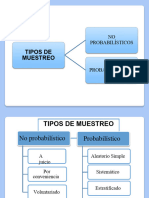
También podría gustarte
- Unidad 4 Muestreo (BLANCO REYES AZIEL DE JESUS)Documento19 páginasUnidad 4 Muestreo (BLANCO REYES AZIEL DE JESUS)AzielBlancoReyesAún no hay calificaciones
- Distribucion MuestralDocumento85 páginasDistribucion Muestralerick3797Aún no hay calificaciones
- Métodos TodoDocumento731 páginasMétodos TodoADRIANA MICHELLE CAMPOVERDE BALCAZARAún no hay calificaciones
- Prueba de HipotesisDocumento10 páginasPrueba de HipotesisrsemprunAún no hay calificaciones
- LMG-043-2016 UVCS Balanza de 150 KG Cód.31516Documento4 páginasLMG-043-2016 UVCS Balanza de 150 KG Cód.31516Alexander Alza Zamudio100% (1)
- Investigacion Tipos de MuestreoDocumento18 páginasInvestigacion Tipos de MuestreooscarAún no hay calificaciones
- Sesión 6Documento57 páginasSesión 6CIELO ARACELI RIOS GALANAún no hay calificaciones
- Unidad 2 - MuestreoDocumento9 páginasUnidad 2 - MuestreoANDREA CAROLINA BAYONA ALZATEAún no hay calificaciones
- Población y MuestraDocumento6 páginasPoblación y MuestraJohn VelaAún no hay calificaciones
- Trabajo Colaborativo I. Inferencia EstadísticaDocumento13 páginasTrabajo Colaborativo I. Inferencia EstadísticaVictor MartinezAún no hay calificaciones
- SEMANA 9 FusionadoDocumento109 páginasSEMANA 9 FusionadoKatherine Rodríguez0% (1)
- Unidad 5 Parte1Documento23 páginasUnidad 5 Parte1jorge palma50% (2)
- Estadistica Ii - FreddyDocumento23 páginasEstadistica Ii - FreddyFreddy Rodriguez QuinteroAún no hay calificaciones
- PyE - Unidad 4 - Clase X - LSDocumento25 páginasPyE - Unidad 4 - Clase X - LSMatias AcostaAún no hay calificaciones
- MUESTREODocumento50 páginasMUESTREOEfraín A. GarcíaAún no hay calificaciones
- Muest ReoDocumento24 páginasMuest Reoc3cowan3mu3oz3vargasAún no hay calificaciones
- VVGGHDVZVBZJDocumento25 páginasVVGGHDVZVBZJNeiser SalasAún no hay calificaciones
- Muestra y Técnicas de MuestreoDocumento44 páginasMuestra y Técnicas de MuestreoJHOANNA JAQUELINE HERNANDEZ DOMINGUEZAún no hay calificaciones
- 2 Estadstica Empresarial IIDocumento7 páginas2 Estadstica Empresarial IICecilia KostinchokAún no hay calificaciones
- Distribuciones MuestralesDocumento24 páginasDistribuciones MuestralesArianna MontesAún no hay calificaciones
- Población y MuestraDocumento30 páginasPoblación y MuestraguidobravoAún no hay calificaciones
- SEM10 - 1 - CLASE Muestreo y Tamaño de MuestraDocumento11 páginasSEM10 - 1 - CLASE Muestreo y Tamaño de MuestraAlonso Avila QuintanillaAún no hay calificaciones
- Poblacion y Muestra PDFDocumento24 páginasPoblacion y Muestra PDFmaco0% (1)
- Actividad 2 TerminadoDocumento7 páginasActividad 2 TerminadoSebastian TrujilloAún no hay calificaciones
- Actividad5 EstadisticaprobabilidadDocumento6 páginasActividad5 EstadisticaprobabilidadPeter GuerreroAún no hay calificaciones
- Trabajo de Estadistica IIDocumento6 páginasTrabajo de Estadistica IIBlanca Eugenia Zabala ChirinosAún no hay calificaciones
- Portafolio de EvidenciasDocumento37 páginasPortafolio de EvidenciasIsaac CalderonAún no hay calificaciones
- Asesoria 2 Tipos de MuestreoDocumento10 páginasAsesoria 2 Tipos de MuestreoCristopher RodríguezAún no hay calificaciones
- Distribución de Medias MuestralesDocumento36 páginasDistribución de Medias Muestralessorsire LabarcaAún no hay calificaciones
- CLASE MUESTREO 2aDocumento25 páginasCLASE MUESTREO 2aTifany BajañaAún no hay calificaciones
- Muestreoii 120806200254 Phpapp02Documento50 páginasMuestreoii 120806200254 Phpapp02Claudia Patricia BELTRAN CASTANEDAAún no hay calificaciones
- Muestreo EstadisticoDocumento37 páginasMuestreo EstadisticoAriel JimenezAún no hay calificaciones
- Teoria de MuestreoDocumento31 páginasTeoria de Muestreoicav28100% (1)
- Guia 2. Distribuciones Muestrales y Estimacion Estadistica PDFDocumento19 páginasGuia 2. Distribuciones Muestrales y Estimacion Estadistica PDFelizabethAún no hay calificaciones
- Muestreoii 120806200254 Phpapp02Documento49 páginasMuestreoii 120806200254 Phpapp02HUGO EDUARDO PEÑA LABANAún no hay calificaciones
- Muestreo Parte 2Documento36 páginasMuestreo Parte 2Diego Andrés Quezada DuránAún no hay calificaciones
- Guia Contenido 4 Estadistica InferencialDocumento13 páginasGuia Contenido 4 Estadistica InferencialMARCELA GUERRAAún no hay calificaciones
- Teoría Del MuestreoDocumento31 páginasTeoría Del MuestreoMaria Daniela AsaroAún no hay calificaciones
- Ejercicios Unidad IIDocumento15 páginasEjercicios Unidad IIAntoniaAún no hay calificaciones
- Eba U3 A2 ObvcDocumento6 páginasEba U3 A2 ObvcSilvia VelasquezAún no hay calificaciones
- Unidad5 Distribuciones de MuestreoDocumento8 páginasUnidad5 Distribuciones de MuestreoAngie CastroAún no hay calificaciones
- Muest ReoDocumento14 páginasMuest ReoJenther Eduardo Davila RinconAún no hay calificaciones
- UNIDAD 6. Muestreo y Distribuciones en El MuestreoDocumento36 páginasUNIDAD 6. Muestreo y Distribuciones en El MuestreoJulieta Rodriguez AznarezAún no hay calificaciones
- Actividad5 - Estadística y ProbabilidadDocumento7 páginasActividad5 - Estadística y Probabilidadedgar jafet murillo silvaAún no hay calificaciones
- 1.1 A 1.2 TIPOS DE MUESTREODocumento6 páginas1.1 A 1.2 TIPOS DE MUESTREOVERONICA ANGELES MARTINEZAún no hay calificaciones
- Clase 09Documento37 páginasClase 091420srodriguezcAún no hay calificaciones
- Muestreo EstadisticaDocumento32 páginasMuestreo EstadisticaJealitzaAún no hay calificaciones
- Capitulo 7.2Documento61 páginasCapitulo 7.2Daniel Alonso Ochoa GordónAún no hay calificaciones
- Probabilidad Actividad 01Documento15 páginasProbabilidad Actividad 01Luis JuarezAún no hay calificaciones
- Teoria de MuestreoDocumento4 páginasTeoria de Muestreoricardo veintimillaAún no hay calificaciones
- Selección de La MuestraDocumento13 páginasSelección de La Muestraomar castañedaAún no hay calificaciones
- Unidad 2. Muestreo Simple PDFDocumento29 páginasUnidad 2. Muestreo Simple PDFGUILLERMO ANDRES NAVARRO RODRIGUEZAún no hay calificaciones
- Muestra y MuestreoDocumento31 páginasMuestra y MuestreoNorman ArauzAún no hay calificaciones
- Unidad 1: Muestreo Y Distribuciones Muestrales.: Por: Gilma Sabina Lizama GaitánDocumento37 páginasUnidad 1: Muestreo Y Distribuciones Muestrales.: Por: Gilma Sabina Lizama GaitánAriana Alexandra Padilla VanegasAún no hay calificaciones
- Estadística Aplicada para La Toma de Decisiones Semana 2 ConferenciaDocumento20 páginasEstadística Aplicada para La Toma de Decisiones Semana 2 ConferenciaPedro JesúsAún no hay calificaciones
- 2 MuestreoDocumento13 páginas2 MuestreoHAIRTON WRIAN HERRERA TORRESAún no hay calificaciones
- Expo Cisneros MuestreoDocumento10 páginasExpo Cisneros MuestreoIsai Keoma Chirinos DiazAún no hay calificaciones
- P - Sem09 - Ses17 - Tipos de Muestreo - ACTDocumento21 páginasP - Sem09 - Ses17 - Tipos de Muestreo - ACTjessica mamaniAún no hay calificaciones
- Unidad IV Distribuciones MuestralesDocumento19 páginasUnidad IV Distribuciones MuestralesJoel TabareAún no hay calificaciones
- MuestreoDocumento23 páginasMuestreoRinocerontiito Campos RamosAún no hay calificaciones
- Elementos de estadística para ingeniería: Un curso básicoDe EverandElementos de estadística para ingeniería: Un curso básicoAún no hay calificaciones
- Consenso de muestra aleatoria: Estimación robusta en visión por computadoraDe EverandConsenso de muestra aleatoria: Estimación robusta en visión por computadoraAún no hay calificaciones
- Riesgos Quimicos Avance 2Documento18 páginasRiesgos Quimicos Avance 2Tatiana Melissa JOSA POTOSIAún no hay calificaciones
- Examenes Medicos FlujogramaDocumento14 páginasExamenes Medicos FlujogramaTatiana Melissa JOSA POTOSIAún no hay calificaciones
- Alternativas y Mecanismos para Resolver ConflictosDocumento1 páginaAlternativas y Mecanismos para Resolver ConflictosTatiana Melissa JOSA POTOSI100% (1)
- Enfermedad Laboral PosterDocumento2 páginasEnfermedad Laboral PosterTatiana Melissa JOSA POTOSIAún no hay calificaciones
- Actividad 5 NoramatividadDocumento13 páginasActividad 5 NoramatividadTatiana Melissa JOSA POTOSIAún no hay calificaciones
- Metodologia de La Investigacio en SaludDocumento9 páginasMetodologia de La Investigacio en SaludCESMO ESTELIAún no hay calificaciones
- CUEST. UNIDAD No. 1 EstadisticaDocumento11 páginasCUEST. UNIDAD No. 1 EstadisticaRosme RosarioAún no hay calificaciones
- Planificación 9 Semanas 9 NO EGB MatemáticaDocumento14 páginasPlanificación 9 Semanas 9 NO EGB Matemáticaveronica janneth centeno moyon100% (1)
- Enfoques Cualitativo y CuantitativoDocumento2 páginasEnfoques Cualitativo y Cuantitativoyeni yanet teran terrones100% (1)
- Foro 2 (El Marco Conceptual)Documento3 páginasForo 2 (El Marco Conceptual)BRYAN ESTUARDO CHAVEZ AGUILARAún no hay calificaciones
- CHI CUADRADO NuevoDocumento4 páginasCHI CUADRADO NuevoEdgar VásquezAún no hay calificaciones
- Informe Método Fenomenológico - HermenéuticoDocumento5 páginasInforme Método Fenomenológico - HermenéuticoFrancisco AlviarezAún no hay calificaciones
- Desarrollo Esquema Del Proyecto de Tesis Cuantitativa Maestria Uns 2016Documento27 páginasDesarrollo Esquema Del Proyecto de Tesis Cuantitativa Maestria Uns 2016Victor Janampa SantosAún no hay calificaciones
- Clase Psicologìa, Ciencia y EstadísticaDocumento21 páginasClase Psicologìa, Ciencia y EstadísticaCoraAún no hay calificaciones
- Hipotesis MuestrasDocumento40 páginasHipotesis MuestrasArnold Angulo RamosAún no hay calificaciones
- Infografia 9Documento1 páginaInfografia 9SAUL DAVID BARRERA CARVOAún no hay calificaciones
- Metodos de Investigación Bajo El Enfoque Cualitativo - La FenomenologiaDocumento32 páginasMetodos de Investigación Bajo El Enfoque Cualitativo - La FenomenologiaLudwin SosaAún no hay calificaciones
- Tema 8Documento28 páginasTema 8Educacio VisualAún no hay calificaciones
- Metodologia de Accion DidacticaDocumento7 páginasMetodologia de Accion Didacticaapi-532515711Aún no hay calificaciones
- Metodos Cuantitativos Metodos Cualitativos o Su CoDocumento16 páginasMetodos Cuantitativos Metodos Cualitativos o Su CoedinsomosqueraAún no hay calificaciones
- Recoleccion de DatosDocumento1 páginaRecoleccion de DatosDaniel Humberto Hospina Rios0% (1)
- Rios Córdova - Examen FinalDocumento9 páginasRios Córdova - Examen FinalDarkFredy MallmaAún no hay calificaciones
- Ejemplos - Regresión Lineal SimpleDocumento2 páginasEjemplos - Regresión Lineal SimpleIng. Francisco Torres EspriúAún no hay calificaciones
- 4 Qué Etapas Se Contemplan Durante Una Prueba de PenetraciónDocumento2 páginas4 Qué Etapas Se Contemplan Durante Una Prueba de PenetraciónDennis CisnerosAún no hay calificaciones
- Subcompetencia 2Documento7 páginasSubcompetencia 2Mauro Carmona AraizaAún no hay calificaciones
- Practica 7Documento7 páginasPractica 7OB ManuelAún no hay calificaciones
- Estructura de Informe de IndagaciónDocumento3 páginasEstructura de Informe de IndagaciónSneyder LloclleAún no hay calificaciones
- Examen Final - Semana 8 - Inv - Primer Bloque-Metodos de Investigacion en Ciencias Sociales - (Grupo b01)Documento12 páginasExamen Final - Semana 8 - Inv - Primer Bloque-Metodos de Investigacion en Ciencias Sociales - (Grupo b01)Johanna Bedoya ArbelaezAún no hay calificaciones
- Tarea No 10Documento3 páginasTarea No 10Marvin Said RojasAún no hay calificaciones
- Gallardo Razonamientos D I A ADocumento20 páginasGallardo Razonamientos D I A ArodrigogmendozasAún no hay calificaciones
- Verdad, Objetividad y Evolución. La Teoría Evolucionista Darwiniana Desde El Enfoque de La Epistemología de Karl PopperDocumento20 páginasVerdad, Objetividad y Evolución. La Teoría Evolucionista Darwiniana Desde El Enfoque de La Epistemología de Karl PopperLoïc MarticuestAún no hay calificaciones
- Trabajo N°5Documento20 páginasTrabajo N°5Froilan Aycachi PayeAún no hay calificaciones