
También podría gustarte
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Fase 4 Medidas EstadísticasDocumento31 páginasFase 4 Medidas EstadísticasdarwinyandreaAún no hay calificaciones
- TAREA # 4 Medidas de Tendencia Central, Localización y DispersiónDocumento10 páginasTAREA # 4 Medidas de Tendencia Central, Localización y DispersiónCarlos HernandezAún no hay calificaciones
- Primeras Lecturas de Estad Stica DescriptivaDocumento7 páginasPrimeras Lecturas de Estad Stica DescriptivaMaria Pia Morales RiveroAún no hay calificaciones
- Tarea Investigación Aplicada Estadística DescriptivaDocumento10 páginasTarea Investigación Aplicada Estadística DescriptivaElida elizabeth García lumbrerasAún no hay calificaciones
- Parcial 1 EstadísticaDocumento128 páginasParcial 1 EstadísticaIxchel Marisol Zapeta AlbanésAún no hay calificaciones
- Documento de Cátedra Unidad 4 PDFDocumento9 páginasDocumento de Cátedra Unidad 4 PDFGuillermo Alexander Hernandez HernandezAún no hay calificaciones
- Trabajo Final ProbabilidadDocumento111 páginasTrabajo Final ProbabilidadKhabib SánchezAún no hay calificaciones
- Estaditica EmilioDocumento7 páginasEstaditica EmilioycremAún no hay calificaciones
- Practica 2 Varianza PiiDocumento22 páginasPractica 2 Varianza PiiMayerlin GonzalezAún no hay calificaciones
- Conceptos EstadisticosDocumento11 páginasConceptos EstadisticosJessica SisaAún no hay calificaciones
- Estadistica - IntroducciónDocumento5 páginasEstadistica - IntroducciónRena CrespoAún no hay calificaciones
- Tarea 3 EstadisticaDocumento7 páginasTarea 3 EstadisticaTommy Orrala MAún no hay calificaciones
- Trabajo Escrito ESTADISTICA Medidas de TendenciaDocumento8 páginasTrabajo Escrito ESTADISTICA Medidas de TendenciagissellAún no hay calificaciones
- MATEMATICASDocumento9 páginasMATEMATICASduendemendoza666Aún no hay calificaciones
- Estadistica InstruccionalDocumento12 páginasEstadistica InstruccionalTeresa ZoghbiAún no hay calificaciones
- Vet Cristopher Mantilla 30121076Documento10 páginasVet Cristopher Mantilla 30121076Sara Chacon BernalAún no hay calificaciones
- Guia Definiciones BasicaDocumento6 páginasGuia Definiciones BasicaVianna Del Sol n sAún no hay calificaciones
- ESTADÍSTICA DES-WPS OfficeDocumento15 páginasESTADÍSTICA DES-WPS Officeronny joseAún no hay calificaciones
- Estadistica 2Documento18 páginasEstadistica 2BrendelbashnJoseDanielCarrasquelAún no hay calificaciones
- ESTADISTICASDocumento7 páginasESTADISTICASandrea menaAún no hay calificaciones
- Estadística Descriptiva - 2-1Documento21 páginasEstadística Descriptiva - 2-1Gabriela GutierrezAún no hay calificaciones
- Estadistica Descriptiva INVESTIGACIONDocumento7 páginasEstadistica Descriptiva INVESTIGACIONMARIELIS GONZALEZAún no hay calificaciones
- Probabilidad y EstadísticaDocumento9 páginasProbabilidad y EstadísticaEduardo AlvarezAún no hay calificaciones
- Andino Estefany U2T1a6Documento9 páginasAndino Estefany U2T1a6Estefany AndinoAún no hay calificaciones
- Definición de EstadísticaDocumento27 páginasDefinición de Estadísticaesni10Aún no hay calificaciones
- Rigoberto - Ef1 - Probabilidad y EstadisticaDocumento10 páginasRigoberto - Ef1 - Probabilidad y EstadisticaRIGOBERTO MARIN OVIEDOAún no hay calificaciones
- Actividad 1 Estadistica InferencialDocumento9 páginasActividad 1 Estadistica InferencialLizeth Hernández100% (1)
- Actividad N. 3estadistica Inferencial ForoDocumento9 páginasActividad N. 3estadistica Inferencial ForoMarina PalacioAún no hay calificaciones
- Actividad 4. Formulario EstadísticoDocumento6 páginasActividad 4. Formulario EstadísticoDiana100% (1)
- Qué Es La EstadísticaDocumento10 páginasQué Es La EstadísticaJesus DiazAún no hay calificaciones
- Estadística y PrevalidadDocumento10 páginasEstadística y PrevalidadCesar TiradoAún no hay calificaciones
- Estadística DescriptivaDocumento6 páginasEstadística DescriptivaGlendaZamoraAún no hay calificaciones
- MEDIADocumento7 páginasMEDIAEvelyn GutiérrezAún no hay calificaciones
- Descargable U2Documento21 páginasDescargable U2juan manuelAún no hay calificaciones
- VarianzaDocumento12 páginasVarianzaAlejandro SanchezAún no hay calificaciones
- ModaDocumento5 páginasModaVanessa RinconAún no hay calificaciones
- 3P - Guia 5 - Estadistica - John Jairo Obando Galvis (10.5-10.6-10.7) 2022Documento15 páginas3P - Guia 5 - Estadistica - John Jairo Obando Galvis (10.5-10.6-10.7) 2022Jhon Jairo Obando GalvisAún no hay calificaciones
- Analisis BiometricoDocumento14 páginasAnalisis BiometricoAmaury Comas MontañoAún no hay calificaciones
- Medidas de Tendencia CentralDocumento7 páginasMedidas de Tendencia CentralOzkr Corilloclla AvilezAún no hay calificaciones
- Trabajo Medidas de Tendencia CentralDocumento20 páginasTrabajo Medidas de Tendencia CentralEloiby ValbuenaAún no hay calificaciones
- Fundamentos Estadísticos-DiapositivasDocumento20 páginasFundamentos Estadísticos-DiapositivasMarthaAún no hay calificaciones
- Conceptos Básicos de EstadísticaDocumento13 páginasConceptos Básicos de EstadísticaRicardo Jose Pineda EscobarAún no hay calificaciones
- Medidas de Tendencia CentralDocumento23 páginasMedidas de Tendencia CentralWilfredoAún no hay calificaciones
- Andres Trabajo Deciles PercentilesDocumento6 páginasAndres Trabajo Deciles PercentilesNicky Gibo RitaAún no hay calificaciones
- 1 Actividad Estadistica 31-07-2023Documento3 páginas1 Actividad Estadistica 31-07-2023Lina Marcela Pulido LandinezAún no hay calificaciones
- Estadistica UnidDocumento2 páginasEstadistica UnidGDLMAún no hay calificaciones
- Resumen EstadisticaDocumento11 páginasResumen EstadisticaJuan CarlosAún no hay calificaciones
- Las Medidas de Tendencia Central Son Medidas Estadísticas Que Pretenden Resumir en Un Solo Valor A Un Conjunto de ValoresDocumento6 páginasLas Medidas de Tendencia Central Son Medidas Estadísticas Que Pretenden Resumir en Un Solo Valor A Un Conjunto de ValoresEnrique HernandezAún no hay calificaciones
- Reporte Video de La Unidad 3Documento8 páginasReporte Video de La Unidad 3Luz Ángela EspinosaAún no hay calificaciones
- Intervalo de ConfianzaDocumento18 páginasIntervalo de ConfianzaFernandoAún no hay calificaciones
- Taller EstadisticaDocumento5 páginasTaller EstadisticaCarolvanesa PrietomolinaAún no hay calificaciones
- Minimalist Vintage Medieval Brown Museum PresentationDocumento19 páginasMinimalist Vintage Medieval Brown Museum PresentationRida CatalellaAún no hay calificaciones
- Moda, Que Es El Valor Que Más Se Repite Dentro Del Conjunto de Datos. Por Ejemplo, en ElDocumento3 páginasModa, Que Es El Valor Que Más Se Repite Dentro Del Conjunto de Datos. Por Ejemplo, en ElNathalia TapiaAún no hay calificaciones
- Sintesis EstadisticaDocumento8 páginasSintesis EstadisticaKatherin EscobarAún no hay calificaciones
- Resumen EstadisticaDocumento9 páginasResumen EstadisticaCaterina KategoraAún no hay calificaciones
- Parcial ESTADISTICADocumento7 páginasParcial ESTADISTICAFlor AlegreAún no hay calificaciones
- Reporte de La Unidad IiiDocumento47 páginasReporte de La Unidad IiiLuz Ángela EspinosaAún no hay calificaciones
- CUARTILESDocumento7 páginasCUARTILESAlex Alegria LinaresAún no hay calificaciones
- Probabilidad y EstadisticaDocumento6 páginasProbabilidad y EstadisticaUltimateBuld399Aún no hay calificaciones
- Actividad Fecha 10 de NoviembreDocumento1 páginaActividad Fecha 10 de NoviembreEliana Zapata ruedaAún no hay calificaciones
- Imagenes de Nuevas MasculinidadesDocumento9 páginasImagenes de Nuevas MasculinidadesEliana Zapata ruedaAún no hay calificaciones
- El Poder de La Comunicación AsertivaDocumento3 páginasEl Poder de La Comunicación AsertivaEliana Zapata ruedaAún no hay calificaciones
- Que Ha Pasado Con La Participacion Ciudadana en Colombia. Fabio VelasquezDocumento4 páginasQue Ha Pasado Con La Participacion Ciudadana en Colombia. Fabio VelasquezEliana Zapata ruedaAún no hay calificaciones
- Trabajo de Cierre - FinalDocumento13 páginasTrabajo de Cierre - FinalEliana Zapata ruedaAún no hay calificaciones
- EMOCIONESDocumento126 páginasEMOCIONESEliana Zapata ruedaAún no hay calificaciones
- Área Grado Maestro Periodo Inicia Culmina Contenidos Temáticos Básicos Periodo Indicadores de DesempeñoDocumento37 páginasÁrea Grado Maestro Periodo Inicia Culmina Contenidos Temáticos Básicos Periodo Indicadores de DesempeñoEliana Zapata ruedaAún no hay calificaciones
- Taller de NeuropsicologiaDocumento4 páginasTaller de NeuropsicologiaEliana Zapata ruedaAún no hay calificaciones
- LA VIDA ES UN JUEGO, Es Una ArteDocumento35 páginasLA VIDA ES UN JUEGO, Es Una ArteEliana Zapata ruedaAún no hay calificaciones
- Pruebas Primer PeriodoDocumento19 páginasPruebas Primer PeriodoEliana Zapata ruedaAún no hay calificaciones
- Proyecto de DemocraciaDocumento22 páginasProyecto de DemocraciaEliana Zapata ruedaAún no hay calificaciones
- Semana de Feria El PalacitoDocumento4 páginasSemana de Feria El PalacitoEliana Zapata ruedaAún no hay calificaciones
- Recomendaciones Academicas A Padres de FamiliaDocumento2 páginasRecomendaciones Academicas A Padres de FamiliaEliana Zapata ruedaAún no hay calificaciones
- TALLER ESTADISTICAn2Documento12 páginasTALLER ESTADISTICAn2Eliana Zapata ruedaAún no hay calificaciones
- UntitledDocumento2 páginasUntitledEliana Zapata ruedaAún no hay calificaciones
- Semana 2 Del 30 Enero Al 3 de FebreroDocumento7 páginasSemana 2 Del 30 Enero Al 3 de FebreroEliana Zapata ruedaAún no hay calificaciones
- Fichas de La Semana 3Documento8 páginasFichas de La Semana 3Eliana Zapata ruedaAún no hay calificaciones
- Invencion Del Desarrollo en ColombiaDocumento11 páginasInvencion Del Desarrollo en ColombiaEliana Zapata ruedaAún no hay calificaciones
- Taller Numero 3Documento6 páginasTaller Numero 3Eliana Zapata ruedaAún no hay calificaciones
- Semana Institucional Del 16 Al 20 de EneroDocumento1 páginaSemana Institucional Del 16 Al 20 de EneroEliana Zapata ruedaAún no hay calificaciones
- Semana 4 Del 13 Al 17 de FebreroDocumento11 páginasSemana 4 Del 13 Al 17 de FebreroEliana Zapata ruedaAún no hay calificaciones
- Observaciones Transicion 1-2012Documento18 páginasObservaciones Transicion 1-2012Eliana Zapata ruedaAún no hay calificaciones
- Ensayo LA ADMINISTRACION PUBLICA UNA MIRADA A SU INTERIORDocumento3 páginasEnsayo LA ADMINISTRACION PUBLICA UNA MIRADA A SU INTERIOREliana Zapata ruedaAún no hay calificaciones
- Contrato #PS 038 Luz Eliana Zapata RuedaDocumento12 páginasContrato #PS 038 Luz Eliana Zapata RuedaEliana Zapata ruedaAún no hay calificaciones
- Semana 1 Del 23 Al 27 EneroDocumento2 páginasSemana 1 Del 23 Al 27 EneroEliana Zapata ruedaAún no hay calificaciones
- Informe Actividades Luz Eliana Zapata 001Documento11 páginasInforme Actividades Luz Eliana Zapata 001Eliana Zapata ruedaAún no hay calificaciones
- UNIDAD2Documento11 páginasUNIDAD2Eliana Zapata ruedaAún no hay calificaciones
- ENSAYODocumento1 páginaENSAYOEliana Zapata ruedaAún no hay calificaciones
- Con La Pluma Escribo Mi HistoriaDocumento8 páginasCon La Pluma Escribo Mi HistoriaEliana Zapata ruedaAún no hay calificaciones
- Trabajo de Administracion PublicaDocumento18 páginasTrabajo de Administracion PublicaEliana Zapata ruedaAún no hay calificaciones
- EjerciciosDocumento5 páginasEjerciciosJulioCarlosSantos100% (1)
- Sustentacion Trabajo Colaborativo - Escenario 7 - Primer Bloque-Ciencias Basicas - Estadistica Inferencial - (Grupo2)Documento5 páginasSustentacion Trabajo Colaborativo - Escenario 7 - Primer Bloque-Ciencias Basicas - Estadistica Inferencial - (Grupo2)Víctor ManuelAún no hay calificaciones
- Probablilidad y EstadisticaDocumento10 páginasProbablilidad y EstadisticaMartínez Badillo José CarlosAún no hay calificaciones
- Notacion de KendallDocumento11 páginasNotacion de Kendallpepe389 gamerAún no hay calificaciones
- Variabilidad Del ProcesoDocumento7 páginasVariabilidad Del Procesojcrodgon0% (1)
- Taller de Estimación y Pruebas de HipótesisDocumento3 páginasTaller de Estimación y Pruebas de HipótesisJose Gabriel Salinas VillalbaAún no hay calificaciones
- Determinación de Hierro y Cobre en Vino. Estimación de Los Límites de Detección y Cuantificación para El CobreDocumento6 páginasDeterminación de Hierro y Cobre en Vino. Estimación de Los Límites de Detección y Cuantificación para El CobrecristinaruizgAún no hay calificaciones
- Práctica PH - 2023-2Documento2 páginasPráctica PH - 2023-2Tony Grandez SilvaAún no hay calificaciones
- Practica #12 Ic Media Proporc Sistemas 2021 10Documento2 páginasPractica #12 Ic Media Proporc Sistemas 2021 10BPstudios OficialAún no hay calificaciones
- SIM 2P Ejercicios Atributos L Gicas VR19Documento3 páginasSIM 2P Ejercicios Atributos L Gicas VR19Angelly RamosAún no hay calificaciones
- Web 5.simulador Medidas de Dispersion Variable Discreta y Continua 16-01 2018Documento23 páginasWeb 5.simulador Medidas de Dispersion Variable Discreta y Continua 16-01 2018Pérez EdithAún no hay calificaciones
- Ii. Distribuciones Probabilisticas DiscretasDocumento11 páginasIi. Distribuciones Probabilisticas DiscretasJose Miguel PeraltaAún no hay calificaciones
- U5 - 3Documento2 páginasU5 - 3lucyAún no hay calificaciones
- U de Mann WhitneyDocumento24 páginasU de Mann WhitneyAndre Freddy Haro Bendita100% (1)
- 8 Ejercicio - Experimentación Con Los Modelos de Regresión Más Eficaces - Training - Microsoft LearnDocumento13 páginas8 Ejercicio - Experimentación Con Los Modelos de Regresión Más Eficaces - Training - Microsoft Learnacxel david castillo casasAún no hay calificaciones
- Actividad de Aprendizaje Unidad 1 - Estadistica DescriptivaDocumento4 páginasActividad de Aprendizaje Unidad 1 - Estadistica DescriptivaDayana GonzalezAún no hay calificaciones
- Sustentacion Trabajo Colaborativo - Escenario 7 - Moreno Garzon Wilson DaniloDocumento7 páginasSustentacion Trabajo Colaborativo - Escenario 7 - Moreno Garzon Wilson DanilostevenAún no hay calificaciones
- Taller 1 - U3Documento15 páginasTaller 1 - U3mariana assia acostaAún no hay calificaciones
- Poster Anomalos Seguridad Vial Colombia 2018Documento1 páginaPoster Anomalos Seguridad Vial Colombia 2018Beatriz García Peña100% (2)
- ComfinDocumento22 páginasComfinSheyla MenesesAún no hay calificaciones
- Práctica BioestadísticaDocumento47 páginasPráctica BioestadísticaMICHELL YULISSA ROMO CARDENASAún no hay calificaciones
- Mat3eso Ac 128 PDFDocumento1 páginaMat3eso Ac 128 PDFJose Wvarley MostacillaAún no hay calificaciones
- Taller 1, Estadistica InferencialDocumento2 páginasTaller 1, Estadistica InferencialMILDRETH MUÑOZAún no hay calificaciones
- Examen - (AAB01) Cuestionario 1 - Realice El Cuestionario en EVA Correspondiente A Las Unidades 1 y 2Documento5 páginasExamen - (AAB01) Cuestionario 1 - Realice El Cuestionario en EVA Correspondiente A Las Unidades 1 y 2Mara LarreateguiAún no hay calificaciones
- Calibracion de Material Volumetrico QuimDocumento13 páginasCalibracion de Material Volumetrico QuimAlexis TibanAún no hay calificaciones
- 206 Matemáticas Ii Ebau2023 Junio Examen y Criterios - OkDocumento5 páginas206 Matemáticas Ii Ebau2023 Junio Examen y Criterios - OkIgnacio ChazarraAún no hay calificaciones
- Evaluacion Interna - Matematicas (Esta SiDocumento12 páginasEvaluacion Interna - Matematicas (Esta SiJoel López Vizueta100% (1)
- Control 1Documento4 páginasControl 1Betty OtinianoAún no hay calificaciones
- Resumen RiesgosDocumento1 páginaResumen RiesgosDaniel MacarioAún no hay calificaciones
- Análisis de Aparatos de Medida y Teoría de Error A Partir Del MRUADocumento13 páginasAnálisis de Aparatos de Medida y Teoría de Error A Partir Del MRUAErika Alexandra Hidalgo CuasquerAún no hay calificaciones
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Había una vez el átomo: O cómo los científicos imaginan lo invisibleDe EverandHabía una vez el átomo: O cómo los científicos imaginan lo invisibleCalificación: 5 de 5 estrellas5/5 (3)
- Guía práctica para la refracción ocularDe EverandGuía práctica para la refracción ocularCalificación: 5 de 5 estrellas5/5 (2)
- Armónicas en Sistemas Eléctricos IndustrialesDe EverandArmónicas en Sistemas Eléctricos IndustrialesCalificación: 4.5 de 5 estrellas4.5/5 (12)
- El Tao de la física: Una exploración de los paralelismos entre la física moderna y el misticismo orientalDe EverandEl Tao de la física: Una exploración de los paralelismos entre la física moderna y el misticismo orientalCalificación: 5 de 5 estrellas5/5 (3)
- Visualización: Cambie su vida en cuatro semanas utilizando la ley de atracciónDe EverandVisualización: Cambie su vida en cuatro semanas utilizando la ley de atracciónCalificación: 5 de 5 estrellas5/5 (18)
- Fundamentos de matemática: Introducción al nivel universitarioDe EverandFundamentos de matemática: Introducción al nivel universitarioCalificación: 3 de 5 estrellas3/5 (9)
- Mentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraDe EverandMentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraCalificación: 4.5 de 5 estrellas4.5/5 (5)
- Cálculo integral: Técnicas de integraciónDe EverandCálculo integral: Técnicas de integraciónCalificación: 4 de 5 estrellas4/5 (8)
- Los mágicos números del Doctor Matrix: Conviértete en un maestro de los númerosDe EverandLos mágicos números del Doctor Matrix: Conviértete en un maestro de los númerosCalificación: 5 de 5 estrellas5/5 (2)
- Matemáticas financieras y evaluación de proyectos: Segunda ediciónDe EverandMatemáticas financieras y evaluación de proyectos: Segunda ediciónAún no hay calificaciones
- La Guía Definitiva en Matemáticas para el Ingreso a la UniversidadDe EverandLa Guía Definitiva en Matemáticas para el Ingreso a la UniversidadCalificación: 4 de 5 estrellas4/5 (11)
- Control de calidad. Un enfoque integral y estadísticoDe EverandControl de calidad. Un enfoque integral y estadísticoCalificación: 5 de 5 estrellas5/5 (8)
- Entrelazamiento cuántico y sincronicidad. Campos de fuerza, no localidad, percepciones extrasensoriales. Las sorprendentes propiedades de la física cuántica.De EverandEntrelazamiento cuántico y sincronicidad. Campos de fuerza, no localidad, percepciones extrasensoriales. Las sorprendentes propiedades de la física cuántica.Calificación: 4.5 de 5 estrellas4.5/5 (9)
- La Física - Aventura del pensamientoDe EverandLa Física - Aventura del pensamientoCalificación: 4.5 de 5 estrellas4.5/5 (9)
- Análisis estructural mediante el método de los elementos finitos. Introducción al comportamiento lineal elásticoDe EverandAnálisis estructural mediante el método de los elementos finitos. Introducción al comportamiento lineal elásticoCalificación: 4.5 de 5 estrellas4.5/5 (12)
- Estadística básica: Introducción a la estadística con RDe EverandEstadística básica: Introducción a la estadística con RCalificación: 5 de 5 estrellas5/5 (8)
- La teoría de casi todo: El modelo estándar, triunfo no reconocido de la física modernaDe EverandLa teoría de casi todo: El modelo estándar, triunfo no reconocido de la física modernaCalificación: 4 de 5 estrellas4/5 (32)
- Mecánica cuántica para principiantesDe EverandMecánica cuántica para principiantesCalificación: 3.5 de 5 estrellas3.5/5 (5)
- Introducción a las ecuaciones de la física matemáticaDe EverandIntroducción a las ecuaciones de la física matemáticaCalificación: 5 de 5 estrellas5/5 (4)
- La Biblia de las Matemáticas RápidasDe EverandLa Biblia de las Matemáticas RápidasCalificación: 4.5 de 5 estrellas4.5/5 (19)




























































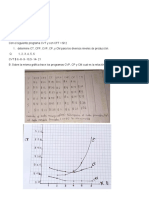














































































![Diseño de Experimentos [Métodos y Aplicaciones]](https://imgv2-2-f.scribdassets.com/img/word_document/436271314/149x198/596c96deb2/1654336147?v=1)







