También podría gustarte
- ProtocolosDocumento5 páginasProtocolosDafne ItzelAún no hay calificaciones
- Aplicaciones de La Red InformaticaDocumento15 páginasAplicaciones de La Red InformaticaRomel SolanoAún no hay calificaciones
- Protocolo de Comunicacion Redes 2Documento4 páginasProtocolo de Comunicacion Redes 2Angel Gabriel Pimentel JimenezAún no hay calificaciones
- Practica 5 ProtocolosDocumento5 páginasPractica 5 ProtocolosBraulio ReyesAún no hay calificaciones
- Protocolos de Comunicación de Redes de DispositivosDocumento5 páginasProtocolos de Comunicación de Redes de Dispositivosraul juzgadoAún no hay calificaciones
- Practica 2 - SISTEMAS DE COMPUTO Y REDESDocumento12 páginasPractica 2 - SISTEMAS DE COMPUTO Y REDESPAOLA GISELLE HERNANDEZ PERAZAAún no hay calificaciones
- Protocolos de Comunicación de RedesDocumento3 páginasProtocolos de Comunicación de RedesLuis TempoAún no hay calificaciones
- Protocolos de ComunicacionDocumento18 páginasProtocolos de ComunicacionVictor Carmona SuarezAún no hay calificaciones
- Protocolo de ComunicacionDocumento4 páginasProtocolo de ComunicacionggenesisAún no hay calificaciones
- Modelo OsiDocumento16 páginasModelo OsiElso MarquezAún no hay calificaciones
- Historia, Redes y Protocolos Jorge SarmientoDocumento11 páginasHistoria, Redes y Protocolos Jorge SarmientoAxxel SarmientoAún no hay calificaciones
- Modelos de Referencia OSI TCP - IPDocumento11 páginasModelos de Referencia OSI TCP - IPLENNER FRANCISCO GONZALEZ RODRIGUEZAún no hay calificaciones
- Practica Jose Pablo RecinosDocumento38 páginasPractica Jose Pablo RecinosjoseAún no hay calificaciones
- JRB (20 Eist 1 079) 506391 Int Red Trab1 13 - 05 - 2021Documento15 páginasJRB (20 Eist 1 079) 506391 Int Red Trab1 13 - 05 - 2021Jesus RomeroAún no hay calificaciones
- Actividad 4 TeleprocesosDocumento18 páginasActividad 4 Teleprocesosomer primeraAún no hay calificaciones
- ELECTIVA VI TeleprocesioDocumento7 páginasELECTIVA VI Teleprocesiomoises eduardo ventura valderreyAún no hay calificaciones
- TeoríaDocumento12 páginasTeoríaGenexita Mite ApolinarioAún no hay calificaciones
- Modelo de OSI y Modelo TCP-IPDocumento8 páginasModelo de OSI y Modelo TCP-IPLuis Felipe Sanchez RodriguezAún no hay calificaciones
- Redes 1 Capitulo 2Documento25 páginasRedes 1 Capitulo 2Ivan AmadorAún no hay calificaciones
- Trabajo PracticoDocumento40 páginasTrabajo PracticoWilfredo Rafael FloresAún no hay calificaciones
- Investigación Sobre Los Modelos OSI y TCPDocumento17 páginasInvestigación Sobre Los Modelos OSI y TCPFdSlash ZaidAún no hay calificaciones
- Redes Industriales Investigacion Unidad 5 - EspañolDocumento17 páginasRedes Industriales Investigacion Unidad 5 - EspañolJORGE ANTONIO MAY CRUZAún no hay calificaciones
- Redes de ComputadorasDocumento26 páginasRedes de ComputadorasAllan MIch Pliego MojardinAún no hay calificaciones
- RT Tema0a Repaso Osi TCP Ip Lan 2018 FDocumento100 páginasRT Tema0a Repaso Osi TCP Ip Lan 2018 FMiguel Angel DocampoAún no hay calificaciones
- Tarea 6 - William Campo YepesDocumento19 páginasTarea 6 - William Campo YepesRafael Enrique Mendoza PerezAún no hay calificaciones
- Comunicacion Entre Computadoras y Perifericos de ControlDocumento6 páginasComunicacion Entre Computadoras y Perifericos de ControlExayana Lujan GarcíaAún no hay calificaciones
- 8.-B . - Actividad Modelo OsiDocumento5 páginas8.-B . - Actividad Modelo OsiRey MisterioAún no hay calificaciones
- 1.7 Protocolos - Alberto Corona AceitunoDocumento12 páginas1.7 Protocolos - Alberto Corona AceitunoAlberto Corona AceitunoAún no hay calificaciones
- Actividad 2 de Medios de TransmisiónDocumento7 páginasActividad 2 de Medios de Transmisiónjose cordoba100% (1)
- 2.1modelo de Comunicación OSIDocumento16 páginas2.1modelo de Comunicación OSIJOSE IGNACIO DIAZ RODRIGEZAún no hay calificaciones
- Actividad de Redes de DatosDocumento10 páginasActividad de Redes de DatosAngel Uriek Ramos Cruz100% (1)
- El CaciqueDocumento15 páginasEl CaciquemarAún no hay calificaciones
- Practica 3 - Protocolos de Comunicacion TCP, Modelo y OSIDocumento10 páginasPractica 3 - Protocolos de Comunicacion TCP, Modelo y OSIJose MereteAún no hay calificaciones
- Trabajo Sistemas OperativosDocumento4 páginasTrabajo Sistemas OperativosDeiby IzquielAún no hay calificaciones
- DANIELDocumento11 páginasDANIELwc59xzyf8qAún no hay calificaciones
- Practica Unidad 3Documento7 páginasPractica Unidad 3herald acosta amadorAún no hay calificaciones
- RedesDocumento57 páginasRedesjavier herreraAún no hay calificaciones
- Protocolos PDFDocumento28 páginasProtocolos PDFGEREMI JESUSAún no hay calificaciones
- REDES Y COMUNICACIONES Actividad 2Documento5 páginasREDES Y COMUNICACIONES Actividad 2oscar arangoAún no hay calificaciones
- Investigacion de RedDocumento11 páginasInvestigacion de RedJosé RamosAún no hay calificaciones
- Capas Del Modelo OsiDocumento6 páginasCapas Del Modelo OsiDavid HuertaAún no hay calificaciones
- Practica 7Documento5 páginasPractica 7JESUE ADAN FRAYRE GARCIAAún no hay calificaciones
- Protocolos de Comunicación y Seguridad en InternetDocumento12 páginasProtocolos de Comunicación y Seguridad en Internetsergio A SHAún no hay calificaciones
- Concepto de Arquitectura de RedesDocumento6 páginasConcepto de Arquitectura de RedesSoledad SotoAún no hay calificaciones
- Monografia Redes Lan y WanDocumento10 páginasMonografia Redes Lan y WanDavid BlancoAún no hay calificaciones
- Tecnologias Ethernet (Grupal)Documento15 páginasTecnologias Ethernet (Grupal)Jenny Snchz PimientoAún no hay calificaciones
- PT01 - 03042005 - Juan Maxia - S03 - Tarea 02Documento10 páginasPT01 - 03042005 - Juan Maxia - S03 - Tarea 02EMILIO VELASQUEZAún no hay calificaciones
- Me 2Documento29 páginasMe 2Marcelo UlloaAún no hay calificaciones
- Redes de ComputadorasDocumento41 páginasRedes de Computadorasjonathanescalante1885Aún no hay calificaciones
- Tema5 Modelo OSIDocumento63 páginasTema5 Modelo OSIJESUS IGNACIO BENITEZ NAVAAún no hay calificaciones
- Tema V Protocolos y CapasDocumento10 páginasTema V Protocolos y CapasAgustin Guerra ferreiraAún no hay calificaciones
- Modelo OSI y TCP:IPDocumento3 páginasModelo OSI y TCP:IPyerayerayera37Aún no hay calificaciones
- Curso de Preparación para El Examen de CCNA 200-120 PDFDocumento221 páginasCurso de Preparación para El Examen de CCNA 200-120 PDFAaron Perez NoriegaAún no hay calificaciones
- Programación Iii: Material Teórico 2° Año - 3° CuatrimestreDocumento192 páginasProgramación Iii: Material Teórico 2° Año - 3° CuatrimestreGalderAún no hay calificaciones
- TUP 3C PIII TEO U1 ProgramacionWebDocumento50 páginasTUP 3C PIII TEO U1 ProgramacionWebGalderAún no hay calificaciones
- Interfasez en VHDLDocumento12 páginasInterfasez en VHDLLuis SantiagoAún no hay calificaciones
- Tarea1 de Redes de ComputadorasDocumento9 páginasTarea1 de Redes de ComputadorasERICK ALEXANDER MURILLO VILLAFUERTEAún no hay calificaciones
- Cabrera - Alexander - Protocolos de ComunicaciónDocumento3 páginasCabrera - Alexander - Protocolos de ComunicaciónAlexander CabreraAún no hay calificaciones
- Tarea6 JohanPerezDocumento15 páginasTarea6 JohanPerezEvelin AndradeAún no hay calificaciones
- Selección, instalación, configuración y administración de los servidores de transferencia de archivos. IFCT0509De EverandSelección, instalación, configuración y administración de los servidores de transferencia de archivos. IFCT0509Aún no hay calificaciones
- Universidad Nacional Tecnológica de Lima Sur: Escuela Profesional de Ingeniería Mecánica Y EléctricaDocumento81 páginasUniversidad Nacional Tecnológica de Lima Sur: Escuela Profesional de Ingeniería Mecánica Y EléctricaJonathan Eleazar Serrano MendezAún no hay calificaciones
- CETGU061 Guía de Uso Del Simulador de Conexión de TransformadoresDocumento14 páginasCETGU061 Guía de Uso Del Simulador de Conexión de TransformadoresJonathan Eleazar Serrano MendezAún no hay calificaciones
- Manual de Operaciones CondensadorasDocumento17 páginasManual de Operaciones CondensadorasJonathan Eleazar Serrano MendezAún no hay calificaciones
- Presentacion CCO - Instructoria 04-Metodos de CosteoDocumento16 páginasPresentacion CCO - Instructoria 04-Metodos de CosteoJonathan Eleazar Serrano MendezAún no hay calificaciones
- Parcial 3 FisicaDocumento3 páginasParcial 3 FisicaJonathan Eleazar Serrano MendezAún no hay calificaciones
- Guia de Ejrcicios 1Documento30 páginasGuia de Ejrcicios 1Jonathan Eleazar Serrano MendezAún no hay calificaciones
- Teoria Adaminsitrativa II Trabajo FinalDocumento36 páginasTeoria Adaminsitrativa II Trabajo FinalJonathan Eleazar Serrano MendezAún no hay calificaciones
- TAREA HIGIENE Y SEGURIDAD OCTUBRE 2022 Jonathan Serrano 0108019Documento6 páginasTAREA HIGIENE Y SEGURIDAD OCTUBRE 2022 Jonathan Serrano 0108019Jonathan Eleazar Serrano MendezAún no hay calificaciones
- Práctica 4 UTLADocumento3 páginasPráctica 4 UTLAJonathan Eleazar Serrano MendezAún no hay calificaciones
- Practica 5 PowerpointsDocumento16 páginasPractica 5 PowerpointsJonathan Eleazar Serrano MendezAún no hay calificaciones
- TAREA TECNOLOGIA INDUSTRIAL II OCTUBRE 2022 Jonathan Serrano 0108019Documento5 páginasTAREA TECNOLOGIA INDUSTRIAL II OCTUBRE 2022 Jonathan Serrano 0108019Jonathan Eleazar Serrano MendezAún no hay calificaciones
- Organizacion: Acción y Efecto de Organizar, Es Decir Disponer Algo Ordenadamente para Alcanzar Un ObjetivoDocumento21 páginasOrganizacion: Acción y Efecto de Organizar, Es Decir Disponer Algo Ordenadamente para Alcanzar Un ObjetivoJonathan Eleazar Serrano MendezAún no hay calificaciones
- Guion de Clase 9 EticaDocumento1 páginaGuion de Clase 9 EticaJonathan Eleazar Serrano MendezAún no hay calificaciones
- Práctica 5 UTLADocumento3 páginasPráctica 5 UTLAJonathan Eleazar Serrano MendezAún no hay calificaciones
- Manual de Practicas Higiene y Seguridad IndustrialDocumento27 páginasManual de Practicas Higiene y Seguridad IndustrialJonathan Eleazar Serrano MendezAún no hay calificaciones
- Jorge Alexis Sevillano AyalaDocumento7 páginasJorge Alexis Sevillano AyalaJonathan Eleazar Serrano MendezAún no hay calificaciones
- Práctica 1 UTLADocumento2 páginasPráctica 1 UTLAJonathan Eleazar Serrano MendezAún no hay calificaciones
- Practica 7 ImpresionDocumento6 páginasPractica 7 ImpresionJonathan Eleazar Serrano MendezAún no hay calificaciones
- REQUISICION Discos de Estado Solido 07-11-22Documento4 páginasREQUISICION Discos de Estado Solido 07-11-22Jonathan Eleazar Serrano MendezAún no hay calificaciones
- 18.10.2022 Conferencia UtlaDocumento22 páginas18.10.2022 Conferencia UtlaJonathan Eleazar Serrano MendezAún no hay calificaciones
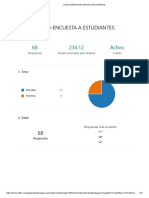
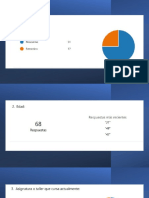
- Cuestionario-Encuesta A EstudiantesDocumento15 páginasCuestionario-Encuesta A EstudiantesJonathan Eleazar Serrano MendezAún no hay calificaciones
- Respuestas de FormularioDocumento55 páginasRespuestas de FormularioJonathan Eleazar Serrano MendezAún no hay calificaciones
- Programa Módulo V 2022Documento7 páginasPrograma Módulo V 2022Jonathan Eleazar Serrano MendezAún no hay calificaciones
- Oferta UtlaDocumento13 páginasOferta UtlaJonathan Eleazar Serrano MendezAún no hay calificaciones
- Parcial 03 UtlaDocumento1 páginaParcial 03 UtlaJonathan Eleazar Serrano MendezAún no hay calificaciones
- Serrano Mendez Jonathan Eleazar - Parcial 1 - Tecnologia Industrial 2Documento10 páginasSerrano Mendez Jonathan Eleazar - Parcial 1 - Tecnologia Industrial 2Jonathan Eleazar Serrano MendezAún no hay calificaciones
- OSHADocumento2 páginasOSHAJonathan Eleazar Serrano MendezAún no hay calificaciones
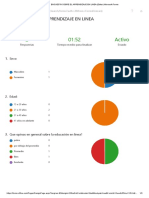
- ENCUESTA SOBRE EL APRENDIZAJE EN LINEA (Editar) Microsoft FormsDocumento3 páginasENCUESTA SOBRE EL APRENDIZAJE EN LINEA (Editar) Microsoft FormsJonathan Eleazar Serrano MendezAún no hay calificaciones
- Guía 2. Perfil Del ProfesionalDocumento2 páginasGuía 2. Perfil Del ProfesionalJonathan Eleazar Serrano MendezAún no hay calificaciones
- Actividad 4Documento10 páginasActividad 4Cronwell MairenaAún no hay calificaciones
- Microsoft AccessDocumento30 páginasMicrosoft AccessBrianAún no hay calificaciones
- Características y Funciones de Seguridad Del SGBD - 1Documento16 páginasCaracterísticas y Funciones de Seguridad Del SGBD - 1mary_acevedo573608Aún no hay calificaciones
- Microcurrículo Fundamentos y Diseño de BD-2020-2 PDFDocumento6 páginasMicrocurrículo Fundamentos y Diseño de BD-2020-2 PDFMarlon MarinAún no hay calificaciones
- Guía de Tareas Practico Final PDFDocumento94 páginasGuía de Tareas Practico Final PDFKarito FonsecaAún no hay calificaciones
- Marco Esquemático de La Auditoría de Sistemas ComputacionalesDocumento3 páginasMarco Esquemático de La Auditoría de Sistemas ComputacionalesYuli SanchezAún no hay calificaciones
- Informatica y Ciencias de La SaludDocumento13 páginasInformatica y Ciencias de La SaludNAKARI POTTERAún no hay calificaciones
- Estrategia Email MarketingDocumento28 páginasEstrategia Email MarketingferiverAún no hay calificaciones
- Ejemplo Documento VisionDocumento15 páginasEjemplo Documento VisionMasterkz100% (17)
- GFPI-F-019 - GUIA - DE - APRENDIZAJE - Utilizar Herramientas Informáticas de Acuerdo Con Las Necesidades de Manejo de InformaciónDocumento22 páginasGFPI-F-019 - GUIA - DE - APRENDIZAJE - Utilizar Herramientas Informáticas de Acuerdo Con Las Necesidades de Manejo de InformaciónOSWALDO CONTRERAS SIERRAAún no hay calificaciones
- Guia de Uso DataholzDocumento24 páginasGuia de Uso DataholzIsabel S.Aún no hay calificaciones
- Quick-EDD-DR ESDocumento2 páginasQuick-EDD-DR ESIsmael VaiAún no hay calificaciones
- Analizadores de Humedad ESDocumento20 páginasAnalizadores de Humedad ESBrandong Franco MejíaAún no hay calificaciones
- Guía para La Implementación de Un SGSDPDocumento67 páginasGuía para La Implementación de Un SGSDPYuve DgnAún no hay calificaciones
- Tecnologías para La Digitalización I4.0Documento16 páginasTecnologías para La Digitalización I4.0brayan alexis06Aún no hay calificaciones
- Actividad 4 Estudio de Caso Diseñar Una Base de Datos Relacional Nelson DiazDocumento19 páginasActividad 4 Estudio de Caso Diseñar Una Base de Datos Relacional Nelson Diaznelson henry diaaAún no hay calificaciones
- Unidad 1 - Ejercicios de NormalizacionDocumento8 páginasUnidad 1 - Ejercicios de NormalizacionAlejandra FernandezAún no hay calificaciones
- Motores de Bases de Datos Ventajas y Desventajas - BASES de DATOSDocumento5 páginasMotores de Bases de Datos Ventajas y Desventajas - BASES de DATOSAnonymous tupKMcWcAún no hay calificaciones
- Definición Del Modelo CDocumento4 páginasDefinición Del Modelo CAntonio FloresAún no hay calificaciones
- m5 - Bases de Datos 1 Parte (1Documento43 páginasm5 - Bases de Datos 1 Parte (1Edwin Vigoya VizcainoAún no hay calificaciones
- Diseño de Sistema WebDocumento8 páginasDiseño de Sistema WebYair RoblesAún no hay calificaciones
- FelicidadDocumento4 páginasFelicidadJuan Antonio Araujo CaudilloAún no hay calificaciones
- Administración de Bases de Datos NombreDocumento30 páginasAdministración de Bases de Datos NombreAnonymous LgQZ2C26bcAún no hay calificaciones
- Inducción A Las Bases de DatosDocumento36 páginasInducción A Las Bases de DatosCindy RojasAún no hay calificaciones
- Guia de Ofimatica No 1 A Desarrollar AprendicesDocumento7 páginasGuia de Ofimatica No 1 A Desarrollar AprendicesCheryl BrownAún no hay calificaciones
- Temario c1 Escala Administrativa de Informática-LDocumento2 páginasTemario c1 Escala Administrativa de Informática-Lunedmatematicas0% (1)
- SENADocumento16 páginasSENAAndrés MejiaAún no hay calificaciones
- Trabajo Parcial - TareaDocumento9 páginasTrabajo Parcial - Tareaervin lewis caceres mariñoAún no hay calificaciones
- Colegio Sueños Del Futuro (Entrega 1)Documento29 páginasColegio Sueños Del Futuro (Entrega 1)Sofia PedrazaAún no hay calificaciones
- Creacion de Empresas en Hosting y AccessoDocumento11 páginasCreacion de Empresas en Hosting y AccessoGessenia AlonsoAún no hay calificaciones