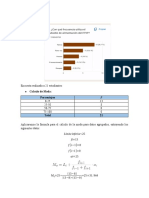
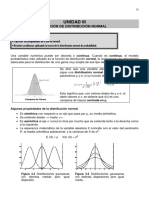
También podría gustarte
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- TRABAJO ESTADISTICA Fase 3 - Distribución y ProbabilidadDocumento19 páginasTRABAJO ESTADISTICA Fase 3 - Distribución y ProbabilidadKarolina Alvarado50% (4)
- Fase 3 - Elaborar Documento de Aplicación de Conceptos de Probabilidad Actualización 12 de Abril Con Ajustes Acorde A La Web.Documento13 páginasFase 3 - Elaborar Documento de Aplicación de Conceptos de Probabilidad Actualización 12 de Abril Con Ajustes Acorde A La Web.Pilar0% (1)
- Distribución de ProbabilidadDocumento50 páginasDistribución de Probabilidadpamela martinez cazorla100% (1)
- Hoja Calculo Incertidumbre Calcio Completa 2014Documento13 páginasHoja Calculo Incertidumbre Calcio Completa 2014Rosa Maria Higuera ArdilaAún no hay calificaciones
- Informe Presion Hidrostatica UA 2018Documento5 páginasInforme Presion Hidrostatica UA 2018Carlos Roa0% (1)
- Practica Matematicas III - Ciclo Terraba PDFDocumento27 páginasPractica Matematicas III - Ciclo Terraba PDFCascante RosaAún no hay calificaciones
- tarea-2-construccion-de-un-documento-de-aplicacion-de-conceptos-de-probabilidadDocumento11 páginastarea-2-construccion-de-un-documento-de-aplicacion-de-conceptos-de-probabilidadKarol BermudezAún no hay calificaciones
- 28 Estadística Descriptiva (Para Agrarias) : Andrea Paola Neira Emanuel Hurtado Zuley Yolima Ramirez Carolina RuedaDocumento30 páginas28 Estadística Descriptiva (Para Agrarias) : Andrea Paola Neira Emanuel Hurtado Zuley Yolima Ramirez Carolina RuedaAngelica Maria Gonzalez OrtegaAún no hay calificaciones
- Tarea 2 CONSTRUCCIÓN DE UN DOCUMENTO DE APLICACIÓN DE CONCEPTOSDocumento8 páginasTarea 2 CONSTRUCCIÓN DE UN DOCUMENTO DE APLICACIÓN DE CONCEPTOSLeidy NoriegaAún no hay calificaciones
- Estadistica 3Documento36 páginasEstadistica 3luis salazar osorioAún no hay calificaciones
- Probabilidad en R: Conceptos y aplicaciones agropecuariasDocumento16 páginasProbabilidad en R: Conceptos y aplicaciones agropecuariasNELSON FONTALVOAún no hay calificaciones
- Trabajo - Colavorativo - Fase 3 - Grupo - 300046 - 150Documento37 páginasTrabajo - Colavorativo - Fase 3 - Grupo - 300046 - 150Carlos LòpezAún no hay calificaciones
- Tarea 3 - Grupo 124Documento15 páginasTarea 3 - Grupo 124Jhon CaroAún no hay calificaciones
- Tatiana 1Documento29 páginasTatiana 1Nelcy yiseth Holguín florezAún no hay calificaciones
- Tarea 3 Aplicar Conceptos de Probabilidad Grupo 300046 68Documento12 páginasTarea 3 Aplicar Conceptos de Probabilidad Grupo 300046 68Katherin MendozaAún no hay calificaciones
- Fase 3 - Grupo 9Documento26 páginasFase 3 - Grupo 9Cristian ReyesAún no hay calificaciones
- Fase 3 EstadisticaDocumento14 páginasFase 3 Estadisticaceya1203Aún no hay calificaciones
- Tarea 2 - Construccion de Un Documento de Aplicacion de Conceptos de ProbabilidadDocumento14 páginasTarea 2 - Construccion de Un Documento de Aplicacion de Conceptos de ProbabilidadKaren Daniela Taborda losadaAún no hay calificaciones
- Fase3 AuraGonzalez 42Documento19 páginasFase3 AuraGonzalez 42Aura MariaAún no hay calificaciones
- Fase 3 - Distribucion y PortabilidadDocumento13 páginasFase 3 - Distribucion y PortabilidadJohan DiazAún no hay calificaciones
- YeisonAviles - Preguntas Punto 14Documento6 páginasYeisonAviles - Preguntas Punto 14mileidyAún no hay calificaciones
- Aplicación de conceptos de probabilidad con RDocumento16 páginasAplicación de conceptos de probabilidad con Rifael hernandezAún no hay calificaciones
- Fase 3 (Preguntas Orientadoras) .Documento27 páginasFase 3 (Preguntas Orientadoras) .Hector Tenorio0% (4)
- Fase 3 - Trabajo ColaborativoDocumento47 páginasFase 3 - Trabajo ColaborativoLorena Perez Valencia100% (3)
- PreguntasDocumento20 páginasPreguntassebastian torresAún no hay calificaciones
- Actividad Estadística DescriptivaDocumento9 páginasActividad Estadística DescriptivaMarcelo OrtegaAún no hay calificaciones
- Unidad 2 - Fase 3 - Distribución y Probabilidad - Mery - GarciaDocumento22 páginasUnidad 2 - Fase 3 - Distribución y Probabilidad - Mery - GarciaDora Duran100% (1)
- Fase 3 - Elaborar Documento de Aplicación de Conceptos de ProbabilidadDocumento13 páginasFase 3 - Elaborar Documento de Aplicación de Conceptos de Probabilidadmiguel romero100% (1)
- Estadistica Fase 3Documento28 páginasEstadistica Fase 3Wilson CaraballoAún no hay calificaciones
- Aplicacion de Conseptos de ProbabilidadDocumento11 páginasAplicacion de Conseptos de ProbabilidadSimeona DiazAún no hay calificaciones
- Trabajo Grupal BioestadisticaDocumento10 páginasTrabajo Grupal BioestadisticaAlison Castillo SanchezAún no hay calificaciones
- 50 - Fase 3 Distribución y ProbabilidadDocumento22 páginas50 - Fase 3 Distribución y Probabilidadliliana margarita luna sanches0% (1)
- Unidad2 Fase3 Grupo300046 112.Documento23 páginasUnidad2 Fase3 Grupo300046 112.Angelica Maria Gonzalez OrtegaAún no hay calificaciones
- Tarea 3 - Angela MendezDocumento22 páginasTarea 3 - Angela MendezJhon CaroAún no hay calificaciones
- Estadística Descriptiva Fase 3Documento35 páginasEstadística Descriptiva Fase 3Andres Favian Mendoza FonsecaAún no hay calificaciones
- Fase 3 - Estadística DescriptivaDocumento22 páginasFase 3 - Estadística Descriptivadarling matAún no hay calificaciones
- Estadistica Descriptiva-Fase3-Daniel-VelasquezDocumento9 páginasEstadistica Descriptiva-Fase3-Daniel-VelasquezDaniel VelasquezAún no hay calificaciones
- N. NDocumento11 páginasN. Nedinson herney lara llanosAún no hay calificaciones
- Fase 2 - Grupo 300046-2Documento13 páginasFase 2 - Grupo 300046-2Wilfredy Lemus VillamizarAún no hay calificaciones
- Unidad Uno-Fase 3 Distribución y ProbabilidadDocumento22 páginasUnidad Uno-Fase 3 Distribución y ProbabilidadsagarielgsAún no hay calificaciones
- Probabilidad y variables aleatoriasDocumento4 páginasProbabilidad y variables aleatoriasyurimarcela80Aún no hay calificaciones
- Fase 3 Individual Edwin H EstadisticaDocumento18 páginasFase 3 Individual Edwin H EstadisticaKntro Yineth Ivon100% (1)
- Fase 3Documento7 páginasFase 3CEFACUNDOSAún no hay calificaciones
- Distribución y probabilidad en variables aleatoriasDocumento17 páginasDistribución y probabilidad en variables aleatoriasMarcela CastroAún no hay calificaciones
- Distribuciones probabilidad binomial PoissonDocumento21 páginasDistribuciones probabilidad binomial PoissonRonaldo Jesús Salinas TapiaAún no hay calificaciones
- Estadsitica DescriptivaDocumento20 páginasEstadsitica DescriptivaMiguelito GordilloAún no hay calificaciones
- Investigacion Unidad 4Documento13 páginasInvestigacion Unidad 4Jonathan PerezAún no hay calificaciones
- Fase 3Documento15 páginasFase 3Tatiana AlvarezAún no hay calificaciones
- Guía Didáctica de Binomial y PoissonDocumento23 páginasGuía Didáctica de Binomial y PoissonAlejandro EscobarAún no hay calificaciones
- Fase 3 Unidad 2 Distribucion y ProbabilidadDocumento34 páginasFase 3 Unidad 2 Distribucion y ProbabilidadGerson Leandro RizoAún no hay calificaciones
- Probabilidad Unidad 3Documento16 páginasProbabilidad Unidad 3beatriz_roogAún no hay calificaciones
- Tonche Luna Oziel Jared - Investigacion Unidad VDocumento22 páginasTonche Luna Oziel Jared - Investigacion Unidad VOziel ToncheAún no hay calificaciones
- Investigacion Unidad 3 Probabilidad y EstadisticaDocumento8 páginasInvestigacion Unidad 3 Probabilidad y Estadisticapars78Aún no hay calificaciones
- Taller de Consulta y Estudio de Variables Aleatorias CompletarDocumento9 páginasTaller de Consulta y Estudio de Variables Aleatorias Completaradrian rodriguez rodriguezAún no hay calificaciones
- Estadistica Fase 3 Preguntas OrientadorasDocumento26 páginasEstadistica Fase 3 Preguntas OrientadorasmairaAún no hay calificaciones
- Teoría de ColasDocumento65 páginasTeoría de ColasandreaAún no hay calificaciones
- Distribución de probabilidad y PoissonDocumento17 páginasDistribución de probabilidad y Poissonmanuel corrales cerpaAún no hay calificaciones
- U-3 - Inv - Estadistica Administrativa PDFDocumento14 páginasU-3 - Inv - Estadistica Administrativa PDFMartin ValdesAún no hay calificaciones
- Fase 3 - Distribucion y ProbabilidadDocumento22 páginasFase 3 - Distribucion y ProbabilidadDuvan PeñaAún no hay calificaciones
- Estadística Inferencial CC Y ANDocumento10 páginasEstadística Inferencial CC Y ANAlbaro NadalesAún no hay calificaciones
- Carpeta de Evidencias 3ra Unidad Probabilidad y EstadísticaDocumento23 páginasCarpeta de Evidencias 3ra Unidad Probabilidad y EstadísticaKokosAún no hay calificaciones
- Caso Practico Unidad 3 Estadistica Descriptiva Actualizado Es EsteDocumento9 páginasCaso Practico Unidad 3 Estadistica Descriptiva Actualizado Es EsteCARROMENAún no hay calificaciones
- GUIA #3 DATOS NO AGRUPADOSDocumento4 páginasGUIA #3 DATOS NO AGRUPADOSJhon CaroAún no hay calificaciones
- Trabajo DaraDocumento38 páginasTrabajo DaraJhon CaroAún no hay calificaciones
- Tarea 3 - ColaborativaDocumento7 páginasTarea 3 - ColaborativaJhon CaroAún no hay calificaciones
- Mapa conceptual - Iventarios. Ivonne DuranDocumento2 páginasMapa conceptual - Iventarios. Ivonne DuranJhon CaroAún no hay calificaciones
- Tarea 1- Aprendizaje previo - Ivonne DuranDocumento14 páginasTarea 1- Aprendizaje previo - Ivonne DuranJhon CaroAún no hay calificaciones
- Formato_Propuesta-240201064-AA2-EV01Documento18 páginasFormato_Propuesta-240201064-AA2-EV01Jhon CaroAún no hay calificaciones
- ParcialDocumento4 páginasParcialJhon CaroAún no hay calificaciones
- Angela_Mendez_201105_Paso 4_carpeta de archivos.Documento12 páginasAngela_Mendez_201105_Paso 4_carpeta de archivos.Jhon CaroAún no hay calificaciones
- Trabajo Colaborativo - Ivonne DuranDocumento15 páginasTrabajo Colaborativo - Ivonne DuranJhon CaroAún no hay calificaciones
- Tarea 3 - Grupo 124Documento15 páginasTarea 3 - Grupo 124Jhon CaroAún no hay calificaciones
- Anexo 2 - Poster (entrega)Documento12 páginasAnexo 2 - Poster (entrega)Jhon CaroAún no hay calificaciones
- Instituto Jorge Tadeo LozanoDocumento2 páginasInstituto Jorge Tadeo LozanoJhon CaroAún no hay calificaciones
- Tarea 3 - Angela MendezDocumento22 páginasTarea 3 - Angela MendezJhon CaroAún no hay calificaciones
- Fase 2 - Angela MendezDocumento5 páginasFase 2 - Angela MendezJhon CaroAún no hay calificaciones
- Ejercicio 1 y 2Documento7 páginasEjercicio 1 y 2Jhon CaroAún no hay calificaciones
- Fase 2 - Angela MendezDocumento5 páginasFase 2 - Angela MendezJhon CaroAún no hay calificaciones
- 1 - Plan de Mejora - Técnico-YESSICADocumento16 páginas1 - Plan de Mejora - Técnico-YESSICAJhon CaroAún no hay calificaciones
- Moda y Analsis de Resultados.Documento14 páginasModa y Analsis de Resultados.Jhon CaroAún no hay calificaciones
- C Versalles Estado de Situación FinancieraDocumento6 páginasC Versalles Estado de Situación FinancieraJhon CaroAún no hay calificaciones
- Task 1 - Freddy AriasDocumento9 páginasTask 1 - Freddy AriasJhon CaroAún no hay calificaciones
- Anexo 2 - Fase 3 - Reflexión Ético-ciudadanaDocumento4 páginasAnexo 2 - Fase 3 - Reflexión Ético-ciudadanaJhon Caro100% (2)
- Tarea 6 - Angela Mendez Rincon.Documento5 páginasTarea 6 - Angela Mendez Rincon.Jhon CaroAún no hay calificaciones
- Trabajo Auditoria.Documento24 páginasTrabajo Auditoria.Jhon CaroAún no hay calificaciones
- Trabajo - MineriaDocumento11 páginasTrabajo - MineriaJhon CaroAún no hay calificaciones
- Analisis - Etapas Del Conflicto Armado en ColombiaDocumento4 páginasAnalisis - Etapas Del Conflicto Armado en ColombiaJhon CaroAún no hay calificaciones
- Ensayo Critico.Documento5 páginasEnsayo Critico.Jhon CaroAún no hay calificaciones
- Propuesta Plan de Mejoramiento - CamiloDocumento7 páginasPropuesta Plan de Mejoramiento - CamiloJhon CaroAún no hay calificaciones
- Certificacion Jhon CaroDocumento1 páginaCertificacion Jhon CaroJhon CaroAún no hay calificaciones
- Aca # 1 Planeacion y Control de La ProduccionDocumento11 páginasAca # 1 Planeacion y Control de La ProduccionJhon CaroAún no hay calificaciones
- Consolidado Final EstadisticaDocumento199 páginasConsolidado Final EstadisticacesarsaavedrasantaAún no hay calificaciones
- Mat 10u3Documento46 páginasMat 10u3David GuzmánAún no hay calificaciones
- Dstribuciòn de Gauss - Estadistica y Probabilidad 2Documento4 páginasDstribuciòn de Gauss - Estadistica y Probabilidad 2Jose Manuel NavarreteAún no hay calificaciones
- Notas de Clase Diseño de ExperimentosDocumento61 páginasNotas de Clase Diseño de ExperimentosBaruck Lucho MixtegaAún no hay calificaciones
- Un Tanque Rígido Contiene 12 Moles de Un Gas A Temperatura de 47Documento2 páginasUn Tanque Rígido Contiene 12 Moles de Un Gas A Temperatura de 47Rodrigo AquipuchoAún no hay calificaciones
- Determinantes IED ColombiaDocumento17 páginasDeterminantes IED ColombiaJoseLuisTangaraAún no hay calificaciones
- Presion de VaporDocumento4 páginasPresion de Vapormarzinus0% (1)
- Medidas de localización deciles y percentilesDocumento21 páginasMedidas de localización deciles y percentilesJaneth NavarreteAún no hay calificaciones
- 5Documento2 páginas5Yenii Bruno0% (1)
- Proceso Estocástico o AleatorioDocumento6 páginasProceso Estocástico o AleatorioDanieleonardoAún no hay calificaciones
- Ejercicios Estadistica DescriptivaDocumento6 páginasEjercicios Estadistica DescriptivaJimmy Arias SalamancaAún no hay calificaciones
- Presión de Vapor de Una Sustancia Pura Ing KarinaDocumento4 páginasPresión de Vapor de Una Sustancia Pura Ing KarinaJessicaAún no hay calificaciones
- Taller Distribuciones e ProbabilidadDocumento3 páginasTaller Distribuciones e Probabilidadandres gonzalez cosioAún no hay calificaciones
- Ejercicio 1 Unidad 1 - Alejandro CastilloDocumento2 páginasEjercicio 1 Unidad 1 - Alejandro Castillokaren florianAún no hay calificaciones
- La Distribución Normal.Documento2 páginasLa Distribución Normal.Daniel CoggiolaAún no hay calificaciones
- Examenes Resueltos de ProbabilidadDocumento3 páginasExamenes Resueltos de ProbabilidadSanty XaAún no hay calificaciones
- Tciv 03 PDFDocumento279 páginasTciv 03 PDFMiguel Angel Tocto AyalaAún no hay calificaciones
- NOTAS CLASE 8 Variables InstrumentalesDocumento17 páginasNOTAS CLASE 8 Variables InstrumentalesJESUS ALBERTO PUENTE ALONSOAún no hay calificaciones
- Guia Practica de Ecuaciones Simultaneas - Econometria II-2016-BDocumento23 páginasGuia Practica de Ecuaciones Simultaneas - Econometria II-2016-BLisset Soraya Huamán QuispeAún no hay calificaciones
- Reser Grupal FDocumento23 páginasReser Grupal FAnonymous L8SWYwKAún no hay calificaciones
- Probabilidad y Estadística II (Diagrama de Arbol)Documento12 páginasProbabilidad y Estadística II (Diagrama de Arbol)Deyci Fabiola Villarreal AlvaradoAún no hay calificaciones
- Efecto de la edad al destete en conejos alimentados con bloques de ramiéDocumento43 páginasEfecto de la edad al destete en conejos alimentados con bloques de ramiéJerry Vivas TorrezAún no hay calificaciones
- Unidad 2 - Materia Estadísticas y CostosDocumento19 páginasUnidad 2 - Materia Estadísticas y Costostamara3101Aún no hay calificaciones
- Informe de Calibracion IcDocumento7 páginasInforme de Calibracion IcCarlitos Cervantes GarciaAún no hay calificaciones
- Gas de Condensacion RetrogradoDocumento12 páginasGas de Condensacion RetrogradoFranz Carlos Conalde Tejerina100% (1)
- A Descriptiva e Inferencial IVDocumento54 páginasA Descriptiva e Inferencial IVJuan Guerrero RodriguezAún no hay calificaciones
- Diseño Experimentos KVC Pollos A La Canasta Victor ValdiviaDocumento23 páginasDiseño Experimentos KVC Pollos A La Canasta Victor ValdiviaVictor Dg ValdiviaAún no hay calificaciones