrador AndroidAún no hay calificaciones
- Relecion de FacDocumento1 páginaRelecion de FacAdministrador AndroidAún no hay calificaciones
- Códigos Paises: Cód. DescripciónDocumento8 páginasCódigos Paises: Cód. DescripciónFelipe Augusto Diaz SuazaAún no hay calificaciones
- Códigos Paises: Cód. DescripciónDocumento8 páginasCódigos Paises: Cód. DescripciónFelipe Augusto Diaz SuazaAún no hay calificaciones
- Formulario de Solicitud-AutomotorDocumento2 páginasFormulario de Solicitud-AutomotorJuan CamiloAún no hay calificaciones
- Instructivo Actualizado para Descargar Certificados de RetencionDocumento3 páginasInstructivo Actualizado para Descargar Certificados de RetencionAdministrador AndroidAún no hay calificaciones
- Formato de Constancia para La Transferencia de Propiedad de Un Equipo Terminal Móvil UsadoDocumento1 páginaFormato de Constancia para La Transferencia de Propiedad de Un Equipo Terminal Móvil UsadoAndres Maldonado Beltran100% (1)
- Formulario de Solicitud-AutomotorDocumento2 páginasFormulario de Solicitud-AutomotorJuan CamiloAún no hay calificaciones
- G2Documento1 páginaG2Administrador AndroidAún no hay calificaciones
- 4Documento2 páginas4Administrador AndroidAún no hay calificaciones
- W2Documento2 páginasW2Administrador AndroidAún no hay calificaciones
- Listado de ProductsDocumento1 páginaListado de ProductsAdministrador AndroidAún no hay calificaciones
- DsfsfsdfssaqqqqqqqqDocumento2 páginasDsfsfsdfssaqqqqqqqqAdministrador AndroidAún no hay calificaciones
- W2Documento2 páginasW2Administrador AndroidAún no hay calificaciones
- DsfsfsdfssaqqqqqqqqDocumento2 páginasDsfsfsdfssaqqqqqqqqAdministrador AndroidAún no hay calificaciones
- 4Documento2 páginas4Administrador AndroidAún no hay calificaciones
- Listado de ProductsDocumento1 páginaListado de ProductsAdministrador AndroidAún no hay calificaciones
- Listado de ProductsDocumento1 páginaListado de ProductsAdministrador AndroidAún no hay calificaciones
- Listado de ProductsDocumento1 páginaListado de ProductsAdministrador AndroidAún no hay calificaciones
- 2021.08.20 00 Pendiente Por Asignacion Itagui CalatravaDocumento1 página2021.08.20 00 Pendiente Por Asignacion Itagui CalatravaAdministrador AndroidAún no hay calificaciones
- 2Documento1 página2Administrador AndroidAún no hay calificaciones
- NORMALIZACIÓNDocumento15 páginasNORMALIZACIÓNjose8manuel8bern88beAún no hay calificaciones
- Guia de Ejercicios de NormalizacionDocumento7 páginasGuia de Ejercicios de Normalizacionheisemberg5694Aún no hay calificaciones
- Fundamentos de La Normalización de Bases de Datos PDFDocumento6 páginasFundamentos de La Normalización de Bases de Datos PDFjoseph tobonAún no hay calificaciones
- Normalización de bases de datos: Formas normales 1FN a BCNFDocumento15 páginasNormalización de bases de datos: Formas normales 1FN a BCNFBerenice Ramirez HernandezAún no hay calificaciones
- Taller de Normalizacion PDFDocumento3 páginasTaller de Normalizacion PDFAlexey RojasAún no hay calificaciones
- Normalizacion BDDocumento7 páginasNormalizacion BDESTEFANIA ABRILAún no hay calificaciones
- Cuarta Forma NormalDocumento4 páginasCuarta Forma Normalsolrac1308Aún no hay calificaciones
- NormalizacionDocumento19 páginasNormalizacionKEVIN DAVID DIAZ CANDELOAún no hay calificaciones
- Normalización de Base de DatosDocumento2 páginasNormalización de Base de DatosJoshep Antoniwo Diego RevillaAún no hay calificaciones
- 2do ParcialDocumento4 páginas2do ParcialRoy Jorge ArnezAún no hay calificaciones
- Unidad I - Introducción A Oracle - ParteIDocumento68 páginasUnidad I - Introducción A Oracle - ParteICarlosSandovalMedinaAún no hay calificaciones
- 8 NormalizacionDocumento18 páginas8 NormalizacionCristián Vergara CastroAún no hay calificaciones
- 2021 11 11 Practica - Normalizar Una Base de DatosDocumento8 páginas2021 11 11 Practica - Normalizar Una Base de DatosQuiquez ElodioAún no hay calificaciones
- Análisis de Caso 1 Diseño y Administración de Bases de Datos Andrés MarínDocumento5 páginasAnálisis de Caso 1 Diseño y Administración de Bases de Datos Andrés MarínAndrés MarínAún no hay calificaciones
- Formas NormalesDocumento3 páginasFormas NormalesHenry Aroldo Culajay BororAún no hay calificaciones
- Normalización de bases de datos: Formas normalesDocumento16 páginasNormalización de bases de datos: Formas normalesJOSE IGNACIO DIAZ RODRIGEZAún no hay calificaciones
- Normalizacion de Bases de DatosDocumento36 páginasNormalizacion de Bases de DatosArmando CasallasAún no hay calificaciones
- Actividad 4 Mario NormalizacionDocumento4 páginasActividad 4 Mario NormalizacionJoelissa PerdomoAún no hay calificaciones
- Reducción de Los Diagramas E-R A TablasDocumento7 páginasReducción de Los Diagramas E-R A TablasManuel Eduardo GutierrezAún no hay calificaciones
- Normalización BD: concepto, importancia y aplicaciónDocumento3 páginasNormalización BD: concepto, importancia y aplicaciónSARAH MICHELLE LÓPEZ MUÑOZAún no hay calificaciones
- Normalización 1FN, 2FN, 3FN, 4FNDocumento17 páginasNormalización 1FN, 2FN, 3FN, 4FNJorge RodriguezAún no hay calificaciones
- Clase Teorica de Base de Datos 15 - 04 - 20Documento10 páginasClase Teorica de Base de Datos 15 - 04 - 20Mayerlin A Diaz GAún no hay calificaciones
- EntityFramework DB FirstDocumento28 páginasEntityFramework DB FirstMarco Antonio Monzón LazcanoAún no hay calificaciones
- Reconocer La Importancia Del Concepto de Normalización en Una Base de Datos1.Documento5 páginasReconocer La Importancia Del Concepto de Normalización en Una Base de Datos1.jhonny marinAún no hay calificaciones
- Guía de Ejercicios NormalizacionDocumento2 páginasGuía de Ejercicios NormalizacionIdalys MilagroAún no hay calificaciones
- Manual AccessDocumento45 páginasManual AccessGUIJARRO NÚÑEZ JONATHAN ALEJANDROAún no hay calificaciones
- Normalizacion de Bases de DatosDocumento19 páginasNormalizacion de Bases de DatosHugo de PauzaAún no hay calificaciones
- NormalizaciónDocumento23 páginasNormalizaciónMarcela PadillaAún no hay calificaciones
- Normalización de DatosDocumento14 páginasNormalización de DatosGabriel Forero BarretoAún no hay calificaciones
- Foro 2Documento4 páginasForo 2Natty FloresAún no hay calificaciones