También podría gustarte
- Curso básico de teoría de númerosDe EverandCurso básico de teoría de númerosCalificación: 5 de 5 estrellas5/5 (2)
- Algebra de BorelDocumento101 páginasAlgebra de BorelVön Jurgen RiggenbachAún no hay calificaciones
- Teoría de cuerpos y teoría de GaloisDe EverandTeoría de cuerpos y teoría de GaloisCalificación: 5 de 5 estrellas5/5 (1)
- Distribuciones probabilidad variables aleatoriasDocumento55 páginasDistribuciones probabilidad variables aleatoriasLaura Pamela AlvarezAún no hay calificaciones
- Cálculo estocásticoDocumento101 páginasCálculo estocásticoMax Valverde ErazoAún no hay calificaciones
- Funciones MediblesDocumento27 páginasFunciones MediblesAlejandro AlbertoAún no hay calificaciones
- Calculo Estocastico PDFDocumento101 páginasCalculo Estocastico PDFCristian Llanos MoscaizaAún no hay calificaciones
- Probab Problemas Tema 1 PDFDocumento3 páginasProbab Problemas Tema 1 PDFIrene PérezAún no hay calificaciones
- Procesos EstocasticosDocumento16 páginasProcesos EstocasticosivangrandaAún no hay calificaciones
- Material ClaseDocumento33 páginasMaterial ClaseFranco Ignacio Zurita ZuritaAún no hay calificaciones
- Resumen Espacio Muestral y EventosDocumento5 páginasResumen Espacio Muestral y EventosEnrique PerezAún no hay calificaciones
- Clase 2 - Parte 2Documento93 páginasClase 2 - Parte 2JC ParraAún no hay calificaciones
- ProbabilidadDocumento8 páginasProbabilidadFlorencia CaceresAún no hay calificaciones
- Elementos de Teoría de Probabilidades - MAT041 - SPDocumento56 páginasElementos de Teoría de Probabilidades - MAT041 - SPCarla MuñozAún no hay calificaciones
- Fase 3 Trabajo Colaborativo Probabilidad Grupo1Documento47 páginasFase 3 Trabajo Colaborativo Probabilidad Grupo1ximena sarmiento100% (2)
- Capítulo 2Documento24 páginasCapítulo 2neymarvaAún no hay calificaciones
- Variables aleatorias y probabilidadDocumento45 páginasVariables aleatorias y probabilidadalan_franco19Aún no hay calificaciones
- Introduccion A La ProbabilidadDocumento43 páginasIntroduccion A La ProbabilidadAnonymous l2a20NZSeLAún no hay calificaciones
- Probabilidades básicas: eventos, variables aleatorias y distribuciónDocumento24 páginasProbabilidades básicas: eventos, variables aleatorias y distribuciónzedanes0% (1)
- Guia TeoricaDocumento47 páginasGuia TeoricaCamilo BautistaAún no hay calificaciones
- Cap 4Documento35 páginasCap 4shoggothassoAún no hay calificaciones
- Procesos EstocasticosDocumento26 páginasProcesos EstocasticosivangrandaAún no hay calificaciones
- Variables aleatorias y probabilidadDocumento44 páginasVariables aleatorias y probabilidadAl CernaAún no hay calificaciones
- ProbabilodadDocumento7 páginasProbabilodadJose EspinozaAún no hay calificaciones
- Unidad I Clase 4Documento4 páginasUnidad I Clase 4Damaris SarmientoAún no hay calificaciones
- Capitulo 3. Introducción A La Probabilidad PDFDocumento13 páginasCapitulo 3. Introducción A La Probabilidad PDFvnn bbAún no hay calificaciones
- Medida de ProbabilidadDocumento8 páginasMedida de ProbabilidadKatia Lariisaa Jauregui0% (1)
- Practica ProbabilidadDocumento7 páginasPractica ProbabilidadJobian GutierrezAún no hay calificaciones
- Cap 4 PDFDocumento42 páginasCap 4 PDFFrancisco Montoya SánchezAún no hay calificaciones
- Folleto de Probabidad FinalDocumento36 páginasFolleto de Probabidad Finalfreddy darkAún no hay calificaciones
- Probabilidad de eventos en muestreo con y sin reemplazoDocumento5 páginasProbabilidad de eventos en muestreo con y sin reemplazoMichelle Vargas RojasAún no hay calificaciones
- 2023 2 Bayesiana Exposiciones Temas de RepasoDocumento20 páginas2023 2 Bayesiana Exposiciones Temas de RepasoLEIDY TATIANA ESTUPIÑAN RODRIGUEZAún no hay calificaciones
- ProbabilidadDocumento146 páginasProbabilidadManuel Soto FigueroaAún no hay calificaciones
- 2010 Matematicas 65 13Documento26 páginas2010 Matematicas 65 13kudasai_sugoi100% (1)
- Variables AleatoriasDocumento10 páginasVariables AleatoriasNicolas Cruz SwaneckAún no hay calificaciones
- Libro Proceso SDocumento199 páginasLibro Proceso Scerjio9Aún no hay calificaciones
- Variables Aleatorias: Facultad de Ciencias Matemáticas Escuela Profesional de Investigación Operativa Semestre 23 - IDocumento13 páginasVariables Aleatorias: Facultad de Ciencias Matemáticas Escuela Profesional de Investigación Operativa Semestre 23 - IJOSE FERNANDO MUGURUZA VASQUEZAún no hay calificaciones
- Principios de Probabilidad 2021Documento22 páginasPrincipios de Probabilidad 2021IzharAún no hay calificaciones
- Probabilidad II: Espacios de medida y variables aleatoriasDocumento6 páginasProbabilidad II: Espacios de medida y variables aleatoriasLetyAún no hay calificaciones
- Taller 4Documento7 páginasTaller 4MariaAngelicaNarvaezAún no hay calificaciones
- Probabilidades Discretas (Mate Discreta)Documento15 páginasProbabilidades Discretas (Mate Discreta)Renzo Espejo SalazarAún no hay calificaciones
- Mpro1 U3 A2 GuhgDocumento6 páginasMpro1 U3 A2 GuhgGustavo HernandezAún no hay calificaciones
- Va FamosasDocumento4 páginasVa FamosasCamiloSantiagoUjedaAún no hay calificaciones
- ME04403CDocumento50 páginasME04403CLuis Alberto Currea SáenzAún no hay calificaciones
- Mat2805 1Documento2 páginasMat2805 1RodrigoBazaesRiverosAún no hay calificaciones
- Algunas Distribuciones Discretas Importantes PDFDocumento30 páginasAlgunas Distribuciones Discretas Importantes PDFKevin Quijada LandaverdeAún no hay calificaciones
- Variables AleatoriasunidimensionalessDocumento22 páginasVariables AleatoriasunidimensionalessmaticoAún no hay calificaciones
- Intro A ProbabilidadDocumento6 páginasIntro A ProbabilidadLautaro PatiñoAún no hay calificaciones
- Clase 3 Modelo de ProbabilidadDocumento27 páginasClase 3 Modelo de ProbabilidadNazareth Michelle AdamesAún no hay calificaciones
- Ficha ProbabilidadesDocumento5 páginasFicha Probabilidadeslobofrank2Aún no hay calificaciones
- Variables AleatoriasDocumento84 páginasVariables AleatoriasAmIn20122Aún no hay calificaciones
- PROBABILIDADESDocumento19 páginasPROBABILIDADESPatricia JimenezAún no hay calificaciones
- Taller probabilidad fundamentosDocumento8 páginasTaller probabilidad fundamentosDeiby Caicedo LeonAún no hay calificaciones
- Teoría Elemental de ProbabilidadesDocumento18 páginasTeoría Elemental de ProbabilidadesMartina Benitez sosaAún no hay calificaciones
- Variable aleatoria discreta y continuaDocumento13 páginasVariable aleatoria discreta y continuaJose EspinozaAún no hay calificaciones
- Modelos y análisis estocásticosDocumento34 páginasModelos y análisis estocásticosManuel David Vargas YepesAún no hay calificaciones
- Distribuciones de probabilidad discretas y continuasDocumento20 páginasDistribuciones de probabilidad discretas y continuasRAULAún no hay calificaciones
- Notas Estadistica I PrimeraParteDocumento42 páginasNotas Estadistica I PrimeraParteCinthia Sierra LgarsAún no hay calificaciones
- Semana 7 y 8 - Variables AleatoriasDocumento46 páginasSemana 7 y 8 - Variables AleatoriasAndrea FloresAún no hay calificaciones
- Contrato Piggy Back - Sweet and Coffe, StarbucksDocumento2 páginasContrato Piggy Back - Sweet and Coffe, StarbucksMishellAún no hay calificaciones
- Trabajo Practico SegmentacionDocumento10 páginasTrabajo Practico SegmentacionMishellAún no hay calificaciones
- Preguntas ContrataciónDocumento14 páginasPreguntas ContrataciónMishellAún no hay calificaciones
- RUBRICA - T III GENERAL - NRC.10816docxDocumento2 páginasRUBRICA - T III GENERAL - NRC.10816docxMishellAún no hay calificaciones
- Una Fotografía Del Curso! - Formularios de GoogleDocumento6 páginasUna Fotografía Del Curso! - Formularios de GoogleMishellAún no hay calificaciones
- Zara cadena suministrosDocumento8 páginasZara cadena suministrosMishellAún no hay calificaciones
- Universidad de las Fuerzas Armadas ESPE estadísticaDocumento13 páginasUniversidad de las Fuerzas Armadas ESPE estadísticaMishellAún no hay calificaciones
- Prueba 1er ParcialDocumento12 páginasPrueba 1er ParcialMishellAún no hay calificaciones
- Examen CCNA4 v4.0 Capítulo 1 - Tecnologías de La Información - Universidad Politécnica de TlaxcalaDocumento5 páginasExamen CCNA4 v4.0 Capítulo 1 - Tecnologías de La Información - Universidad Politécnica de TlaxcalarigsapanamaAún no hay calificaciones
- Historia Del VinoDocumento2 páginasHistoria Del VinoMary RoblesAún no hay calificaciones
- Ecuaciones Diferenciales Parciales: Clasificación y TiposDocumento2 páginasEcuaciones Diferenciales Parciales: Clasificación y TiposVero ValdezzAún no hay calificaciones
- Derecho Empresarial 1: Sociedades ComercialesDocumento2 páginasDerecho Empresarial 1: Sociedades ComercialesKarla RomeroAún no hay calificaciones
- Clasificación Magnética de Los MaterialesDocumento11 páginasClasificación Magnética de Los MaterialesAndy Vera75% (4)
- Cómo desarrollar el arte del análisis organizacionalDocumento16 páginasCómo desarrollar el arte del análisis organizacionalLucía TorresAún no hay calificaciones
- Veredas Corregimiento PanoramaDocumento1 páginaVeredas Corregimiento PanoramaMai KissAún no hay calificaciones
- Universidad Adolfo Ibáñez Ingeniería Comercial: Eduardo - Morales@uai - CLDocumento11 páginasUniversidad Adolfo Ibáñez Ingeniería Comercial: Eduardo - Morales@uai - CLEmiliaAún no hay calificaciones
- Act 3 Admión GeneralDocumento17 páginasAct 3 Admión GeneralDavid RodriguezAún no hay calificaciones
- Activity Guide and Evaluation Rubric - Unit 2 - Task 4 - Creating A City - En.esDocumento6 páginasActivity Guide and Evaluation Rubric - Unit 2 - Task 4 - Creating A City - En.esEl jojo's de tu vida100% (1)
- Trabajo Grupal S3Documento5 páginasTrabajo Grupal S3kevin159263Aún no hay calificaciones
- Ejercicios de Newton-Raphson (No Lineal)Documento10 páginasEjercicios de Newton-Raphson (No Lineal)Shugyn PisaniAún no hay calificaciones
- El MonopolioDocumento12 páginasEl MonopolioMilagritozHuaman100% (4)
- Cristóbal ColónDocumento6 páginasCristóbal ColónHenry RamosAún no hay calificaciones
- Ficha Convenio 169Documento1 páginaFicha Convenio 169saravasti2046Aún no hay calificaciones
- Ética cívica aplicada a las profesionesDocumento42 páginasÉtica cívica aplicada a las profesionesadriss01Aún no hay calificaciones
- Moderna NeurofisiologíaDocumento6 páginasModerna NeurofisiologíaRomario Chacon VargasAún no hay calificaciones
- Por qué la estadística es útil en PsicologíaDocumento2 páginasPor qué la estadística es útil en PsicologíaNicole100% (1)
- Campo Electrico Dentro de Un SolenoideDocumento7 páginasCampo Electrico Dentro de Un Solenoideuriel mendezAún no hay calificaciones
- Fica de Analisis Semana 21 CC. SS 5to 2022Documento3 páginasFica de Analisis Semana 21 CC. SS 5to 2022LinyoAún no hay calificaciones
- Sensibilización e Interacciones A La EscuelaDocumento6 páginasSensibilización e Interacciones A La EscuelaGiovanny Alexander Zamudio CastellanosAún no hay calificaciones
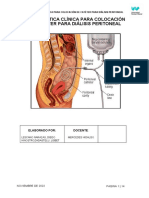
- Colocacion CATETER PERITONEALDocumento14 páginasColocacion CATETER PERITONEALLisbet Hinostroza GasteluAún no hay calificaciones
- INFORME VICTOR JAIME RAMOS MONZON JuevesDocumento23 páginasINFORME VICTOR JAIME RAMOS MONZON Juevesa2021201154Aún no hay calificaciones
- Colocación de Férula de YesoDocumento5 páginasColocación de Férula de YesoEdgarYadhirPerezHernandezAún no hay calificaciones
- GuiaInglesIII PDFDocumento85 páginasGuiaInglesIII PDFCarlos Bernal LopezAún no hay calificaciones
- Instrumentos de Evaluación. ODEC Lima.Documento29 páginasInstrumentos de Evaluación. ODEC Lima.Bruno DiazAún no hay calificaciones
- Evaluación de DesempeñoDocumento16 páginasEvaluación de DesempeñoDiana Alexandra LONDONO RIVILLASAún no hay calificaciones
- La fe y la riqueza: el camino de la confianza infantilDocumento12 páginasLa fe y la riqueza: el camino de la confianza infantilnelson TorresAún no hay calificaciones
- QuemadurasDocumento24 páginasQuemadurasLeo SalAún no hay calificaciones
- Bolilla 10 y 11Documento33 páginasBolilla 10 y 11Mariel SantorskiAún no hay calificaciones
- Estadística básica: Introducción a la estadística con RDe EverandEstadística básica: Introducción a la estadística con RCalificación: 5 de 5 estrellas5/5 (8)
- La guía definitiva en Matemáticas para el Ingreso al BachilleratoDe EverandLa guía definitiva en Matemáticas para el Ingreso al BachilleratoCalificación: 4.5 de 5 estrellas4.5/5 (9)
- La Biblia de las Matemáticas RápidasDe EverandLa Biblia de las Matemáticas RápidasCalificación: 4.5 de 5 estrellas4.5/5 (19)
- El cerebro matemático: Cómo nacen, viven y a veces mueren los números en nuestra menteDe EverandEl cerebro matemático: Cómo nacen, viven y a veces mueren los números en nuestra menteCalificación: 4 de 5 estrellas4/5 (5)
- Mentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraDe EverandMentalidades matemáticas: Cómo liberar el potencial de los estudiantes mediante las matemáticas creativas, mensajes inspiradores y una enseñanza innovadoraCalificación: 4.5 de 5 estrellas4.5/5 (5)
- El físico y el filósofo: Albert Einstein, Henri Bergson y el debate que cambió nuestra comprensión del tiempoDe EverandEl físico y el filósofo: Albert Einstein, Henri Bergson y el debate que cambió nuestra comprensión del tiempoAún no hay calificaciones
- Problemas de física general en un año olímpicoDe EverandProblemas de física general en un año olímpicoCalificación: 5 de 5 estrellas5/5 (1)
- Enseñar Matemática hoy: Miradas, sentidos y desafíosDe EverandEnseñar Matemática hoy: Miradas, sentidos y desafíosCalificación: 5 de 5 estrellas5/5 (1)
- Cuántica: Qué significa la teoría de la ciencia más extrañaDe EverandCuántica: Qué significa la teoría de la ciencia más extrañaCalificación: 1 de 5 estrellas1/5 (1)
- La Teoría de Conjuntos y los Fundamentos de las MatemáticasDe EverandLa Teoría de Conjuntos y los Fundamentos de las MatemáticasCalificación: 5 de 5 estrellas5/5 (1)
- Análisis estructural mediante el método de los elementos finitos. Introducción al comportamiento lineal elásticoDe EverandAnálisis estructural mediante el método de los elementos finitos. Introducción al comportamiento lineal elásticoCalificación: 4.5 de 5 estrellas4.5/5 (12)
- Visualización: Cambie su vida en cuatro semanas utilizando la ley de atracciónDe EverandVisualización: Cambie su vida en cuatro semanas utilizando la ley de atracciónCalificación: 5 de 5 estrellas5/5 (18)
- Álgebra lineal aplicada a las ciencias económicas 2edDe EverandÁlgebra lineal aplicada a las ciencias económicas 2edCalificación: 4 de 5 estrellas4/5 (1)
- Matemáticas financierasDe EverandMatemáticas financierasCalificación: 4 de 5 estrellas4/5 (7)
- Física cuántica para principiantes: Descubra los fundamentos de la mecánica cuántica y cómo afecta al mundo en que vivimos a través de todas sus teorías más famosasDe EverandFísica cuántica para principiantes: Descubra los fundamentos de la mecánica cuántica y cómo afecta al mundo en que vivimos a través de todas sus teorías más famosasCalificación: 5 de 5 estrellas5/5 (4)
- Didáctica de la matemática en la escuela primariaDe EverandDidáctica de la matemática en la escuela primariaCalificación: 2.5 de 5 estrellas2.5/5 (3)
- Física paso a paso: Más de 100 problemas resueltosDe EverandFísica paso a paso: Más de 100 problemas resueltosCalificación: 4 de 5 estrellas4/5 (12)
- Álgebra Tomo Ii: Hake MateDe EverandÁlgebra Tomo Ii: Hake MateCalificación: 5 de 5 estrellas5/5 (2)
- Análisis estadístico de datos multivariadosDe EverandAnálisis estadístico de datos multivariadosCalificación: 5 de 5 estrellas5/5 (1)