También podría gustarte
- Desarrollo local y dinámicas territoriales: Homenaje a Joan NogueraDe EverandDesarrollo local y dinámicas territoriales: Homenaje a Joan NogueraAún no hay calificaciones
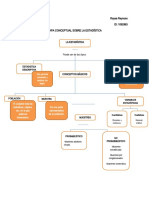
- Mapa Mental EstadisticaDocumento1 páginaMapa Mental EstadisticaMaria IsabelAún no hay calificaciones
- Mapa Mental EstadisticaDocumento1 páginaMapa Mental EstadisticaMaria IsabelAún no hay calificaciones
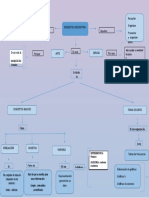
- Mapa ConceptualDocumento1 páginaMapa ConceptualLEONARDO IVAN ADARME RIVERAAún no hay calificaciones
- Mapa ConceptualDocumento1 páginaMapa ConceptualVictoria Vanesa Perdomo CabreraAún no hay calificaciones
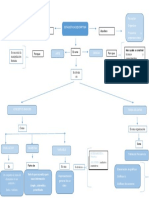
- Mapa Mental EstadisticaDocumento1 páginaMapa Mental EstadisticasinduryAún no hay calificaciones
- Mapa Conceptual - Estadística DescriptivaDocumento2 páginasMapa Conceptual - Estadística DescriptivaarkanatarottAún no hay calificaciones
- Raven MPC-2019Documento19 páginasRaven MPC-2019Iliana DìazAún no hay calificaciones
- Organizador Gráfico Estadistica Inferencial y DescriptivaDocumento1 páginaOrganizador Gráfico Estadistica Inferencial y DescriptivaBibAún no hay calificaciones
- PLANIFICACIÓN 2° Semestre 8°B, Matemática 2022Documento2 páginasPLANIFICACIÓN 2° Semestre 8°B, Matemática 2022Ramón Vinay SepúlvedaAún no hay calificaciones
- Spss Basico 2019 Octubre NoviembreDocumento62 páginasSpss Basico 2019 Octubre NoviembreDiegoOsorioAún no hay calificaciones
- Ejemplo de Mapa Mental para Marketing DigitalDocumento1 páginaEjemplo de Mapa Mental para Marketing DigitalLuz Elena100% (1)
- Cuadro de Operacionalización de Variables v2Documento8 páginasCuadro de Operacionalización de Variables v2Flavio MondragónAún no hay calificaciones
- Mapa Conceptual EstadísticaDocumento1 páginaMapa Conceptual EstadísticaRaysa Reynoso56% (9)
- Investigacion ConcluyenteDocumento1 páginaInvestigacion ConcluyenteLuisa Fernanda LEYTON RINCON 2Aún no hay calificaciones
- Estadistica IDocumento3 páginasEstadistica IRosa BaezAún no hay calificaciones
- Actividad 5 Mapa Conceptual Uso e Importancia de Los DatosDocumento1 páginaActividad 5 Mapa Conceptual Uso e Importancia de Los DatosPipe DazaAún no hay calificaciones
- Matriz de Consistencia y Operacionalización de VariablesDocumento3 páginasMatriz de Consistencia y Operacionalización de VariablesRosanti RodajasAún no hay calificaciones
- Mapa Conceptual EstadisticaDocumento1 páginaMapa Conceptual EstadisticaDiego VeraAún no hay calificaciones
- CATEDRA GRADO 7-2020-1 PeriodoDocumento1 páginaCATEDRA GRADO 7-2020-1 Periodomariazamudio244714Aún no hay calificaciones
- KLINGER MUESTREO ESTADISTICO-Métodos, Aplicaciones y Ejercicios PDFDocumento787 páginasKLINGER MUESTREO ESTADISTICO-Métodos, Aplicaciones y Ejercicios PDFEDGARDO RAMOSAún no hay calificaciones
- Aprendizajes de Los Textos Matematicas Prest - 2°Documento3 páginasAprendizajes de Los Textos Matematicas Prest - 2°franklinAún no hay calificaciones
- Eda #4Documento6 páginasEda #4Cassidy BertellAún no hay calificaciones
- S2 BioeDocumento7 páginasS2 BioeCata AlvarezAún no hay calificaciones
- 9° - Formato 02 - Matriz Curricular - EstadísticaDocumento9 páginas9° - Formato 02 - Matriz Curricular - EstadísticaRICARDO MANJARRES MANJARRESAún no hay calificaciones
- Microcurriculo Matematicas Ii 2023-2Documento8 páginasMicrocurriculo Matematicas Ii 2023-2Yussep Avila100% (1)
- Ideograma de La Lectura 2Documento1 páginaIdeograma de La Lectura 2Katherine ChicaizaAún no hay calificaciones
- Tema 1. Introducción A La Inferencia EstadísticaDocumento20 páginasTema 1. Introducción A La Inferencia EstadísticaEsteban Felipe Cano GarcíaAún no hay calificaciones
- Mapa Mental de EstadísticaDocumento1 páginaMapa Mental de EstadísticaElda Rodríguez CollinsAún no hay calificaciones
- Mallas Primaria MatDocumento10 páginasMallas Primaria MatEly LopezAún no hay calificaciones
- Asignatura Matemáticas 10Documento7 páginasAsignatura Matemáticas 10MariaAún no hay calificaciones
- EI1 A2T1 CruzMorfinLisseteDocumento5 páginasEI1 A2T1 CruzMorfinLisseteCây HuêAún no hay calificaciones
- Razonamiento Matematico MatrizDocumento2 páginasRazonamiento Matematico MatrizYulisa LesaAún no hay calificaciones
- Mapa Conceptual BioestadisticaDocumento2 páginasMapa Conceptual BioestadisticaMarco BustilloAún no hay calificaciones
- MATEMÁTICA 1ERO - Eva Diag.Documento25 páginasMATEMÁTICA 1ERO - Eva Diag.CaruMica BrujitaAún no hay calificaciones
- Variables de Investigación InfografíaDocumento1 páginaVariables de Investigación InfografíaKristabell Mena MedinaAún no hay calificaciones
- Unidad Didáctica N°9 - Matemática Noviembre y Diciembre EditadoDocumento3 páginasUnidad Didáctica N°9 - Matemática Noviembre y Diciembre Editadomercedes.paredesAún no hay calificaciones
- Cualitativa PautasDocumento5 páginasCualitativa PautasGelfo EscobarAún no hay calificaciones
- Mapa Conceptual - EstadísticaDocumento1 páginaMapa Conceptual - EstadísticaJessicaAún no hay calificaciones
- Estadistica DescriptivaDocumento17 páginasEstadistica DescriptivaNILDA RICALDEZAún no hay calificaciones
- Plan de Clase 1 Bloque 6Documento4 páginasPlan de Clase 1 Bloque 6Pablo ParraAún no hay calificaciones
- EstadísticaDocumento1 páginaEstadísticaAlejandro Mendoza MirandaAún no hay calificaciones
- BPMN 2.0Documento1 páginaBPMN 2.0Victor Yunan GarciaAún no hay calificaciones
- 1352 - Pensamiento Administrativo Publico Cetap La UnionDocumento5 páginas1352 - Pensamiento Administrativo Publico Cetap La UnionMalvis CamargoAún no hay calificaciones
- 05 Ejercicio 01Documento1 página05 Ejercicio 01Sol KookminAún no hay calificaciones
- Mapa Conceptual de La EstadisticaDocumento1 páginaMapa Conceptual de La EstadisticaHector David Henriquez LlanosAún no hay calificaciones
- Mapa Conceptual EstadisticaDocumento1 páginaMapa Conceptual EstadisticaDailyn Dayana RINCON HERNANDEZAún no hay calificaciones
- Mapa Mental EnfoquesDocumento2 páginasMapa Mental EnfoquesAlexy Nohemy Reyes CabreraAún no hay calificaciones
- Mapa Conceptual EstadisticaDocumento1 páginaMapa Conceptual EstadisticaCamila25% (4)
- 6 A y B de PrimariaDocumento18 páginas6 A y B de PrimariaManuel Asdrúbal Ahumada MendozaAún no hay calificaciones
- Matriz de OperacionalizacionDocumento3 páginasMatriz de OperacionalizacionDIEGO BRANCO MEJIA RAMIREZAún no hay calificaciones
- C1 - Distribución de Frecuencia PDFDocumento6 páginasC1 - Distribución de Frecuencia PDFsonia.ortiz.guerreroAún no hay calificaciones
- Actividad 1Documento12 páginasActividad 1Paula AndreaAún no hay calificaciones
- Matriz Matematicas 9Documento2 páginasMatriz Matematicas 9joas tapAún no hay calificaciones
- PsicologíaDocumento1 páginaPsicologíanunez.sarah.liaAún no hay calificaciones
- Adobe Scan 07 Jun. 2023Documento1 páginaAdobe Scan 07 Jun. 2023Carlita TorresAún no hay calificaciones
- Planeacion Didactica MIDocumento6 páginasPlaneacion Didactica MIJimmy QuirogaAún no hay calificaciones
- Tarea Taller Sistema de CoordenadasDocumento5 páginasTarea Taller Sistema de Coordenadaskatherine quirogaAún no hay calificaciones
- MATRIZ AMBIENTAL Identificacion y Evaluacion de Impactos Ambientales INGECOP LTDADocumento20 páginasMATRIZ AMBIENTAL Identificacion y Evaluacion de Impactos Ambientales INGECOP LTDAJose EmilioAún no hay calificaciones
- Estadística Descriptiva - Romero VilchisDocumento1 páginaEstadística Descriptiva - Romero VilchisSusyAún no hay calificaciones
- Anexo 7Documento7 páginasAnexo 7Karen PaolaAún no hay calificaciones
- Ajuste Por Inflacion Diferencia de CambioDocumento2 páginasAjuste Por Inflacion Diferencia de CambioKaren PaolaAún no hay calificaciones
- It Iva V3 Muestra PDFDocumento19 páginasIt Iva V3 Muestra PDFKaren PaolaAún no hay calificaciones
- Iue 570Documento3 páginasIue 570Carlos Saravia50% (10)
- boletadepago1000-HEREDEROS MLBDocumento2 páginasboletadepago1000-HEREDEROS MLBKaren PaolaAún no hay calificaciones
- boletadepago1000-HEREDEROS MLBDocumento2 páginasboletadepago1000-HEREDEROS MLBKaren PaolaAún no hay calificaciones
- Modelo Acta de ConstituciónDocumento4 páginasModelo Acta de ConstituciónDanielaVargasHurtadoAún no hay calificaciones
- Resis t2Documento2 páginasResis t2joe avilezAún no hay calificaciones
- S06.s1 SOLUCIÓN DE TAREA N°6Documento8 páginasS06.s1 SOLUCIÓN DE TAREA N°6Rodrigo Sonco CuadrosAún no hay calificaciones
- Origen y Aplicación Del No. PiDocumento6 páginasOrigen y Aplicación Del No. PiANONIMO MORALESAún no hay calificaciones
- Relaciones Escalares y Complejas en Circuitos Lineales ACDocumento16 páginasRelaciones Escalares y Complejas en Circuitos Lineales ACJesus Ferro VillaAún no hay calificaciones
- Metodo de TriangulacionDocumento5 páginasMetodo de Triangulacionpriamo123100% (5)
- MA262 Sesión 7.1 OptimizaciónDocumento18 páginasMA262 Sesión 7.1 Optimizaciónricardomaguina29Aún no hay calificaciones
- Problemas de Criterios de Divisibilidad para Segundo Grado de SecundariaDocumento2 páginasProblemas de Criterios de Divisibilidad para Segundo Grado de SecundariaTito VillafaneAún no hay calificaciones
- Areas CircularesDocumento2 páginasAreas CircularesRonny Condori DiazAún no hay calificaciones
- S3GE34BDocumento10 páginasS3GE34BJorge Luis Chumberiza ManzoAún no hay calificaciones
- Formulas de IntegralesDocumento2 páginasFormulas de IntegralesWordline100% (4)
- Pauta Ayudantia 04.1Documento2 páginasPauta Ayudantia 04.1NiightWiishAún no hay calificaciones
- Silabo Algebra Lineal AbetDocumento5 páginasSilabo Algebra Lineal AbetMiguel PatersonAún no hay calificaciones
- Cultura AndinaDocumento11 páginasCultura AndinadavidAún no hay calificaciones
- Caso Practico Unidad 3 Estadistica 1Documento5 páginasCaso Practico Unidad 3 Estadistica 1Adriana DiazAún no hay calificaciones
- Energia y PotenciaDocumento3 páginasEnergia y PotenciaJuan sebastian Chacón VegaAún no hay calificaciones
- Problemario Analisis Primer Parcial PDFDocumento6 páginasProblemario Analisis Primer Parcial PDFIrma SernaAún no hay calificaciones
- Guia 1 de La Nocturna Ciclo 4. NOVENODocumento9 páginasGuia 1 de La Nocturna Ciclo 4. NOVENOSharryth DiazAún no hay calificaciones
- Diseño y Simulación Del Comportamiento de Un Robot Scara de 2 Grados de LibertadDocumento3 páginasDiseño y Simulación Del Comportamiento de Un Robot Scara de 2 Grados de LibertadDaniel_19938Aún no hay calificaciones
- Relatividad en Intervalos de TiempoDocumento6 páginasRelatividad en Intervalos de TiempoLiza Montalvo Barrera67% (3)
- Distribucion BinomialDocumento19 páginasDistribucion BinomialGabriela López Cáceres0% (1)
- Funciones Vectoriales - Pag 26y27Documento2 páginasFunciones Vectoriales - Pag 26y27Jorge Morales c100% (1)
- Procesos SecuencialesDocumento2 páginasProcesos Secuencialeshugo serranoAún no hay calificaciones
- Trigo No Me TriaDocumento3 páginasTrigo No Me TriaDaly RojasAún no hay calificaciones
- SefirotDocumento16 páginasSefirotJohn BenaíahAún no hay calificaciones
- Aplicaciones de La Integral DefinidaDocumento71 páginasAplicaciones de La Integral DefinidaAlexander MoralesAún no hay calificaciones
- 14 Funciones Trigonometricas ViernesDocumento1 página14 Funciones Trigonometricas ViernesWilber Ramos CartAún no hay calificaciones
- PotenciasDocumento11 páginasPotenciasmichelledelvalleAún no hay calificaciones
- Sucesión GeométricaDocumento5 páginasSucesión GeométricaLuis ChuquipomaAún no hay calificaciones
- La Trama de Análisis Cultural, Modo de Interpretar La Cultura Popular y Herramienta de SistematizaciónDocumento12 páginasLa Trama de Análisis Cultural, Modo de Interpretar La Cultura Popular y Herramienta de SistematizaciónAfter AleAún no hay calificaciones
- Taller 2 Cinematica de Cuerpos RigidosDocumento5 páginasTaller 2 Cinematica de Cuerpos RigidosSara GomezAún no hay calificaciones