También podría gustarte
- LabVIEW: Entorno gráfico de programaciónDe EverandLabVIEW: Entorno gráfico de programaciónCalificación: 4 de 5 estrellas4/5 (4)
- Prueba Estemporanea Francisco Murillo AICDocumento14 páginasPrueba Estemporanea Francisco Murillo AICFRANCISCO FEDERICO MURILLO VILLAREAL100% (1)
- Entrega Final Metodos Numericos PDFDocumento11 páginasEntrega Final Metodos Numericos PDFJUAN JOSE CAMACHO MARTINEZAún no hay calificaciones
- Proyecto de Simulación en SIMIO para La UniversidadDocumento12 páginasProyecto de Simulación en SIMIO para La UniversidadFrancisco Nyarlathotep Maturana Vásquez100% (1)
- Lectura Simulaciones Monte CarloDocumento5 páginasLectura Simulaciones Monte CarloAlbert Alonso Traña SantanaAún no hay calificaciones
- Salvaguarda y seguridad de los datos. IFCT0310De EverandSalvaguarda y seguridad de los datos. IFCT0310Aún no hay calificaciones
- Econometría I: manual de Eviews: Estimulación de un modelo de exportaciónDe EverandEconometría I: manual de Eviews: Estimulación de un modelo de exportaciónAún no hay calificaciones
- Guías para El Programa MbalDocumento18 páginasGuías para El Programa Mbalcesil reynaldo callaguara baños50% (2)
- Tarea RegresionDocumento10 páginasTarea Regresionalexander.valdivia.ancaAún no hay calificaciones
- Informe de Hysys Calculos y ResultadoDocumento19 páginasInforme de Hysys Calculos y ResultadoDaniel Delgado100% (1)
- Trabajo Automatizacion Agroindustrial Sistema de RiegoDocumento12 páginasTrabajo Automatizacion Agroindustrial Sistema de Riegojhon celis mendezAún no hay calificaciones
- Analisis Exploratorio de DatosDocumento28 páginasAnalisis Exploratorio de DatosAnthonySilvaAún no hay calificaciones
- Ejercicios para El Laboratorio Del 24 de AgostoDocumento2 páginasEjercicios para El Laboratorio Del 24 de AgostoJOHAN MARCO QUISPE RODRIGUEZAún no hay calificaciones
- F3 OscarFernandoAviles 203055 16Documento17 páginasF3 OscarFernandoAviles 203055 16lindapinoAún no hay calificaciones
- Manual de Usuario - ClawsDocumento10 páginasManual de Usuario - ClawsFélipe BeltránAún no hay calificaciones
- Lab4 Algoritmia 2020BDocumento4 páginasLab4 Algoritmia 2020BSteven MuñozAún no hay calificaciones
- Lab 06 Caso Integrador Trees-1Documento5 páginasLab 06 Caso Integrador Trees-1Mendoza Quispe Luis JorgeAún no hay calificaciones
- Planta de Producción 2Documento19 páginasPlanta de Producción 2Jose VelascoAún no hay calificaciones
- Laboratorio de Sistemas de Control SCILABDocumento27 páginasLaboratorio de Sistemas de Control SCILABLuisCarlosRemonCotesAún no hay calificaciones
- Simulación de SistemasDocumento6 páginasSimulación de SistemasJenny Corrales SanchezAún no hay calificaciones
- Enunciado Proyecto N4 IP 20221Documento10 páginasEnunciado Proyecto N4 IP 20221javier stevenAún no hay calificaciones
- Get Faostat Data With TidyverseDocumento10 páginasGet Faostat Data With TidyverseFranklin SantosAún no hay calificaciones
- T3 - Reporte TecnicoDocumento23 páginasT3 - Reporte TecnicoMaria trinidad reyes tapiaAún no hay calificaciones
- 3kadle7ssoeojil4slyhwq Mlflow VF DsaDocumento8 páginas3kadle7ssoeojil4slyhwq Mlflow VF Dsajuan sebastian perdomo becerraAún no hay calificaciones
- Act Fund 4 Voltmetro FreeRTOS - 1915024Documento11 páginasAct Fund 4 Voltmetro FreeRTOS - 1915024Hiram GonzalezAún no hay calificaciones
- Reporte de Máquina de Aprendizaje No SupervisadoDocumento27 páginasReporte de Máquina de Aprendizaje No Supervisadoluis tellezAún no hay calificaciones
- Programación en ArcgisDocumento11 páginasProgramación en ArcgisEduardoAún no hay calificaciones
- Monitoreo Motor CaterpillarDocumento10 páginasMonitoreo Motor CaterpillarTwisted LowellAún no hay calificaciones
- L06 Macros Nivel BasicoDocumento16 páginasL06 Macros Nivel BasicoSergio Alberto Escobedo RodriguezAún no hay calificaciones
- L06 Macros Nivel BásicoDocumento16 páginasL06 Macros Nivel BásicoJoshep RoqueAún no hay calificaciones
- 03 - Taller de Desempeño Entradas-Procesos-Salidas - 03-Nov-2017Documento2 páginas03 - Taller de Desempeño Entradas-Procesos-Salidas - 03-Nov-2017Javiier CanolesAún no hay calificaciones
- Capitulo 11Documento43 páginasCapitulo 11c2franco23Aún no hay calificaciones
- Lab16. Control de ProcesoDocumento11 páginasLab16. Control de ProcesoYordi AlvitresAún no hay calificaciones
- Implementacion de Procedimientos AlmacenadosDocumento58 páginasImplementacion de Procedimientos Almacenadosluis cv0% (1)
- Condiciones ClimaticasDocumento132 páginasCondiciones ClimaticasElisabeth Rivas AlcaideAún no hay calificaciones
- Lab 08 - Excel 2013 - Funciones Matematicas y Estadisticas 1Documento9 páginasLab 08 - Excel 2013 - Funciones Matematicas y Estadisticas 1Wilde Ronald Apaza PariAún no hay calificaciones
- Taller 3Documento9 páginasTaller 3Rubén DarioAún no hay calificaciones
- Guia de MonitoreoDocumento14 páginasGuia de MonitoreoPedro TenorioAún no hay calificaciones
- Aplicaciones Simples Del Calculo de MatricesDocumento19 páginasAplicaciones Simples Del Calculo de Matricesapi-26274418100% (1)
- 3ra Entrega TC Subgrupo 17Documento12 páginas3ra Entrega TC Subgrupo 17Laura Fonseca50% (2)
- Medidor de Parámetros AmbientalesDocumento31 páginasMedidor de Parámetros AmbientalesMauricio CastillaAún no hay calificaciones
- Lab 02 - RecursividadDocumento5 páginasLab 02 - Recursividaderick joseAún no hay calificaciones
- Simulación de Un Proceso de Obtención de Acetato de Metilo en Aspen PlusDocumento12 páginasSimulación de Un Proceso de Obtención de Acetato de Metilo en Aspen PlusCristian Duvan Gamboa JerezAún no hay calificaciones
- Guía para El Desarrollo Del Componente Práctico-Unidad 1,2 y 3 - Fase 5 - Componente PrácticoDocumento10 páginasGuía para El Desarrollo Del Componente Práctico-Unidad 1,2 y 3 - Fase 5 - Componente Prácticodiana betancour0% (1)
- Guia RDocumento40 páginasGuia RMaría José BordónAún no hay calificaciones
- Diferencia Entre PLC y UcDocumento10 páginasDiferencia Entre PLC y Ucmartin.saavedra.epieAún no hay calificaciones
- Laboratorio N°02 - Procesos IndustrialesDocumento25 páginasLaboratorio N°02 - Procesos IndustrialesMariaJose Davila FernandezAún no hay calificaciones
- Lab 02 - Recursividad-1 MAMANI - MAMANI.renzo - junior-3C24EDocumento7 páginasLab 02 - Recursividad-1 MAMANI - MAMANI.renzo - junior-3C24EaaAún no hay calificaciones
- Cáceres Solís, David Alonso U20161B459Documento8 páginasCáceres Solís, David Alonso U20161B459Deyvis TA100% (1)
- TraducidoDocumento7 páginasTraducidoSelene VargasAún no hay calificaciones
- Guia de Práctica 3 PYTHON 2022-0Documento14 páginasGuia de Práctica 3 PYTHON 2022-0RONALDO VICTOR CABEZAS CORTEZAún no hay calificaciones
- Solucion de Casos PDocumento17 páginasSolucion de Casos PAdán RodriguezAún no hay calificaciones
- Actividad 4. Microeconomia - NRC 21018 - Teoria Del Productor - Grupo 3Documento11 páginasActividad 4. Microeconomia - NRC 21018 - Teoria Del Productor - Grupo 3Eliana Libeth LOMBANA JOJOA100% (1)
- P3 IAA Rodriguez Zubaran Carlos ErickDocumento11 páginasP3 IAA Rodriguez Zubaran Carlos ErickCarlos Erick Rodríguez ZubaránAún no hay calificaciones
- Entrega 1 Investigación de OperacionesDocumento10 páginasEntrega 1 Investigación de OperacionesIsabela TrujilloAún no hay calificaciones
- Analisis de Monte CarloDocumento17 páginasAnalisis de Monte CarloBryam Ulloa MontoyaAún no hay calificaciones
- Operaciones auxiliares con Tecnologías de la Información y la Comunicación. IFCT0108De EverandOperaciones auxiliares con Tecnologías de la Información y la Comunicación. IFCT0108Aún no hay calificaciones
- Administración de Sistemas Gestores de Bases de Datos (2ª Edición)De EverandAdministración de Sistemas Gestores de Bases de Datos (2ª Edición)Aún no hay calificaciones
- Gestión de bases de datos (2ª Edición) (GRADO SUPERIOR)De EverandGestión de bases de datos (2ª Edición) (GRADO SUPERIOR)Aún no hay calificaciones
- Administración de redes LAN. Ejercicios prácticos con GNS3De EverandAdministración de redes LAN. Ejercicios prácticos con GNS3Aún no hay calificaciones
- Practica 4 Capacidad CalorificaDocumento4 páginasPractica 4 Capacidad CalorificaAlexander Pinzon100% (1)
- Comunicación PublicitariaDocumento3 páginasComunicación PublicitariaMontserrat EguiaAún no hay calificaciones
- Clase 12 - Combinacion Lineal & Independencia Lineal - 3 OctubreDocumento10 páginasClase 12 - Combinacion Lineal & Independencia Lineal - 3 OctubreGEOVANY MARCELINO JIMENEZ MIRANDAAún no hay calificaciones
- Modelo Toma de Desiciones-Escenario 8-PoliDocumento9 páginasModelo Toma de Desiciones-Escenario 8-PoliMaria Angelica Restrepo PallaresAún no hay calificaciones
- PLANIFICACION DE MATEMATICA - Agosto 4° Grado MatematicaDocumento13 páginasPLANIFICACION DE MATEMATICA - Agosto 4° Grado MatematicaPAMELA ALEJANDRAAún no hay calificaciones
- Proceso para El Desarrollo de Software - Wikipedia, La Enciclopedia LibreDocumento47 páginasProceso para El Desarrollo de Software - Wikipedia, La Enciclopedia LibreLesbia CastroAún no hay calificaciones
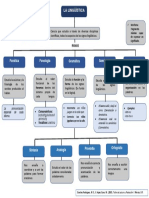
- Linguistica PDFDocumento1 páginaLinguistica PDFPATRICIA ANGELESAún no hay calificaciones
- Variables y TiposDocumento3 páginasVariables y Tiposn q sAún no hay calificaciones
- Inferencias Inmediatas. Cuadro de BoecioDocumento7 páginasInferencias Inmediatas. Cuadro de BoeciokattializzetAún no hay calificaciones
- Leccion 3Documento236 páginasLeccion 3Jorge GalavizAún no hay calificaciones
- 8vo Micro Mate 2 Parc (27686)Documento20 páginas8vo Micro Mate 2 Parc (27686)daniel sloisAún no hay calificaciones
- Calor II HermosoDocumento43 páginasCalor II HermosoIsrael CachumbaAún no hay calificaciones
- Trabajo Metodos 2do AporteDocumento18 páginasTrabajo Metodos 2do AportePaulo BordaAún no hay calificaciones
- EJERCICIOS DE CONJUNTOS TallerDocumento6 páginasEJERCICIOS DE CONJUNTOS TallerCristian OcampoAún no hay calificaciones
- ESTATICA CompletoDocumento13 páginasESTATICA CompletoJuan Carlos Mamani GomezAún no hay calificaciones
- MAT 3 Unidad4 PDFDocumento10 páginasMAT 3 Unidad4 PDFRicardo CabezasAún no hay calificaciones
- Guia de AlgebraDocumento49 páginasGuia de AlgebraFacultad De Quimica UaqAún no hay calificaciones
- Deber N - 3Documento22 páginasDeber N - 3siulseerdna7770% (1)
- Inestabilidad de BarrasDocumento16 páginasInestabilidad de BarrasCristóbal Ruíz SánchezAún no hay calificaciones
- Yadira Martinez Campos Matematicas 3Documento8 páginasYadira Martinez Campos Matematicas 3Yadira CamposAún no hay calificaciones
- Asignación Semana 8 Regresión y CorrelaciónDocumento8 páginasAsignación Semana 8 Regresión y CorrelaciónPalomaAún no hay calificaciones
- Capitulo 11 - ConfiabilidadDocumento6 páginasCapitulo 11 - Confiabilidadluz gomezAún no hay calificaciones
- Tesis-PROCEDIMIENTO PARA EL DISEÑO DE ESTRATEGIAS FINANCIERAS EN EMPRESAS ESTATALES CUBANAS-Leyva Ferreiro, Grisell (2014) PDFDocumento189 páginasTesis-PROCEDIMIENTO PARA EL DISEÑO DE ESTRATEGIAS FINANCIERAS EN EMPRESAS ESTATALES CUBANAS-Leyva Ferreiro, Grisell (2014) PDFJorge ResendezAún no hay calificaciones
- Proyecto Casino AlgabraicoDocumento18 páginasProyecto Casino AlgabraicoJose Luis Monja GarciaAún no hay calificaciones
- La Intersecci´on Arbitraria de una Familia de Subconjuntos Abiertos con la Propiedad α-S-Localmente Finita es α-SemiabiertaDocumento8 páginasLa Intersecci´on Arbitraria de una Familia de Subconjuntos Abiertos con la Propiedad α-S-Localmente Finita es α-SemiabiertaRichardAún no hay calificaciones
- Teoría de ErroresDocumento9 páginasTeoría de ErroresMapache StaelAún no hay calificaciones
- InvestigaciònDocumento32 páginasInvestigaciònGin CastelblancoAún no hay calificaciones
- PRACTICA 4 de Quimica Aplicada Viscosidad y Tension SuperficialDocumento20 páginasPRACTICA 4 de Quimica Aplicada Viscosidad y Tension SuperficialErick Deras0% (1)