También podría gustarte
- La Batalla Del FuturoDocumento167 páginasLa Batalla Del FuturoFran Cisco83% (6)
- Machine LearningDocumento59 páginasMachine LearningLinda Esmeralda Torres RiosAún no hay calificaciones
- Trabajo 2 de Algebra Lineal PDFDocumento5 páginasTrabajo 2 de Algebra Lineal PDFMaria Rene Saucedo MedinaAún no hay calificaciones
- MonografiaDocumento68 páginasMonografiaFigueroa Sara50% (2)
- Árboles de Decisión ID3Documento2 páginasÁrboles de Decisión ID3pejos65271Aún no hay calificaciones
- Árboles de Decisión CompletosDocumento6 páginasÁrboles de Decisión CompletosJPG230691Aún no hay calificaciones
- Practica 1 - Introduccion Al MatlabDocumento12 páginasPractica 1 - Introduccion Al MatlabRami DavidAún no hay calificaciones
- Resumen Elementos de Algebra LinealDocumento87 páginasResumen Elementos de Algebra LinealhermeszanotticapoAún no hay calificaciones
- Introduccion A Matlab - PPT (Invalid Encoding)Documento80 páginasIntroduccion A Matlab - PPT (Invalid Encoding)CrisianyoAún no hay calificaciones
- Expocision de Algebra LinealDocumento4 páginasExpocision de Algebra LinealElanonimo TererodoAún no hay calificaciones
- Tipos MatricesDocumento5 páginasTipos MatricesJavier OlguinAún no hay calificaciones
- Matriz de CofactoresDocumento32 páginasMatriz de CofactoresErick AurelianoAún no hay calificaciones
- MATLAB99Documento21 páginasMATLAB99Ana Cecilia GomezAún no hay calificaciones
- Agregados Del ManualDocumento38 páginasAgregados Del ManualRene DíazAún no hay calificaciones
- Multiplicación de MatricesDocumento13 páginasMultiplicación de MatricesshirleynarAún no hay calificaciones
- 6 Arreglos MatricesDocumento25 páginas6 Arreglos MatricesJuankPeñaRamirezAún no hay calificaciones
- Comandos Importantes en Matlab-2013Documento27 páginasComandos Importantes en Matlab-2013Jose VzqzAún no hay calificaciones
- 6-Arreglos-Matrices Álgebra LinealDocumento30 páginas6-Arreglos-Matrices Álgebra LinealNahum MolinaAún no hay calificaciones
- Artículo Árboles de Decisión V3Documento15 páginasArtículo Árboles de Decisión V3Hernan Dario Cruz MazueraAún no hay calificaciones
- Cómo Calcular Una Matriz InversaDocumento8 páginasCómo Calcular Una Matriz InversaLizardo Montesinos BalladaresAún no hay calificaciones
- Operaciones Elementales Por Una MatrizDocumento2 páginasOperaciones Elementales Por Una MatrizAlejandro Fornerino NietoAún no hay calificaciones
- Unidad 2 - Parte 2Documento14 páginasUnidad 2 - Parte 2Agustina HerreraAún no hay calificaciones
- Informe de Algebra para Formato de TareasDocumento15 páginasInforme de Algebra para Formato de TareasadministratorAún no hay calificaciones
- Tensor trifocal: Explorando la profundidad, el movimiento y la estructura en visión por computadoraDe EverandTensor trifocal: Explorando la profundidad, el movimiento y la estructura en visión por computadoraAún no hay calificaciones
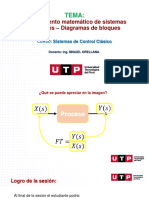
- S03.s1 - Control - Clásico - Modelo MatemáticoDocumento57 páginasS03.s1 - Control - Clásico - Modelo MatemáticoJONATHANAún no hay calificaciones
- Deber 03 Dayne SanchezDocumento5 páginasDeber 03 Dayne SanchezDayne SánchezAún no hay calificaciones
- Definición de La Función DeterminanteDocumento19 páginasDefinición de La Función DeterminanteerickaAún no hay calificaciones
- Determinantes de Una MatrizDocumento14 páginasDeterminantes de Una MatrizAriadny SilvaAún no hay calificaciones
- Investigacion de Al - Kevin 201 ADocumento15 páginasInvestigacion de Al - Kevin 201 AKevinAún no hay calificaciones
- Presentación Web Conferencia Definitiva Punto 4 y 5Documento23 páginasPresentación Web Conferencia Definitiva Punto 4 y 5LuisaAún no hay calificaciones
- Algebra Lineal-1Documento33 páginasAlgebra Lineal-1Edson MoralesAún no hay calificaciones
- Definición de Matriz Triangular SuperiorDocumento16 páginasDefinición de Matriz Triangular SuperiorAnonymous o22LE0HAún no hay calificaciones
- Matrices y Determinadas Alg Lineal Unidad 3 complETODocumento19 páginasMatrices y Determinadas Alg Lineal Unidad 3 complETOAntonio NavasAún no hay calificaciones
- Examenes Preda Completo OCRDocumento114 páginasExamenes Preda Completo OCRsergioitiAún no hay calificaciones
- Definición de MatrizDocumento9 páginasDefinición de MatrizVictor Javier InfanteAún no hay calificaciones
- Algebra-Lineal-Unidad 2Documento16 páginasAlgebra-Lineal-Unidad 2Luis FernandoAún no hay calificaciones
- Manual TécnicoDocumento5 páginasManual TécnicoMario RamírezAún no hay calificaciones
- Problemas de Matrices, Determinantes y Sistemas de EcuacionesDocumento9 páginasProblemas de Matrices, Determinantes y Sistemas de EcuacionesCarlos MotosAún no hay calificaciones
- Clase - Librería NumpyDocumento41 páginasClase - Librería NumpyAndrea SincheAún no hay calificaciones
- Exposicion Metodos de Clasificacion y Prediccion RDocumento48 páginasExposicion Metodos de Clasificacion y Prediccion RJesus Alberto Quishpe GrandaAún no hay calificaciones
- Unidad 2 A 5Documento16 páginasUnidad 2 A 5ea6244648Aún no hay calificaciones
- Formas para Desarrollar Matrices + Regla de CramerDocumento10 páginasFormas para Desarrollar Matrices + Regla de CramerPalmer DionicioAún no hay calificaciones
- CruzYuliana Practica3Documento8 páginasCruzYuliana Practica3318216274Aún no hay calificaciones
- DeterminantesDocumento4 páginasDeterminantesGeovanny JavierAún no hay calificaciones
- DeterminanteDocumento5 páginasDeterminantegrimaldo rodriguezAún no hay calificaciones
- Algoritmo c45 - Arboles de DecisionDocumento13 páginasAlgoritmo c45 - Arboles de DecisionGerardAún no hay calificaciones
- DETERMINANTESDocumento93 páginasDETERMINANTESjorge puyolAún no hay calificaciones
- Artículo Árboles de Decisión V4Documento16 páginasArtículo Árboles de Decisión V4Hernan Dario Cruz MazueraAún no hay calificaciones
- Alejandro Zurita Taller1 Modelo de Ecuaciones Nolineales 701Documento14 páginasAlejandro Zurita Taller1 Modelo de Ecuaciones Nolineales 701Krlos Francis AleAún no hay calificaciones
- TEMA 1 Matrices Determinates y Sistemas ResumenDocumento4 páginasTEMA 1 Matrices Determinates y Sistemas ResumenFran Ortuño avalosAún no hay calificaciones
- Matrices Tema 2Documento10 páginasMatrices Tema 2JENNIFER EMILIA ALDAZ ROJANOAún no hay calificaciones
- 1.-Algebra Lineal PDFDocumento34 páginas1.-Algebra Lineal PDFWalter100% (1)
- Modulo Unidad 2Documento6 páginasModulo Unidad 2Carlos GonzalezAún no hay calificaciones
- Análisis Factorial SPSS MenúsDocumento13 páginasAnálisis Factorial SPSS MenúsOrlando MartínAún no hay calificaciones
- Laboratorio 10 - MatricesDocumento4 páginasLaboratorio 10 - MatricesCrossAún no hay calificaciones
- AdalineDocumento13 páginasAdalineAsdtnGhymnbFghjytAún no hay calificaciones
- ALGEBRA LINEAL Tema2Documento10 páginasALGEBRA LINEAL Tema2Fresita Lokis Chuquitarco EgasAún no hay calificaciones
- T2.Matrices y DeterminantesDocumento19 páginasT2.Matrices y DeterminantesNato MoralesAún no hay calificaciones
- FSCNADocumento22 páginasFSCNAKelyAún no hay calificaciones
- Funciones Matemáticas y Trigonométricas Con ExcelDocumento19 páginasFunciones Matemáticas y Trigonométricas Con ExcelJuan Cho FernandezAún no hay calificaciones
- Consenso de muestra aleatoria: Estimación robusta en visión por computadoraDe EverandConsenso de muestra aleatoria: Estimación robusta en visión por computadoraAún no hay calificaciones
- Escribe en Tercera Persona Con Propósitos AcadémicosDocumento3 páginasEscribe en Tercera Persona Con Propósitos AcadémicosLuis Benjamin Mendoza BallinesAún no hay calificaciones
- Desarrollo PersonalDocumento2 páginasDesarrollo PersonalGabriel Manrique LoayzaAún no hay calificaciones
- Actividad #4 Diseño de Un Recurso Educativo Inclusivo Parte 1Documento12 páginasActividad #4 Diseño de Un Recurso Educativo Inclusivo Parte 1JAVIER ANDRES HERNANDEZ BARRERAAún no hay calificaciones
- Aracely MendozaDocumento6 páginasAracely MendozaDiego Daniel Villagomez MendozaAún no hay calificaciones
- 1u Vida Tu Mejor Negocio PDFDocumento10 páginas1u Vida Tu Mejor Negocio PDFPatricia CastañedaAún no hay calificaciones
- Reflexión Mensaje Sin Destino IragorryDocumento8 páginasReflexión Mensaje Sin Destino IragorryGuillermo LópezAún no hay calificaciones
- Como Poner en Practica La Gestion LeanDocumento35 páginasComo Poner en Practica La Gestion LeanEnrique Sáenz VeràsteguiAún no hay calificaciones
- Reglamento Del Estudiante ADEX - 2020Documento10 páginasReglamento Del Estudiante ADEX - 2020Bruce HuayanayAún no hay calificaciones
- HV7-07.1 - La Organización Del Territorio ColonialDocumento7 páginasHV7-07.1 - La Organización Del Territorio Colonialcarloschuecos3295Aún no hay calificaciones
- YOGA SUTRAS DE PATANJALI Dharmachari Maitreyananda (Fernando Estevez Griego)Documento12 páginasYOGA SUTRAS DE PATANJALI Dharmachari Maitreyananda (Fernando Estevez Griego)Fernando EstevezAún no hay calificaciones
- Oliveros López, Luis TESISDocumento194 páginasOliveros López, Luis TESISLuis RodriguezAún no hay calificaciones
- Grupos de HombresDocumento5 páginasGrupos de HombrespbongiorniAún no hay calificaciones
- Bases Teóricas - Científicas (Alexander Justino, RAMIREZ TOLEDO)Documento8 páginasBases Teóricas - Científicas (Alexander Justino, RAMIREZ TOLEDO)AlexanderAún no hay calificaciones
- Catalogo Residencial 2012 FinalDocumento32 páginasCatalogo Residencial 2012 FinalCarlos Fuentes TorresAún no hay calificaciones
- Lim011604 Certificacion Onix Roca Oct 2020Documento20 páginasLim011604 Certificacion Onix Roca Oct 2020San EduardoAún no hay calificaciones
- Ejes Temáticos Mes OctubreDocumento5 páginasEjes Temáticos Mes OctubreFlor CardenasAún no hay calificaciones
- Arboles de Regresion IntroduccionDocumento18 páginasArboles de Regresion IntroduccionCharo PradosAún no hay calificaciones
- Cap 2 F3 Ley GaussDocumento36 páginasCap 2 F3 Ley GaussPeter Efrain Flores BerrocalAún no hay calificaciones
- Análisis de La PelículaDocumento6 páginasAnálisis de La PelículaKaryme Guevara FisherAún no hay calificaciones
- Ortega Valcárcel - 2000 - Geografía HistóricaDocumento4 páginasOrtega Valcárcel - 2000 - Geografía HistóricaMartin DiazAún no hay calificaciones
- Avance de QuechuaDocumento37 páginasAvance de QuechuaGUILMER MENDOZA UCHAROAún no hay calificaciones
- RiesgoDocumento3 páginasRiesgoNAHOMI DIANA HUALLPA ARBITOAún no hay calificaciones
- Clase 25 - P11 Flexión en MaderaDocumento14 páginasClase 25 - P11 Flexión en MaderaJuan FranciscoAún no hay calificaciones
- Avance 1 de ProyectoDocumento3 páginasAvance 1 de ProyectoOswaldoAmayaBautistaAún no hay calificaciones
- Manual TinkercadDocumento1 páginaManual TinkercadAlberto CostaAún no hay calificaciones
- 3 Respuesta Metabolica Al TraumaDocumento11 páginas3 Respuesta Metabolica Al TraumaDavid MayoAún no hay calificaciones
- José Ratzer Los Marxistas Argentinos Del 90 y El Movimiento Socialista en ArgentinaDocumento3 páginasJosé Ratzer Los Marxistas Argentinos Del 90 y El Movimiento Socialista en ArgentinaVladimir RiverosAún no hay calificaciones
- Aparejos de Los LadrillosDocumento5 páginasAparejos de Los LadrillosJose LuisAún no hay calificaciones