También podría gustarte
- Aprende a Programar en MATLABDe EverandAprende a Programar en MATLABCalificación: 3.5 de 5 estrellas3.5/5 (11)
- 4 Guía ColeccionesDocumento21 páginas4 Guía Coleccionesluis lopAún no hay calificaciones
- Estructuras de Datos en Java - CollectionsDocumento22 páginasEstructuras de Datos en Java - CollectionsJorge Arvayo100% (1)
- 01 JCFDocumento21 páginas01 JCFBorjaAún no hay calificaciones
- FlujogramasDocumento5 páginasFlujogramasEdgar Humberto Angel Millan100% (2)
- 7 - Guía Colecciones 2020Documento12 páginas7 - Guía Colecciones 2020Ute Procon Laugero100% (1)
- Colecciones en JavaDocumento21 páginasColecciones en JavaStevenTM ReyesAún no hay calificaciones
- Laboratorio Framework CollectionsDocumento5 páginasLaboratorio Framework CollectionsF. A.RAún no hay calificaciones
- Comité Reactivo Vigilancia ESE SoachaDocumento6 páginasComité Reactivo Vigilancia ESE SoachaEdgar Humberto Angel MillanAún no hay calificaciones
- Trabajo de ProgramaciónDocumento15 páginasTrabajo de ProgramaciónJosneilys RodriguezAún no hay calificaciones
- Colecciones en JavaDocumento3 páginasColecciones en JavaDavid MallquiAún no hay calificaciones
- POO - Lenguaje 2Documento15 páginasPOO - Lenguaje 2Jared SalgadoAún no hay calificaciones
- 1113-Colecciones 1Documento6 páginas1113-Colecciones 1Diego BecerraAún no hay calificaciones
- Unidad 14Documento18 páginasUnidad 14Antonio BravoAún no hay calificaciones
- Java Collections API IntroDocumento22 páginasJava Collections API IntroCarlos PinargoteAún no hay calificaciones
- Colecciones JavaDocumento3 páginasColecciones JavaCHIKY16Aún no hay calificaciones
- Contenedores de Objetos Collection, Map y ArrayDocumento43 páginasContenedores de Objetos Collection, Map y ArrayJosué López Acosta100% (2)
- Colecciones 2Documento22 páginasColecciones 2Luis FigueroaAún no hay calificaciones
- Tema15 ColeccionesDocumento38 páginasTema15 ColeccionesCARLOS YAÑEZAún no hay calificaciones
- Java Collection Framework.Documento29 páginasJava Collection Framework.CrashポOverrideAún no hay calificaciones
- INVESTIGACION DE METODOS PARA TABLA HASHDocumento5 páginasINVESTIGACION DE METODOS PARA TABLA HASHjaviant18Aún no hay calificaciones
- Tema 4 - Funciones Estandarizadas - Parte 1Documento6 páginasTema 4 - Funciones Estandarizadas - Parte 1Jackie Vargas UribeAún no hay calificaciones
- Coleccion Es JavaDocumento13 páginasColeccion Es JavaIMValleAún no hay calificaciones
- Uso de ColeccionesDocumento3 páginasUso de ColeccionesCindy DiazAún no hay calificaciones
- 7 - Guía ColeccionesDocumento22 páginas7 - Guía ColeccionesPepe ArgentoAún no hay calificaciones
- Colecciones en JavaDocumento4 páginasColecciones en JavaAdriana SaavedraAún no hay calificaciones
- Colecciones en Java PooDocumento12 páginasColecciones en Java PooElmer CeladitaAún no hay calificaciones
- Estructura de DatosDocumento14 páginasEstructura de DatosJennifer VillamilAún no hay calificaciones
- Estructura de DatosDocumento14 páginasEstructura de DatosJennifer VillamilAún no hay calificaciones
- Java Collections List Vs Set (I)Documento6 páginasJava Collections List Vs Set (I)francisco jimenezAún no hay calificaciones
- Java Map, Generics y estructuras de datosDocumento5 páginasJava Map, Generics y estructuras de datosDiego Ospina RojasAún no hay calificaciones
- API Collection en JavaDocumento15 páginasAPI Collection en JavaMarianaAún no hay calificaciones
- Parcial - Estructura de DatosDocumento11 páginasParcial - Estructura de DatosJiliar Silgado CardonaAún no hay calificaciones
- Java 16Documento35 páginasJava 16Rocio SorianoAún no hay calificaciones
- Guia5 2022 Parte2Documento23 páginasGuia5 2022 Parte2Andres GaldeanoAún no hay calificaciones
- 13 Colecciones en JavaDocumento12 páginas13 Colecciones en JavadoblebirdieAún no hay calificaciones
- Módulo 4 - Actividad Evaluativa - DESARROLLADODocumento3 páginasMódulo 4 - Actividad Evaluativa - DESARROLLADOGuille Pardo GutierrezAún no hay calificaciones
- Guia Colecciones 1 1Documento25 páginasGuia Colecciones 1 1Codigo libreAún no hay calificaciones
- Colecciones Java más allá de ArrayListDocumento4 páginasColecciones Java más allá de ArrayListJaime SantanaAún no hay calificaciones
- vuyxp3F-ytitHsA3 - r5s0GDU1hQmiwXbn-Lectura 3. La Clase ArrayListDocumento7 páginasvuyxp3F-ytitHsA3 - r5s0GDU1hQmiwXbn-Lectura 3. La Clase ArrayListDaniel CorreaAún no hay calificaciones
- Diferencias Entre Array ListDocumento2 páginasDiferencias Entre Array ListMartha Angelica Calderon OrtizAún no hay calificaciones
- Java Avanzado Clase 7Documento19 páginasJava Avanzado Clase 7lindodiaxd10Aún no hay calificaciones
- THP-Colecciones de DatosDocumento12 páginasTHP-Colecciones de DatossebaconteAún no hay calificaciones
- 3colecciones TeoriaDocumento11 páginas3colecciones TeoriaEdwin OsorioAún no hay calificaciones
- Sesion02 ApuntesDocumento18 páginasSesion02 ApuntesyayitoAún no hay calificaciones
- Módulo 4 - Actividad EvaluativaDocumento8 páginasMódulo 4 - Actividad EvaluativaJuan BenedictoAún no hay calificaciones
- Colecciones Java Arrays ListasDocumento9 páginasColecciones Java Arrays ListasJoseCarlosAún no hay calificaciones
- Algoritmos HashDocumento13 páginasAlgoritmos HashDuvan BotelloAún no hay calificaciones
- La Clase Scanner de JavaDocumento6 páginasLa Clase Scanner de JavaCarlos ConcepcionAún no hay calificaciones
- Estructuras de Datos en JavaDocumento4 páginasEstructuras de Datos en Javacheo68Aún no hay calificaciones
- TPROG1-U1-Colecciones de DatosDocumento8 páginasTPROG1-U1-Colecciones de DatosEMY CUPAún no hay calificaciones
- Algoritmos ME - 3Documento19 páginasAlgoritmos ME - 3Alejandro Ruben ToledanoAún no hay calificaciones
- Evaluacion EmilyDocumento7 páginasEvaluacion EmilyJorge LuisAún no hay calificaciones
- Colecciones, clases abstractas e interfaces en JavaDocumento43 páginasColecciones, clases abstractas e interfaces en JavaGinna BurbanoAún no hay calificaciones
- Colecciones en JavaDocumento5 páginasColecciones en JavaDaniel SuhulAún no hay calificaciones
- Clases Java Stack Queue ArrayList VectorDocumento7 páginasClases Java Stack Queue ArrayList VectorAlondra NoguèzAún no hay calificaciones
- Tarea Programacion ArreglosDocumento2 páginasTarea Programacion ArreglosDavidAún no hay calificaciones
- Java09 PDFDocumento29 páginasJava09 PDFJose Manuel Rayo OrtiguelaAún no hay calificaciones
- Unidad 1 PRN115Documento74 páginasUnidad 1 PRN115Irene DelgadoAún no hay calificaciones
- Todo El Proceso para Legalizar La Esperiencia en PDRGDocumento27 páginasTodo El Proceso para Legalizar La Esperiencia en PDRGdescarga todoAún no hay calificaciones
- 2.1.1 Colecciones JavaDocumento32 páginas2.1.1 Colecciones JavaCAMILA . REBOLLEDO MATAMALAAún no hay calificaciones
- Foro de discusión sobre colecciones en JavaDocumento4 páginasForo de discusión sobre colecciones en JavamauropelucheAún no hay calificaciones
- Creación de Base de Datos Proyecto UniminutoDocumento1 páginaCreación de Base de Datos Proyecto UniminutoEdgar Humberto Angel MillanAún no hay calificaciones
- Creacion de Una WikiDocumento22 páginasCreacion de Una WikiEdgar Humberto Angel MillanAún no hay calificaciones
- Creacion de Una WikiDocumento22 páginasCreacion de Una WikiEdgar Humberto Angel MillanAún no hay calificaciones
- Cronograma de actividadesTIC EN SALUD PRIMERA INFANCIA Edgar Angel FinalDocumento3 páginasCronograma de actividadesTIC EN SALUD PRIMERA INFANCIA Edgar Angel FinalEdgar Humberto Angel MillanAún no hay calificaciones
- Taller Uniminuto InformaticaDocumento12 páginasTaller Uniminuto InformaticaEdgar Humberto Angel MillanAún no hay calificaciones
- Cronograma de Actividades 2020-2 Programacion 1 Edgar Angel FinalDocumento7 páginasCronograma de Actividades 2020-2 Programacion 1 Edgar Angel FinalEdgar Humberto Angel MillanAún no hay calificaciones
- Creacion de Una WikiDocumento22 páginasCreacion de Una WikiEdgar Humberto Angel MillanAún no hay calificaciones
- Taller Sociales 4 PeriodoDocumento1 páginaTaller Sociales 4 PeriodoEdgar Humberto Angel MillanAún no hay calificaciones
- Crear Un Blog UniminutoDocumento50 páginasCrear Un Blog UniminutoEdgar Humberto Angel MillanAún no hay calificaciones
- Encuesta de Satisfacción ArticulaciónDocumento2 páginasEncuesta de Satisfacción ArticulaciónEdgar Humberto Angel MillanAún no hay calificaciones
- Cronograma de Actividades LENGUAJES DE PROGRAMACION PARA APLICACIONES DE NUBE Edgar Angel FinalDocumento3 páginasCronograma de Actividades LENGUAJES DE PROGRAMACION PARA APLICACIONES DE NUBE Edgar Angel FinalEdgar Humberto Angel MillanAún no hay calificaciones
- Cronograma de Actividades LENGUAJES DE PROGRAMACION PARA APLICACIONES MOVILES Edgar Angel FinalDocumento3 páginasCronograma de Actividades LENGUAJES DE PROGRAMACION PARA APLICACIONES MOVILES Edgar Angel FinalEdgar Humberto Angel MillanAún no hay calificaciones
- Toma de Muestras - DaissyDocumento40 páginasToma de Muestras - DaissyEdgar Humberto Angel MillanAún no hay calificaciones
- Desarrollo - DISEÑO DE ALGORTIMOS I Actividad de Aprendizaje 2 2Documento8 páginasDesarrollo - DISEÑO DE ALGORTIMOS I Actividad de Aprendizaje 2 2Edgar Humberto Angel MillanAún no hay calificaciones
- Instructivo Equipo Phoenix APDocumento5 páginasInstructivo Equipo Phoenix APEdgar Humberto Angel MillanAún no hay calificaciones
- Acta Capacitacion VenopuncionDocumento7 páginasActa Capacitacion VenopuncionEdgar Humberto Angel MillanAún no hay calificaciones
- Nucleo 2Documento5 páginasNucleo 2Edgar Humberto Angel MillanAún no hay calificaciones
- Lectura 2. Selección de Contenidos EducativosDocumento8 páginasLectura 2. Selección de Contenidos EducativosHugo MoralesAún no hay calificaciones
- Lectura 4. Sistema de Gestión de Aprendizaje MoodleDocumento9 páginasLectura 4. Sistema de Gestión de Aprendizaje MoodleHugo MoralesAún no hay calificaciones
- 0913 Profundización - Parcial 3 Supletorio - Ventas - SoluciónDocumento12 páginas0913 Profundización - Parcial 3 Supletorio - Ventas - SoluciónEdgar Humberto Angel MillanAún no hay calificaciones
- Lectura 5. Recursos y Actividades de MoodleDocumento8 páginasLectura 5. Recursos y Actividades de MoodleHugo MoralesAún no hay calificaciones
- Lectura 1. Entorno Virtual de Aprendizaje PDFDocumento9 páginasLectura 1. Entorno Virtual de Aprendizaje PDFEdgar Humberto Angel MillanAún no hay calificaciones
- 0913 Profundización - Parcial 3 - Ventas - SoluciónDocumento14 páginas0913 Profundización - Parcial 3 - Ventas - SoluciónEdgar Humberto Angel MillanAún no hay calificaciones
- Lectura 3. Seguimiento A Las Estrategias EvaluativasDocumento4 páginasLectura 3. Seguimiento A Las Estrategias EvaluativasHugo MoralesAún no hay calificaciones
- 0913 Profundización - Parcial 3 Supletorio - VentasDocumento9 páginas0913 Profundización - Parcial 3 Supletorio - VentasEdgar Humberto Angel MillanAún no hay calificaciones
- 0913 Profundización - Parcial 3 Supletorio - VentasDocumento9 páginas0913 Profundización - Parcial 3 Supletorio - VentasEdgar Humberto Angel MillanAún no hay calificaciones
- Parcial 1 PDFDocumento126 páginasParcial 1 PDFSabasto PorcoAún no hay calificaciones
- JVM-Entorno JavaDocumento25 páginasJVM-Entorno JavaEdison SànchezAún no hay calificaciones
- Buenas Practicas JavaDocumento16 páginasBuenas Practicas JavatitobesaleelAún no hay calificaciones
- Llamar Desde Una Clase Java A Otra ClaseDocumento14 páginasLlamar Desde Una Clase Java A Otra ClaseFranco Gonzales100% (1)
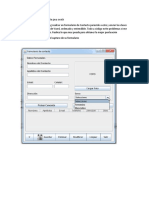
- Formulario de contacto Java SwingDocumento4 páginasFormulario de contacto Java SwingSameer Brito100% (2)
- Interfaz de Alto NivelDocumento35 páginasInterfaz de Alto NivelFrancisco AAún no hay calificaciones
- PDSD-519 AlumnotrabajofinalDocumento6 páginasPDSD-519 AlumnotrabajofinalJohan IsidroAún no hay calificaciones
- PROGRAMAS Get y Set06Documento4 páginasPROGRAMAS Get y Set06Dalia SandovalAún no hay calificaciones
- AP7 AA3 Ev1 Desarrollo Del Tutorial Construccion de Aplicacion Con JavaDocumento34 páginasAP7 AA3 Ev1 Desarrollo Del Tutorial Construccion de Aplicacion Con JavaEstiven CardonaAún no hay calificaciones
- Mapa Conceptual ExepcionesDocumento2 páginasMapa Conceptual ExepcionesKEVIN SEBASTIAN POVEDA GONZALEZAún no hay calificaciones
- Desarrollo de Aplicaciones en Eclipse y NetBeansDocumento11 páginasDesarrollo de Aplicaciones en Eclipse y NetBeansVanessa De la CruzAún no hay calificaciones
- Programacion Orientada A Objetos 1ra EdiciónDocumento17 páginasProgramacion Orientada A Objetos 1ra Edicióngiba269Aún no hay calificaciones
- Informe 2Documento25 páginasInforme 2MELOAún no hay calificaciones
- JavaaDocumento2 páginasJavaaFOREVER LOVEAún no hay calificaciones
- Ejercicios # 30 y 31 Investigación....Documento3 páginasEjercicios # 30 y 31 Investigación....Oscar ContrerasAún no hay calificaciones
- AA1 - Entorno WebDocumento19 páginasAA1 - Entorno WebYuli PlazaAún no hay calificaciones
- Clase 06Documento21 páginasClase 06Emilio29Aún no hay calificaciones
- Codo a Codo inicial clase 29Documento37 páginasCodo a Codo inicial clase 29Anto RolAún no hay calificaciones
- $RKQI3AUDocumento85 páginas$RKQI3AUCarlos FernandezAún no hay calificaciones
- Cliclo 2 JAVA DocV5Documento152 páginasCliclo 2 JAVA DocV5Wilmer J MendozaAún no hay calificaciones
- Codigo Java JSP MVC MYSQLDocumento4 páginasCodigo Java JSP MVC MYSQLMario David QUINONES CUERVOAún no hay calificaciones
- Paquetes en Java Definición, Uso y Ejemplos - Java Desde CeroDocumento17 páginasPaquetes en Java Definición, Uso y Ejemplos - Java Desde Ceroaprende phpAún no hay calificaciones
- Guía práctica laboratorio arquitectura monolíticaDocumento3 páginasGuía práctica laboratorio arquitectura monolíticaRUBEN ANTHONY DOMINGUEZ HUAMANAún no hay calificaciones
- Polimorfismo en POODocumento10 páginasPolimorfismo en POOjoker lolAún no hay calificaciones
- PDF Modelo 2 Experiencias Transformadoras DLDocumento6 páginasPDF Modelo 2 Experiencias Transformadoras DLRicardoEGAún no hay calificaciones
- Documentacion Snake GameDocumento11 páginasDocumentacion Snake GameTomás DelgadoAún no hay calificaciones
- Práctica 2Documento9 páginasPráctica 2Elber Gudo Jiménez0% (1)
- Arreglos de Objeto en JavaDocumento8 páginasArreglos de Objeto en JavaAlexx SamiiAún no hay calificaciones
- Wrapper y CastingDocumento2 páginasWrapper y CastingJuan Pablo Vasquez HAún no hay calificaciones
- Capítulo 5 - Funciones y ParámetrosDocumento15 páginasCapítulo 5 - Funciones y ParámetrosJosu Aguilar MartínezAún no hay calificaciones