También podría gustarte
- Seminario Tarea 2Documento1 páginaSeminario Tarea 2Valery Sepúlveda PodestáAún no hay calificaciones
- Solución Taller (Investigacion de Operaciones)Documento10 páginasSolución Taller (Investigacion de Operaciones)DANNA VALENTINA ANGARITA QUINTEROAún no hay calificaciones
- Experiments SlidesDocumento64 páginasExperiments SlidesDiego Cardozo AgudeloAún no hay calificaciones
- Merchán - TapiaDocumento15 páginasMerchán - TapiaMaria JoseAún no hay calificaciones
- Evidencia Pam 4Documento38 páginasEvidencia Pam 4Melanie GodinaAún no hay calificaciones
- Monitoria 1 AutocorrelaciónDocumento22 páginasMonitoria 1 AutocorrelaciónTomas UrregoAún no hay calificaciones
- Eval1 2022Documento4 páginasEval1 2022Andrés EspinozaAún no hay calificaciones
- Calculos (Carga y Descarga)Documento8 páginasCalculos (Carga y Descarga)EVER CHINO APAZAAún no hay calificaciones
- Practica 2 - Datos - Calculos - Reporte 4Documento5 páginasPractica 2 - Datos - Calculos - Reporte 4Alondra GRAún no hay calificaciones
- Informe #9 - Laboratorio Sistemas de Control II - Rondinel Buleje IvanDocumento11 páginasInforme #9 - Laboratorio Sistemas de Control II - Rondinel Buleje IvanIvan Rondinel BulejeAún no hay calificaciones
- Segundo TrabajoDocumento14 páginasSegundo TrabajoLORENA JAZMIN PANDO ESPINOZAAún no hay calificaciones
- Variable Aleatoria DiscretaDocumento6 páginasVariable Aleatoria DiscretaAndre Edy Ramos PeñaAún no hay calificaciones
- Resolucion PR4Documento7 páginasResolucion PR4Marco Flores ZuñigaAún no hay calificaciones
- UntitledDocumento8 páginasUntitledBenjamín EspañaAún no hay calificaciones
- Deber Tnte Carlos Perugachi NRC 3347 Tercer Parcial FinDocumento15 páginasDeber Tnte Carlos Perugachi NRC 3347 Tercer Parcial FinChristiaan GodoyAún no hay calificaciones
- Variable Aleatoria DiscretaDocumento9 páginasVariable Aleatoria DiscretaVargas Berber OsvaldoAún no hay calificaciones
- Trabajo 2 MV ADocumento7 páginasTrabajo 2 MV AAngel Daniel Velazquez RodriguezAún no hay calificaciones
- Examen de Aplazados de Econometria II 2017-IDocumento2 páginasExamen de Aplazados de Econometria II 2017-IEingel Rap100% (1)
- D Exp Ii Pdir 03 Fact Bca A Cuant B Cuant 20 03 21 (Zootecnia)Documento30 páginasD Exp Ii Pdir 03 Fact Bca A Cuant B Cuant 20 03 21 (Zootecnia)Aldair Condolo GuerreroAún no hay calificaciones
- Solucionario Sustitutorio 21 1Documento9 páginasSolucionario Sustitutorio 21 1jhonajhonaAún no hay calificaciones
- Tutorial Spatstat 2Documento55 páginasTutorial Spatstat 2Gerardo MartinAún no hay calificaciones
- Clase 2Documento11 páginasClase 2Richard Villca TiconaAún no hay calificaciones
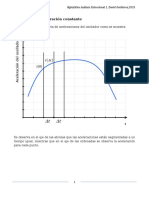
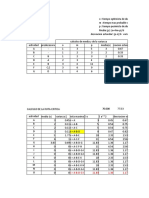
- Método Numérico Aceleración ConstanteDocumento6 páginasMétodo Numérico Aceleración ConstanteGerson KitAún no hay calificaciones
- Capitulo 7Documento15 páginasCapitulo 7violeta molleturo100% (1)
- Taller FuncionesDocumento6 páginasTaller FuncionesMolano CeciAún no hay calificaciones
- Tema 2.3 Alg Div Entera-Euclides (A8)Documento4 páginasTema 2.3 Alg Div Entera-Euclides (A8)Alexander Toro TorrezAún no hay calificaciones
- Pract. 9 - 10. y 11 Epid.. VetDocumento8 páginasPract. 9 - 10. y 11 Epid.. VetMANUEL JESÚS HUAMÁN RAMÍREZAún no hay calificaciones
- T1 19Documento28 páginasT1 19Leonardo Romero JimenezAún no hay calificaciones
- Output PDFDocumento16 páginasOutput PDFGerman Galdamez OvandoAún no hay calificaciones
- InecuacionesDocumento6 páginasInecuacionesWlliansitozaxz CxrxAún no hay calificaciones
- EJERCICIO3EXAMENIIDocumento25 páginasEJERCICIO3EXAMENIIRondelle MendozaAún no hay calificaciones
- Taller Ubica PolosDocumento15 páginasTaller Ubica PolosDIEGO ALEJANDRO CASTILLO RAYMEAún no hay calificaciones
- Proyecto Final MetodosDocumento26 páginasProyecto Final MetodosjuansAún no hay calificaciones
- Test - Laboratorio6 - Solución de Ecuaciones No LinealesDocumento8 páginasTest - Laboratorio6 - Solución de Ecuaciones No LinealesSebastian GamarraAún no hay calificaciones
- A#10 EOA Solución de ProblemasDocumento5 páginasA#10 EOA Solución de ProblemasValeria Ortega GnatovichAún no hay calificaciones
- Seleccion AtributosrDocumento29 páginasSeleccion AtributosrdavizonnAún no hay calificaciones
- Ejercicios Tarea 1Documento10 páginasEjercicios Tarea 1Alexis Yuri Chaves BurbanoAún no hay calificaciones
- Metodos Numericos Trabajo 01Documento7 páginasMetodos Numericos Trabajo 01Nathan JannaAún no hay calificaciones
- Estabilidad Transitoria en Sistemas Multimaquina Potencia IIDocumento14 páginasEstabilidad Transitoria en Sistemas Multimaquina Potencia IIJUAN ISRAEL GREGORIO HUERTAAún no hay calificaciones
- Ejercicios de Aplicación de Los Métodos de Soluciones de Ecuaciones No Lineales y LinealesDocumento55 páginasEjercicios de Aplicación de Los Métodos de Soluciones de Ecuaciones No Lineales y LinealesYuri Saul Sivincha QuispeAún no hay calificaciones
- Método de Cross - Portico Con DesplazamientoDocumento12 páginasMétodo de Cross - Portico Con Desplazamientoterry pariona de la cruzAún no hay calificaciones
- Algebra 2°sec (Iibim)Documento66 páginasAlgebra 2°sec (Iibim)eduardo02929Aún no hay calificaciones
- 4ejerciciosZN-LA LCDocumento16 páginas4ejerciciosZN-LA LCFaker LegendAún no hay calificaciones
- TP2 U2 VA ResultadosDocumento6 páginasTP2 U2 VA ResultadosMaria Milagros TOMERAAún no hay calificaciones
- Parcial 1 Econometría I v2 SOLUCIÓNDocumento4 páginasParcial 1 Econometría I v2 SOLUCIÓNWill Ríos100% (1)
- P Ar CialDocumento3 páginasP Ar CialalexAún no hay calificaciones
- Actividad#10 EstadisticaDocumento8 páginasActividad#10 EstadisticaLuis AyalaAún no hay calificaciones
- Practica de Datos Panel Con EviewsDocumento10 páginasPractica de Datos Panel Con EviewsLu MathAún no hay calificaciones
- Regresion Lineal Con R RStudio - Jorge Eduardo Briceño Uron CENS - Jorge - Briceno@cens - Com.coDocumento8 páginasRegresion Lineal Con R RStudio - Jorge Eduardo Briceño Uron CENS - Jorge - Briceno@cens - Com.coJorge Eduardo Briceño UrónAún no hay calificaciones
- Juan Carlos Gonzalez Sierra Tarea 1Documento16 páginasJuan Carlos Gonzalez Sierra Tarea 1Juan GonzalezAún no hay calificaciones
- Taller Gna Gva Montecarlo - T71aDocumento25 páginasTaller Gna Gva Montecarlo - T71aJorge V. PatiñoAún no hay calificaciones
- Actividad1 Montiel CerónDocumento4 páginasActividad1 Montiel CerónAngélica Mont Cer100% (1)
- Análisis Numérico Tarea # 6Documento8 páginasAnálisis Numérico Tarea # 6Wenddy Rivera AguirreAún no hay calificaciones
- Raices de Ecuaciones No LinealesDocumento9 páginasRaices de Ecuaciones No LinealesJosse Luys H. MamaniAún no hay calificaciones
- Manual GAUSS SEIDELDocumento3 páginasManual GAUSS SEIDELNicolásAún no hay calificaciones
- Ejercitando 2do Parcial 2020 Sis386Documento5 páginasEjercitando 2do Parcial 2020 Sis386Beimar Miguel CeronAún no hay calificaciones
- Variable Aleatoria DiscretaDocumento24 páginasVariable Aleatoria DiscretaYamilethAún no hay calificaciones
- Examenes AnalisisDocumento21 páginasExamenes AnalisiswildpereAún no hay calificaciones
- Ejercicios Resueltos Estadistica de MarcDocumento20 páginasEjercicios Resueltos Estadistica de MarcVergel IvanAún no hay calificaciones
- Métodos Matriciales para ingenieros con MATLABDe EverandMétodos Matriciales para ingenieros con MATLABCalificación: 5 de 5 estrellas5/5 (1)
- Curso de Programación en C18: Universidad Nacional de Salta Facultad de Ciencias Exactas TEU Daniel PazDocumento28 páginasCurso de Programación en C18: Universidad Nacional de Salta Facultad de Ciencias Exactas TEU Daniel Pazdaniel7766Aún no hay calificaciones
- Teledeteccion S I G y Cambio GlobalDocumento24 páginasTeledeteccion S I G y Cambio Globaldaniel7766Aún no hay calificaciones
- MPLABX C18 Consideraciones Generales IIDocumento6 páginasMPLABX C18 Consideraciones Generales IIdaniel7766Aún no hay calificaciones
- Unidad 2 Intro Programacion en AndroidDocumento55 páginasUnidad 2 Intro Programacion en Androiddaniel7766Aún no hay calificaciones
- Teoria 3 AnovaDocumento28 páginasTeoria 3 Anovadaniel7766Aún no hay calificaciones
- Mapas ElementosDocumento24 páginasMapas Elementosdaniel7766Aún no hay calificaciones
- Fundamentos Basicos para La TeledeteccionAmbientalDocumento50 páginasFundamentos Basicos para La TeledeteccionAmbientaldaniel7766Aún no hay calificaciones
- Clase 01 - Data AnalyticsDocumento10 páginasClase 01 - Data Analyticsdaniel7766100% (1)
- TP Fuentes 2019Documento2 páginasTP Fuentes 2019daniel7766Aún no hay calificaciones
- Taller Caso SuzukiDocumento3 páginasTaller Caso SuzukiDario Bernardo Montufar BlancoAún no hay calificaciones
- El Club de Los Corazones SolitariosDocumento9 páginasEl Club de Los Corazones SolitariosFlorencia80% (5)
- SIMETRIADocumento37 páginasSIMETRIAJuli ataramaAún no hay calificaciones
- Matris ParqueaderoDocumento18 páginasMatris ParqueaderoJhonatan Ferney MORENO MUNOZ100% (1)
- Quirofano de HemodinamiaDocumento3 páginasQuirofano de Hemodinamiaapi-446914421Aún no hay calificaciones
- Avanse Proyecto SanchezDocumento24 páginasAvanse Proyecto SanchezKevin Sanchez LoayzaAún no hay calificaciones
- Anexo 38 Especificaciones Tecnicas 28 Cortacorriente Tipo IDocumento4 páginasAnexo 38 Especificaciones Tecnicas 28 Cortacorriente Tipo IRojas Gómez AngelicaAún no hay calificaciones
- UIIX-Brochure Doctorado en Educacion e InnovacionDocumento11 páginasUIIX-Brochure Doctorado en Educacion e InnovacionLuz EcheverriaAún no hay calificaciones
- Define El Enfoque de Tu NegocioDocumento6 páginasDefine El Enfoque de Tu NegocioJavier BocanumenthAún no hay calificaciones
- PotenciadorDocumento4 páginasPotenciadorRayan UnidosAún no hay calificaciones
- Sermonario Culto Joven 2023Documento131 páginasSermonario Culto Joven 2023Luis AG Rivera82% (11)
- Matriz LegalDocumento4 páginasMatriz LegalAnllela Lorena BlancoAún no hay calificaciones
- Absolucion Denuncia IndecopiDocumento3 páginasAbsolucion Denuncia IndecopiCristhian CarreonAún no hay calificaciones
- Estados Financieros ProyectadosDocumento23 páginasEstados Financieros ProyectadosRaul Arenas AsteteAún no hay calificaciones
- HLM - ASM - Diri - Sem 02Documento2 páginasHLM - ASM - Diri - Sem 02Carlos Martín Medina TáberAún no hay calificaciones
- Planeamiento y Administración de Obra (P-2)Documento2 páginasPlaneamiento y Administración de Obra (P-2)norman arielAún no hay calificaciones
- Caracteristicas Generales de Los Protozoarios FlageladosDocumento4 páginasCaracteristicas Generales de Los Protozoarios Flageladosmaria zegarra100% (1)
- EJE 2 TP 5 Mary Richmond y Otros PrecursoresDocumento17 páginasEJE 2 TP 5 Mary Richmond y Otros PrecursoresflavioAún no hay calificaciones
- Investigacion Que Es La Cavitacion y Cuales Son Las Variables A Considerar para Seleccionar Una Bomba CentrifugaDocumento10 páginasInvestigacion Que Es La Cavitacion y Cuales Son Las Variables A Considerar para Seleccionar Una Bomba CentrifugaChristian DanielAún no hay calificaciones
- Area de Asistencia Tecnica DicriDocumento5 páginasArea de Asistencia Tecnica Dicrialdo pelicoAún no hay calificaciones
- Cuadernillo 4to 07Documento78 páginasCuadernillo 4to 07Anonymous jaDmtyU3Aún no hay calificaciones
- BATALLANDocumento24 páginasBATALLANMariel BufariniAún no hay calificaciones
- Transferencia de Calor en Estado No Estacionario en Alimentos IDocumento5 páginasTransferencia de Calor en Estado No Estacionario en Alimentos IJulio Mauricio Vidaurre-RuizAún no hay calificaciones
- Sesión 06 - Siaf IngresosDocumento6 páginasSesión 06 - Siaf IngresosJosue GarciaAún no hay calificaciones
- Catalogo Inversiones RHDocumento16 páginasCatalogo Inversiones RHalexander gutierrezAún no hay calificaciones
- Contrato de Venta Jeep LuisDocumento2 páginasContrato de Venta Jeep LuisWillysAún no hay calificaciones
- Protocolos de NegociacionDocumento12 páginasProtocolos de NegociacionFausto EstradaAún no hay calificaciones
- Trabajo ColaborativoDocumento9 páginasTrabajo ColaborativoAna María Garzón RamosAún no hay calificaciones
- DMTA 10072 01ES - Rev - C Vanta User PDFDocumento168 páginasDMTA 10072 01ES - Rev - C Vanta User PDFcristosferAún no hay calificaciones
- Teoria Del Final en La Partida de Ajedrez - Ganzo (1957) PDFDocumento94 páginasTeoria Del Final en La Partida de Ajedrez - Ganzo (1957) PDFanfichoelosAún no hay calificaciones