0% encontró este documento útil (0 votos)
30 vistas27 páginasSimulación y Pruebas de Ajuste Estadístico
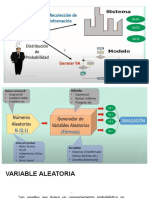
El documento aborda la creación de distribuciones de probabilidad y la aplicación de pruebas de bondad de ajuste, como la Chi-Cuadrado y Kolmogorov-Smirnov, para determinar la mejor distribución que se ajusta a los datos. Se explica el proceso de modelado estadístico, desde la recolección de datos hasta la visualización mediante histogramas, y se presentan ejemplos prácticos. Además, se discuten las variables aleatorias y las funciones de densidad de probabilidad en el contexto de simulación de sistemas.
Cargado por
José MendozaDerechos de autor
© © All Rights Reserved
Nos tomamos en serio los derechos de los contenidos. Si sospechas que se trata de tu contenido, reclámalo aquí.
Formatos disponibles
Descarga como PPT, PDF, TXT o lee en línea desde Scribd
0% encontró este documento útil (0 votos)
30 vistas27 páginasSimulación y Pruebas de Ajuste Estadístico
El documento aborda la creación de distribuciones de probabilidad y la aplicación de pruebas de bondad de ajuste, como la Chi-Cuadrado y Kolmogorov-Smirnov, para determinar la mejor distribución que se ajusta a los datos. Se explica el proceso de modelado estadístico, desde la recolección de datos hasta la visualización mediante histogramas, y se presentan ejemplos prácticos. Además, se discuten las variables aleatorias y las funciones de densidad de probabilidad en el contexto de simulación de sistemas.
Cargado por
José MendozaDerechos de autor
© © All Rights Reserved
Nos tomamos en serio los derechos de los contenidos. Si sospechas que se trata de tu contenido, reclámalo aquí.
Formatos disponibles
Descarga como PPT, PDF, TXT o lee en línea desde Scribd