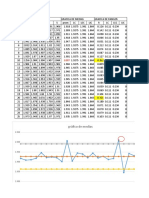
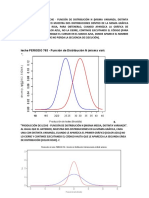
También podría gustarte
- Distribución HipergeometricaDocumento2 páginasDistribución HipergeometricaAnonymous DxVQ2H67% (3)
- SPS - Grupo Numero 8 - Tarea FinalDocumento29 páginasSPS - Grupo Numero 8 - Tarea FinalNicole MontesAún no hay calificaciones
- TAREA 8 EstadisticaDocumento10 páginasTAREA 8 EstadisticaJennifer CamachoAún no hay calificaciones
- Ejercicios Alumnos Sem9Documento16 páginasEjercicios Alumnos Sem9joseAún no hay calificaciones
- Daniela MONTOYA RIVAS - 358060 - 0 PDFDocumento8 páginasDaniela MONTOYA RIVAS - 358060 - 0 PDFDaniela100% (2)
- Experimento Aleatorio Lanzar Dos DadosDocumento7 páginasExperimento Aleatorio Lanzar Dos DadosCarlos LòpezAún no hay calificaciones
- Aporte 1Documento4 páginasAporte 1Karolina AlvaradoAún no hay calificaciones
- Fase 5 - Ejercicio FinalDocumento35 páginasFase 5 - Ejercicio FinalMaria Angelica Tordecilla JimenezAún no hay calificaciones
- Fase 5 Ejercicio Final.Documento42 páginasFase 5 Ejercicio Final.fredy serrato riveraAún no hay calificaciones
- Presentacion Fase 4 - 3Documento20 páginasPresentacion Fase 4 - 3Angelica Maria Gonzalez OrtegaAún no hay calificaciones
- Estadistica Bolo 1Documento11 páginasEstadistica Bolo 1milca vizaAún no hay calificaciones
- Trabajocolaborativo Fase3 Grupo93Documento17 páginasTrabajocolaborativo Fase3 Grupo93Angelica Maria Gonzalez OrtegaAún no hay calificaciones
- Punto 3Documento9 páginasPunto 3Gerson AdrianAún no hay calificaciones
- Deber 01 - Ejercicios de Calculo de FrecuenciasDocumento5 páginasDeber 01 - Ejercicios de Calculo de Frecuenciasivanovickn1989Aún no hay calificaciones
- Ejemplo 1 ConfiabilidadDocumento4 páginasEjemplo 1 Confiabilidadandreskarlos1Aún no hay calificaciones
- Fase5 Ejercicio Final Grupo - 16Documento32 páginasFase5 Ejercicio Final Grupo - 16Camila MaldonadoAún no hay calificaciones
- Distribución de FrecuenciasDocumento8 páginasDistribución de Frecuenciasjose fontalvoAún no hay calificaciones
- Fase 5 - 112 FinalDocumento16 páginasFase 5 - 112 FinalAngelica Maria Gonzalez OrtegaAún no hay calificaciones
- 126 - Fase 5 - Ejercicio FinalDocumento25 páginas126 - Fase 5 - Ejercicio FinalJohan Diaz100% (2)
- Practica Calificada 03 - ResueltaDocumento5 páginasPractica Calificada 03 - ResueltaDaniel CutipaAún no hay calificaciones
- Videoconferencia - Unidad 3 - Gestión de OperacionesDocumento33 páginasVideoconferencia - Unidad 3 - Gestión de Operacionesesteban LizondoAún no hay calificaciones
- Ejercicios de ConfiabilidadDocumento5 páginasEjercicios de Confiabilidadandrew leivaAún no hay calificaciones
- La Empresa GLORIA PDFDocumento4 páginasLa Empresa GLORIA PDFAnonymous p83ZoVPHeP0% (1)
- Fase 5 - Ejercicio Final.Documento33 páginasFase 5 - Ejercicio Final.Deiner Matute GutierrezAún no hay calificaciones
- Tercera Práctica FinalDocumento16 páginasTercera Práctica Finalandres zegarraAún no hay calificaciones
- Eeba U3 Ea JaqmDocumento5 páginasEeba U3 Ea JaqmJavier Quintero MonsivaisAún no hay calificaciones
- DANIEL BELEÑO - Fase4 - PRACTICODocumento25 páginasDANIEL BELEÑO - Fase4 - PRACTICOAngelica Maria Gonzalez OrtegaAún no hay calificaciones
- Eba U2 A2 JomeDocumento13 páginasEba U2 A2 Jomejuan mezaAún no hay calificaciones
- Generador de Va - ElaDocumento24 páginasGenerador de Va - Elagonzalez.gonzalez.andres.54Aún no hay calificaciones
- Juan Lorca Tarea Semana 1Documento6 páginasJuan Lorca Tarea Semana 1Juan LorcaAún no hay calificaciones
- Solucionando Problemas en La Fabricacion de Balines Aplicando Los Metodos de Control de CalidadDocumento65 páginasSolucionando Problemas en La Fabricacion de Balines Aplicando Los Metodos de Control de CalidadBladimir GregorioAún no hay calificaciones
- Ejercicios 10 Al 19Documento12 páginasEjercicios 10 Al 19STEPHANY garcia bonillaAún no hay calificaciones
- Ejercicio 3Documento4 páginasEjercicio 3Henry Kasuma SanAún no hay calificaciones
- Caso de Estudio Panadería de Pierre: Donde X Es La Cantidad de Números Aleatorios Que Se RequierenDocumento5 páginasCaso de Estudio Panadería de Pierre: Donde X Es La Cantidad de Números Aleatorios Que Se RequierenDaniela BarraganAún no hay calificaciones
- Rivera - Natalie - MM241 T2P1Documento4 páginasRivera - Natalie - MM241 T2P1Natalie RiveraAún no hay calificaciones
- Fase 3 Elaborar Documento de Aplicación de Conceptos de ProbabilidadDocumento16 páginasFase 3 Elaborar Documento de Aplicación de Conceptos de ProbabilidadYessica SierraAún no hay calificaciones
- Taller 7 - ResueltoDocumento30 páginasTaller 7 - ResueltoJosue DavidAún no hay calificaciones
- Estadistica 4Documento3 páginasEstadistica 4Consuelo FloresAún no hay calificaciones
- Act 1 U2 ProbDocumento3 páginasAct 1 U2 ProbAurelio Alejandro Moreno SolórzanoAún no hay calificaciones
- Tabla de Frecuencias Datos Agrupados y No AgrupadosDocumento9 páginasTabla de Frecuencias Datos Agrupados y No AgrupadosFrater MariusAún no hay calificaciones
- Clase 5Documento52 páginasClase 5AlvaroAún no hay calificaciones
- Cap Xi-Distribuciones TeoricasDocumento24 páginasCap Xi-Distribuciones TeoricasGerson Bernaola HuamanAún no hay calificaciones
- Practica .Medicion de TiemposDocumento6 páginasPractica .Medicion de TiemposLaura VenegasAún no hay calificaciones
- Plantilla Usada en Clases.Documento11 páginasPlantilla Usada en Clases.Iris FortínAún no hay calificaciones
- Ejercicio 2bDocumento8 páginasEjercicio 2bMarcoOrozcoBritoAún no hay calificaciones
- Taller Otras Distribuciones ContinuasDocumento18 páginasTaller Otras Distribuciones ContinuasEFRAIN VARGAS QUINTANAAún no hay calificaciones
- ZoteranoDocumento6 páginasZoteranopaolazoteranojulioAún no hay calificaciones
- S2 - Guia de Ejercicios - N°3 - Cálculo e Interpretación de ResultadosDocumento9 páginasS2 - Guia de Ejercicios - N°3 - Cálculo e Interpretación de ResultadosRoxana Lizana PachecoAún no hay calificaciones
- PCdirigida SolucionarioDocumento6 páginasPCdirigida SolucionarioKatherineFloresAún no hay calificaciones
- Ejemplos de Distribucion de Frecuencia - Julio PeñaDocumento7 páginasEjemplos de Distribucion de Frecuencia - Julio PeñaZoneNoCopyrightAún no hay calificaciones
- Evaluacion de Laboratorio Análisis IiDocumento16 páginasEvaluacion de Laboratorio Análisis IiCristhian HernandezAún no hay calificaciones
- Alfredo Cosio - Plan de Muestreo Por Variables PDFDocumento20 páginasAlfredo Cosio - Plan de Muestreo Por Variables PDFAlxdangelo Choque FloresAún no hay calificaciones
- Fase 4 EstadisticaDocumento20 páginasFase 4 EstadisticaGustavo MaciasAún no hay calificaciones
- Tablas de DatosDocumento26 páginasTablas de DatosRicardo Munoz AedoAún no hay calificaciones
- Tarea 5 MinitabDocumento2 páginasTarea 5 Minitabjoseph GARCIA MIRANDAAún no hay calificaciones
- Numero Valor X.X (X.X) 2 Desv Datos Validos: Datos Tomados en CampoDocumento7 páginasNumero Valor X.X (X.X) 2 Desv Datos Validos: Datos Tomados en Campov&n proyectosAún no hay calificaciones
- (Casi Terminado) MODELO DE INFORME I Ciclo 2022-IDocumento14 páginas(Casi Terminado) MODELO DE INFORME I Ciclo 2022-ICristhian MacedAún no hay calificaciones
- Tarea 1 Estadistica y Probabilidad - Rosalba Miossotti CruzDocumento17 páginasTarea 1 Estadistica y Probabilidad - Rosalba Miossotti CruzRosalba Miossotti HollingsAún no hay calificaciones
- Tarea 4Documento19 páginasTarea 4Cesar LuqueAún no hay calificaciones
- Parcial 1 - Prob y Estadistica Isem21Documento6 páginasParcial 1 - Prob y Estadistica Isem21K u r i s u t e r uAún no hay calificaciones
- Estadistica DescriptivaDocumento7 páginasEstadistica DescriptivaFermin Augusto Perdigón BemúdezAún no hay calificaciones
- Modelos Discretos ComunesDocumento39 páginasModelos Discretos ComunesCristian LadeusAún no hay calificaciones
- DISTRIBUCIONBINOMIAL Informe 2 1Documento4 páginasDISTRIBUCIONBINOMIAL Informe 2 1Luis Alfons Beltrán RíosAún no hay calificaciones
- Temas 9-10-11-Med de Resumen - Dats DiscretosDocumento17 páginasTemas 9-10-11-Med de Resumen - Dats Discretosdaniel alejandro amado calzadoAún no hay calificaciones
- Introducción A Los Métodos Estadísticos PDFDocumento3 páginasIntroducción A Los Métodos Estadísticos PDFBRAYAN ESTIBEN RAMIREZ GONZALEZAún no hay calificaciones
- 5.2 La Distribución BinomialDocumento5 páginas5.2 La Distribución BinomialCAMILA BELEN MAMANI CHOQUEHUAYTAAún no hay calificaciones
- Propiedad Reproductiva de La Distribución NormalDocumento3 páginasPropiedad Reproductiva de La Distribución NormalCristian Arias Chavez50% (2)
- Distribuciones Discretas de Probabilidad IngenieriaDocumento44 páginasDistribuciones Discretas de Probabilidad IngenieriaJuliiana LondoñoAún no hay calificaciones
- Examen Parcial - Semana 4 - Ra - Primer Bloque-Simulacion Gerencial - (Grupo1) MiltonDocumento13 páginasExamen Parcial - Semana 4 - Ra - Primer Bloque-Simulacion Gerencial - (Grupo1) Miltonkatherin100% (2)
- Temas 1 Teoria de Probabilidad 2 ModelosDocumento235 páginasTemas 1 Teoria de Probabilidad 2 ModelosSandraAún no hay calificaciones
- Tarea 3 89Documento21 páginasTarea 3 89Nelson JimenezAún no hay calificaciones
- Distribución de Probabilidad BinomialDocumento9 páginasDistribución de Probabilidad BinomialJosua RodriguezAún no hay calificaciones
- S07.s1 - MaterialDocumento19 páginasS07.s1 - MaterialRoger RodriguezAún no hay calificaciones
- Distribución de PoissonDocumento12 páginasDistribución de PoissonNathhy MoralesAún no hay calificaciones
- Actividad 4. Distribuciones Binomial J Poisson y NormalDocumento40 páginasActividad 4. Distribuciones Binomial J Poisson y Normalandrea fonsecaAún no hay calificaciones
- Guía 2 Distribución Binomial y PoissonDocumento6 páginasGuía 2 Distribución Binomial y PoissonAbdullGamesAún no hay calificaciones
- Clase 6 Distribuciones DiscretasDocumento6 páginasClase 6 Distribuciones DiscretasAlex Chuquisana MendozaAún no hay calificaciones
- Estadistica InferencialDocumento28 páginasEstadistica InferencialOscarCastroCordovaAún no hay calificaciones
- ASU S09 Probabilidades 2907Documento42 páginasASU S09 Probabilidades 2907yesica sobrado de la cruzAún no hay calificaciones
- 5.4 Distribuciones Binomial Negativa y GeométricaDocumento6 páginas5.4 Distribuciones Binomial Negativa y GeométricaEvelin Daniela Pinchao TulcanAún no hay calificaciones
- Estadística TP4 Variables Aleatorias DiscretasDocumento1 páginaEstadística TP4 Variables Aleatorias DiscretasGabriel Perez100% (1)
- Distribución de BernoulliDocumento4 páginasDistribución de BernoulliGissella velasquez100% (1)
- Hugo Gómez ChahuaDocumento25 páginasHugo Gómez ChahuaHUGO GOMEZ CHAHUAAún no hay calificaciones
- PREST S8.2 Investigación Bibliográfica Julio Delgado y Juan YeeDocumento13 páginasPREST S8.2 Investigación Bibliográfica Julio Delgado y Juan YeeFOX STOREAún no hay calificaciones
- Correccion de Variables 10%Documento6 páginasCorreccion de Variables 10%Renzo HuertaAún no hay calificaciones
- Distribucion Binomial y de PoissonDocumento16 páginasDistribucion Binomial y de PoissonMelany BanegasAún no hay calificaciones
- Cgeu Cgeu-114 TrabajofinalDocumento4 páginasCgeu Cgeu-114 TrabajofinalCARLOS M.fAún no hay calificaciones
- S09.s01 - MaterialDocumento33 páginasS09.s01 - MaterialLizet ayalaAún no hay calificaciones
- Resolución U3Documento10 páginasResolución U3Griselda PellegriniAún no hay calificaciones